
基于循环神经网络的微博转发行为预测①
2019-08-22 02:31穆圣坤张路桥滕彩峰
计算机系统应用 2019年8期
穆圣坤, 张路桥, 滕彩峰
(成都信息工程大学 网络空间安全学院,成都 610225)
近年来,随着微博活跃用户持续稳步增长,微博逐渐成为社交网络中信息传播及信息收集的重要平台,截至2017年9月,微博月活跃人数共3.76亿,较去年同期增长27%,日活跃用户达到1.65亿,较去年同期增长25%. 如此庞大的用户规模使得微博已经成为社交网络中重要的媒体之一.
微博转发是微博信息传播的重要途径,是微博信息传播[1,2]、微博营销、舆情监控[3]等问题的研究关键,研究微博转发问题可以更好地跟踪微博信息的传播路径,更好地研究微博传播的特点,方便进行深层次的研究; 同时还可以通过挖掘用户粉丝的兴趣特点,进行粉丝分类,从而达到微博营销、微博推荐[4,5]等目的. 因此,研究微博转发问题有着重要的意义.
1 相关工作
再对微博转发的研究上,主要的研究方向有影响微博转发因素的分析[6,7]和微博转发预测[8-10]. 在影响微博转发因素的分析方面,Rudat[11]等研究了用户引导、微博主题以及信息量3个方面因素对微博转发行为的影响. 徐晓璇[12]主要是根据信息的传播特点、微博群体转发规律、微博用户信息转发行为的心理三方面因素,分别从传播学、信息学、社会学的角度对影响用户转发微博的因素进行了研究. 赖胜强[13]等人利用多元回归法在微博信息内容特性、传播者特性以及受众特性这三个方面对影响用户转发微博的因素进行了研究. 吴凯[14]利用兴趣相似程度、社会关系影响、文本特征与用户属性影响、用户受激活次数的影响四种指标构建了一种行为预测的信息传播模型. 文献[15]在微博数据中发现影响用户是否会转发的一个重要因素是用户的社会关系结构,并利用逻辑回归构建转发预测模型. 在微博预测方面,S Petrovic[16]提出了基于passive-aggressive算法的人工实验方法来预测微博.Suh[17]等人首先研究了对微博转发率影响较大的因素,然后又提出了预测转发率的广义线性模型. 邓青[18]从微博文本内容和发帖人两方面对影响微博转发的因素进行了分析研究,并利用BP神经网络对突发事件下的微博转发量进行了预测. 张效尉[19]等借助集成学习的思想提出了一种的预测微博用户转发行为的算法.Nesi P[20]等从Twitter数据中提取出若干特征,然后利用递归划分过程构建了用于预测的分类树. 李志清[21]通过LDA主题生成模型提取并构建了微博的主题特征,同时再与微博特征和用户特征相结合,最终提出了基于主题特征的微博预测模型. 李英乐[22]等利用用户影响力、兴趣相似度、用户活跃度、微博文本内容的重要性和用户亲密程度五类特征通过支持向量机算法构建模型进行转发行为预测.
综上所述,以往模型存在的问题是:(1) 没有考虑到网络的飞速发展、微博营销策略的改变对微博转发的影响. (2) 在通过用户历史微博来预测当前微博转发量的研究上,没有考虑到历史微博和预测微博的文本相关性. (3) 在兴趣相似度的问题上,没有通过微博文本和粉丝兴趣的相似度来预测单个粉丝是否会转发. 这样必然会导致最终的结果不准确. 基于以上的分析,本文结合LSTM[23,24]和DNN神经网络[25]的优势,提出一种基于LSTM的模型来预测用户微博的转发量级.
1.1 模型架构
随着微博用户数量和微博平均浏览时长的不断增长,微博用户营销策略的不断变化,微博转发量也会呈现不同的变化趋势,故本文定义这种变化趋势为转发趋势度. 当然微博主题的不同、用户知名度变化、微博用户营销策略的不同都对应这不同的转发趋势度,转发趋势度越高的用户其发布微博后,该微博被转发几率越大,传播的范围和影响也会变大,所以转发趋势度也是影响微博转发的关键因素之一. 此外,用户转发微博主要有两类原因:① 内容:即用户对微博的内容感兴趣,② 用户本身:用户对微博发布者感兴趣.
基于以上三点,本文通过微博特征、用户特征、微博文本与粉丝兴趣的相似度、转发趋势度与LSTM和DNN神经网络的优势相结合来建立预测模型. 模型架构如图1.
2 数据采集及特征选择
2.1 数据采集
由于微博API的限制,本文采用网络爬虫获取新浪微博数据. 详细数据如表1.
2.2 特征选择
本文选取用户特征和微博特征共计17种. 详见表2.
以“汽车之家”微博为例,其中活跃粉丝数是在“汽车之家”一年之内发布的所有微博中存在评论或转发行为的用户. 平均微博转发数是用户所有微博的转发数之和与发布微博总数量的比值.
微博文本特征词向量:将微博文本提取出来,利用jieba分词获取文本的特征词向量.
粉丝兴趣特征词向量:获取每个粉丝近期的微博文本,同样通过分词得到该粉丝的特征词向量.

图1 模型框架图
利用微博文本特征词向量和粉丝的特征词向量构建的语料库,然后通过TF-IDF分别建立微博文本特征向量和粉丝微博特征向量
微博文本兴趣相似度:计算微博文本特征向量和粉丝微博特征向量的余弦相似度.
如图2所示,是用户微博文本示例.
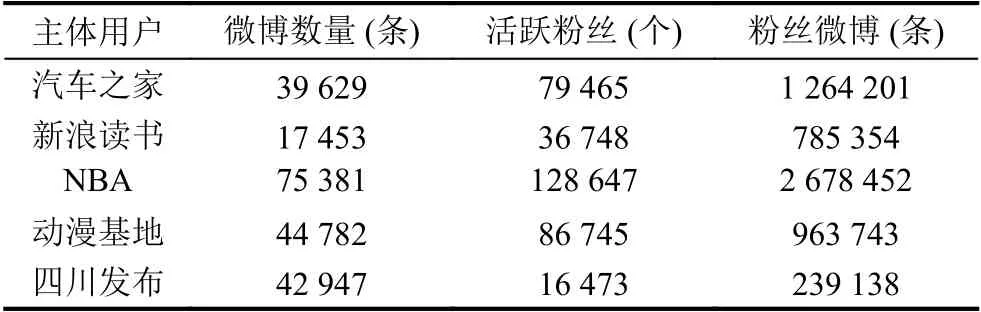
表1 数据表
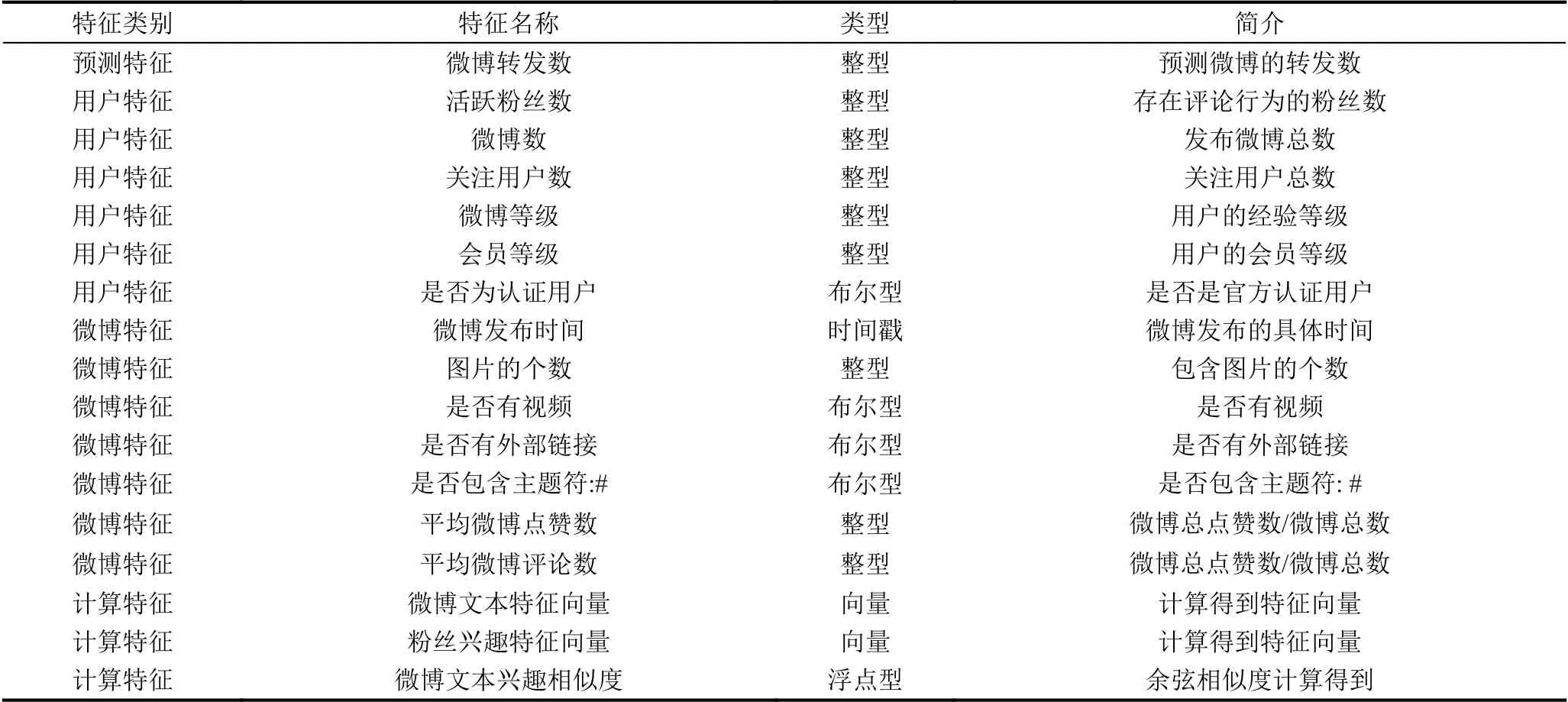
表2 特征表

图2 预测微博文本示例
图3是不同小时发布微博数累计分布曲线,可知用户在晚上22时至8时,活跃次数较少,发布微博的数量也相对较低. 图4为微博VIP等级与用户微博转发数的分布图,微博针对VIP级别越高的会员,会有更多的特权,其微博更易扩散,转发量也会多一些. 此外,从前人的研究中也可以看出微博包含图片数、是否有视频、是否有外部链接、是否包含主题符都对微博转发有着一定的影响.
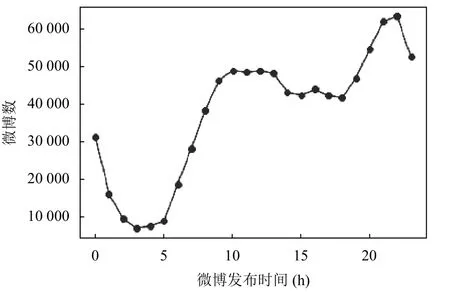
图3 不同小时发布微博数累计分布曲线
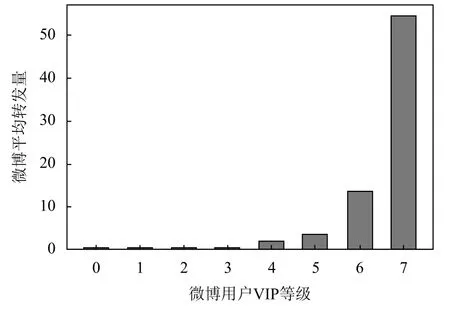
图4 微博用户VIP等级与平均转发量分布图
3 转发行为预测
3.1 SIM-LSTM神经网络模型:构建转发趋势度
目的:预测出某条微博的转发趋势度.
输入:活跃粉丝数、关注用户数、微博数、是否为认证用户、微博等级、会员等级、平均微博转发数、微博发布时间、图片的个数、是否有视频、是否有外部链接、是否有包含主题符:#、平均微博点赞数、平均微博评论数、微博文本特征向量、预测微博文本特征向量.
输出:微博转发趋势度对应该条微博转发量,根据本文所使用的数据集,将微博最终转发量对应为10个数量级(0-9). 如表3所示.
相较于传统的LSTM,本文新加入了一个控制门sim. sim门功能:前一节点的细胞状态 C(t-1)和输出的隐藏层 h(t-1)进入当前节点时会先进入sim门,sim门是微博相似度的余弦函数,sim值大于0时:进入遗忘门、输入门依次更新细胞状态最后得到 C(t)和 h(t); 当sim值小于0时:细胞状态直接输出上一时刻的细胞状态和上一时刻的隐藏层状态即 C(t)=C(t-1),h(t)=h(t-1).

表3 微博转发趋势与微博转发数对照表
SIM-LSTM网络模型可以根据历史微博文本内容和预测微博文本内容的相似度来选取相关性大的微博作为训练集,使得训练数据之间的关系更加紧密,故采用此结构可以有效的使弱相关的训练数据权重变小,从而得到更加准确的预测效果.
改进LSTM模型图如图5所示.
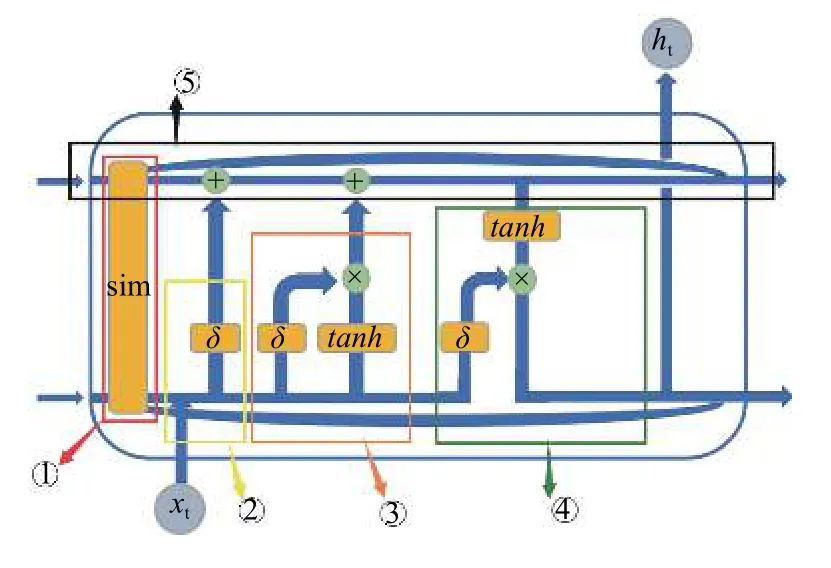
图5 SIM-LSTM结构图
图5中①号框中是sim判断门; 是改进的判断控制函数sim:
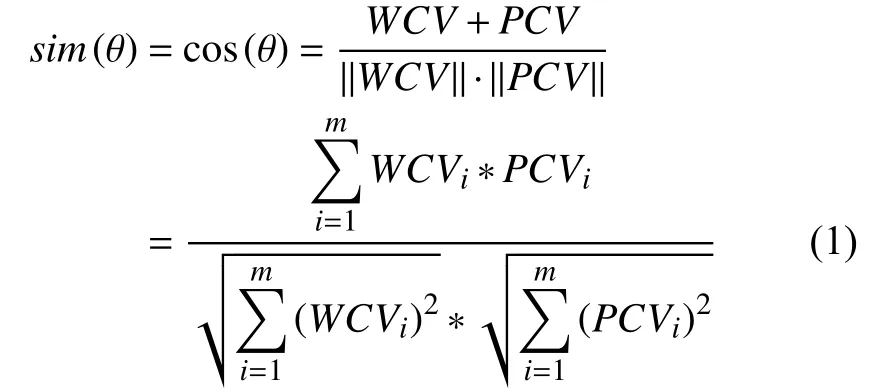
当判断的sim值大于0时:按照原来LSTM依次更新细胞状态; 当sim值小于0时:细胞状态直接输出上一时刻的细胞状态和上一时刻的隐藏层状态.
图5中②号框中是遗忘门:输入是前一时刻的隐藏状态 h(t-1)和本序列数据 X(t),此处通过的激活函数是本文提出的Sigmoid函数,得到遗忘门输出:其中,Wf、Uf、bf是线性关系的系数和偏倚,X(t)是本文上面提到的16种特征.
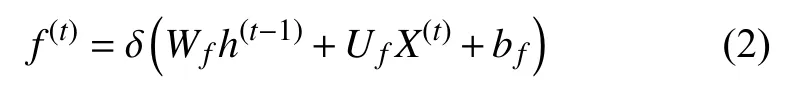
图5中③号框中是输入门:它的输入是包括两部分是i(t)和a(t):
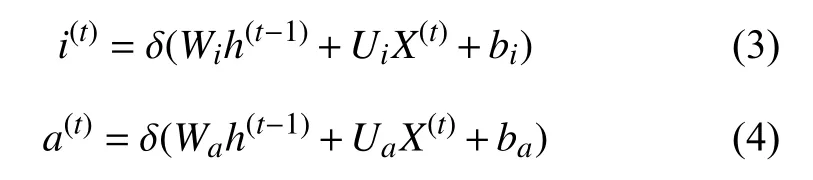
同理Wi、Ui、bi、Wa、Ua、ba是线性关系的系数和偏倚.
图5中④号框中是输出门:

图5中⑤号框中是细胞状态更新:细胞状态更新C(t)有两部分组成:遗忘门输出f(t)和C(t-1)的乘积、输入门i(t)和a(t)的乘积.
其中,·是Hadamard积.
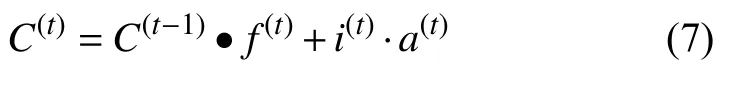
4 建模分析与结果
4.1 SIM-LSTM预测模型分析
SIM-LSTM模型中sim门是通过粉丝兴趣和微博文本的相似度来对输入数据进行权重控制,使相关性小的微博数据权重降低甚至为0,所以我们训练集中的数据会与预测微博相关性更大,结果必然会更好. 为此,我们将SIM-LSTM模型和传统的LSTM模型进行对比试验,分别将各自的转发趋势度作为特征训练最后的神经网络模型,实验结果表明SIM-LSTM的提出是有效的.
图6上图是SIM-LSTM结果混淆矩阵,下图是LSTM的混淆矩阵,我们可以看出,SIM-LSTM得到结果会更好,同时我们计算得SIM-LSTM的准确率为89.55%,LSTM的准确率为75.53%.
4.2 深度神经网络预测转发量级
目的:预测微博的转发量级.
本文是在用户活跃粉丝集中预测单个粉丝是否会转发微博,最后统计预测会转发微博的粉丝数来得到微博的转发量.
因为要预测粉丝是否会转发,所以输入包含用户、微博、粉丝3类特征再加兴趣相似度和转发趋势度共计20种.
用户特征有:活跃粉丝数、关注数、微博数、是否认证、微博等级、VIP等级、平均转发量、平均点赞量、平均评论量; 微博特征有图片数、是否有视频、外部链接、主题符、发布时间; 粉丝特征有微博数、关注数、VIP等级、是否认证.
输出:0 和 1,0代表该粉丝不会转发,1代表该粉丝会转发.
为了深入探究不同模型对最后转发预测结果的影响,我们使用LR、SVM、BP、RF算法进行建模预测.
此外我们在实验后,又利用随机森林预测模型给出的特征权重(如图7(a)、(b)和图8所示为训练特征中微博类特征、粉丝类特征、微博用户类特征的权重条形图)进行特征筛选,剔除权重在0.5以下的特征,然后再次通过DNN进行建模预测,得到了更高的准确率.

图6 SIM-LSTM和LSTM预测结果混淆矩阵
DNN的一些关键参数如下:
损失函数:对数似然损失函数.
激活函数:Softmax函数.
参数设置:本文最终采用隐藏层为8层,节点数目为32的神经网络模型. 利用指数衰减法来动态的设置学习率,设置初始学习率为0.1,衰减系数为0.95. 滑动平均模型的衰减率为:0.999,dropout率为0.5.
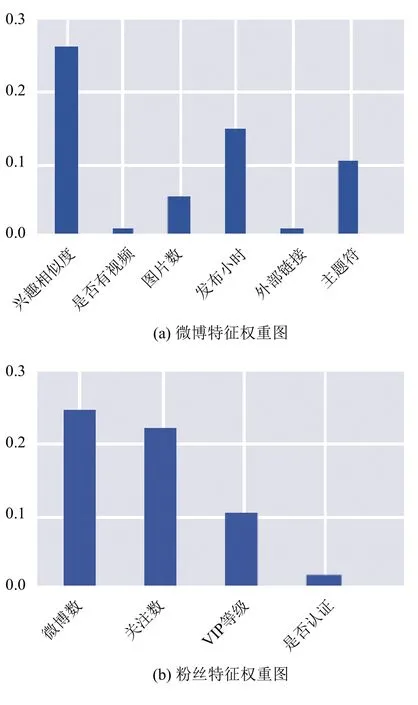
图7 微博类、粉丝类特征的权重条形图
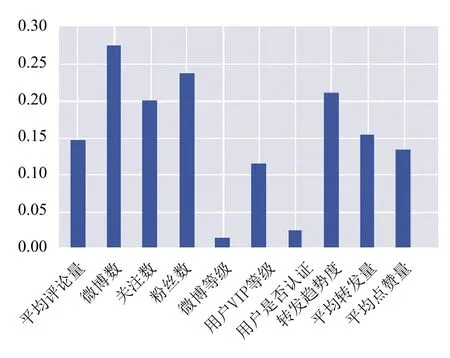
图8 微博用户类特征的权重条形图
在DNN模型训练中,我们将图9是微博兴趣相似度与转发率的关系图,可以看出,相似程度高的粉丝转发用户微博的可能性更高.
预测用户转发量级:为了获得理想的预测结果,本文选择了多种预测模型并通过交叉验证来对转发行为进行预测,通过准确率、召回率、F1值来对结果进行度量,准确率用于检验模型的准确性,召回率用于检验模型的完备性,准确率和召回率相互制约,因此用F1值作为模型效果的综合评价指标. 经实验得:本文提出的方法较其他的方法而言有着近5%的提高,提出的转发趋势度和微博兴趣相似度对微博转发的研究也有着重要的影响. 如表4所示.
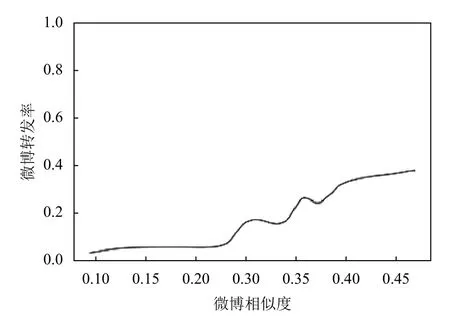
图9 微博兴趣相似度与转发率的关系图
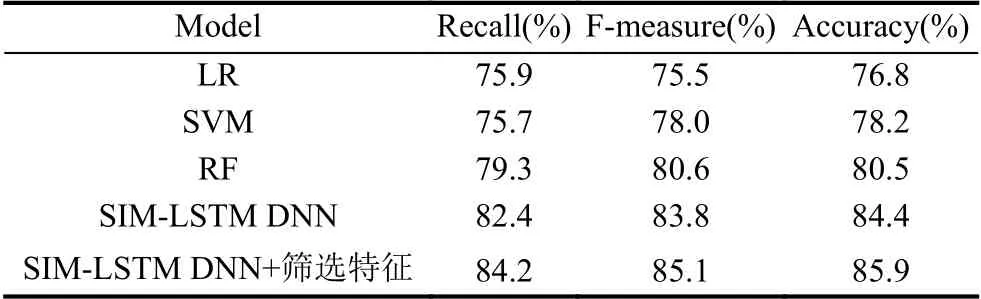
表4 微博转发量级预测结果
5 结语
本文主要是针对社交网络平台(以微博为例)用户微博的转发量级的预测,社交平台的消息传播是通过千千万万个用户转发而实现的,本文首先考虑到近几年我国网络发展迅速,人们的生活水平不断提高,上网浏览微博信息的时长不断增加,使得微博的转发量呈递增趋势,所以提出微博转发趋势度,同时又针对性的利用用户活跃粉丝兴趣与用户微博文本内容的相似度来把微博转发量的预测针对到每一个粉丝的身上. 经试验分析,并取得较好的结果,准确率达85.6%. 此外,本文只是利用微博的特征来对微博的转发量级进行预测,如果可以将微博发布后的一天内的转发数据利用起来,再进行微博最终转发量的预测,那么应该会有更大的提高. 这也为微博预测提供一种新的思路.
猜你喜欢
黄河之声(2022年10期)2022-09-27
舰船科学技术(2022年11期)2022-07-15
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
作文大王·低年级(2022年3期)2022-03-19
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
电子制作(2019年24期)2019-02-23
小学生作文·小学低年级适用(2018年12期)2018-04-11
