
LSTM网络模型在Web服务器资源消耗预测中的应用研究①
2019-08-16 09:10谭宇宁党伟超白尚旺潘理虎
计算机系统应用 2019年7期
谭宇宁,党伟超,白尚旺,潘理虎
(太原科技大学 计算机科学与技术学院,太原 030024)
引言
软件老化是指软件(特别是大访问量、大数据量的服务器软件)在长期不间断地运行一段时间后系统的性能持续下降、占用的资源不断增加、错误不断累积,最终导致软件失效或系统宕机的现象[1].为尽可能地减少甚至避免损失,提高软件的可靠性和可用性,Huang 等人提出一种主动性的容错策略—软件再生技术[2](Software Rejuvenation,SR),通过周期性地清除老化状态,使得运行环境恢复正常,从而避免因软件老化引起突发性失效.尽管通过抗衰操作可以消除软件老化带来的影响,然而对一个正常运行的系统执行抗衰操作势必会带来直接或间接的损失[3],因此如何能够准确地对软件老化趋势进行预测,并及时采取相应恢复策略是当前预防软件老化的研究重点.
目前对于软件老化趋势的预测主要是对影响软件系统相关参数的资源损耗进行分析.梁佩[4]使用时间序列分析法以及马尔可夫模型对软件老化的资源消耗进行预测;苏莉[5]等人使用非线性有源自回归网络模型来检测软件系统的老化现象;Jia[6]等人则使用多元线性回归算法来分析和预测软件老化问题;渊岚[7]则建立了一个基于AdaBoost 算法的BP 神经网络模型来预测资源的消耗.尽管很多学者使用回归分析法、时间序列法以及BP 神经网络算法等方法来预测遭受软件老化影响的系统资源消耗情况,然而已有的单一模型很难达到理想的预测效果[8],因此文献[8]提出使用混合模型,即将自回归累积移动平均模型(Autoregressive Integrated Moving Average Model,ARIMA)和人工神经网络结合来预测Web 服务器中的资源消耗.然而混合方法的构建过程复杂、人工依赖性强,不利于在实际中推广和使用.
近年来,随着深度学习技术的不断发展,越来越多的深度学习模型逐渐被应用到各个领域.深度学习模型是一种拥有多个非线性映射层级的深度神经网络模型,能够对输入信号逐层抽象并提取特征,挖掘出更深层次的潜在规律[9].其中循环神经网络(Recurrent Neural Network,RNN)模型在结构设计中引入了时序概念,在学习具有内在依赖性的时序数据时能够产生对过去数据的记忆状态,能从原始数据中获取更多的数据波动以及规律性特征,它的诞生解决了传统神经网络在处理序列信息方面的局限性.作为近年来深度学习领域热点技术之一,在机器翻译、语音识别及图像识别领域都取得了巨大成功[10],然而在软件可靠性领域对于资源消耗的预测目前还未发现展开过相关研究.
基于上述分析,本文提出了一种基于LSTM 的Web 资源消耗预测模型,该模型充分考虑了Web 资源损耗的时间特性,将当前的资源损耗情况动态的与历史数据相关联并将其与传统模型进行实验对比.结果表明该资源消耗预测模型在处理老化数据的时间序列建模问题上预测精度更高,能够有效地应用于软件老化趋势的预测.
1 模型原理
1.1 循环神经网络
RNN 是一类由各神经元相互连接形成的有向循环人工神经网络,其基于时序展开后的结构如下图1所示.与传统的前馈神经网络(Feedforward Neural Network,FNN)不同,RNN 不仅通过层与层间的连接进行信息的传递,而且通过在网络中引入环状结构,建立了神经元到自身的连接.每一步的输出不仅包括当前所见的输入样例,还包括网络在上一个时刻所感知到的信息即当前时刻的ht不仅仅取决于当前时刻的输入xt,而且与上一时刻的ht-1也相关.

图1 按照时序展开的RNN 结构图
简单的循环神经网络由1 个输入层、1 个隐含层以及1 个输出层组成.给定输入向量序列x=[x1,x2,…,xT],通过迭代下列公式(1)首先计算出t=1 至t=T的隐含层状态序列h=[h1,h2,…,hT],然后根据公式(2)计算出输出序列o=[o1,o2,…,oT].

式中,U为输出层到隐含层的权重矩阵;W为隐含层到隐含层的权重矩阵;V为隐含层到输出层的权重矩阵,f和b分别表示输入层到隐含层的激活函数以及偏置,g和b分别表示隐含层到输出层的激活函数以及偏置.相比于FNN 需要n个时刻来帮助学习一次权重,RNN 可以用n个时刻学习n次W和U,实现了在时间结构上的共享特性.
将式(1)带入式(3)可得:
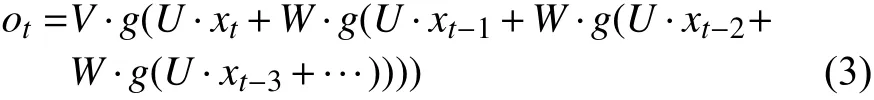
由式(3)可知循环神经网络在计算过程中虽然加入了上一时刻的输入,但随着时间的推移,后面节点对前面节点的感知能力下降,即RNN 存在梯度消失问题.
1.2 长短时记忆单元
与传统RNN 结构相比,LSTM 在其基础上增加了一个细胞状态(cell state).在传递过程中,通过当前输入、上一时刻隐藏层状态、上一时刻细胞状态以及三个基于Sigmod 函数的门结构来增加或删除细胞状态中的信息,其具体单元结构如下图2所示.其中门结构用来控制即时信息对历史信息的影响程度,通过线性积累,使得网络模型能够较长时间保存并传递信息[11].

图2 LSTM 单元结构图
一个典型的LSTM 单元共有三个门:遗忘门、输入门以及输出门[12].其中遗忘门和输入门主要用来控制上一时刻细胞状态Ct-1以及当前输入新生成的中有多少信息可以加入到当前的细胞状态Ct中来,通过遗忘门和输入门的输出,更新细胞状态,输出门基于更新后的细胞状态输出隐藏状态ht,各门计算公式如式(4).

其中:ft、it、ot分别表示遗忘门、输入门、输出门的结算结果;Wf、Wi、Wo分别为遗忘门、输入门、输出门的权重矩阵;bf、bi、bo分别为遗忘门、输入门、输出门的偏置项.最终的输出由输出门和单元状态共同确定,具体计算公式如式(5)所示.

式中,xt为t时刻输入的单元状态;Wc为输入单元状态权重矩阵;bc为输入单元状态偏置项;tanh()为激活函数,⊙表示hadamard 乘积.
1.3 LSTM 预测模型具体构建过程
Web 服务器资源消耗预测就是根据前t时刻老化指标的资源使用特征来预测t+1 或者t+x时间内的资源损耗,以此判断Web 服务器的老化状况.因此通过使用老化数据对LSTM 神经网络进行训练,构建基于LSTM 网络的软件老化资源预测模型,其具体构建步骤如下所示:
(1)首先将原始老化数据清洗后进行特征表示和特征提取:定义老化资源损耗时间序列F={f1,f2,…,f},将其划分为测试集Ftrain={f1,f2,…,fm}和训练集Ftest={fm+1,fm+2,…,fn},其中m<n且m,n∈N,对Ftrain集合中的元素max-min 标准化,处理后的训练集表示为式(6).
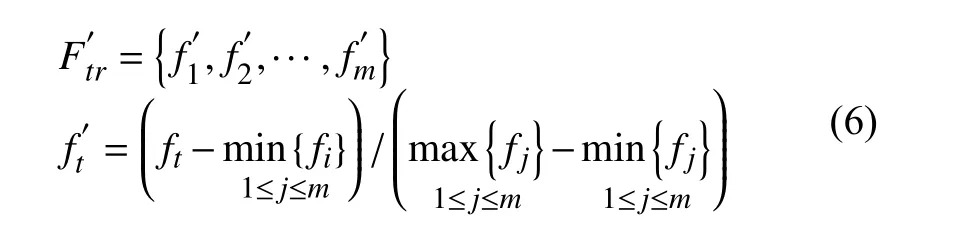
(2)构建训练输入以及对应的训练输出:对数据集进行时间融合,按照滑动窗口的大小s 进行分割,则模型输入、输出分别变为式(7)、式(8).通过设置s 的值,旨在训练LSTM 网络学习样本数据前后的关联及规律.
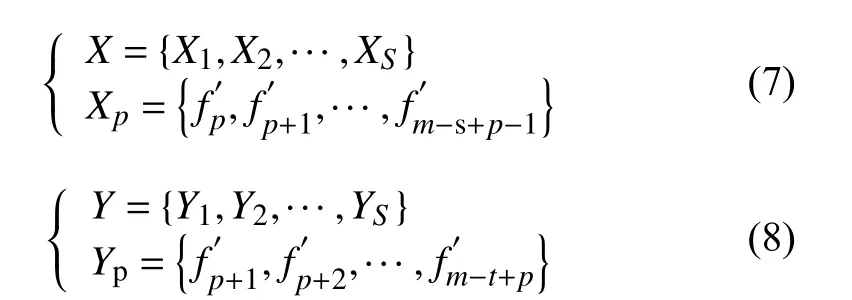
(3)确定网络结构并初始化LSTM 网络:确定每层激活函数的选择、每层网络节点的舍弃率以及误差计算方式、权重参数迭代的更新方式.给定初始权值矩阵,设置最大迭代训练次数和最小误差值,通过改变网络的各项参数来训练网络.
(4)前向计算:将X输入网络,根据前向计算公式(4)-(5)计算遗忘门、输入门以及输出门的值,经过隐藏层后的输出结果可表示为:其中CP-1和HP-1分别表示上一个LSTM 细胞的状态以及隐含层的输出.

(5)误差反向传播:采用批量梯度下降算法对训练数据进行批次(batch)划分,通过对当前批次的损失函数进行优化,实时调整LSTM 网络的权值和偏置,使网络误差不断减小,既保证了参数的更新又减少了模型收敛所需要的迭代次数.

(6)将训练好的模型用于预测:当迭代次数和最小误差值满足要求时停止训练模型,并将未知的样本数据通过迭代输入模型得到预测序列Pte={pm+1,pm+2,…,pn},并对其进行反标准化处理得到最终预测序如式11.

为评估基于LSTM 的Web 资源消耗预测模型的性能,运用平均绝对误差(Mean Absolute Error,MAE) 和均方根误差(Root Mean Squared Error,RMSE)作为评价指标来衡量模型的预测精度,其计算公式分别如式(12)和式(13)所示.
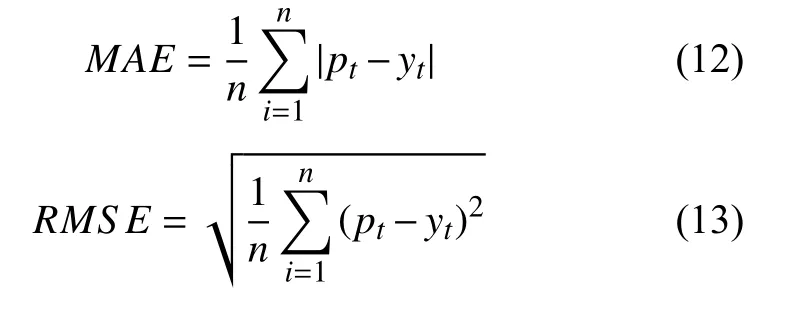
其中,n为Web 老化资源参数的样本数目,pt为老化资源参数的预测值,yt为老化资源参数的真实值或观测值,MAE 和RMSE 越小,模型预测能力越好.
2 实验与结果分析
由于软件老化是一个错误不断累积的过程,一个Web 系统出现老化现象时并不会立刻失效,需要耗费很长时间才能观察到系统故障.当前绝大多数的老化实验只是简单识别老化效应,很难准确把握软件老化的整体趋势[13].因此针对软件老化的特性,本文根据R.Matias 等人提出的系统化方法,将工业领域已成熟应用的加速测试理论[14]引入到软件领域,通过监测软件系统的运行状况,根据采集到的老化数据,建立一个基于LSTM 的Web 资源消耗预测模型.
2.1 Web 软件老化加速寿命实验
为研究因内存泄漏而导致应用程序故障的老化效应,本文以一个典型的Web 应用服务器为研究对象,搭建了一个引入内存泄漏的软件老化测试实验平台.该平台由一个Web 服务器,一个数据库服务器以及一组模拟的客户端组成,具体配置如表1所示.
服务器端实现了一个符合TPC-W 基准测试规范的多层电子商务网站系统.该系统模拟了一个在线售书网站,包括主页、畅销页面、新书页面、搜索页面、购物车和订单状态页面等14 种不同类型的网页,并规定了一系列模拟真实环境下顾客的访问规则.客户端则是一系列模拟浏览器(Emulated Browser,EB),以会话(Session)为单位与服务器端建立逻辑请求,按照上述规则访问服务器.模拟浏览器可以产生三种不同类型的工作负载,分别是Browsing 类型、Shopping类型以及Ordering 类型[15].因Shopping 类型的工作负载处于Browsing 和Ordering 之间,因此本实验客户端主要模拟Shopping 这种类型的工作负载,以随机生成的概率对不同页面进行访问.

表1 实验环境配置描述
内存泄漏是造成软件老化的一个重要原因,因此内存使用情况是衡量软件老化的一个重要指标,通过使用采集到的Java 虚拟机(Java Virtual Machine,JVM) 可用内存对Web 资源消耗进行预测来验证LSTM 预测模型的准确性.为产生软件老化现象,修改了服务器端商品查询请求的TPC-W_search_request_servlet 类,为其注入内存泄漏代码.由于JVM 有垃圾回收(Garbage Collection,GC)机制,任何不再被引用的对象都会被垃圾回收器回收,其占用的内存也会被释放以便新对象使用.为模拟内存泄漏现象,增加了一个HeapLeak 类,使得Tomcat 的整个生命周期保持对该类HeapLeak 对象的引用,HeapLeak 对象在程序运行期间不会被垃圾回收器回收.修改JVM 堆内存的配置(表2),使实验在受控环境下进行操作.由于Java 堆存的是对象实例,所以当创建的对象实例数量达到最大堆容量限制后会造成堆溢出.
运行客户端,每隔1 秒采集一次JVM 内存使用量,实验持续14 400 s,共4 个小时,采集到样本14 400 个.每30 s 取一次均值,得到实验数据(图3).
2.2 LSTM 资源消耗预测建模
本文使用Keras 框架搭建并训练LSTM 预测模型,所使用的网络主要由循环层(Recurrent)中的LSTM 层和全连接层(Dense)组成.取前9650 个点(真实时间近似2.6 个小时)对未来4750 个点(真实时间近似1.4 小时) 进行建模预测,即使用67% 的数据作为训练集,33%的数据作为测试集.根据2.3 节提出的模型具体构建过程对标准化后的JVM 内存序列建立一个含30 个隐藏神经元的单层LSTM 老化资源消耗预测模型,根据网格搜索参数寻优法确定模型参数,设置迭代次数epoch=20,batch=10,time steps=10,lr=0.001,损失函数为MSE.采用Adam(Adaptive Moment Estimation)算法对lr 进行优化,利用梯度的一阶矩和二阶矩估计动态调整每个参数的学习率,使得lr 平稳迭代,模型参数有效更新.由于深度神经网络含有多个网络层以及大量参数,为防止模型发生过拟合现象,采用Dropout对数据进行正则化处理即在每轮权重更新时随机选择隐去一些节点,从而限制模型单元之间的协同更新[16].该模型使用的Dropout 为0.5,即含有Dropout 的网络层在训练过程中,会有50%的节点被抛弃.

表2 JVM 堆内存配置描述
2.3 实验分析
为验证LSTM 模型在循环神经网络中的优势,将LSTM 中的隐含层单元替换为RNN 结构,按照上述相同参数进行实验,结果如图4所示.该图从整体上反映出了RNN 以及LSTM 资源消耗预测模型的预测能力,其中实线表示真实值,虚线表示测试值.由图4可知两种预测模型测试值与真实值接近,预测趋势与实际资源消耗趋势基本一致,对于出现较大波动处的点也有较好的拟合,说明RNN 以及LSTM 模型能有效地对软件老化趋势进行预测.

图3 实验数据
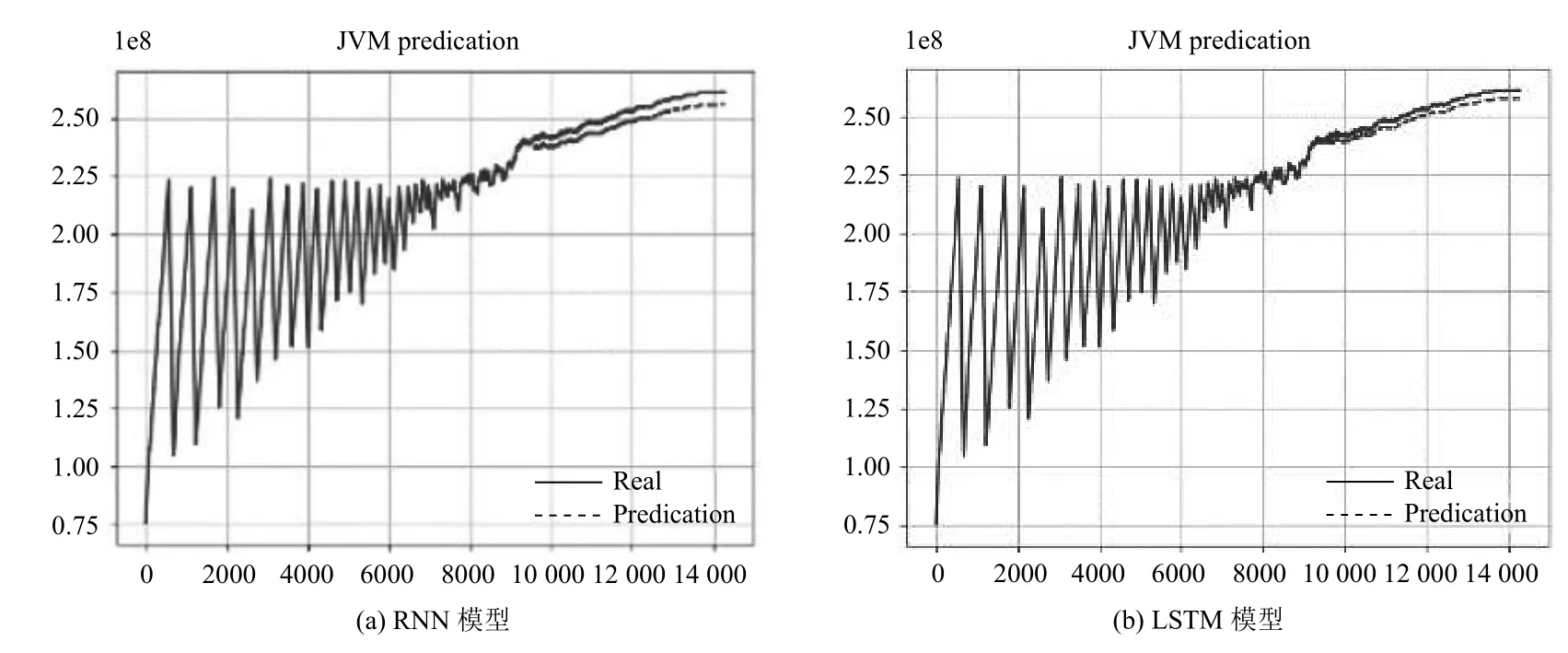
图4 实验预测结果图
由2 种模型对应的损失函数图5(a)、5(b)可知:在老化资源时序预测问题上,相比于RNN,LSTM 算法训练过程相对稳定,测试集上的误差波动较小.
为进一步验证LSTM 的预测能力,将其与传统预测方法:ARIMA 以及BP 神经网络做对比,实验结果如下图6所示,由图可知LSTM 模型的拟合程度更好.通过对3 种不同预测模型的评价指标进行对比,由表3可知,采用LSTM 网络预测算法在预测Web 老化资源时,预测精度明显高于其他两种算法.

图5 实验损失函数图

图6 实验对比结果预测图

表3 预测精度对比
3 结束语
软件老化是影响软件系统可靠性的重要潜在因素,本文以一个典型的Web 应用服务器为实例,通过随机注入内存泄漏的方式设计加速寿命测试实验来加速系统老化过程,根据获取的老化数据构建了基于LSTM 的Web 服务器资源消耗预测模型.结果证明该预测模型与Web 服务器资源老化趋势一致,拟合度很高,能准确地描述软件老化现象.与ARIMA 以及BP神经网络相比预测度高、泛化能力好、误差较小,说明LSTM 网络模型能够很好地描述Web 服务器资源的动态、非线性变化规律,适用于老化参数的时间序列建模.
猜你喜欢
昆钢科技(2022年1期)2022-04-19
昆钢科技(2021年6期)2021-03-09
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
智富时代(2016年12期)2016-12-01
智富时代(2016年12期)2016-12-01
英语学习(2016年1期)2016-09-10
Coco薇(2016年2期)2016-03-22
Coco薇(2015年3期)2015-12-24
电脑爱好者(2015年21期)2015-09-10
