
基于LDA模型的网络刊物主题发现与聚类
2019-08-14 11:09:56杨传春张冰雪李仁德
上海理工大学学报 2019年3期
杨传春, 张冰雪, 李仁德, 郭 强
(1. 上海理工大学 复杂系统科学研究中心,上海 200093;2. 上海理工大学 MPA教育中心,上海 200093)
快速发现和获取网络中的目标信息是自然语言处理、机器学习、人工智能等领域内的研究热点。文本的主题是目标信息的重要载体,获取主题信息是实现准确定位的重要途径。不同的网络数据和处理要求,其发现算法一般有差异[1-3],但大多是基于LDA(latent Dirichlet allocation)生成模型实现的一种统计方法,该方法可以挖掘文本内词与词之间的语义联系[4]。在此基础上进行的文本聚类能有效地对文本内潜在的主题进行提炼和划分,从而实现缩小查找范围、快速准确定位目标信息的目的。
生成模型的显著优点是,不需要预先对文本进行归类或标记,具有无监督的机器学习特点。文献[5]对具有规范语言特点和明确关键词的社科文献进行了主题建模,提出了主题引导词库的概念;文献[6]把文本聚类应用于查新系统,进行了主题挖掘实验,并对实验效果进行了自评;文献[7]则对新浪平台的微博网络社区进行了主题发现,以微博的主题分布作为衡量微博主题在用户中影响力大小的依据。
近年来,在线网络教育内容呈现出爆炸式增长,其巨量数据的生成与维护成为在线教育吸引大众的重要资源。本文基于LDA文本生成模型,对一个开放的在线教育机构网络刊物进行主题发现与聚类研究,提出了主题发现和聚类的流程,对层次聚类文本距离的算法作出了改进,提出了合并向量算法(union vector method,UVM)。
1 LDA主题模型
1.1 模型概述
LDA生成模型简称LDA模型,是挖掘文本集内文本主题潜在关系的算法,它模拟文本的生成过程。文本的主题发现与文本的生成是个互逆过程,文本的主题发现是从文本中发现词项描述的主题,以及不同主题间的关联,同一文本可以有多个主题;文本的生成是根据主题,从词库内选用与主题相匹配的词项来构成文本。两者的路径相反,通过先验参数,LDA模型实现了文本生成逆问题的解决方案。
假定要生成包含M篇文本的文本集,文本集的内容与K个主题相关,每个文本所用的词项均来自于同一个包含V个元素的集合。文本生成过程如下[8]:
步骤1 生成文本的主题分布Θ,分布的维度为M×K,如图1所示。

图 1 文本-主题分布Fig.1 Doc-topics distribution
图1 中的通项pmk(m≤M,k≤K)为第m篇文本选择主题k的概率,每行的概率和为1。文本-主题分布服从狄利克雷分布Dir(Θ|α),α为先验参数,又称超参数。文本的主题分布服从多项式分布Mult(ϑ),依据该分布选择概率值最大的主题。
步骤2 生成主题-词项分布Ф,分布的维度为K×Nm,Nm为第m篇文本总的词数量,如图2所示。
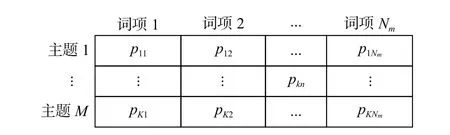
图 2 主题-词项分布Fig.2 Topic-words distribution
图 2中的通项 pkn(k≤K,n≤Nm)为第 k个主题下选中第n个词项的概率,每列的概率和为1。主题-词项分布服从狄利克雷分布Dir(Φ|β),β为先验参数。主题下的词分布服从多项式分布Mult(φ),依据该分布选择概率值最大的词项wj。
步骤3 迭代上述过程,直至产生文本集。
1.2 模型的数学原理
词袋(bag of words,BOW)中有V个独立同分布的不重复词,取N个词生成一篇文本(文本可取重复的词),由每个生成后的词在文本中出现的概率,反过来便可得到文本W的生成概率为

图3中的矩形表示框内相应变量n,m,k的作用域;阴影圆圈内的值表示实验中是可以被观测到的已知量,矩形框内无阴影圆圈表示隐含变量;矩形框外的值表示先验参数,即狄利克雷分布的超参数,需在实验前预先给定;φk的箭头穿透了2层矩形框指向,表示生成该词项前有一个文本到主题和先验参数β到主题的混合过程。图中各量及其他相关符号含义见表1。
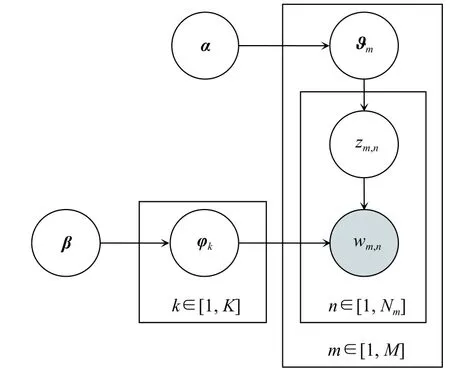
图 3 LDA混合生成模型Fig. 3 Model of LDA hybrid generation
文本集中第m篇文本的生成过程可分为两步[9-10]:a. 由先验参数α获得文本的主题分布,选取主题;b. 由先验参数β获得每个主题的词项分布,选取词项。因此,LDA模型文本生成过程可以看成3层条件概率过程。

表 1 使用符号及其含义Tab.1 Symbles and meanings used
第一层:基于主题概率的生成过程。第m篇文本中词项t的生成概率可表示为

第二层:混合层,基于主题概率和基于文本概率的生成过程。第m篇文本的生成概率为文本-主题概率与主题-词项概率的乘积

式中,φk的取值由中的主题值k确定。第三层:基于先验参数的生成过程。文本集的生成概率等于每篇文本的概率积
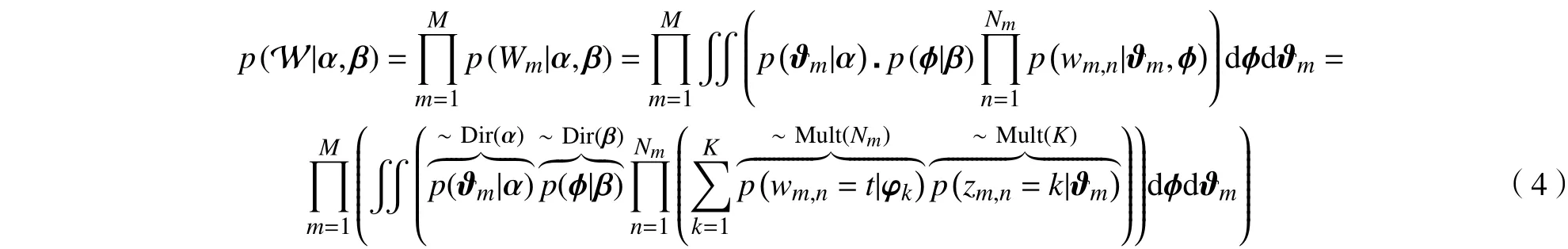
1.3 吉布斯采样
LDA模型在概念上很简单,但要实现求解就有很大困难,一般采用近似计算完成,吉布斯采样是完成模型计算的一个理想方法,它可以消除先验参数值对结果的影响。吉布斯采样是对马尔科夫链蒙特卡洛法(Markov-chain Monte Carlo,MCMC)的一种模拟,通过马尔可夫链的平稳态来模拟高维分布,某时刻xi的值只和生成xi之前的状态 x¬i=(x1,x2,…,xi-1)有关(¬i表示不包含i状态),即

式中:x={xi,x¬i};z为隐含变量。
LDA模型中,文本-主题分布Θ和主题-词项分布Φ均是隐含的变量。它们包含在由两个先验超参数确定的联合分布p(w,z|α,β)中,文本主题分布和主题词项分布是两个独立过程,因此联合分布可分解成两个独立项

其中 p(w|z,β)由下式给出:

布,在整数范围内有 Γ(n+1)=nΓ(n)。式(6)中p(z|α)由下式确定:

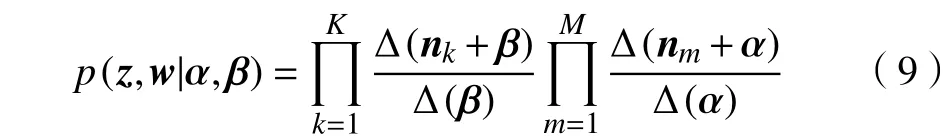
根据式(5)可得主题吉布斯采样更新规则[11]:

最后可获得多项式参数Θ和ϕ的表示,结合多项式分布为狄利克雷的后验分布可得
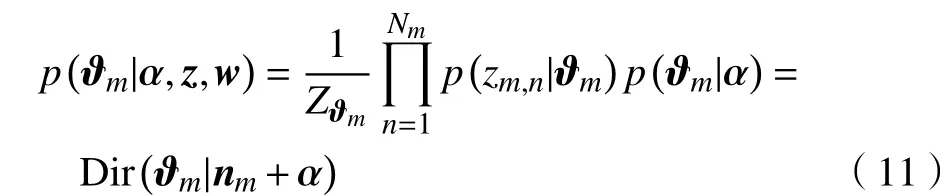
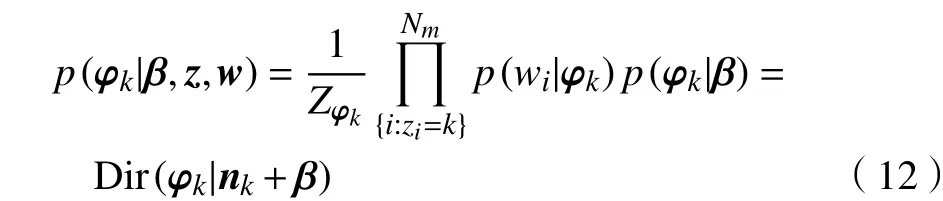
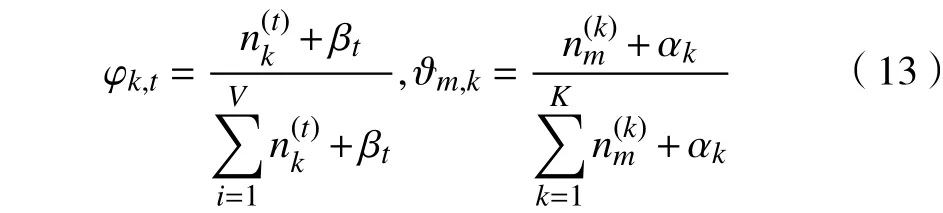
式(9)是LDA模型数学原理的核心,它通过式(7)和式(8)包含了文本-主题分布和主题-词项分布,文本主题发现的信息就集中在这两个概率分布中。然而由该式计算出来的结果具有不确定性,因为式中包含有先验参数成份,因此需要不断迭代以获得稳定的文本-主题分布和主题-词项分布,这两个分布更新规则通过吉布斯采样求得的式(13)确定,这样LDA生成模型就确定下来了。
1.4 困惑度
评价LDA生成模型质量的标准一般用困惑度表示,困惑度的定义为[8]

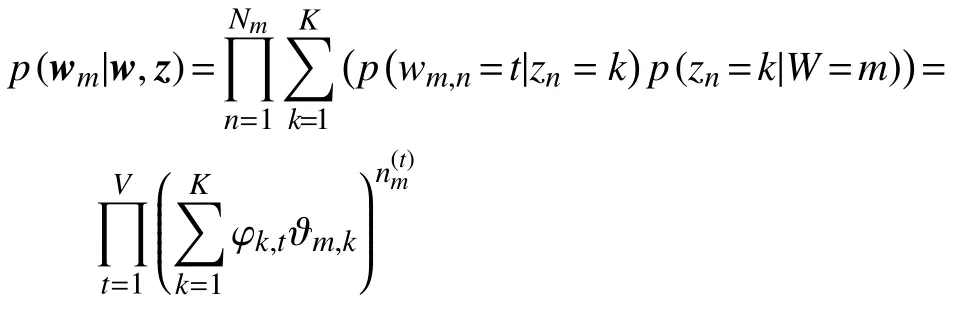
由此可得,

2 聚 类
2.1 TF-IDF
文本的聚类就是挖掘文本的相似性,是以描述文本的主题信息为基础的,信息重要性的度量常用TF-IDF算法[12]。不同的词在文本中出现的次数一般不同,可以用词项在文本中出现的次数词频(term frequency,TF)表示。文本集中文本数量除以包含某个词的文本数量叫逆文本频率(inverse document frequency,IDF),该值越大,表示词项在文本集内具有一定的“独特性”。
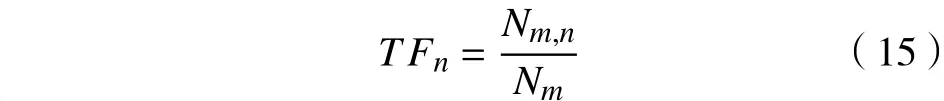

式中:分子Nm,n表示第m篇文本中第n个词在该文本中出现的次数;分母Nm表示第m篇文本中所有词项的数量和。逆文本频率为式中:M为文本集中文本的总数量;分母表示包含第n个词项wn的文本数量。两者的比值取对数是为了平衡TF和IDF对同一词项wn的影响。
2.2 文本距离
文本距离用来反映文本的相似程度,距离越小表示文本越相似。要实现文本距离的计算,先要实现文本的计算表示,向量空间模型(vector space model,VSM)就是把文本语义的相似度简化为空间向量运算的模型[13],它以词袋为基础,把文本的每个关键与词袋对比,赋予一个正实数值,使每篇文本构成一个多维空间向量,从而实现数据的计算表示。文本间距离的度量常用的有余弦相似度和杰森-香农距离(Jensen-Shannon distance,JSD)[14],两者都具有对称性。余弦相似度的定义为
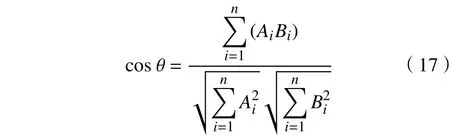
余弦相似度为零,表示两个向量无语义关联性;相似度越接近于1,表示文本越相似。JSD的定义为

3 实验过程与结果分析
本实验的主题发现和聚类流程如图4所示,实线箭头所指的方向为实验时间顺序和步骤,虚线所指表示需要的相关算法或技术路线。
3.1 数据抓取与清洗
通过分析在线教育机构的网页特点,利用python语言的urllib,urllib2模块和正则表达式制作爬虫程序,匹配目标字段抓取数据,共取得了2 794篇网络刊物的名称、分类和概述3个字段值。刊物内容涉及学习和兴趣的各个方面。

图 4 文本聚类流程和技术路线Fig. 4 Text clustering process and technical route
由于页面中存在着大量不规范的词语,抓取下来的数据无法被直接利用,必须进行词语替换、去污和深度清洗,仅保留简体中文数据。通过建立非目标字符库,构造字符过滤器,把文本集中的数据与过滤器字符库逐一对比达到清洗的目的。采用开源的结巴(Jieba)分词算法,对文本集的全部语句进行分词便可得到需要的数据。
3.2 数据表示与建模预处理
清洗后的词项构成了实验的文本集,通过去重建立词袋,将词袋与每篇文本所含词项对比,构造包含0与1的多维向量空间,1表示文本与词袋有映射关系,0表示文本内没有该词。每个文本对应一个向量,向量的分量按词袋内词的顺序排列,形成1110010101…10结构序列,序列长度等于文本内词项总数。计算各词的TF-IDF值,用其置换向量序列内的1,实现向量的计算表示。
计算文本间的余弦相似度,如图5所示,它反映了不同余弦相似度随文本数量变化的关系。随着余弦值的增加,具有相似性的文本数量逐渐减少,没有完全相同的文本(cosine=1),其中的子图是母图文本数量归一化后的情况。

图 5 余弦相似度与文本数量关系Fig.5 Relation of cosine similarity and text quantity
3.3 主题建模
LDA模型的输入值有,自定义主题数量K(60~440)、文本主题分布的超参数α=0.01、主题词项分布超参数β=60/K,模型迭代的次数为1 000次;模型的输出有文本主题分布Θ、主题词项分布ϕ,以及词袋与自定义特征整数间的映射表,该映射表并非必须,但通过它易于人机交互计算建模。
利用先验参数和文本集对模型作持续训练,同时以20为步长改变主题数,得到困惑度变化如图6所示。数据显示,当主题数为320时,模型困惑度最小,表明模型此时的生成效果最好;K>320时,模型的困惑度基本保持不变,这有可能是模型陷入了局部极小值的原因。困惑度最小意味着主题生成的概率最大。
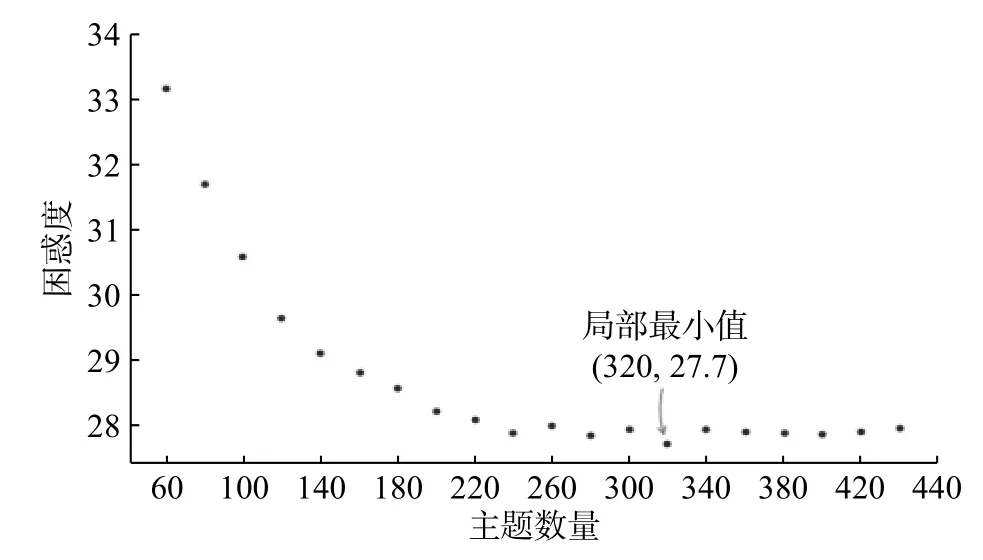
图 6 困惑度Fig.6 Perplexity
表2显示了主题数K=320时,模型提取出的前4个主题和相应的生成概率。可以看出每个主题的关键词聚焦的内容语义边界非常明显,表明LDA模型挖掘出了文本主题间的内在联系。与之对比,当主题数目K=80时,模型提取的前4个主题和相应的生成概率如表3所示。此时,主题的关键词之间有些模糊,主题边界出现了交叉现象,交叉词语已用下划线标出。这种情况有可能是模型在进行数据采样时,未进入平稳态程序就已经结束。实验表明,当迭代次数增加到2 000次时,模型输出的主题结果并未改变,说明即使迭代只有1 000次时,模型事实上已进入了采样的平稳态。因此只能表明,如果把全部在线网络刊物的内容归纳到现有的主题数目时,主题定位将不再清晰,需要进一步细分或者放大主题内涵才能确定更清晰的主题边界。
3.4 层次聚类及评价
聚类时,将每个刊物作为一个独立的簇,计算两两文本之间的距离,并设定距离阀值簇的容量,依次合并不同的簇,合并后的簇以簇内所有样本点的距离平均值作为迭代计算的依据,反复迭代直到最后所有簇均被合并[15]。这一算法只有在能定义簇平均值时才有意义,其时间复杂度为O(nmkt),其中n为数据点的数目,m为数据点的维度,k为簇的数目,t为迭代次数[16]。
本实验中,合并以后的簇采用簇内各数据点向量的并集来表示簇,并以此计算簇间的距离,该算法称之为合并向量算法(UVM),算法的伪码如表4所示。
UVM算法与文献[15]算法随词袋中词项数量的性能对比如图7所示。
聚类结果如图8所示,横轴为各个刊物的序号,纵轴为向量间的欧几里德距离。最后15步的聚类如图9所示,横轴上带括号的数字表示该聚类叶子包含的刊物数量,未加括号的表示刊物序号。从图9可以简单统计出,最后一步的聚类中,两个分支的刊物数量分别为4和2 790,表明全部刊物的主题总体上比较集中,有利于用户在相应主题下通过聚类层次图向下找到更为确切的主题,实现主题定位。但是,平台主题的过度集中,也暴露出刊物数量相对于内容的冗余,如果平台能对主题相似度较大的刊物进行归并,适当缩减刊物数量,精炼刊物主题,不仅能增强不同刊物在用户使用中的辨识度,也可以节约大量的平台人力维护成本。

表 2 主题和词项的概率(K=320)Tab.2 Probability of topics and items(K=320)

表 3 主题和词项的概率(K=80)Tab.3 Probability of topics and items(K=80)

表 4 UVM算法伪码表示Tab.4 Representation of pseudo-code of UVM algorithm

图 7 UVM算法性能Fig.7 UVM algorithm performance

图 8 全部刊物层次聚类图Fig.8 Cluster graph of total journals
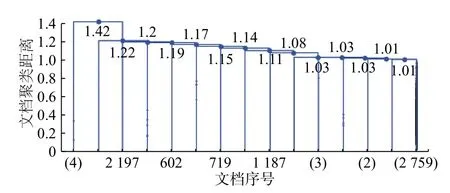
图 9 最后15步聚类图Fig.9 Graph of last 15 steps
4 结束语
对在线网络教育平台的刊物进行了主题发现和聚类研究。实验数据通过爬虫获取,提出了主题发现和聚类的一般流程,通过对数据的清洗、生成词袋、计算TF-IDF值和向量空间模型的表示等为主题建模提供了有效数据。以LDA生成模型为基础,完成了对2 794个刊物的潜在主题的发现,以文本的关键词为基础,利用层次聚类模型进行了主题聚类工作,并提出了新的合并向量算法(UVM算法)。
实验中2 794篇文本中包含3 800左右的关键词,聚类难度相当大。实验中采用了分步聚类方法,先用kmeans算法聚类成320个主题,再进行层次聚类。结果表明,合理的聚类有助于用户快速发现目标信息,在线教育机构亦需要对刊物内容和刊物构成进行适当的优化。
本实验研究的不足之处是文本的层次聚类算法中距离的计算方法,这也是目前聚类算法面临的系统性难题。在计算距离时,无论是采用余弦距离、欧几里德距离还是香农距离等都无法避免极端情况下,距离数值相等或相近引起结果可能出现的大偏差。如表5所示,向量1与向量2、向量2与向量3......向量n-1与向量n的“距离”是相等的,在进行簇合并时,它们将会被归为同一簇。事实上,向量1和向量n在语义上可能根本没有相似性,因此,对聚类距离的研究值得继续深入。

表 5 向量在极端情况下的分布Tab.5 Distribution of vectors in extreme conditions
猜你喜欢
飞天(2020年10期)2020-10-26 02:23:39
成都信息工程大学学报(2019年3期)2019-09-25 08:31:14
中国外汇(2019年21期)2019-05-21 03:04:06
哲学评论(2018年1期)2018-09-14 02:34:18
自动化学报(2017年5期)2017-05-14 06:20:44
中国工程咨询(2017年5期)2017-01-31 03:03:26
快乐语文(2016年29期)2016-02-28 09:03:34
探测与控制学报(2015年4期)2015-12-15 15:00:56
东南法学(2015年2期)2015-06-05 12:21:36
上海理工大学学报(社会科学版)(2011年4期)2011-09-26 11:01:32
