
面向智能电网的大数据降维管理方案
2019-08-13 09:26彭姣刘明硕杨力平
计算技术与自动化 2019年4期
彭姣 刘明硕 杨力平

摘 要:针对智能电网数据繁多、维度较高、难以识别的技术问题,提出了降低大数据维度的构想,并设计出基于随机森林算法的物联网智能电网大数据管理系统。通过采用Bagging算法对数据样本训练、学习,建立起多个决策树构型,根据少数服从多数的投票法原则确定建立决策树的节点和分支,最终建立起成熟的随机森林算法模型,通过随机森林算法模型将智能电网中的大数据从高纬度降低到低纬度。本设计的方案大大减小了大数据处理难度,优化了数据处理的效率,增加了分析问题、解决问题的有效途径,为智能电网的健康、有序运行提供有力保障。
关键词:智能电网;维度;Bagging算法;随机森林算法;决策树
中图分类号:TP39 中图分类号:A
Big Data Dimension Reduction Management Scheme for Smart Grid
PENG Jiao?覮,LIU Ming-shuo,YANG Li-ping
(Information & Telecommunication Branch,State Grid Hebei Electric Power Co. Ltd.,Shijiazhuang,Hebei 050000,China)
Abstract:Aimed at the technical problems such as much data,high dimension,difficult to identify in smart grid data,the idea of reducing the big data dimension is proposed,and the big data management system of the Internet of Things smart grid based on random forest algorithm is designed. Multiple decision tree configurations are established by using the bagging algorithm to train and learn data samples,according to the minority majority voting principle,the nodes and branches of the decision tree are determined,and finally the mature random forest algorithm model is established,and the big data in the smart grid is reduced from high dimensionality to low dimensionality via the random forest algorithm model. The scheme designed in this paper greatly reduces the difficulty of big data processing,optimizes the efficiency of data processing,and increases the effective way of analyzing problems and solves problems,as well as providing powerful guarantee for the healthy and orderly operation of smart grid.
Key words:smart grid;dimension;Bagging algorithm;random forest algorithm;decision tree
智能电网是以物理电网为基础,将现代先进的传感测量技术、通信技术、信息技术、计算机技术和控制技术与物理电网高度集成而形成的新型电
网[1-4]。随着云计算、物联网技术的广泛应用,大数据已经涉及各行各业[5-6],在智能电网行业中,由于产生的各种数据繁多,如何从大量数据中提取有效信息已成为智能电网应用过程中的重要研究课题[7]。在智能电网行业中,浩瀚的大数据往往由于数据量太大、维数太高而在具体实践工作中,给供电企业、用户都带来极其不便。在大数据应用中,维度越高,计算数据的复杂程度也就越高,发现隐藏在数据之间的逻辑关系以及隐藏的问题也就越难发现。
随着信息技术的不断进步,用户越来越多地发现降低数据维度不仅仅能够大大降低数据获取的成本,还能够提高数据分类的精度,更为重要的是,能够发现肉眼看不到的深层含义,这对于解决智能电网运行中出现的各种问题极其有利。随着图像处理技术的发展,这一块技术领域得到更深刻的研究。用户可以通过图像处理技術提取图像中蕴含的数据问题,对问题的分析更为透彻,使用户面对智能电网中存在的问题时,能够从更为本质的意义上获取问题存在的根源。由于大数据时代的到来,各种数据正以迅雷不及掩耳之势的速度强势增长,为了减低企业的运行成本,提高智能电网应用的大数据系统的业务能力,保证大数据的配网运营能力正常、有序、健康地发展,就有必要研究一种降低智能电网大数据维度的方法。基于此,本文针对这一课题进行了研究。
1 方案构架设计
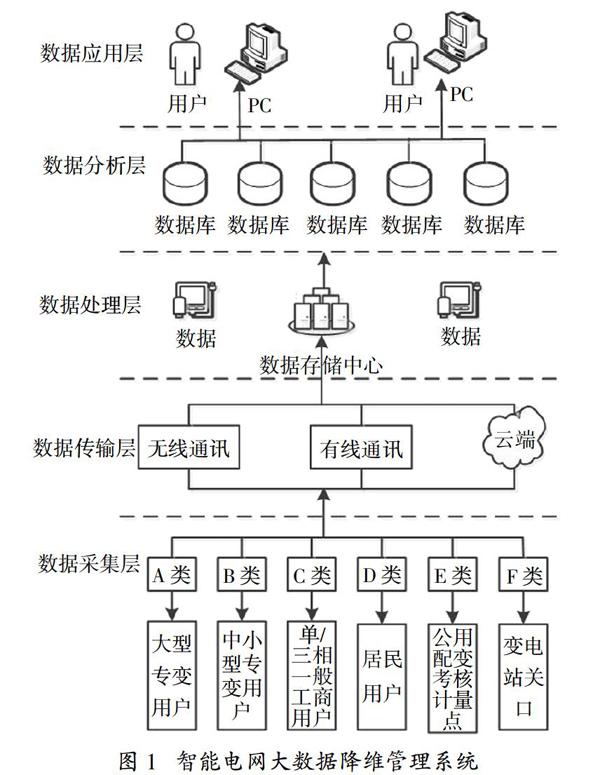
智能电网是聚集发电、输电、变电、配电、用电和调度等各个环节的综合电网,其结构繁杂,数据库浩大。在用户获取大量的高纬度数据库时,难以对其有直观的认识,难以发现数据之间隐含的关系。通过降维则可发现肉眼无法发现的规律,有利于用户对智能电网数据分析和研究,便于及时解决在低纬发现的问题。在本文设计中,对智能电网的数据进行降维管理的架构大致如图1所示。系统包括数据采集层、数据传输层、数据处理层、数据分析层以及数据应用层,下面对各个层次分别说明。
在数据采集层中,采用TMS320F2812作为运算控制核心,控制电网数据的采集,以IEC61970为智能电网数据采集平台,对各种数据进行采集并实现与上层设备的数据通讯和传递。在该数据采集层中能够实现对A类、B类、C类、D类、E类、F类等的设备进行数据采集,提供直测数据、复制数据和定制数据等服务类型。
在数据传输层,可以采用IEEE C37.118通讯协议实现底层数据采集和数据处理层之间的数据传输和通讯,采用基于TCP/IP的Socket技术完成底层与上层的数据通讯。由于智能电网的数据信息采集涉及面较为广泛,不同的用户出于成本的考虑,也会采用RS232、CAN和以太网这3种方式将这些数据信息通过数据传输层传递到数据处理层,这也是可行的。在该层中,直接测量出的数据也可以通过上传云端实现数据的永久性存储。
在数据处理层中,数据存储中心接收到底层传递的各种数据。由于数据繁多,类型不等,这对于用户来说,增加了识别难度,应用效率低下。就需要对这些数据进行预处理,从而增加可识别度,提高数据读取质量。通常采用的方法为数据清理、数据集成和转换、数据规约。数据清理主要是填补数据缺失值,使数据噪声平滑,将离散点识别出来,纠正数据中不一致的信息。数据集成和转换主要是对多源数据进行集成,采用大数据机器学习规律和算法对其学习并训练成容易处理的形式,从而更加便捷地发现这些数据之间不容易发现的规律。数据规约主要是在接近或保持原始数据完整性的同时将数据集规模大大减小,使得数据分析更加有效。
在数据分析层中,对电网大数据信息做出减维处理。由于在数据分析层接收到的数据都是经过预处理后的数据,因此,在对数据进行计算时,效率非常高。在本数据层,选用随机森林算法模型对预处理后的数据做进一步的处理。随机森林作为一种特殊的bagging方法应用到智能电网大数据处理能够实现数据的不同分类,增加数据的分类能力,通过用户根据需求设定不同的属性,使用户能够快速从浩瀚的智能电网大数据库中找出期望的数据。具体算法将在下文做进一步的说明。
在数据应用层中,用户根据计算的结果直接可用到各种用途。数据应用层可以为计算机、计算机用户用户、集成在计算机上的各种应用程序、显示器,在应用层中,能够直接或者间接地向用户提供各种处理后的数据服务,使得用户便利地应用该数据,从而实现从数据采集层到接收的最终处理,用户根据来自底层的数据信息,获知设备底层情况,快速做出干预,有利于智能电网的健康、高效运行。
2 基于算法模型的降维方法
将随机森林算法模型应用到智能电网大数据中,对智能电网大数据降维,使得电网数据的时间复杂度、空间复杂度降低,电网中各种数据集中所夹杂着的繁冗数据和噪声数据被过滤,为电网的健康运行提供较为纯净的工作环境。随机森林是通过有放回的方式从原始样本中随机抽取部分样本产生新的样本集合,重复这样的操作产生多个样本集合,每个样本集合后续都会产生一棵决策树[9-10],下面结合图2对降维过程进行详细说明。
(1)数据选择:在智能电网数据采集层生成的大量数据中,根据用户需求选取样本数据集。
(2)预处理:由于数据集包含大量的不平滑信息,同时包含过多的数据噪声,这些噪声干扰会导致算法存在误差,使得计算不准确,在对数据进行降维时,就需要移除不准确的信息量,或者清除与用户无关的数据。执行不便识别的数据转化为易于识别的规范数据的信息处理过程。在预处理阶段,采用bagging集成学习方法对数据集进行学习,如图3所示。
在学习时,从原始样本训练集合中随机采样固定个数的样本,每采集一个样本,放回一个样本,然后再重新采样,如果对有N个样本训练集做T次的随机采样,则由于采样的随机性,T次采样的结果各不相同,每次结果输出频率最多的数据,则作为最终的数据模型,则将该点设置当前节点为叶子节点。在原始样本训练数据集合中,假设输入为样本集D = {(x1,y1),(x1,y1),...(xm,ym)},第一次输出为是通过弱学习器算法进行输出,即弱分类器,将弱分类器进行迭代T次数,将这些弱分类器叠加,输出为最终的强分类器。
(3)建立随机森林算法模型:根据步骤(2)中训练的强分类器建立随机森林算法模型。利用训练成熟的随机森林模型对预处理后的智能电网数据计算、降维,获得易于用户读取的数据。建立随机森林算法模型的方法如图4所示。
随机随机森林算法对数据集的适应能力强,离散型数据、连续型数据都能处理。在对样本进行采样时,选择随机性采样使得随机森林不易过拟合,并且抗噪声能力较好。建立随机森林的过程是在在决策树基础上进行集成的运算过程,因此在生成随机森林模型时,通过将数据又放回的方式从原始样本数据集中随机抽取部分样本产生新的样本集合,然后重复这样的操作可以产生多个样本集合。此时每个样本集合在最后都会产生一个决策树,在每个决策树产生时,要确定建立决策树的节点,在每个节点进行分支的时候都要随机地抽取部分特征,以确定建立决策树需要的的分支節点,然后根据分支节点逐步递归分支,在递归分支时,每次都需要从剩余的数据特征中随机抽取部分特征,在次确定子分支。在确定了节点和分节点之后,就很容易地生成决策树了,由于在样本训练的时候是针对多个样本集合,因此也对应地生成多个决策树。当决策树达到一定数量时,对建立起来的决策树进行存储。然后判断决策树的数量是否达到用户要求,如果没有达到要求,则需要重新训练、学习,根据少数服从多数的投票法原则确定新输入样本的类别。当达到用户要求时,则生成随机森林模型。
在对智能电网数据降维时,利用上述生成的随机森林模型根据数据降维算法将采集的高维数据降至低维,数据降维的原则是在减少数据列数的同时保证丢失的数据信息尽可能少。首先在完成决策树训练后,计算训练样本数据各个决策树的特征变量的加权信息增益率。也计算随机深林的决策树特征变量的加权信息增益值,再针对二者计算特征的特征重要性(指的是特征变量的信息增益率占全部特征变量的信息增益率的比例),更具体说,假设样本集为十万个数据,对各个样本集的特征变量的重要性值进行降序排列,假设将X降低到x维(X>x),选择前n个重要性数值最大的特征变量,然后从剩下的X-n个特征中随机挑选(x-k)个特征。共同组成x个特征,从而将高维数据从X维降低为x维。
3 实验数据及结果分析
以电能计量为例,选择3种电能表检测装置检测信息作为测试,在每个检测装置中选取5组测试数据作为分析,选取500个样本,测试时间为1秒,在本测试时,已经对样本数据进行了去噪处理。数据样本如表1所示。
表2为任意电能检定装置检测项目N(i,j)表示检定装置中电能表为i但是随机森林模型算法估计为j的样本个数。
在用上文建立的随机森林模型进行测试的结果为表3中的数据,在表3中,真正(TPi)表示样本i被分类模型正确预测的样本数,假负(FNi)表示样本i,假正(FPi)为上述装置外的样本被预测为上述的样本数。
根据测试情况以及相关统计结果可以对建立的随机森林模型进行总体评价,采用的评价公式参见表4。
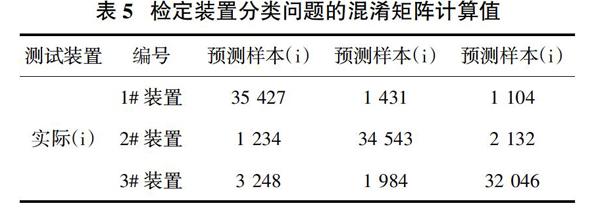
根据上述公式,下面对本文列出的样本数据进行计算,计算结果如表5所示。
根据上述公式,下面利用表4中的公式对本文设计的森林算法模型的正确率进行评估,得出数据如表6所示。
根据上述计算结果,选取的3个检定装置中,召回率别为91.98%、91.09%和87.04%,1#检定装置召回率最高。将这3个检定装置的样本信息经过上述公式运算可得,预测的正确率分别为89.32%、90.91%和91.01%,整个模型的准确率为89.91%,可见本文设计的模型估计的准确率高。
4 结 论
建立随机森林算法模型对智能电网大数据进行降维管理,通过Bagging集成学习方法建立算法模型,使得多个弱分类器训练成强分类器,利用强分类器继续学习、训练,最终建立训练成熟的随机森林模型。通过随机森林模型对智能电网数据降维,有效地剔除與用户关系不大的数据,获得易于用户读取的数据。通过试验分析,本设计的技术方案估计精度达80%以上,准确度高。
参考文献
[1] 卢志翔. 面向智能电网客户大数据的语义关键数据管理算法研究[J].激光杂志,2016,37(2):146—148.
[2] 彭小圣,邓迪元,程时杰,等.面向智能电网应用的电力大数据关键技术 [J]. 中国电机工程学报,2015,(3):503—511.
[3] 王远,陶烨,蒋英明,等. 智能电网时序大数据实时处理系统[J]. 计算机应用,2015,(z2):93—97.
[4] 孙鸿飞,弓丽栋,张海涛,等. 智能电网大数据分析框架及其应用演进研究[J].现代电力,2016,33(6):68—77.
[5] 李佳,徐胜超. 基于云计算的智能电网大数据处理平台[J]. 计算机工程与设计,2018,39(10):81—87.
[6] 张东霞,苗新,刘丽平. 等. 智能电网大数据技术发展研究[J/OL].中国电机工程学报,2015,(1):2—12.
[7] 张根周. 大数据在智能电网领域的应用[J].电网与清洁能源,2016,32(6):114—117.
[8] 葛磊蛟,王守相,瞿海妮. 智能配用电大数据存储架构设计[J]. 电力自动化设备,2016,36(6):194—202.
[9] 贺红燕. 基于大数据的智能电网关键技术研究[J]. 电源技术,2016,40(8):1076—1080.
[10] 彭晖,陶洪铸,严亚勤,等. 智能电网调度控制系统数据库管理技术[J].电力系统自动化,2015,(1):19—25.
猜你喜欢
快乐学习报·教育周刊(2021年34期)2021-09-26
科学与信息化(2019年28期)2019-10-21
福建基础教育研究(2019年12期)2019-05-28
福建基础教育研究(2019年9期)2019-05-28
科学与财富(2016年32期)2017-03-04
科学与财富(2016年28期)2016-10-14
科学与财富(2016年28期)2016-10-14
决策与信息·下旬刊(2013年1期)2013-03-11
