
一种利用半监督学习的在线服务信誉度量方法
2019-08-13 12:38付晓东刘利军昆明理工大学信息工程与自动化学院昆明650500
小型微型计算机系统 2019年8期
张 烨,付晓东,2,3,刘 骊,刘利军,冯 勇,3(昆明理工大学信息工程与自动化学院,昆明650500)
2(昆明理工大学航空学院,昆明650500)
3(云南省计算机技术应用重点实验室,昆明650500)
E-mail:xiaodong_fu@hotmail.com
1 引言
随着互联网技术的不断发展,传统的消费方式发生了巨大的变化.在线服务是指利用互联网技术向用户提供线上服务的方式,因其使用方便、操作简单、成本低廉等优点而受到广泛的欢迎[1].然而,由于存在大量服务功能相同而服务质量(Quality of Service,QoS)不同的在线服务,从而导致用户对选择何种服务难以进行决策.此外,由于网络环境的虚拟性、开放性、动态性以及信息的不对称性,不能保证服务提供者发布的信息都是客观、真实、可信的[2],从而导致在线服务中交易欺诈、网络欺骗等现象频发.信誉作为对服务QoS的综合度量,反映服务履行其承诺服务的水平和其他主体对它的总体信任程度[3],因此,研究一种能够客观度量在线服务信誉的方法可以有效地帮助用户应对交易欺诈并支持用户做出正确的服务选择.
目前在线服务信誉度量领域的研究工作已经取得了很大的进展但依然具有局限.例如,许多在线服务信誉度量模型是单维度的[4],模型仅根据服务交易中的评分数据来度量服务信誉,没有区分交易过程中服务的各属性信息对服务信誉度的影响.而在基于多维度评价信息进行服务信誉度量方法[5,6],仅依据用户对服务的各属性评价信息度量服务信誉,没有考虑服务自身的属性,如服务消费者保障、服务规模等属性对服务信誉度的影响.因此,一种通过综合服务多维度评价信息对服务进行信誉度量的方法可以获得更合理的信誉度量结果.
为解决以上问题,本文提出了一种基于半监督学习的在线服务信誉度量方法.方法以决策树分类器为理论基础,基于Tri-training算法构造服务分类器模型[7],实现综合服务多维度评价信息对服务进行信誉度量.最后,提出半监督随机森林算法训练分类器模型来进一步提升模型的分类性能,实现信誉度量.
2 相关工作
在传统的电子商务中以用户对服务的单维度评分信息来评估在线服务信誉度.常见的信誉度量方法有均值法、累加求和法、概率法等[8,9].Amazon1http://www.amazon.cn/等使用均值法,将所有用户对服务的评分求平均值作为服务的信誉值.EBay2http://www.ebay.com/等网站则将用户对服务的反馈评分进行求和运算得出服务信誉值.文献[10]基于用户对服务的评价获得直接信任值,通过推荐用户获取服务的间接信任值,最后整合直接信任值和间接信任值来计算出服务的信誉.文献[11]提出运用贝叶斯概率的方法,描述信任与信誉以及其之间的关系,并利用历史交易信息进行信誉的计算.文献[12]中提出基于事件驱动和规则驱动的信任管理框架,在此框架中,基于规则确定信誉计算公式和参数.上述研究只是基于服务整体表现做出评价进行信誉度量,没有考虑服务的各个维度属性对服务信誉度的影响,导致信誉度量结果不够客观、准确.
为克服基于单维度评分信息的信誉度量模型的缺陷,文献[13]中从电子商务网站设计的角度对在线服务的影响因素进行研究,指出内容设计、社会因素和结构设计等均影响在线信誉.文献[14]综合服务多维度属性信息,提出使用交易评价体系和评价权重体系体现个人偏好等因素.文献[15]提出了一种基于用户属性的细度化信誉评价体系,在此体系中用户可以评价其他用户的属性,而不对其身份做任何评价,从而避开用户身份对信誉的影响.上述研究通过用户对服务的评分进行信誉度量,提高了服务信誉度量的有效性与准确性,但对服务的信誉度量仅考虑用户对服务各属性的评价信息,没有考虑服务自身的属性信誉,如服务消费者保障、服务规模属性等对服务信誉度的影响.
考虑到以上研究中存在的不足,本文提出一种综合考虑服务的用户评价信息、服务自身属性信息、历史交易信息等多维度信息的在线服务信誉度量模型.模型将服务信誉度量建模成对服务的分类问题,人工标注少量服务样本作为训练集,通过半监督学习算法利用大量未标注服务样本训练服务的分类器模型.该模型以 C4.5 决策树(Decision Tree,DT)[16]为基础,首先利用人工标注的服务样本训练3个不同决策树分类器模型;然后基于Tri-training协同训练算法不断对未知服务进行预测[7],并将所预测服务连带预测结果加入到训练集重新训练分类器.为防止Tri-training的过拟合,提出半监督随机森林算法[17],可以有效提升分类器分类性能并用所得分类器对服务进行分类实现信誉度量.最后,本文通过实验验证了方法的合理性与有效性.
3 问题描述
本文研究如何依据在线服务的多维度属性信息实现服务信誉度量,而信誉度量可视为对服务不同信誉类别的划分,所以将服务信誉度量问题建模成对服务的分类问题.以下先对问题进行形式化描述.
定义 1.(在线服务集)S={s1,s2,…,sm}为服务的有限集.A={a1,a2,…,an}为服务的多维度属性集,这其中包括用户评分属性集Au={描述相符度,售后速度,物流速度,卖家服务态度,卖家服务},服务自身有关属性集 As={销售量,售后率,纠纷率,惩罚数,物流质量,消费者保障}等,则有A=Au∪As.
例如,服务集S中服务样本实例si可以表示为:

定义2.(在线服务多维度评价信息)是指对服务的各个属性A={a1,a2,…,an}的评价信息.服务si的多维度评价信息为si(A)={si(a1i),si(a2
i),…,si(an
i)}.
定义3.(服务信誉)信誉是对服务QoS的综合度量,反映服务履行其承诺的服务水平和其他主体对它的总体信任程度,将服务si的信誉记为R.
为了更容易使用户区分服务信誉好坏程度,可依据服务信誉值的高低程度将R划分为l个不同的区间,代表服务之间不同的信誉级别,例如,可以将用户评分划分为5个等级,记为 R={r1,r2,r3,r4,r5},则信誉标签 r1到 r5,分别代表服务信誉的优秀、良好、中等、较差、特差.
定义4.(训练集)服务si及其信誉标签ri形成一个具有明确信誉标签的训练样本xi={si,ri}.由多个训练样本所组成的集合为训练集记为 X,则有 X={x1,x2,…,xp},其中X(A)为服务的多维度评价信息.
定义5.(服务信誉度量)基于训练集X训练分类器模型,并用所得分类器对服务进行分类,得到该服务的信誉标签,进而实现对服务的信誉度量.
4 基于半监督学习的在线服务信誉度量
为了解决先前研究中评价粒度过粗和维度考虑不全的问题,本文采用一种综合服务多维度评价信息的信誉度量方法.方法利用已知服务的多维度评价信息基于决策树算法训练对服务的初始分类器,然后基于Tri-training算法利用所得初始分类器对未标注服务集中服务进行分类,并将分类后的服务和标签加入到训练集,重新训练分类器.使用最终训练所得分类器对服务进行分类进而实现对服务的信誉度量.决策树是机器学习中一种常用的分类算法,其通过训练集训练分类器模型,实现对样本的分类.将决策树运用到服务信誉度量中主要有两个方面的优点:首先,决策树分类算法相较于其他机器学习中的分类算法属于白盒模型,模型简单易懂;其次,决策树模型属于多分类器模型,相较于SVM、Logistic Regression等算法可以更加方便地实现多分类.
4.1 服务多分类器建模
根据定义4,基于训练集X,利用C4.5决策树算法,训练分类器模型,可得到初始分类器.S={s1,s2,…,sm}为由m个未知标签的服务所组成的服务集,从S中随机选择p个服务进行人工标注,作为训练集记为X,剩余q个未标注服务集记为 Y={y1,y2,…,yn},则有 m=p+q.
首先计算训练集X的信息熵(Information Entropy).训练集X的信息熵是训练集X中样本集合纯度的指标,如果训练集X中第g类服务样本所占的比例为pg={1≤g≤k},则服务集X的信息熵定义为:

计算基于属性ai所产生的信息增益(Information Gain).属性ai的可能取值为,若使用ai划分训练集X,则产生V个分支结点,其中第v个分支结点在训练集X中所有在属性ai上取值为的样本记为Xv,给分支节点赋予权重Xv/X,于是可以得到利用属性ai对训练集X进行划分所获得的信息增益为:

最后计算使用属性ai对服务集X进行划分所产生的信息增益率(Gain ratio)为:

利用训练集X训练该决策树模型.将决策树分类器建模成ri=T(xi,X(A))的形式,其中,X(A)是训练集X中服务的多维度评价信息,用于训练决策树分类器T.xi是基于此分类器要进行分类的服务样本.输出是决策树分类器模型T(xi,X(A)),算法描述如算法1所示,其中max_tag表示训练集中样本最多的标签,max表示取最大值,Father_Node(n)表示n结点的父结点,Xv表示第v个分支节点包含在X中并且属性取值为a*的样本,Leaf_Node为叶结点,Branch_Node为分支结点.
算法1.决策树算法
输入:训练集X,服务多维度属性集A;
输出:生成的决策树T(xi,X(A)).


4.2 约束Tri-training算法训练决策树模型
为解决现实环境中很难获得大量具有明确信誉标签的服务,而仅靠少量人工标注的训练样本所训练的分类器难以代表服务的实际数据分布规律的问题,本文采用半监督学习算法训练决策树模型.利用少量的标注服务数据训练初始分类器,基于所训练分类器对未知服务进行分类实现服务的信誉度量.半监督学习是有监督学习与无监督学习相结合的一种常用的方法,使用标记样本的同时大量使用未标记样本进行模型的训练,在尽大可能减少人工标注成本的同时,又可以带来较高的准确率.为此本文采用距离约束的Tri-training(Con-Tri-training)算法克服训练样本不足的问题.首先对训练集X进行有放回采样,每次随机、等概论地从X中抽取一个服务后放回,连续采样m次得到训练集X1.以同样的方式进行采样得到训练集X2、X3,然后基于算法1训练得到3个决策树分类器T1、T2、T3,通过不断地循环迭代实现对大量未标注服务的预测,并将预测服务加入到训练集提高模型性能.具体地,利用初始训练的T1、T2、T3三个分类器对服务集Y中的服务yj的标签进行预测,首先基于T2、T3两个分类器对服务yj进行分类得到分类标签,然后判断分类结果是否一致:
对于结果①计算服务yj与训练集 X={x1,x2,…,xn}中每个服务属性评分的欧氏距离D,并求得与yj欧氏距离最小的服务xn,已知服务xn的标签为rn.比较服务yj的信誉标签rj和服务xn的信誉标签rn,作如下决策:
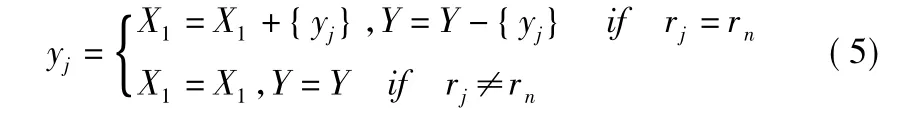
如果rj=rn,则将服务yj连带所预测的标签rj一起加入到训练集X1,并利用X1重新训练分类器T1,如果rj≠rn,则对服务yj不做任何操作.基于分类器T1、T3对服务yj做预测并重新训练分类器T2,同样由T1、T2对服务yj做预测更新分类器T3.最后聚合更新后的分类器T1、T2、T3作为最终分类器,记为G(xi,X(A)),其算法如算法2所示.
算法2.Con-Tri-training算法训练分类器模型
输入:决策树 T1、T2、T3,训练集 X1、X2、X3;
输出:分类器 G(xi,X(A)).

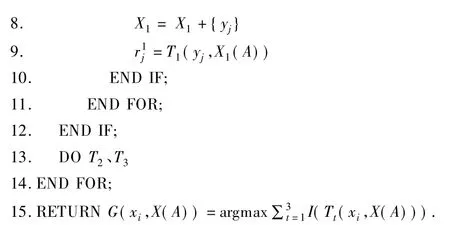
通过Con-Tri-training算法可以在减少误分样本的同时,将服务集Y中服务加入到训练集中,从而使得训练集样本的信息得到完善,所训练的分类器分类性能更加可靠.
4.3 模型的过拟合以及泛化能力
在机器学习的分类任务中,训练的分类器往往会出现对训练样本有很好的分类性能,但对预测样本预测精度不够的问题,称之为过拟合现象[18].过拟合的原因在于学习时过多地考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树.而通过对决策树进行剪枝处理[19],或者基于决策树构造随机森林分类器模型[17],可以解决决策树模型中的过拟合现象,从而达到降低模型过拟合的目的.本文从对决策树进行剪枝处理和构建半监督随机森林两种思路出发消除模型的过拟合,并通过实验比较选出最优抗过拟合模型,作为最终的信誉度量模型.
4.3.1 模型的剪枝处理
通过对已经生成的决策树T1、T2、T3上进行剪枝获得剪枝后分类器.具体地如图1所示,剪枝从生成的树上剪掉子树或者叶节点,并将其根节点或父节点作为新的叶节点从而简化决策树的模型复杂度.

图1 决策树的剪枝Fig.1 Pruning of decision trees
决策树的损失函数表示决策树模型对未知服务预测能力的大小,如公式(6)所示:

其中α为参数,Entt(T)为结点t的信息熵,|T|为叶结点个数,t为决策树的叶结点,Nt为叶结点的样本点.假设叶节点回缩到父节点前后的整体树分别为Ta与Tb,其对应的损失函数分别为Loss(Ta)、Loss(Tb),如算法3所示.
算法3.决策树剪枝算法
输入:已生成的决策树T1、T2、T3;
输出:修剪后的决策树 T1'、T2'、T3'.4.3.2 半监督随机森林模型
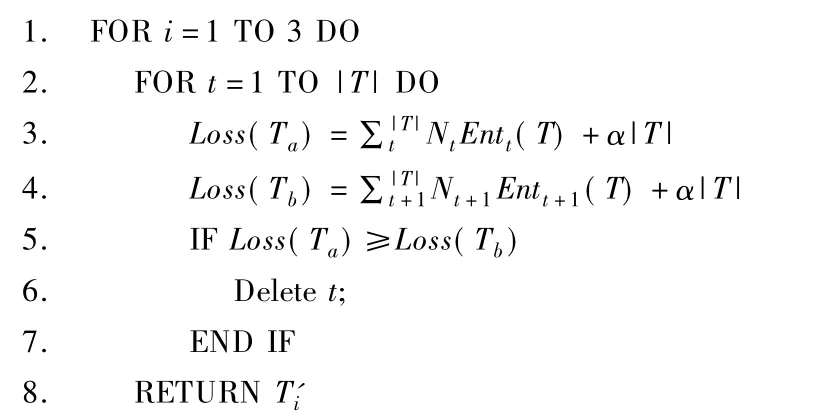

构造随机森林分类器对抗G(xi,X(A))模型的过拟合.首先增加Con-Tri-training算法中分类器G(xi,X(A))的决策树个数至k(k≥3)个,然后对属性集A中的属性进行随机抽样,使得每个训练集尽可能的不同,构造随机森林分类器H(xi,X(A)).基于Bootstrap Sampling采样策略对训练集X进行采样,每采样m次组成一个训练集,共采样出k个训练集记为X1,X2,…,Xk,然后对k个不同训练集中服务的属性集A={a1,a2,…,an}分别进行随机采样,其中每个训练集采样出个属性作为该训练集中服务最终的决策属性集.基于X1,X2,…,Xk个训练集训练得到 k 个分类器 T1,T2,…,Tk.对这k个决策树分类器进行集成构造半监督随机森林分类器H(xi,X(A)),如算法 4 所示.
算法4.随机森林算法
输入:训练集 X,服务属性集合 A={a1,a2,…,an},决策树分
类器 T(xi,X(A)),训练轮数 k;输出:随机森林模型H(xi,X(A))

将服务yj连带预测标签rj加入训练集X1,X2,…,Xk中并对这k个训练集中的服务样本进行更新,得到更新后的训练集X1,X2,…,Xk.利用更新所得训练集重新训练 T1,T2,…,Tk决策树分类器模型.利用所得分类器对服务进行分类,采用简单少数服从多数的投票法则,得到该服务的信誉标签,进而实现对服务的信誉度量.
5 实验与分析
5.1 数据集及实验环境
为了验证本文中方法的有效性,本文爬取网络零售商淘宝网中1632个完整的在线商家交易统计,数据集中包括10个服务种类,每个服务有16个维度属性信息.其中随机选出80%大约(1300个服务)的数据作为模型的训练集,剩余的20%(大约332个服务)作为模型的测试集,为了验证方法的合理性,使得信誉度量的标签信息与人工标注的标签信息具有一致性,对测试样本集中的服务进行人工标注.实验环境为PC机、Windows10系统、Corei7处理器、8GB运行内存,仿真程序用Matlab编写.
5.2 模型有效性验证
本实验的目的是对文中所提出模型有效性的验证.模型的评价指标为平均准确率P,平均召回率Re和F值.其中平均准确率P反映模型的精准度,平均召回率Re反映召回目标类别的比例,而F值则综合准确率与召回率反映模型整体性能.公式如下所示:

5.2.1 Tri-training算法改进前后效果对比
本实验的目的是验证Tri-training算法与本文中所提基于欧式距离约束Con-Tri-training算法在服务准确率上的比较.实验中首先随机对训练集中20%的数据进行人工标注记为X.基于Con-Tri-training算法利用训练集X,训练分类器G(xi,X(A)),将没有欧式距离 Con-Tri-training算法所训练分类器记为 G'(xi,X(A)).利用分类器 G(xi,X(A))、G'(xi,X(A))对测试集中的样本进行预测,准确率如图2所示.

图2 Tri-training模型与Con-Tri-training模型Fig.2 Tri-training model and Con-Tri-training model

图3 半监督决策树模型与Con-Tri-training模型Fig.3 Semi-supervised decision tree model and Con-Tri-training model
从图3可以看出,相较于半监督决策树算法,Con-Tritraining算法在服务标签1到标签5上的分类准确率均有明显的提高.这表明所提出的Con-Tri-training算法相较于半监督决策树算法所训练的分类器在服务分类任务上有着更高的分类准确率.
5.2.3 Con-Tri-training算法与半监督随机森林算法
本实验的目的是将Con-Tri-training算法与半监督随机森林算法在服务测试集各标签上的准确率进行对比.利用训练集X基于算法4训练随机森林分类器H(xi,X(A)),并用该分类器对测试集服务进行预测得到在个标签上的分类准确率.如图4所示.

图4 Con-Tri-training模型与半监督随机森林模型Fig.4 Con-Tri-training model and semi-supervised random forest model
从图4可以看出,半监督随机森林算法相较于Con-Tritraining算法,有着更高的分类准确率.这表明通过增加决策树个数,并随机抽样训练集属性构造随机森林分类器可以防止模型的过拟合,提高模型的泛化能力,进而提高模型的准确率.
5.2.4 半监督随机森林算法与半监督SVM算法
考虑到SVM(Support Vector Machine)作为机器学习中的高效分类算法[20],有着广泛的应用,为此还将文中的方法与SVM进行对比.基于训练集X训练SVM分类器,并利用所训练分类器对测试集中的样本进行预测,每个标签上的准确率如图5所示.

图5 半监督SVM模型与半监督随机森林模型Fig.5 Semi-supervised SVM model and semi-supervised random forest model
从图5可以看出,随机森林分类器在分类准确率更高.同时相对于SVM分类器模型,随机森林分类器模型更加简单,建模时间更短,可以更加高效地完成对服务的分类,因此证明本文所提出算法更加高效.
根据以上实验的结果,列出上述5种方法的准确率、召回率和F值的具体情况,如表1所示.

表1 决策树、Tri-training、Con-Tri-training、SVM、随机森林性能比较Table 1 Decision tree,Tri-training,Con-Tri-training,SVM,Random forest performance comparison
由表1可知,4.3.2所提出的半监督随机森林模型在模型在分类准确率、召回率和F值三个指标上优于DT、Tri-training、Con-Tri-training、SVM,证明所提出的构造随机森林分类器模型可以更好地抗过拟合提高分类指标,因此将该随机森林模型作为最终的信誉度量模型.
5.3 模型剪枝处理
本实验的目的是为了验证剪枝处理可以对抗模型的过拟合同时提高模型的泛化性能,从模型准确率、建模时间等角度来进行验证.为了避免半监督学习等因素对实验的影响,在训练集X中随机的在选择250个服务样本并对其进行标注,选择300个服务样本作为测试样本.
不经过剪枝处理,所训练的分类器的分类准确率P为83.21%,创建模型的开销为1.31s.而经过对所训练的决策树分类器模型进行剪枝处理后,模型的准确率P为88.71%,有了明显的提高,而模型创建的开销为3.94s,如表2所示.
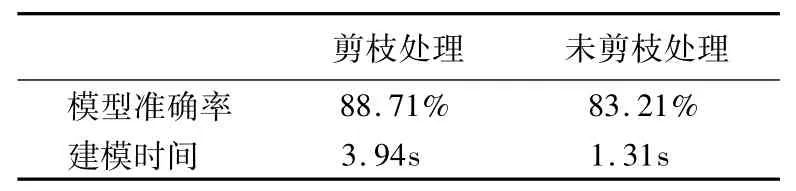
表2 决策树剪枝前后的模型比较Table 2 Comparison of models before and after decision tree pruning
从表2结果可看出,剪枝处理后的分类器模型的准确率有所提高,但相应的建模时间变长.这是由于剪枝处理对建模好的模型进行处理,因此会有额外的时间消耗.模型的准确率的提高是因为剪枝处理可以防止模型的过拟合,提高模型的泛化能力,因此通过剪枝处理可以在牺牲建模时间的同时提高模型的抗泛化能力.
5.4 模型效率验证
本实验的目是通过集成决策树所构造的随机森林分类器模型相对于支持向量机(SVM)模型在时间与分类准确率上的高效性的验证.从实验数据中随机选择250个服务作为训练样本,300个服务作为测试样本.

表3 随机森林与SVM模型的效率比较Table 3 Comparison of efficiency between random forest and SVM model
实验结果表明如表3所示,在模型创建以及分类时间消耗方面:如果使用随机森林算法模型的时间开销仅仅为0.62s,而如果使用SVM 则时间开销为110.40s.在预测准确率方面SVM的准确率达到了94.67%,而随机森林的预测准确率则为93.33%.由此可见SVM分类器模型在分类精度上比随机森林略高,而在时间效率方面两个分类器模型则表现出非常大的差别,随机森林模型的建模时间开销非常小,而SVM模型的时间开销相应的要大得多.这是因为SVM模型在分类中通过高维映射将数据划分开,因此需要花费大量的时间作为代价,而随机森林直接通过集成服务的属性信息对服务进行分类.因此在时间效率要求高的分类任务中随机森林具有绝对的优势.
6 总结与展望
本文研究了基于半监督学习的在线服务信誉度量方法,通过将对服务的信誉度量问题建模成对服务的分类问题,基于服务的多维度属性信息实现对服务的分类.训练服务的分类器模型需要大量的标记样本,但网络上很难直接获取到大量标记样本,因此本文采用半监督的学习算法,而为了防止在学习过程中错误的预测服务样本加入到训练集而对分类器的准确率造成严重影响,提出基于距离约束的Con-Tri-training半监督学习算法,算法通过加入样本间距离约束来对预测样本进行判断,提高半监督学习过程中所训练模型的准确率,通过将所预测的服务样本加入到训练集中不断地优化分类器模型性能.最后通过对Con-Tri-training的抗过拟合处理提出半监督随机森林算法来进一步提高模型对服务的分类性能.
由于人工标注样本可能存在人为因素导致的偏差和不准确,后续将进一步研究如何减少人工标注环节对模型的影响,进一步提高模型效果.
猜你喜欢
电子产品世界(2022年4期)2022-04-21
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
计算机系统应用(2021年2期)2021-02-23
健康体检与管理(2021年10期)2021-01-03
计算机应用与软件(2020年1期)2020-01-14
科学与信息化(2019年28期)2019-10-21
计算机测量与控制(2019年4期)2019-05-08
科学与财富(2016年32期)2017-03-04
