
基于SparkR的人工水体藻类建模预测
2019-08-06 20:18秦业海李修华艾矫燕付旭生
环境与发展 2019年4期
秦业海 李修华 艾矫燕 付旭生

摘要:为探究水质分析与大数据技术结合的可行方案,以MySQL+Hive+SparkR为主体框架搭建一整套从数据输入、存储、调度到应用的SparkR水质分析平台。设置室内培养模拟人工湖藻类生长实验组及其重复实验组,监测各项指标数据,通过SparkR平台,在本地应用Adaptive-Lasso算法识别出对照组和苦草组藻类生长主要影响因子,并建立回归方程进行验证,在集群分布式部署GBTs藻类预测模型,经重复试验验证预测模型未来3天的相对误差均值分别为15.3%、14.8%。
关键词:藻类生长模型;SparkR;Adaptive-Lasso;GBTs
中图分类号:X824 文献标识码:A 文章编号:2095-672X(2019)04-0-03
Abstract:In order to explore the feasible scheme of combining water quality analysis with big data technology, a set of SparkR water quality analysis platform from data input, storage, dispatch to application is built with MySQL+Hive+SparkR as the main framework. Seting up experiment groups indoors to simulate algae growth of artificial lake and its repeated experimental groups, various indicators was monitored. Based on SparkR platform, the adaptive-Lasso algorithm was applied locally to identify the main influencing factors of algae growth in control group and validate the regression equation, and GBTs algae prediction model was deployed in the cluster, and repeated experiments showed that the relative error of GBRT algae prediction models in the next three days was 15.3% and 14.8% respectively.
Keywords:Algal growth model;SparkR;Adaptive-Lasso;GBTs
由于水体污染导致的藻类水华一直受到广泛的重视,我国从20世纪50年代起就已经对各大湖泊水质进行监测,但由于存储管理的混乱,可能造成数据丢失或不可用,而现代的水质监测设备能取大量数据,水质监测也将会进入大数据时代,因此面对大规模的数据,更需要一种规范、安全及可扩展的数据存储方式。国内外对藻类水华进行了大量的影响因子分析、机理建模和数据建模,都取得了良好研究成果,但機理模型针对性强,难以做到普遍适用,而神经网络等数据模型适用性强,依赖现在充盈的数据能进一步提高精确性,然而过大的数据量也将会成为基于内存计算的传统机器学习的瓶颈。因此有学者就水质分析与大数据的结合进行了展望和初步探索[1-4],对学科的结合起到了指引作用,但未列出具体可行的结合方案,水质大数据还处于起步阶段。本文在实验获取数据的基础上,一整套从数据输入、存储、调度到应用的SparkR水质分析平台,具有高可靠、可扩展、兼顾本地及并行计算等优势。通过在本地实现Adaptive-Lasso算法来分析藻类生长的主要影响因子,通过在集群部署GBTs藻类预测模型,在取得较好的分析及预测结果的同时,也验证了基于SparkR平台对水质数据可伸缩性分析这一可行方案。
1 材料与方法
1.1 实验方案
研究对象为广西大学镜湖,是典型的草、藻型人工景观湖,水域面积约3000m2,约70%水域长有苦草,与外界水域无连通为封闭式湖泊。为避免复杂的气候条件和人为活动等因子对藻类生长的干扰,采用室内培养模拟的方案,共设3个实验组,采用60* 40* 60cm的玻璃缸作为培养箱:1)空白组,置入40cm高的湖水;2)对照组,置入10cm厚的底泥及40cm高的湖水;3)苦草组,置入10cm厚的底泥及40cm高的湖水后静置一天,隔天植入18株长势良好的苦草。以上的湖水、底泥和苦草均取自同一区域,湖水均用13号的浮游生物网过滤;底泥去除杂质并搅拌保障匀质性;所用苦草长势良好且修剪为同一外观。培养过程中保持水箱温度为22±1℃,设置光照强度为500μmol.m-2.s-1,光暗比为12h:12h,光照时间段为8:00至20:00,进行统一管理。
为验证模型及预测效果,设计重复实验作为验证组,采用60* 50*70cm的玻璃缸作为培养箱:对照验证组,置入10cm厚的底泥及50cm高的湖水;苦草对照组,置入10cm厚的底泥及50cm高的湖水,植入22株苦草,重复实验相关操作及管理与实验组相同。
1.2 数据测定
测定实验数据主要使用为美国YSI的EXO2型多参数水质监测仪,可以同时装载6只传感器来获取各种的水质参数监测数据,通过设置监测时间和监测频率,最高能以4HZ的速率输出监测数据。传感器监测数据经过自带程序进行数据过滤,最终被传输到数据采集终端显示并以csv格式输出保存。使用水质监测仪监测的水质指标有pH值、溶解氧(DO)、水温(T)、浊度(Tur)、学需氧量(COD)、电导率(Cond)、氧化还原电位(ORP)、叶绿素a(Chl-a)。针对本文藻类生长分析的需求,通过实验室化学测定的方式测定总磷(TP)、总氮(TN)、氨氮(NH4+-N)指标,依照《水和废水监测分析方法》[5]中相应的方法执行。
2 技术与方案
使用VMware创建3台虚拟机为节点构建集群,选用CentOS6.7操作系统。集群各节点通过配置相应IP、主机名及hosts映射文件,关闭防火墙,配置免密登录保证集群通信通畅。集群所有节点安装和配置Java环境和R环境,最基本的需要安装Hadoop HDFS集群、Hive和Spark集群,为加强集群性能,可以选择安装zookeeper、YARN等等大数据生态系统组件。
本文将搭建一整套从数据的输入、存储、调度到应用分析的SparkR水质分析平台,采用的主体框架为MySQL+Hive+SparkR,分别对应本地数据、Hadoop集群和Spark集群模块,SparkR平台的整体架构及流程如图1所示。
水质监测仪器及实验测定数据保存为csv格式文件,通过编写R程序对原始数据进行整合、剔除异常值、补缺、归一化等数据预处理以满足数据应用的格式需求。将经过预处理的数据导入MySQL所建相应的表中,MySQL数据库作为数据的中转,也便于实现数据的可视化。使用Azkaban工作流任务调度器来实现各项任务定时并按流程自动执行,提交的具体任务流程为:csv文件→数据预处理→导入MySQL→导入Hive,自动实现数据经本地预处理后向本地数据库再向集群存储的传递过程。其中使用Sqoop工具将MySQL中的结构化数据导入到Hive中,实则是导入到Hadoop HDFS中,而HDFS本身就是一个高可靠、可扩展的分布式文件系统,满足了数据安全及扩容的需求。Hive是基于HDFS对数据进行类数据库操作的抽象数据库框架,具有强大的数据查询和清洗功能,通过使用符合用户使用习惯的类SQL的HiveSQL语句来高效地获取所需数据。
SparkR使用一种带有列名的分布式数据集SparkDataFrame,它与关系型数据库中的表或是R Data Frame相似,并就分布式环境进行了优化,SparkDataFrame可以由Hive表来构建。SparkR通过SparkSession作为桥梁实现R程序与Spark集群互通,使得R程序能调用Spark集群上的数据和资源,解决了R语言难以实现级联的问题。SparkR中可以使用HiveSQL语句来查询Hive表中的数据来构建SparkDataFrame,实际上是由SparkSession调用Spark SQL组件来实现的。
R语言与大数据集群结合的方式有一般两种,一种是从集群中获取数据到本地,使用R程序进行需求分析。SparkR就可以通过HiveSQL语句从集群的Hive表筛选所需数据到本地,由于大多数的算法都是基于内存进行串行计算,因而只能采用本地计算方式,与传统的R语言数据分析无异,但SparkR为集群和R程序提供了良好的衔接,即使大规模数据也能高效地分块、抽取和筛选成内存可容纳的规格,提高了数据分析的量级和效率。另一种是在集群上部署分布式计算的R程序。分布式计算需要算法支持并行化,目前SparkR实现的可并行化的算法有分类、聚类、回归、树和协同过滤等算法,而实现的本质是由Spark MLlib机器学习库中算法向R语言的迁移,SparkDataFrame作为分布式数据集可以直接调用SparkR所实现的机器学习算法,这使得R语言也能进行大规模数据的并行化计算。SparkR作为R语言与大数据集群的结合方式,对大规模数据或是小规模数据、并行计算或是串行计算,都提供了良好的协调处理方案,使数据分析具有可伸缩性。
3 分析与建模
3.1 Adaptive-Lasso相关分析
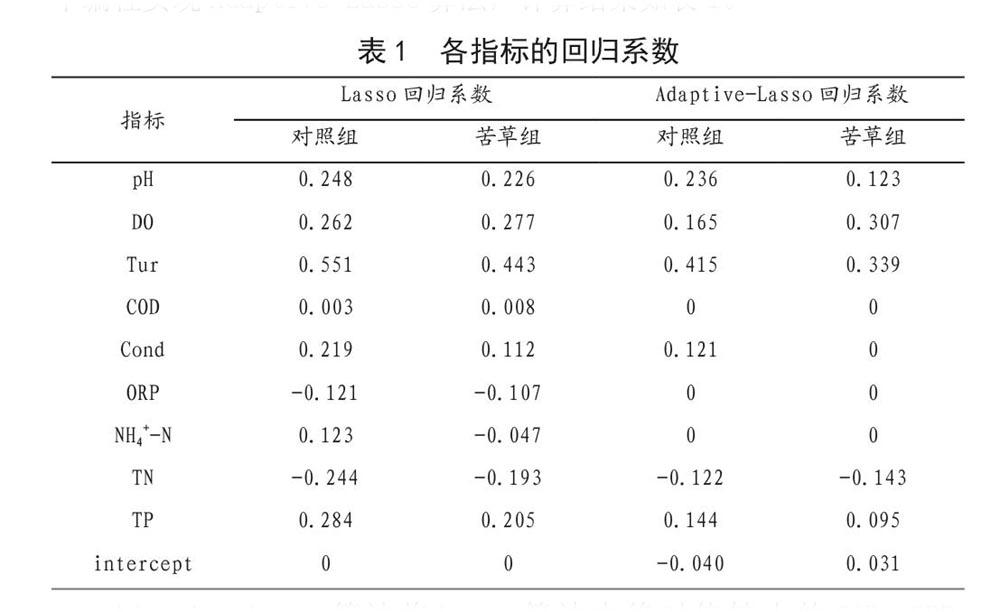
将实验获取的数据通过SparkR将全量加载到本地,使用Adaptive-Lasso算法做相关分析识别藻类生长的主要影响因子。应用Lasso回归来分析影响藻类生长的主要影响因子并建立回归模型,Lasso回归,将参数估计与变量选择同时进行的一种正则方法,用模型系数的绝对值函数做为惩罚来压缩模型系数,能使一些绝对值较小的系数直接变为0[6]。在R语言中的使用LAR(最小角度回归)算法实现Lasso回归算法,但未出现某些指标回归系数为0的情况。为解决Lasso估计对于所有的系数都使用相同程度的压缩效果问题,应用Zuo提出给不同的系数加上不同权值的Lasso改进方法,称为Adaptive-Lasso方法[7],在R语言中编程实现Adaptive-Lasso算法,计算结果如表1。
为验证模型的健壮性,对Adaptive-Lasso回归模型进行10-折交叉验证,计算结果为B、C两组模型的均方误差均值分别为0.331和0.262,预测值相对于真实值的相对误差均值分别为39.5%、18.4%。从计算结果来看,使用Adaptive-Lasso算法选取主要影响因子而构建的回归模型是合理的。使用验证组数据对Adaptive-Lasso回归模型进行验证,对照组和苦草组的均方误差均值分别为0.315和0.283,预测值相对于真实值的相对误差均值分别为33.4%、21.6%使用多元线性回归模型还是存在一定误差,需要更精确的预测方法。
3.2 GBTs建模预测
为更精确地对藻类生长进行预测,将构建GBTs藻类生长模型。梯度提升树(Gradient-Boosted Trees,GBTs ),是一种决策树的迭代集合,通过迭代地训练决策树使损失函数达到最小[8]。梯度提升树对复杂的非线性函数有较好的拟合能力,易于实现并行化,而分布式平臺也较好的解决了该算法内存消耗大的问题[9]。SparkR所实现的GBTs算法支持分布式并行化的分类和回归应用,在集群环境下通过调用spark.gbt()方法,并根据模型需求调整模型训练参数构建藻类生长的GBTs预测模型。
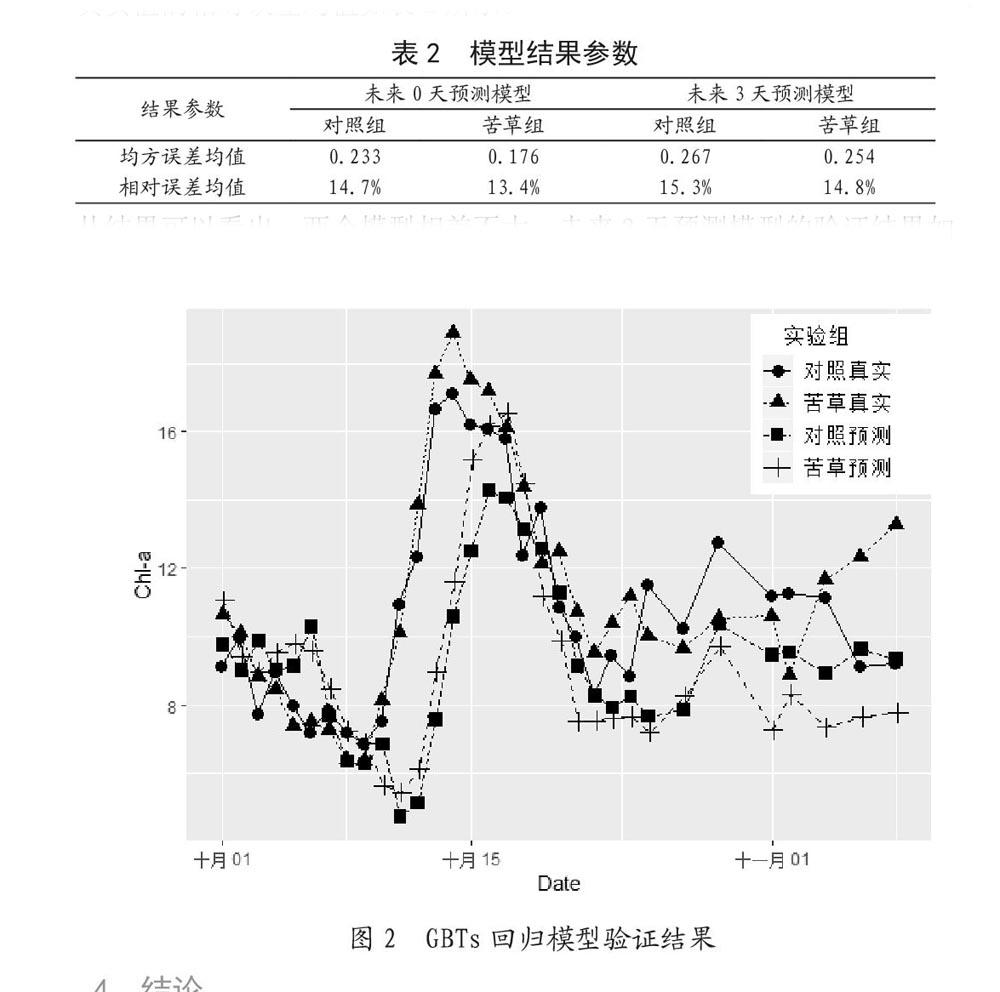
使用实验组数据用于模型训练,Chl-a作为输出,其余指标作为输入,分别使用相应的滞后数据来预测未来0天和3天的叶绿素浓度,其中未来0天预测模型作为参考,未来3天预测模型作为实际应用。使用验证组数据对模型进行验证,两个模型的均方误差均值、预测值相对于真实值的相对误差均值如表2所示。
从结果可以看出,两个模型相差不大,未来3天预测模型的验证结果如图2所示,可以看出在前中期预测点和实际点非常接近,后期由于藻类衰亡后出现了水棉等浮游植物,各指标数据波动较大,导致后期预测结果有所偏差,但总体而言所建立的GBTs预测模型有良好的预测结果。由于本次实验数据还未到达一定规模,在实现水质监测自动化系统而获取大量数据的条件下,将能更好地发挥SparkR平台的优势进而得到更好的数据分析和模型预测结果。
4 结论
(1)搭建了从数据输入、存储、调度到应用的一整套基于SparkR的数据处理分析平台,具有高可靠、可扩展、兼顾本地及并行计算等优势,通过集群加载数据到本地实现Adaptive-Lasso算法来分析藻类生长的主要影响因子,通过在集群部署GBTs藻类预测模型,验证了基于SparkR平台对水质数据可伸缩性分析的可行性。(2)通过Adaptive-Lasso算法筛选参数建立回归方程并进行验证,最终确定对照组对藻类生长的主要影响因子为pH、溶解氧、浊度、电导率、总磷、总氮,苦草组的为pH、溶解氧、浊度、总磷、总氮。(3)就多元线性回归对于有较大峰值出现藻类生长过程预测的不足,在集群上应用GBTs算法建立藻类生长预测模型,经重复试验验证,对照组和苦草组的GBTs藻类预测模型未来3天的相对误差均值分别为15.3%、14.8%,预测效果良好。
参考文献
[1]赵黎明,王海刚,王英珏.大数据在线技术在水质监测中的应用[J].中国环保产业,2017(12):70-72.
[2]周煜申,康望星,沈存,赵贤林.大数据在水环境综合评价预警中的应用研究[J].江苏科技信息,2017(35):52-54+64.
[3]原广平.大数据技术在滇池流域水环境监测网络及信息平台中的应用[J].环境与发展,2018,30(11):146-147.
[4]邵璇,田文君.基于大数据的水质监测技术初探[J].科技传播,2018,10(07):75-76.
[5]魏复盛,国家环境保护总局.水和废水监测分析方法(第4版)[M].北京:中国环境科学出版社,2002.
[6]Robert Tibshirani.(1996),Regression Shrinkahe and Selection via the Lasso.Journal of the Royal Statistical Society.Series B,Vol.58,No.1.267-288.
[7]Hui Zuo.Trevor Hastie.(2005),Regularization and variable selection via the elastic net.
[8]吕依蓉,孙斌,喻之斌,等.基于梯度提升回归树的处理器性能数据挖掘研究[J/OL].集成技術,2018(05):1-10.
[9]张兴.基于Spark大数据平台的火电厂节能分析[D].太原:太原理工大学,2016.
收稿日期:2019-02-26
作者简介:秦业海(1992-),男,汉族,硕士研究生,研究方向为环境智能。
