
基于优化的Inception-ResNetA模块与Gradient Boosting的人群计数方法
2019-08-06 03:18郭瑞琴陈雄杰符长虹
同济大学学报(自然科学版) 2019年8期
郭瑞琴, 陈雄杰, 骆 炜, 符长虹
(1.同济大学 机械与能源工程学院, 上海 201804; 2.斯图加特大学 工程与计算力学研究所, 斯图加特 70569)
随着科学技术的快速发展,交通工具更加便利,城市化进程不断加快,城市流动人口的数量快速增长,城市繁华街道越来越拥挤,各种大型展览会的参展人员也越来越多.为了保证城市交通通畅,合理控制人群密集场合的人员数量,保证人民群众生命安全,有必要对行人行为和分布规律进行研究[1-11].人群计数技术作为该领域的重要组成部分之一,近年来受到众多国内外研究机构的关注[1-7].人群计数主要有以下难点:第一,在一张图片中,行人的尺度变化;第二,不同场景下的行人分布变化;第三,相同场景下不同时间的行人分布变化.由于不同场景图片中行人数量和大小差别较大,因此要求计数方法对不同环境场景中行人尺寸的多样性具有很强的鲁棒性.为解决这个难题,学者们提出了各种不同的人群计数方法来保证神经网络适应这种尺度的变化[1-6].
在早期的人群计数研究中,大多数计数方法是以目标检测为基础,其检测方法主要分为两类:一类是基于人工设计特征的目标检测[11];另一类是基于深度神经网络提取特征的目标检测[12-13].目标检测方法首先通过训练得到能够定位目标的检测器,然后使用该目标检测器在图片中找到指定目标,并将检测得到的目标数量作为最后的计数结果.该方法能够比较有效地检测出目标,并对单个目标精确定位,但是对于有行人相互遮挡和尺度变化比较大,且人群密度较高的场景图片,其识别准确率较低.
为了解决目标检测方法存在的问题,Chan等[14]提出了基于回归的计数方法,该方法直接给出人群的目标数量,不需要对每个目标进行检测.虽然基于回归的方法相对于基于目标检测的方法准确率有所提升,但此种方法没有考虑人群的空间分布,无法理解深层的场景信息,从而影响整体计数结果的准确性.为了将图片中人群的空间位置信息加以利用以提高人群计数的准确率,Ooro-Rubio等[15]提出了基于密度图的计数方法.该方法通过对人群密度图的像素分析,并对密度图按像素求和,将求和得到的数字作为计数的结果.其中,多列结构的卷积神经网络是具有代表性的密度计数方法,该方法的基本思想是在不同的列中使用不同大小的卷积,使得每一列网络具有不同大小的感知野,通过提取每列网络的特征,并将这些特征进行融合,解决人群计数中的行人尺度变化问题[1-2].该方法的不足之处在于,当多列结构训练参数较多时,训练网络变得困难.其次,每一列的网络都表现出相似的人群密度变化特性,使得各列之间的差异并不显著,这与设计多列结构的初衷相违背[6].
最近,Zhang等[3]提出一种端到端的尺度自适应网络结构用于生成密度图,并在多个数据集上证明其有效性,展示出其在准确率和鲁棒性上的优越性.值得注意的是,该网络在其后端使用了最大池化层和反卷积层,尽管这种结构能增大其感知野,但也会导致细粒度信息的丢失.Li等[6]随后提出一种使用空洞卷积作为其后端的神经网络,可有效地增大网络的感知野,同时也避免了使用最大池化层带来的细粒度信息丢失等问题.然而,该网络结构并不包含多尺度信息.本文实例的实验结果证明,多尺度信息可以改进网络人群计数的准确率.
为了提高人群计数方法的准确率,本文使用优化的Inception-ResNet-A模块[16]并结合Gradient Boosting集成学习方法提出一种端到端的卷积神经网络结构,即Gradient Boosting Multi-Scale Counting Net(GB-MSCNet),该结构能够在有效地增大网络输出层感知野的同时保存图片中的细粒度信息.而且该网络能够将多尺度特征融合,保证该网络对于行人尺度变化以及人群密度变化的鲁棒性,使生成的密度图更精确,从而准确地给出图片中的行人数目.
1 人群真实密度图的获取
在基于密度图的计数方法中,监督学习的目标就是学习从原图片到相对应真实密度图的映射,因此,真实密度图能否准确反应原图中行人的空间分布,对最后的计数准确率有很大的影响.
对于人群计数数据集,数据集中通常会给出行人在图片中的位置参数,即计数目标在图片中几何中心的位置(以像素点坐标的形式给出).根据数据集中的位置参数,可得到初始密度图M
(1)
式中:Pi为第i个行人目标在图片中的位置;J为行人的数量;M为与原图片尺寸相同但通道数为1的n×m矩阵;δ(Pi)表示在Pi处的值为1,而其他位置值为0的与M相同尺寸、相同通道数的矩阵.在M的基础上,用高斯核Gσi对M进行滤波操作,生成真实密度图F
F=M*Gσi(x)
(2)
高斯核函数Gσi(x)定义如下:
(3)
式中:σi为二维高斯分布的标准差;Gσi(x)代表矩阵F中x处关于Pi的高斯核的取值,最后F在x处的取值为所有Pi在x处的高斯核函数取值(与σi相关)之和.
根据高斯核函数的性质可知,σi越大,第i个行人在生成的真实密度图中对应的区域越大,因此σi应与第i个行人在图片中的大小相关,为达成这一目的, Zhang等[2]提出了一种用于密集人群的真实密度图的生成方法,将σi与行人之间的平均距离相关联,即对每个行人,以距离该行人最近的k个行人与该行人之间的平均距离来代表σi(k是超参数,可通过实验选择效果最好的k).使用该方法在图1a所示的ShanghaiTech数据集中生成的真实密度图如图1b所示,对图片中的所有行人使用同样大小的σi生成的真实密度图如图1c所示.显然图1b中的密度分布随着行人在图片中的大小而变化,相比图1c更接近图1a中行人的密度分布.
然而Zhang等[2]提出的方法不适用于描述相对稀疏人群的行人目标大小.如果行人之间的平均距离与行人在图片中的大小相关度不高,就无法使用平均距离代表行人在图中的大小.为解决这一问题,Chen等[17]提出一种针对具有固定背景的人群计数数据集的真实密度图生成方法,使用线性拟合的方法模拟行人在图片中的位置与行人大小的关系,并通过数据集中的位置信息近似计算σi并进一步得到不同位置行人的大小,使获得的真实密度图能更精确地表示行人的空间分布.如图2所示,使用该方法在UCSD数据集(该数据集中的图片背景固定不变)中生成的真实密度图相比于使用固定的σi更能代表行人的密度分布.

a

b

c
图1 ShanghaiTech数据集中的密集人群图片与用平均距离代表和使用固定不变的σi生成的真实密度图
Fig.1 Crowd image with dense population in ShanghaiTech dataset and corresponding density map with average distance between pedestrians and fixedσi

a

b

c
图2 UCSD数据集中的人群图片与使用线性拟合方法近似计算和使用固定不变的σi生成的真实密度图
Fig.2Crowd image in UCSD dataset and corresponding density map with linear fitting and fixedσi
由于上述原因,在本文中,对于人群密度较大的ShanghaiTech数据集和UCF_CC_50数据集[11],使用Zhang等提出的基于行人平均距离的真实密度图生成方法;而对于人群相对稀疏且图片背景固定不变的UCSD数据集,则使用Chen等人提出的基于线性拟合的真实密度图生成方法.
2 GB-MSCNet计数网络
GB-MSCNet是基于Inception-Res-Net-A模块的端到端的全卷积网络结构,其具体结构如图3所示;GB-MSCNet中各模块详细结构如图4所示.

图3 GB-MSCNet网络结构
Fig.3 Architecture of GB-MSCNet

该网络能在有效增大网络输出层感知野的同时避免丢失图片中的浅层特征,并将不同尺度的特征融合,保证了该网络对于行人尺度变化的鲁棒性,使生成的密度图更精确.
2.1 网络结构设计
根据之前的研究,在人群计数中,网络提取特征的能力、感知野大小、多尺度特征是影响准确率的主要因素[17].因此,GB-MSCNet使用在ImageNet上预训练过的VGG16[16]的前10层卷积层作为前端网络,以增强网络提取特征的能力;而在网络的后端,使用多个优化的Inception-ResNet-A模块,因为该模块能在增大网络的感知野的同时将不同尺度的特征融合.
为了适应VGG16的网络结构,在各个Block中使用优化后的Inception-ResNet-A模块,优化后的模块与原模块的主要区别在于通道数,实验证明优化后的模块能够提高人群计数的精度[17].相比于第1列的网络,第2列删去了Block-1,这种结构设计的好处在于既能避免参数量过多(Block 1中的参数占MSCNet参数量的80%),又能使用Gradient Boosting方法提高计数的准确率.
2.2 网络训练方法
在本文中,使用Gradient Boosting方法对GB-MSCNet进行训练.Gradient Boosting是集成学习方法的一种,它主要的思想是每一次学习都是建立在前一次模型所犯的错误的基础上,以纠错的方式来提升整体模型的性能.在训练GB-MSCNet时,首先单独训练第1列的卷积网络,至其收敛时将第1列的权重固定,再将第2列的卷积网络与第1列并联,使其学习第1列产生的密度图与真实密度图之间的残差.
在训练过程中,首先使用Adam优化器,学习率设置为1×10-6,待其收敛时使用SGD优化器,学习率设置为1×10-8.同时在训练过程中,还使用了权重衰减(weight decay)、动量(momentum)等方法以加速收敛过程.
本文中使用真实密度图与人群计数网络生成的密度图之间每个像素的欧式距离之和来衡量两者之间的距离,并将这种距离作为训练中的优化函数,其具体定义如下:
(4)
式中:K为人群图片总数;θ为计数网络中的参数;I为输入到网络中的人群图片;Di(Ii,θ)为网络生成的密度图;Di,gt代表真实密度图.
3 实验验证
3.1 计数性能评价指标
目前,评价人群计数网络的性能一般采用平均绝对误差(MAE)e1和均方误差(MSE)e2两个指标值,本文采用MAE和MSE指标对所构建的网络系统进行评价.MAE和MSE的定义如下:
(5)
(6)
式(5)、(6)中:M为测试的图片数量;Ci为网络给出的第i张图片的计数结果;Ci,gt为第i张图片的真实计数结果.当网络给出的计算结果Ci,gt越接近准确计数结果Ci时,网络结构的性能越好,相对应的式(5)和式(6)的计算结果,MAE和MSE值越小.因此,MAE和MSE越小,表示网络的计数准确率越高、鲁棒性越强.
3.2 GB-MSCNet训练过程展示
图5是实验过程中GB-MSCNet的损失函数曲线以及各阶段对应的密度图以及测试得到的MAE数值,从图5中可以看出,随着损失函数函数值的减小,密度图越来越接近于真实密度图,各训练阶段生成的密度如图6a~6e所示.从第1个轮数完全随机产生的密度图开始,训练到第10个轮数已经能较准确地感应出行人的位置,但仍然存在许多对与行人无关的背景的感应;接下来从100到500再到1 000轮数的过程就是逐渐将背景信息过滤的过程,观察图6d可以看出,第500个轮数时还存在一些不明显的背景干扰,但到1 000轮数时背景干扰基本消失.同时,计数产生的误差值也随着训练逐渐减小,这充分说明使用公式(4)中的函数作为损失函数是较为合理的.另外,使用该公式作为损失函数的另一个重要原因是该函数是凸函数,而这对于神经网络的损失函数来说是一个必不可少的属性,否则会极大地加大训练的难度.

图5 GB-MSCNet训练集与验证集损失函数曲线
图7中给出了测试时估计行人数量与真实行人数量随测试视频图片帧数变化的曲线.从图7中可以看出,估计行人数量的曲线与真实行人数量的曲线非常接近,最大的计数误差不超过8,说明GB-MSCNet能够较好地完成人群计数的任务.
在训练GB-MSCNet时,首先训练第1列,再用第2列学习第1列与真实密度图之间的残差,如图8所示,残差不均匀地分布在每一个行人处,主要存在于人群密集区.加入第2列并训练后,模型的计数性能得到提升,图9所示是MAE和MSE在UCSD数据集中随测试视频图片帧数的变化曲线,相比于只使用第1列,加入第2列后模型的MSE和MAE 均有下降.从图9可以看出,MAE和MSE的数值都比较小,并且图中两条曲线的变化趋势平缓,说明GB-MSCNet的计数准确性和稳定性都达到了一个较高的水平.

a 训练轮数=1

b 训练轮数=10
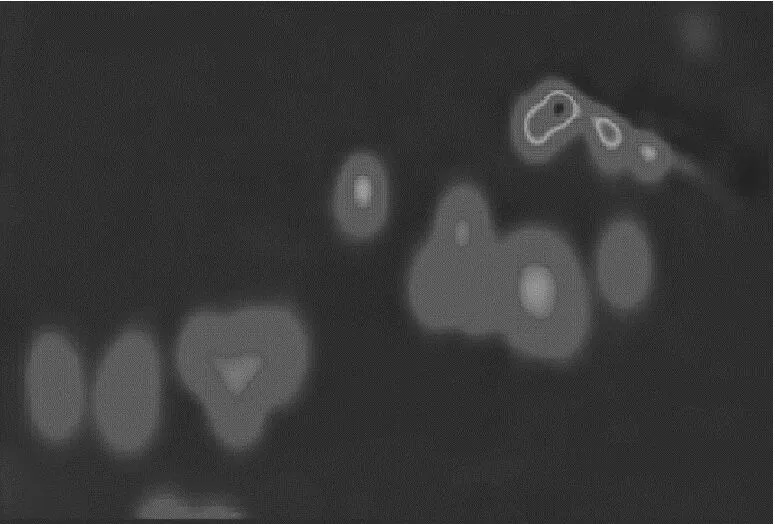
c 训练轮数=100

d 训练轮数=500

e 训练轮数=1 000
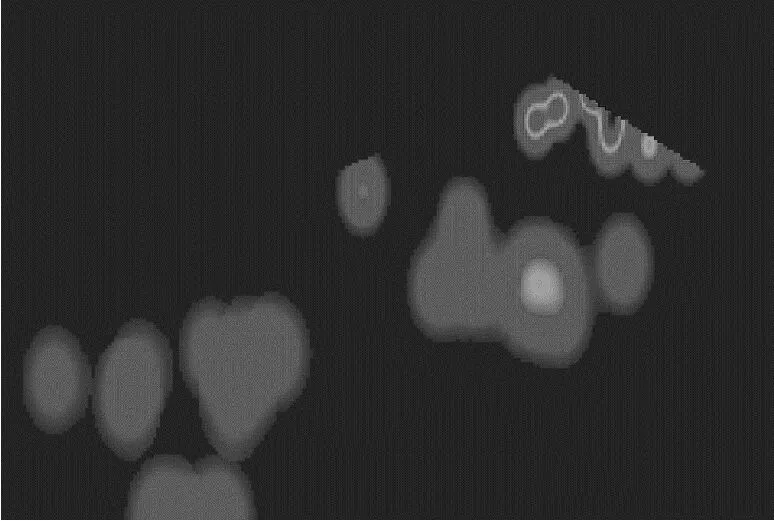
f 真实密度图

图7 UCSD数据集中估计行人数量与真实行人数量随测试图片帧数变化的曲线
3.3 GB-MSCNet计数性能实例验证
为了能够更客观地说明本文所构建的网络结构在人群计数问题中的有效性,本实例验证使用UCSD数据集作为衡量对于稀疏人群的计数性能的数据集,ShanghaiTech和UCF_CC_50数据集作为衡量对于密集人群的计数性能的数据集,最后使用采集于真实场景的包含光照和视角变化的TongjiCanteen数据集测试本文的方法对于这些变化的鲁棒性,同时对本文构建的网络结构的性能进行评价.

图8 GB-MSCNet中第1列产生的残差图
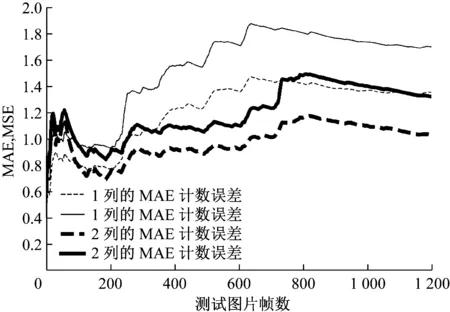
图9 UCSD数据集中评价指标MAE和MSE随测试图片帧数的变化曲线
3.3.1稀疏人群实例验证
UCSD是稀疏人群场景下获得的一组数据集,该数据集中包含2 000张分辨率为238像素×158像素的灰度监控照片,平均每张图片有25.0个标注行人.为了与GB-MSCNet 的感知野大小相匹配,在训练及测试时将UCSD数据集中所有的图片放大7倍至1066像素×1666像素.本次试验中第601至第1 400张图片被用作训练集,余下的图片被用作测试集.该数据集中人群图片、真实密度图、使用GB-MSCNet生成的密度图如图10所示.用不同的方法测试UCSD数据集,得到不同网络结构下的计数误差,实验结果如图11所示.
分析图11中的MAE和MSE数值可知,GB-MSCNet在计数准确率与计数稳定性两方面都展示了其良好的性能,证明了该网络在对相对稀疏的人群进行计数时表现良好.
3.3.2密集人群实验验证
ShanghaiTech数据集是密集人群场景下的一组数据集,该数据集分为A和B两部分,其中,A部分中包含482张图片,平均每张图片包含501.4个标注行人;B部分中包含716张图片,平均每张图片包含123.6个标注行人.根据之前研究的设定[2],对于A部分,300张图片被用作训练集,余下的182张作为测试集;对于B部分,400张图片被用作训练集,余下的316张作为测试集.该数据集中人群图片、真实密度图、使用GB-MSCNet生成的密度图如图12所示.



图10 UCSD 实验结果示例
Fig.10 Example of experiment results on UCSD dataset
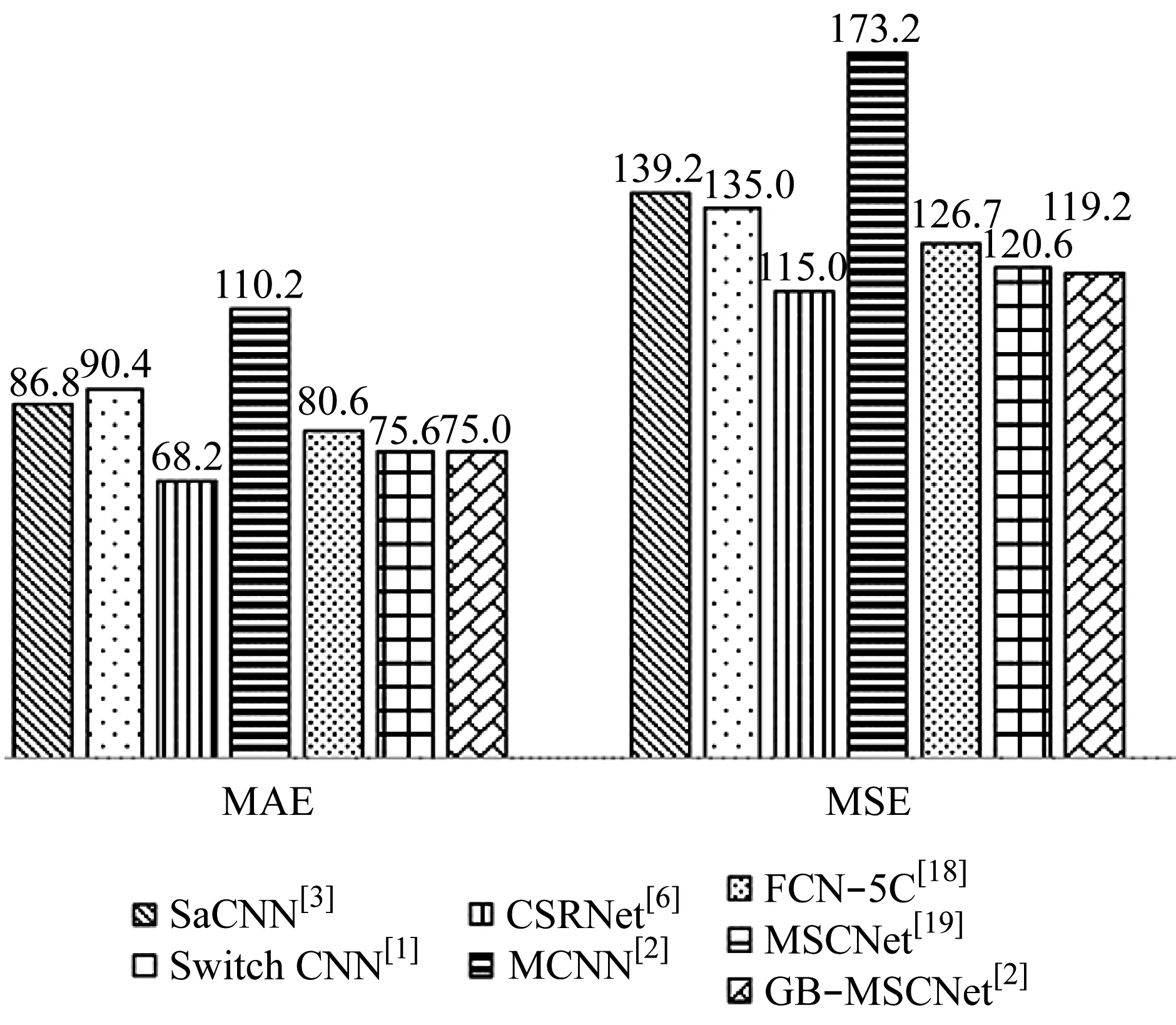
使用不同的方法对ShanghaiTech数据集进行测试,得到不同网络结构下的计数误差,实验结果如图13所示.从图13中可以看出,GB-MSCNet在该数据集中的计数准确率和稳定性均较好.
UCF_CC_50数据集中包含50张密集人群的图片,总共63 974个标注行人,平均每张图片包含1 279.5个行人,是目前公开的数据集中人群最密集的数据集.该数据集中人群图片、真实密度图、使用GB-MSCNet生成的密度图如图14所示.根据之前研究的设定[11],在该数据集中使用五折交叉验证,其实验结果如图15所示.从图15中可以看出,GB-MSCNet在非常密集的人群图片中同样获得了较高的准确率与较好的稳定性.
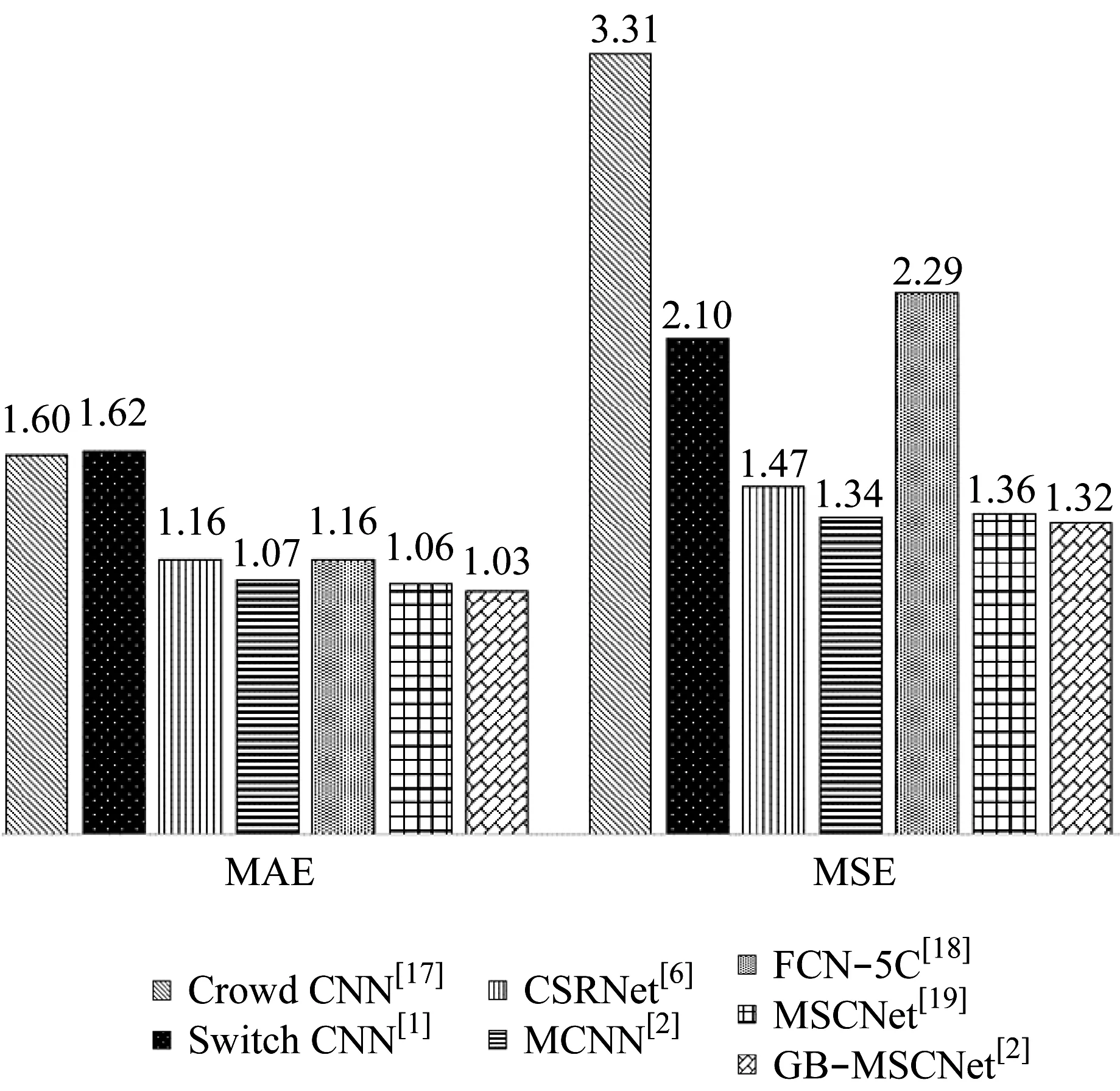
图11 UCSD数据集网络结构计数误差值
3.3.3TongjiCanteen数据集验证
为了验证本文提出方法对于光照和视角变化的鲁棒性,本文采集并标注了4段60 s的真实场景下的视频,4段视频拍摄于同一场景,但光照条件、视角都不相同.图16是该数据集中不同条件下的人群图片、真实密度图和使用GB-MSCNet生成的密度图.
该数据集中,在每个视频前50 s每秒采集3帧图像作为训练集,剩余的所有图像作为测试集,在4个不同的视频中,GB-MSCNet均表现良好,具体的MAE与MSE如表1所示.
3.3.4实时性分析
本次实验所用的显卡型号为GTX1070,处理器为Intel i7处理器.在TongjiCanteen数据集中,测试的图片分辨率为(307像素×425像素),本文提出的方法在该条件下的图像处理速度如图17所示.从图17中可以看出,GB-MSCNet平均每秒能够处理38.9帧图片,达到了在实际应用中的实时性要求.




a A部分

b B部分
图13 ShanghaiTech数据集计数误差值
Fig.13 Experiment results on ShanghaiTech dataset

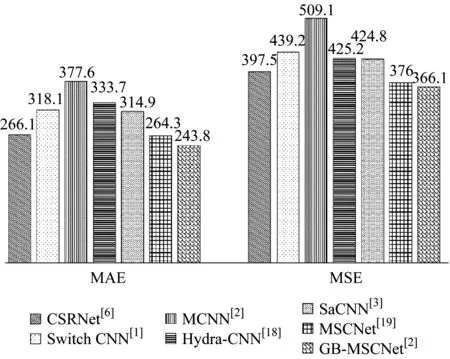
图15 UCF_CC_50数据集计数误差值
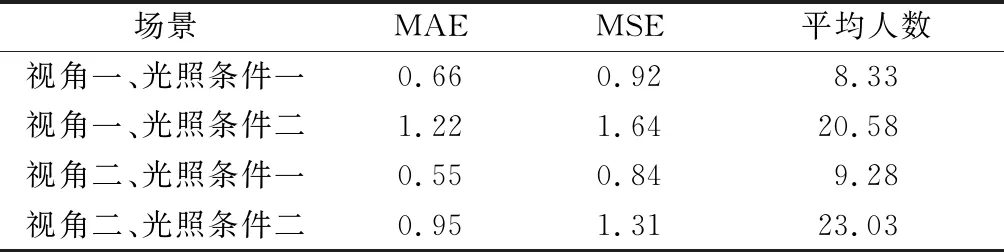
表1 真实场景下计数误差值
综合以上数据集来看,GB-MSCNet在对稀疏人群与密集人群进行计数时,能够准确给出复杂场景中行人的数目,并且对于相机视角和光照变化的鲁棒性较强,较之于之前的方法在准确率和稳定性两方面都有所提高.

视角一光照条件一

真实行人数量4.00

估计行人数量4.02

视角一光照条件二

真实行人数量10.00

估计行人数量10.17

视角二光照条件一

真实行人数量11.00

估计行人数量11.01

视角二光照条件二

真实行人数量21.00

估计行人数量21.48

图17 GB-MSCNet在TongjiCanteen数据集中的运行速度
4 结语
本文针对基于视觉的人群计数进行了研究,提出了使用集成学习方法Gradient Boosting进行训练的人群计数网络GB-MSCNet,该网络具有较大的感知野,且能够融合各个尺度的特征,从而适应人群计数中行人的尺度变化.实验结果证明,对于不同的人群密度、相机视角与光照变化,该方法都能够较准确地给出图片中的行人数量,证实了该网络对于人群密度、行人大小、光照以及视角的变化具有较强的鲁棒性.与之前的人群计数方法相比较,GB-MSCNet在准确率与稳定性两方面均有较大的提高.
猜你喜欢
数学小灵通(1-2年级)(2021年11期)2021-12-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
意林(2021年5期)2021-04-18
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
中等数学(2020年8期)2020-11-26
小学生学习指导(低年级)(2020年4期)2020-06-02
数学大王·低年级(2019年8期)2019-08-27
扬子江(2019年1期)2019-03-08
