
藏文词向量相似度和相关性评测集构建
2019-08-05 06:49:48才智杰孙茂松才让卓玛
中文信息学报 2019年7期
才智杰,孙茂松,才让卓玛
(1. 青海师范大学 计算机学院,青海 西宁 810016;2. 青海省藏文信息处理与机器翻译重点实验室,青海 西宁 810008;3. 藏文信息处理教育部重点实验室,青海 西宁 810008;4. 清华大学 计算机科学与技术系,北京 100084)
0 引言
自2006年以来,随着计算机硬件性能的提升以及优化算法的突破,深度学习技术飞速发展,目前已成为学者们研究的热门课题。在基于深度学习的藏语自然语言处理中,词向量是其基本要素,有了适合藏文的词向量表示,才能更好地利用深度学习技术解决藏语句法、语义、语用等深层次问题。词向量评测集是用来评价词向量表示效果的数据集,包括内部评测集(internal evaluation set)和外部评测集(extrinsic evaluations set),分别用于评价内部任务和外部任务。内部评测是通过建立词之间的语义相似度或紧密度和相关性能力的评测集,对词向量表示模型所得的词向量进行统计分析,从而评价词向量模型的性能,分为词相似度评测(word similarity evalution)、词相关性评测(word relevance evalution)和词汇类比评测(word analogy evalution)等三种。外部评测是将模型得到的词向量应用到具体某个任务中,通过任务性能评价词向量模型,如分类、词性标注和命名实体识别等。内部评测是词向量评测使用最广泛的一种,在词向量表示的数据分析中都会进行内部评测。藏文词向量研究刚刚起步,还没有构建用于评价词向量的评测集。
本文在分析英文、汉文词向量评测集构建方法的基础上,结合藏文的特点研究藏文词向量评测集构建方法,构建了用于评价藏文词向量相似度的评测集TWordSim215和相关性的评测集TWord Rel215,并分析了评测集的有效性。
1 研究现状
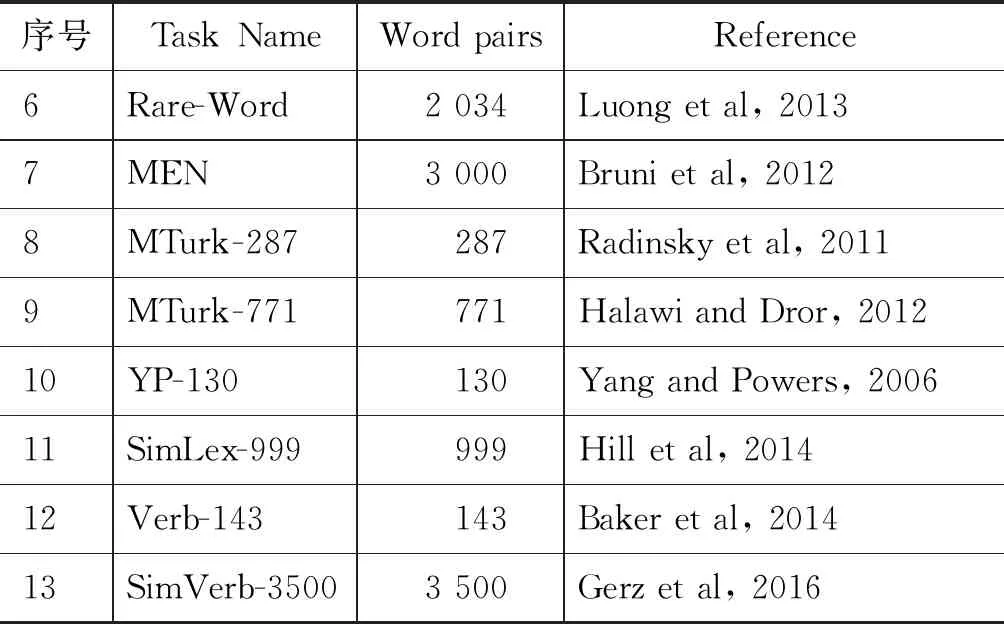
词向量评测是词向量性能分析的基础,自1997年起,学者们开始了词向量评测集的建设工作。英文词向量评测集建设方面,Lin[1]、Curran和Moens[2]、Dinu和Lapata[3]等做了深入研究,并建立了基于WordNet的英文词向量评测集[4],基于整合词库和语料库的英文词向量评测集[5]。Finkelstein等[6]筛选了353个单词对,选择20人对单词对用0到10之间的实数进行主观打分,建立了英文词向量评测集WS353。其他常见的英文词向量相似度/相关性评测集信息表[7]如表1所示。评测集中的分数表示相似度,相似度越高,分数越高;0表示单词完全不相关,单词与其自身的相似度为10。Faruqui等[8]根据Finkelstein建立的评测集构建了词向量评测系统,该系统可以评测英文词向量性能。

表1 英文词向量相似度/相关性评测集信息表
续表
汉文词向量评测集建设方面,Peng Jin等[9]于2012年研究了汉文词向量评测集构建技术,他们首先对Finkelstein等人建立的英文评测集中的单词对进行翻译。翻译工作由3人完成,其中两人平行翻译每个单词对,第三人在前两人的基础上统一翻译结果。然后组织20名本科生对数据进行主观打分,要求每名学生为单词对分配0到5之间的相似度和相关性分数,从而构建了用于汉文词向量相似度和相关性评测的数据集Wordsim296和Wordsim240。评测集中的分数表示相似度或相关性。相似度或相关性越高,分数越高,0表示单词完全不相关,5表示单词非常密切相似或相关。Xinxiong Chen等[10]在研究汉文词向量表示时构建了一个含1 125组汉文词汇类的比评测集,包括3个类比类型: ①国家的首都(687组); ②城市的州/省(175组); ③家族(240组)。
国内少数民族语言文字的词向量研究刚刚起步,藏文词向量研究也处于探索阶段,到目前为止,只有才智杰等[11]提出的基于构件的藏文词向量模型,未见其他藏文词向量评测集构建的文献报道。
2 藏文词向量相似度和相关性评测集构建
2.1 藏文词向量相似度和相关性评测集构建方案
藏文词向量评测集包括词向量相似度评测集、相关性评测集和词汇类比评测集,借鉴英文和汉文词向量评测集建立过程,我们设计了藏文词向量相似度和相关性评测集构建方案。方案包括藏文单词对选取、评测集数据采集、评测集数据的有效性分析和评测值计算等四步。藏文词向量相似度和相关性评测集构建方案如图1所示。

图1 藏文词向量相似度和相关性评测集构建方案
2.2 藏文词向量相似度和相关性评测集构建及有效性分析
根据藏文词向量相似度和相关性评测集构建方案,可以按以下步骤建立藏文词向量相似度和相关性评测集。
第一步: 藏文单词对选取
在汉文词向量评测集构建时,单词对选取采用了翻译英文单词对的方法。由于藏语的语言背景不同于英文和汉文,英、汉文中所选的词在藏文中很少使用或不使用。因此,藏文词向量中的单词对选择不适合采用翻译汉文单词对或英文单词对的方法,我们采用了从语料中自行选取的方案。选取藏文词向量相似度和相关性评测集的单词对时,我们对藏语语料进行了分类和分词,并对语料中的词进行频度统计。根据藏文的实际使用背景,从语料中自行选取单词对,选取标准如下。
(1) 从语料中选取单词对
我们从青海师范大学建立的分词语料中选取相似度和相关性评测集的单词对,语料包括文学、政论和藏医三个领域,语料大小为18.07MB,共1 258 980个词。其中文学类语料大小为6.64MB,含485 815个词,占总词条数的38.59%;政论类语料大小为8.53MB,含542 230词,占总词条数的43.07%;藏医类语料大小为2.90MB,含230 935词,占总词条数的18.34%。
(2) 单词对数量
选取用于建立藏文词相似度和相关性评测集的单词对215个。
(3) 各语料中单词对选取比例
从语料的高频词中按比例选取单词对,从文学类语料中选取用于建立词相似度和相关性评测集的85个高频词对,约占总词对数的39.50%;从政论类语料中选取用于建立词相似度和相关性评测集的90个高频词对,占总词对数的41.86%;从藏医类语料中选取用于建立词相似度和相关性评测集的40个高频词对,占总词对数的18.60%。藏文词向量相似度和相关性评测集词对选取比例见表2和图2,表2中Type表示语料类型,Size表示语料大小,TW_n表示语料中所含词条数,TW_P表示语料中所含词条在总词条数中所占比例,TSim_n表示相似度评测集中的词对数,TSim_P 表示相似度评测集中的词对数在总词数中所占比例,Rel_n表示相关性评测集中的词对数,TRel_P表示相关性评测集中的词对数在总词数中所占比例。

表2 评测集词对分布表
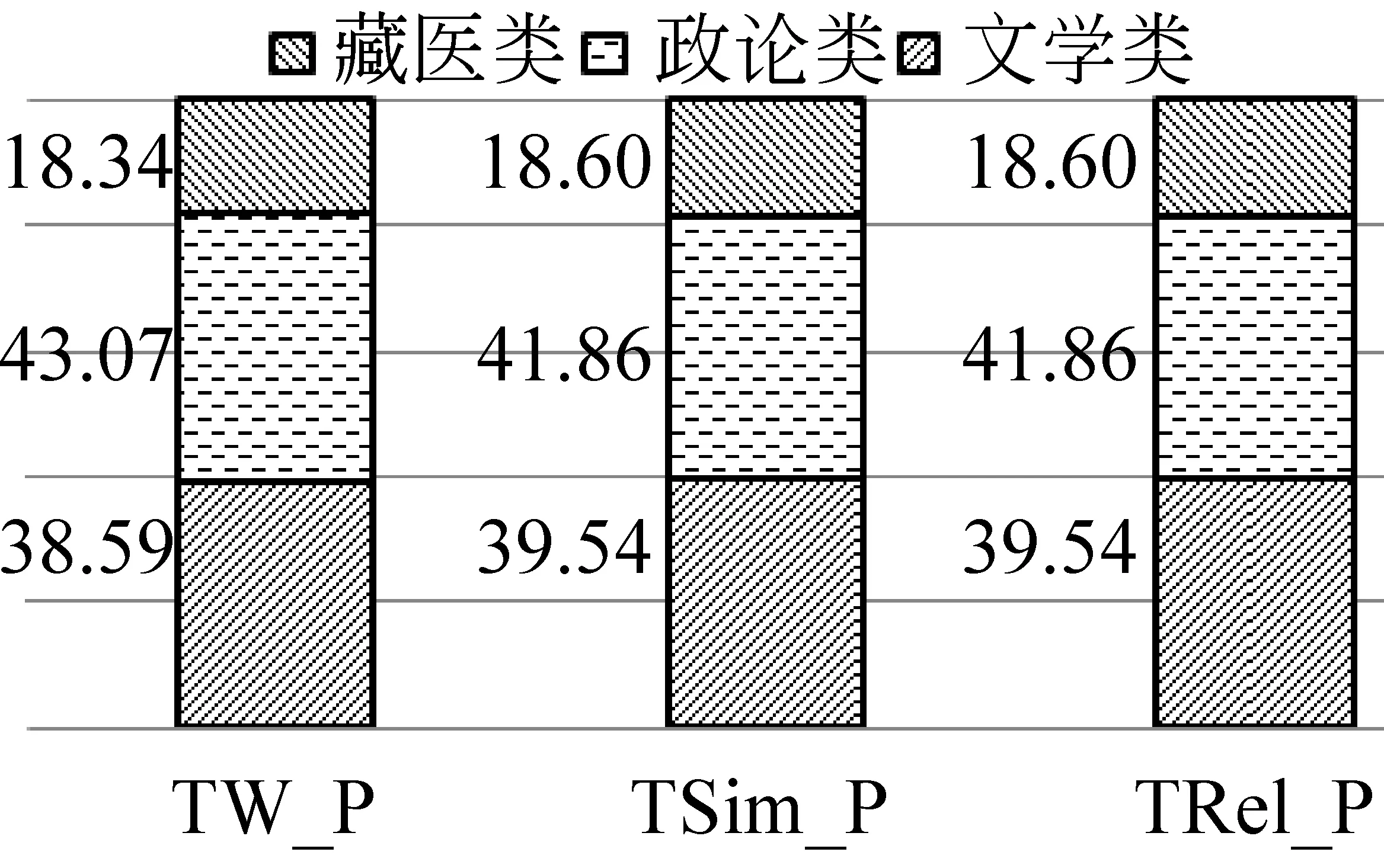
图2 评测集词对分布图
第二步: 评测集数据采集
采集数据时,我们挑选了10名从事藏语自然语言处理的研究生和20名藏语水平高的本科生,对选定的单词对用0到5之间的实数从相似度和相关性两方面主观打分。相似度和相关性分数表示词对间的相似度和相关性,取值越大表示两个词间的相似度或相关性越高,0表示单词完全不相关,5表示单词非常密切地相似。每个人的主观打分对词向量评测数据都有直接的影响,而且相似度和相关性打分在实际操作时很难把控。为了获得比较逼近真实词向量评测的数据,打分前我们对选定的人员进行了有关相似度和相关性的培训,并进行模拟评分。为了防止培训和模拟评分时的举例影响主观打分,规定培训和模拟评分中的词不能出现在我们已选定的评测中。根据第三步的方法对模拟得分进行有效性分析,有效性分析通过后,将选定人员组织在一起以考试方式对评测集数据进行主观打分,以获取评测数据。打分时,人员间不能互相交流,不理解的词汇可以查阅我们提供的《藏文大词典》和《藏汉对照大词典》。
第三步: 评分数据的有效性分析
评测数据的有效性决定最终建立的词向量评测集的可靠性。完成第二步评分数据采集后,我们对采集到的数据进行了有效性分析。如果采集的数据无效,则重新评分,直到评分数据有效为止。有效性问题包括评分数据缺失和评分数据失真两种类型。评分数据缺失的情况,通过设置具有评分数据缺失的文件无法提交的方法得以解决。我们对评分数据用标准差(standard deviation,SD)和相对标准偏差(relative standard deviation,RSD)分析其是否出现失真的现象。如果某单词对的评分数据标准差SD和相对标准偏差RSD比较大,说明该单词对的评分数据出现了失真现象,此时应重新采集该单词对的评分数据。
标准差是反映一组数据离散程度的最常用的量化形式,揭示一组数据与平均值的分散程度。标准差较大,说明大部分数值和其平均值之间差异较大;标准差较小,说明这些数值较接近平均值。相对标准偏差揭示不同数据组在其均值上波动的相对大小。
第四步: 相似度和相关性评测值计算
相似度和相关性利用加权平均值计算,其中研究生的分值权为0.6,本科生的分值权为0.4。这是因为研究生从事该领域研究,对相似度和相关性的理解较为深入,而本科生虽然参加培训,但仍对相似度和相关性的理解较为肤浅。
通过以上方案,我们建立了用于评价藏文词向量相似度的评测集TWordSim215和相关性的评测集TWordRel215。评测集中单词对(word pairs)的相似度和相关性评分分布见表3和图3,相似度评分等级(Rank)前10个和后10个单词对及分数(Score)、评分数据的标准差(SD)和相对标准偏差(RSD)见表4和表5,相关性评分等级前10个和后10个单词对及分数、评分数据的标准差和相对标准偏差见表6和表7,相似度评分与相对标准偏差之间的关系见图4,相关性评分与相对标准偏差之间的关系见图5,相似度评分的标准差与相对标准偏差之间的关系见图6,相关性评分的标准差与相对标准偏差之间的关系见图7。

表3 评测集评分分布表
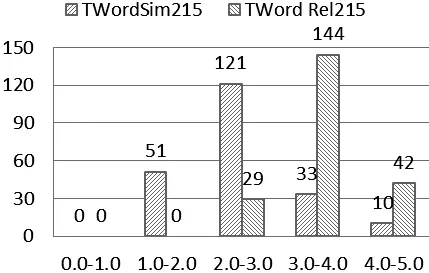
图3 评测集评分分布图

表5 相似度评分等级后10的评分数据表

表6 相关性评分等级前10的评分数据表
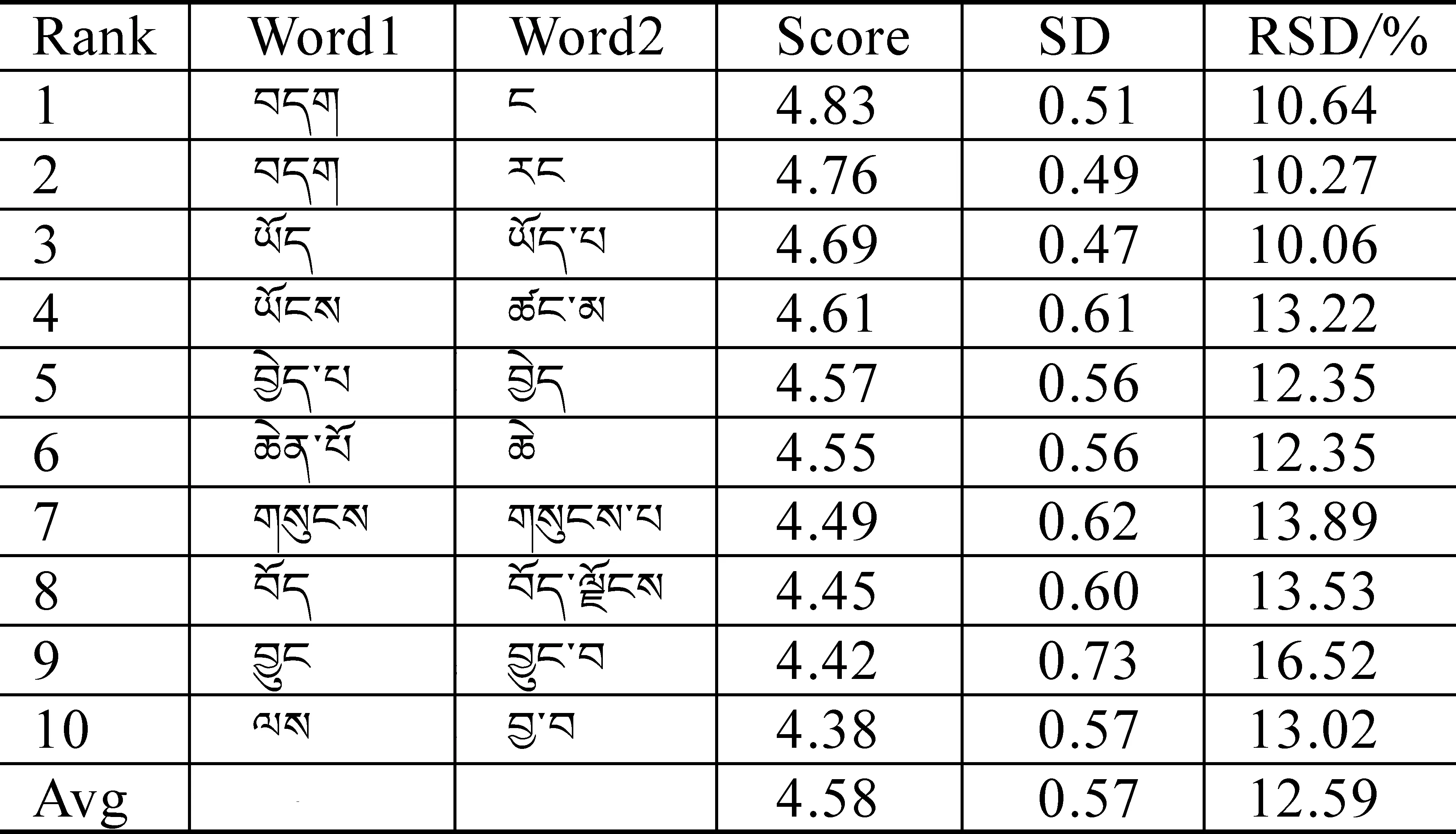
表7 相关性评分等级后10的评分数据表

从表3和图3可以看到,TWordSim215相似度评测集的分数主要集中在2.0~3.0之间,0~1.0之间的得分数为0,1.0~2.0和4.0~5.0之间的得分情况基本相同,呈现正态分布;TWordRel215相关性评测集的分数主要集中在3.0~4.0之间,2.0~3.0和4.0~5.0之间的得分也基本相同,而0~2.0之间没有得分。说明相似度的要求比相关性的要求高。表4、表5、表6和表7给出了TWordSim215相似度和TWordRel215相关性评测集Rank等级前10和后10的单词对和评分,前10对单词得分的平均值分别为4.50和4.58,后10对单词得分的平均值分别为1.49和2.60,整体得分与我们主观认识一致。图4~图7是TWordSim215相似度和TWordRel215相关性评测集的评分、标准差和相对标准偏差之间的关系图,说明了以下两点: ①最大相对标准偏差为0.9,评分低的相对标准偏差较大(没有超过1,在有效性范围内),随着得分的提高相对标准偏差越来越小,最小的相对标准偏差为0.1,基本集中在0.5左右。特别地,TWordRel215相关性评测集的标准差基本小于0.5。②标准差和相对标准偏差对应的两条曲线基本重合,说明标准差和相对标准偏差也基本稳定。综合以上分析,说明我们建立的相似度评测集TWordSim215和相关性评测集TWordRel215是有效的。

图4 相似度评分Score与RSD关系图

图5 相关性评分Score与RSD关系图
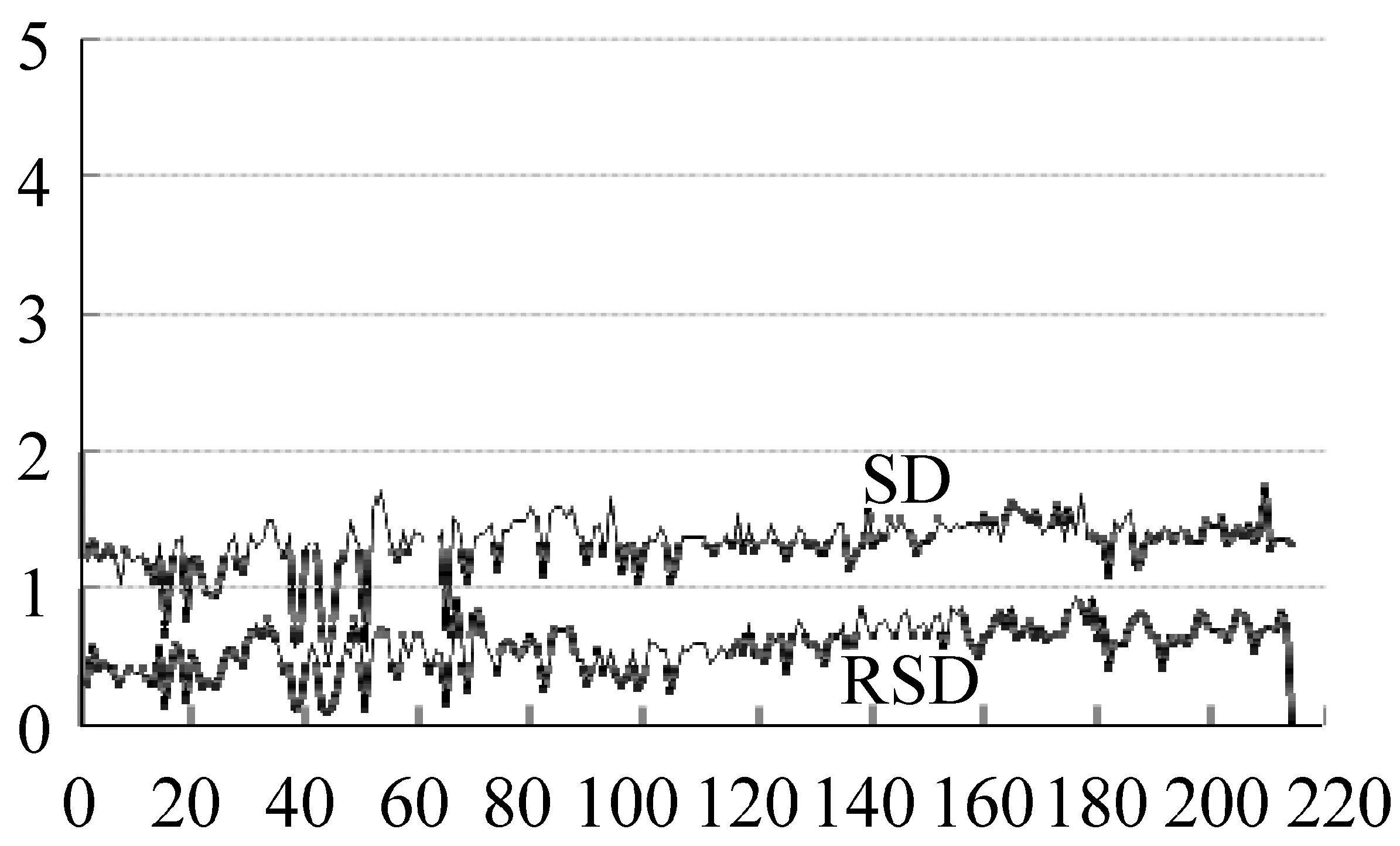
图6 相似度评分的SD与RSD关系图

图7 相关性评分的SD与RSD关系图
3 藏文词向量相似度和相关性评测
3.1 藏文词向量相似度和相关性评测方法
相似度评测和相关性评测,是通过评测集评估模型产生的词向量对词之间的语义紧密度和相关性的表示能力,既是衡量词向量表示效果的重要技术指标,也是一种常用的词向量评测方式,采用Spearman等级相关系数进行评测。Spearman等级相关系数是衡量两个变量的依赖性的指标,利用单调方程评价两个统计变量的相关性。Spearman等级相关系数中,如果数据没有重复值,并且当两个变量完全单调相关时,Spearman相关系数则为+1或-1。对于容量为n的样本,相关系数ρ的计算如式(1)所示。
(1)
具体评测过程如下:
第一步: 选择一个词向量相似度和相关度评测集。在藏文词向量相似度和相关性评测时可以选择我们建立的藏文词向量相似度评测集TWordSim215和相关性评测TWordRel215。
第二步: 对TWordSim215和TWordRel215中的评分进行排序。
第三步: 用词向量模型生成词向量,求出TWordSim215和TWordRel215中每个单词对的词向量。根据词向量计算单词对之间的相似度分数,以词向量的余弦相似度作为词的相似度分数。
第四步: 对生成的词向量也进行排序。
第五步: 计算TWordSim215和TWordRel215中的评分与模型生成词向量相似度分数的Spearman相关系数。
3.2 藏文词向量相似度和相关性评测实验
Word2Vec是谷歌公司2013年发布的一款基于神经网络的词向量表示开源工具包,包含Mikolov等提出的CBOW和Skip-gram模型[12]。CBOW和Skip-gram模型采用了比较简洁的神经网络算法,并通过Hierarchical Softmax、Negative Sampling等手段进一步降低了计算复杂度。因此可在大规模语料库上以较快的速度计算出词向量,在捕捉词之间的语义相似度或相关性上效果突出,在全球范围内迅速产生了广泛影响。
LSA在基于矩阵的向量表示中是一种比较好的算法,它将term-document矩阵进行奇异值分解,从而得到词的向量表示和文档的向量表示。LSA和Word2Vec作为两大类方法的代表,LSA利用全局特征的矩阵分解方法,Word2Vec利用局部上下文的神经网络方法。GloVe模型将这两个特征相结合,使用了语料库的全局统计特征和局部的上下文特征(即滑动窗口),在词向量表示上取得了比较好的效果。
正如文中所述,到目前为止未见有关藏文词向量的研究文献报道,也没有藏文词向量评测集,更没有可比较的实验数据。为了考察我们建立的藏文词向量评测集的有效性和得到藏文词向量表示实验数据(可作为以后研究藏文词向量的baseline),我们以青海师范大学建立的分词语料作为训练语料,选用目前效果最佳的GloVe、CBOW和Skip-gram模型建立藏文词向量,并做了词向量评测实验。训练语料包括文学、政论和藏医三个领域,语料大小为18.07MB,共1 258 980个词。
我们通过大量的实验,观察了基于GloVe、CBOW和Skip-gram模型的超参数对藏文词向量表示效果的影响,并与基于GloVe、CBOW和Skip-gram模型的英文和汉文词向量表示效果进行了对比。首先观察到,在相同模型下英文、汉文和藏文词向量相似度和相关性评测数据基本一致,说明我们建立的藏文词向量评测集有效。其次,在超参数对模型的影响方面,学习率alpha对藏文词向量影响不大,向量维度(dimsize)、窗口大小(window)、迭代次数(iter)、截断阈值(xmax)和负采样或分层Softmax对模型影响较大,可得出如下结论: ①GloVe模型的学习率alpha取0.75,CBOW和Skip-gram模型的学习率alpha取0.025比较合适; ②其他参数相同的情况下,负采样的速度比分层Softmax快3倍; ③GloVe模型的向量维度(dimsize)取50,CBOW和Skip-gram模型的向量维度(dimsize)取300比较合适; ④GloVe模型的窗口大小(window)取15,CBOW和Skip-gram模型窗口大小(window)取5比较合适; (5)CBOW模型的负采样下藏文词向量表示效果最好。
基于GloVe、CBOW和Skip-gram模型的英文[13]、汉文[12,14]和藏文词向量表示实验数据如表8所示。CBOW和Skip-gram模型的藏文词向量表示中列出了负采样和分层Softmax下相似度评测集TWordSim215和相关性评测集TWord-Rel215的Spearman相关系数最大的数据,其中CBOW模型的hs=0时TWordSim215和TWord-Rel215 Spearman相关系数同时取到了最大。
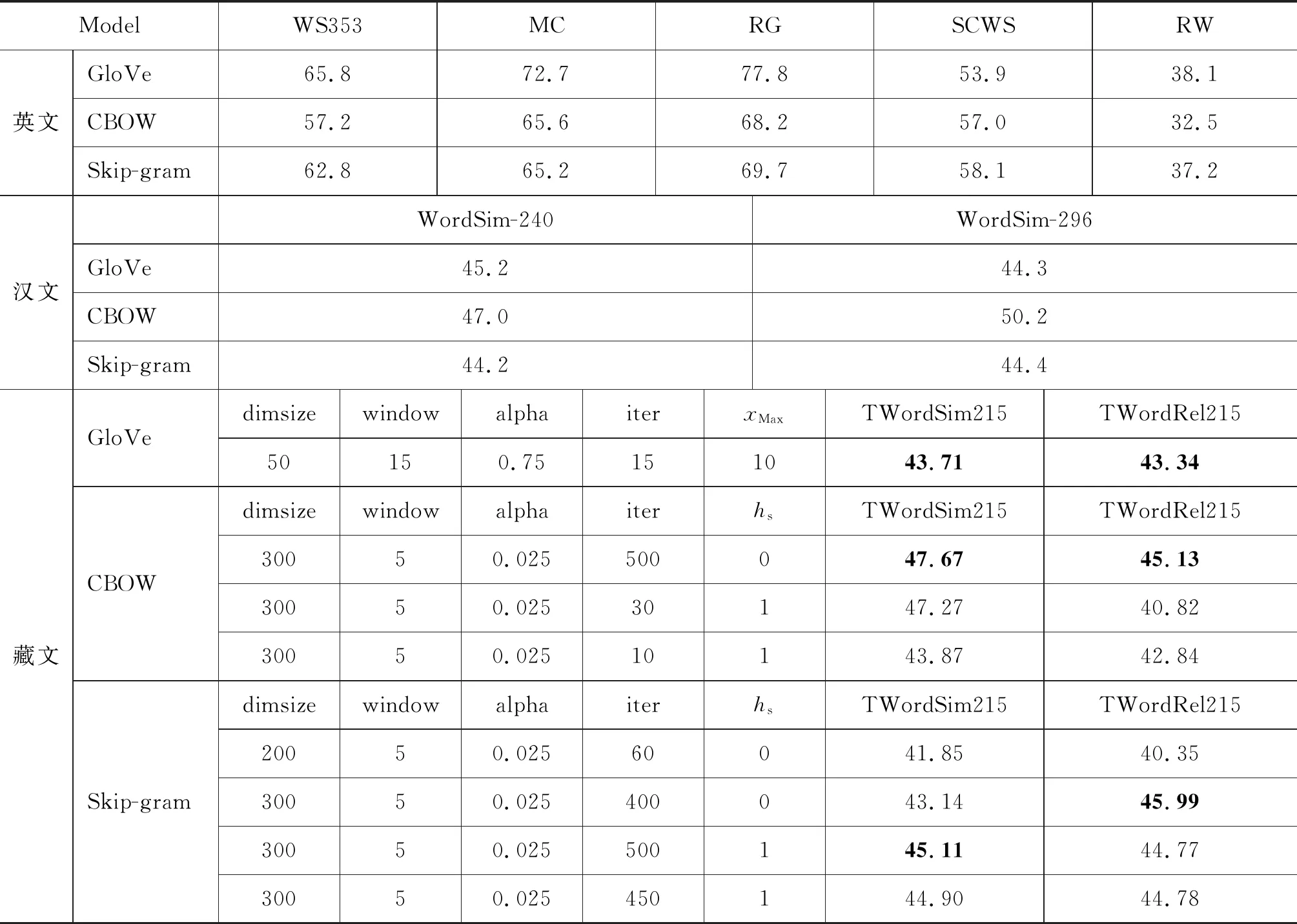
表8 基于GloVe、CBOW和Skip-gram模型的词向量表示实验数据
4 结论
本文通过剖析英文和汉文词向量评测集构建方法,设计了藏文词向量相似度和相关性评测集构建方案,根据此方案构建了藏文词向量相似度评测集TWordSim215和相关性评测集TWordRel215,并验证了其有效性。同时给出了藏文词向量表示性能评测方法,并选用目前效果最佳的词向量表示模型GloVe、CBOW和Skip-gram模型建立了藏文词向量,为研究藏文词向量表示及基于神经网络的藏文词法和句法分析技术奠定了基础。
猜你喜欢
科学技术创新(2021年19期)2021-07-16 10:07:18
家庭影院技术(2021年2期)2021-03-29 07:19:02
家庭影院技术(2021年1期)2021-03-19 05:14:58
布达拉(2020年3期)2020-04-13 10:00:07
西夏学(2019年1期)2019-02-10 06:22:34
中国自行车(2018年11期)2018-12-03 08:20:30
中国自行车(2017年1期)2017-04-16 02:54:06
西藏大学学报(自然科学版)(2016年1期)2016-11-15 05:23:31
新闻传播(2016年17期)2016-07-19 10:12:05
科技与创新(2016年10期)2016-05-28 03:17:18
