
融合单词翻译的神经机器翻译
2019-08-05 06:49:32李军辉周国栋
中文信息学报 2019年7期
韩 冬,李军辉,周国栋
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
神经机器翻译(neural machine translation,NMT)是当前机器翻译的主流方法,其在多种语言对上翻译效果超过了传统的统计机器翻译[1-3]。如今,大部分神经机器翻译包含一个编码器和一个解码器,编码器读入源端序列,输出固定长度的句子向量表示[4-5]。解码器根据源端的向量产生正确的翻译。2017年Vaswani等[6]提出的Transformer结构取得了机器翻译的最优效果,该网络区别于基于循环神经网络的机器翻译,舍弃了循环神经网络[7]和卷积神经网络[8],仅仅通过自注意力机制进行编码与解码。Transformer克服了原有以循环神经网络为基础的机器翻译系统无法并行的缺点,显著地提升了整体效率,节省了大量训练时间。
在NMT中,为了建模单词与单词之间的相关性,每个单词均被表示为一组连续的向量,使得语义相近的单词具有相似的向量表示。但是,从理论上讲,通过这种方法,每个源端单词存在着一定的翻译为目标端任意单词的可能,造成虽然译文通顺,但是翻译结果中存在着大量的单词错误翻译现象[9-10]。例如,图1中给出一个源句子及其翻译结果的例子。其中,基准系统Transformer将源端词“官位”错误地翻译为“life”,而正确的翻译应该为“official position”。针对该基准系统,关于单词翻译错误的更详细分析,见本文第2节。
图1中,Transformer指本文采用的基准系统,Ours指本文提出的融合单词翻译的系统。
针对上述错误翻译现象,本文提出一种融合单词翻译用于增强源端信息的神经机器翻译方法,能够在一定程度上避免源端单词错误翻译。例如,如果预先能够判断源端单词“官位”的目标端翻译为“official”,通过编码器将该目标端单词信息进行编码,将有利于目标端做出正确的译文预测。具体地,该方法首先通过查字典的方式为源端单词找到对应的最有可能的在目标端的单词翻译,如图1中的‘WT’序列所示。然后将单词翻译作为额外的输入,让编码器自动学习到有用的信息。为此,本文提出了两种不同的编码器: Factored编码器和Gated编码器,用于对源端单词与其单词翻译进行融合。其中,Factored编码器采用直接相加的方式利用全部的单词翻译信息。考虑到通过字典方法查找单词翻译存在着错误的情形,进而本文又提出一种Gated编码器的方式,旨在通过门机制控制单词信息的读入,从而使系统有选择性地利用单词翻译提供的信息。在中英翻译上的实验表明,本文提出的两种方法均能有效地提高翻译的质量。其中,Gated编码器方法与原有的Transformer系统相比,BLEU值获得了0.81个点的提升。此外,本文最后从不同的方面比较分析了所提出系统之间的不同与优缺点。
1 Transformer
本节将简要地描述本文的基于自注意力机制的神经机器翻译系统Transformer,该系统包含一个编码器和一个解码器。与基于循环神经网络的机器翻译不同,Transformer编码器和解码器由一种新颖的注意力机制和一个前馈的神经网络构成。作者命名这种新颖的注意力机制为“多头注意力机制”(multi-head attention)。同时,一个“多头注意力机制”又由多个点积注意力机制通过三个向量Q,K,V计算得到:
(1)
其中dk指向量K的维度。
最终,多个点积注意力机制的结果进行拼接后送入一个前馈神经网络中:
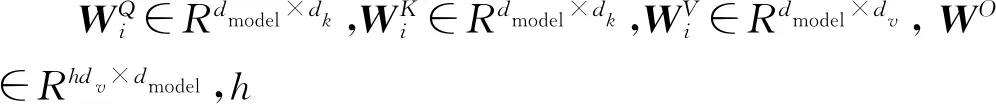
前馈神经网络为两层的全连接网络层,并且使用“修正线性单元”(RELU)作为其激活函数。该网络定义为:
FFN(x)=max(0,xW1+b1)W2+b2
(4)
其中,W1,W2,b1,b2为模型参数。在Vaswani[6]等的论文中,设置输入输出的维度均为512维,隐层的维度设置为2 048维。
由于Transformer结构既没有使用循环神经网络,也没有使用卷积神经网络,因此,为了弥补输入序列顺序上的缺失,Transformer使用了一种叫做位置编码的方法在编码和解码词向量后增加了表示位置的信息,该信息是一种绝对的位置信息,被定义为:
(5)
其中,pos是单词在输入句子中的位置,i是向量的维度。
2 Transformer中的单词错误翻译问题
单词的错误翻译问题是机器翻译面临的一大难题。大量的科研工作者为了减少单词错误翻译的现象,做出了不懈的努力[10-11]。Transformer的提出为机器翻译注入了新的活力,与原有的以循环神经网络为基础的翻译系统相比,Transformer在多种语言对上取得了当前最优的效果。因此,很自然会存在这样的疑问: 在Transformer系统的译文中,单词错误翻译的现象是否依旧严峻?到底有多少单词在Transformer系统中被错误地翻译?
由于很难准确地计算机器翻译中单词翻译的正确率,本文采用近似的方法,按两种不同的方式计算单词翻译准确率。
方式一: 为了得到每个源端单词在目标端对应的单词翻译,使用词对齐工具fast-align[12],得到源端句子与机器译文之间的词对齐,进而得到源端单词在目标端的单词翻译。特别地,如果源端单词与多个目标端单词对齐,仅考虑单词翻译概率最大的那个单词。同样地,可以为源端单词得到其在参考译文上的对齐目标单词,并看作是该源端单词的正确单词翻译。比照其在自动译文及参考译文上的单词翻译,可以判断该源端单词是否翻译正确。
方式二: 考虑到上述方法的有效性依赖于词对齐的结果。特别是,给定源端句子与机器译文时,由于源端句子与自动译文本身在语义上可能是不等价的,在此句对上得到的自动对齐会存在错误。因此,对每个源端单词,我们按照方式一获取它的正确译文,再查看该译文是否出现在自动译文中。如果出现,则认为该单词翻译正确,否则翻译不正确。
表1给出了分别按以上两种方式计算的源端单词翻译的正确率。由于第一种方式的判断条件要比第二种方式更严格,因此其得到的准确率较第二种方式低。从表1中可以得出一个结论: 即使Transformer能够较显著改善译文的质量,但是Transformer中单词错误翻译的现象依旧十分严峻。例如,即使第二种计算方式较宽松,根据其计算结果,仍然存在有约20%的单词未正确翻译。

表1 Transformer中单词翻译的准确率(%)
3 Transformer中融合单词翻译
为了缓解Transformer中单词错误翻译的问题,本文提出在Transformer翻译框架中融入单词翻译的方法,使得翻译模型能够根据提供的单词,选择正确的译文。特别地,本文将单词翻译作为额外的输入,让翻译模型去学习有用的信息来辅助生成译文。本节首先采用字典方法为每个源端单词找寻课文;然后提出两种不同的编码器来实现单词及其翻译结果的融合: Factored编码器和Gated编码器;最后分析了这两种结构的不同与优劣。
3.1 字典方法获取单词翻译
对于源端单词xi,通过单词翻译字典寻找其对应最大概率的单词翻译结果,如式(6)所示。
(6)
其中,Vt是目标端单词的词表,Plex(w|xi)是源端单词xi翻译为目标端单词w的概率。
为了得到单词翻译的字典,本文首先使用Giza++在机器翻译语料上得到源端单词到目标端单词的对齐信息,进而通过该对齐信息计算单词的翻译概率。需要注意的是,如果源端单词没有对齐的目标端单词,那么则用特殊标记“NULL”表示。
通过上述的方法,可以为每个源端单词获取其最大概率的目标端翻译单词。这种方法忽略了单词翻译的多样性,相同源端单词的单词翻译都是一样的。例如,虽然源端单词“中”可以翻译为China、Sino、in等,字典方法都简单地将“China”视作“中”的单词翻译,因为在给定源端词“中”的条件下,此翻译的概率最高。
3.2 融合单词翻译到Transformer
单词翻译可以视作额外的信息,用以辅助生成正确的译文,本文提出了两种不同的编码器,用于融合单词与单词翻译。
3.2.1 Factored编码器
与Sennrich等[13-14]的工作相似,本文将单词翻译作为额外的特征直接加入到编码器中,假设源端单词xi和其翻译词ti对应的词向量分别为exi与eti,那么最终输入到编码器中的词向量ei为:
ei=exi+eti
(7)
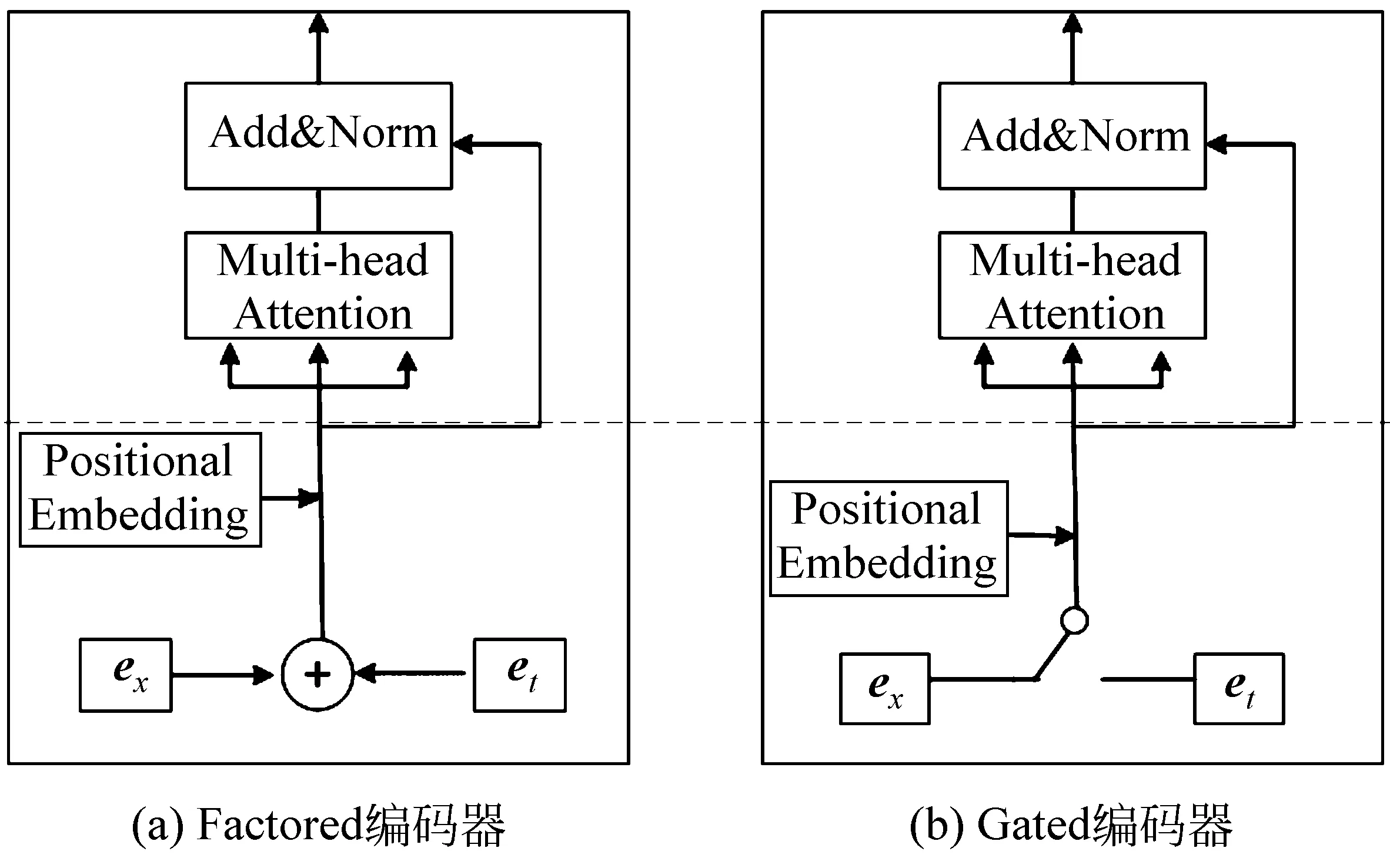
图2 Factored编码器和Gated编码器
图2(a)显示了本文Factored编码器方法。该方法将单词翻译信息全部用到编码器中,是最为直接的一种方法。这种方法将单词与单词翻译看作是等价的输入,并没有彼此区别的对待。
3.2.2 Gated编码器
由于字典方法采用一刀切的方式,使得相同源端单词对应的单词翻译也相同,而忽略了源端单词所处的上下文信息。因此,该方法得到的单词翻译结果势必存在错误,从而负面影响了译文的质量。为此,本文提出了另外一种方法: Gated编码器,旨在通过一个门机制选择性地控制单词翻译进入编码器的信息量。正如图2(b)显示的,输入到编码器中的词向量ei表示为:
ei=exi+g∘eti
(8)
其中“∘”为元素相乘,“g”为门机制,计算如下:
g=σ(Wxexi+Wteti+b)
(9)
其中,σ为sigmoid激活函数.Wx∈Rd×d,Wt∈Rd×d,b∈R1×d模型待训练的参数,d为词向量大小。
3.2.3 Factored编码器与Gated编码器的比较
(1) 参数比较
在两种不同的编码器中,单词翻译的词向量与目标端单词的词向量是共享的。在Factored编码器中,仅将源端单词的词向量与单词翻译词向量相加,输入到编码器中的向量维度和基准系统的输入维度相同,因此该编码器并没有引入额外的参数。对于Gated编码器,需要增加(2*d+1)d个参数,这些参数均用于式(9)中计算门机制的值。
(2) 利用单词翻译方式比较
Factored编码器采用简单但一刀切的方式,使系统在翻译时考虑了单词的翻译信息,虽然这种方法能够学习到有用的信息,但是对于错误的单词翻译,该方法并没有甄别的能力。Gated编码器可以看作是对Factored编码器方法的改进, 通过门机制赋予了该系统一定的自主选择单词译文的能力,对于错误单词翻译,该方法自动挑选了最有利于最终翻译的信息,使得系统自动学习到甄别单词翻译是否正确的能力。
4 实验
本文实验使用中英NIST翻译数据,训练语料是从LDC数据中抽取的1.25MB句对的平行语料[注]其中包括了: LDC2002E18, LDC2003E07, LDC2003E14, LDC2004T07,LDC2004T08和LDC2005T06。,分别含有27.9MB的中文单词和34.5MB的英文单词。选择NIST MT 06 数据集为开发集,含有1 664句。NIST MT 02、03、04、05作为测试集,分别含有878、919、1 788、1 082句。
4.1 Transformer 系统设置
为了有效地训练实验模型,本文分别从中英训练语料中抽取词频最高的前30K个单词作为其词表,其中中文词表覆盖整个训练语料的97.3%,英文词表覆盖率为99.3%。所有不在词表中的单词被表示为“UNK”特殊标记符号,限制源端和目标端句子最大长度为256,单词超过256的句子被舍弃。使用6层编码器与解码器,“多头注意力机制”含有8个头,同时设置Pdropout=0.1。单词词向量和隐层状态维度均为512维。
实验使用Adam模型[15]更新参数,设置β1=0.9,β2=0.98,使用GTX 1080训练模型,翻译性能的评测为BLEU[16]值。在解码时,设置beam_size=4,batch_size=32,所有其他的设置使用Vaswani系统中的默认设置。
4.2 实验结果
表2给出了本文提出的两种编码器与基准系统在各测试集上的翻译性能。从表2可以看出,本文提出的两种编码器均能够提高系统的翻译性能。特别地,与基准系统相比,Gated 编码器较基准系统提升了0.81个 BLEU值,这表明了文中提出的融合单词翻译方法的有效性。另一方面,即使利用相同的信息,Factored编码器较基准系统仅仅使BLEU值提升了0.14个点。这说明,虽然单词翻译可以在一定程度上提供有用的信息,但如果不区分单词翻译的好坏(如Factored编码器),完全利用单词翻译信息,容易造成错误传播,使得翻译系统学习到错误的译文;而Gated编码器采用门机制控制单词翻译的信息流入编码器,使得模型能够在一定程度上学习筛选有用的单词翻译信息,减少单词错误翻译对后续翻译模型的影响。

表2 本文方法与基准系统在不同测试集上的BLEU值
注: ALL为将02,03,04,05测试集拼接后测试的结果;=|: 与Transformer基准系统相比较,BLEU值在p=0.01时具有显著性提高。
5 实验分析
从第4节中可以看出,融合单词翻译到机器翻译系统中,即使在强基准中(Transformer)依旧可以提高最终的实验效果。本节进一步从几个不同的方面分析单词翻译对最终机器翻译性能的影响。
5.1 字典获取翻译的准确率分析
为了增强整体模型对语义的建模,本文引入了单词翻译作为额外的信息。理论上,正确的单词翻译可以提供更多有用的信息,而错误的翻译可能降低系统最终的翻译质量。因此,我们首先分析本文使用的字典方式获取单词翻译的准确率。在开发集上根据源端句子与参考译文,使用fast-align工具获取源端句子与参考译文之间的词对齐信息,从而得到每个源端单词的正确译文。然后再把源端单词按字典方式获取的译文当作机器译文,计算字典获取翻译的准确率。结果显示,字典方法单词翻译准确率在开发集上为61.2%。从中可以看出,虽然采用字典的方法获取单词翻译存在错误,但是依旧有较大部分比例的单词能够获取正确的译文,可以提高句子翻译的质量。
5.2 翻译准确率分析
类似于第2节的分析,从两个不同的方面分析本文提出的Factored编码器和Gated编码器方法译文的准确性,表3呈现了两种方法和基准系统的对比。从中可以看出,本文的Gated编码器在两种不同的评测方法上均超过原有的Transformer 基准系统,其中,采用方式二的评测方法,与基准系统相比,准确率提高了1.2%。这也进一步说明了,本文的Gated编码器采用门机制,能够有选择性地使用正确的单词翻译,缓解单词翻译错误带来的负面影响。另一方面,Factored编码器将单词翻译的信息全部流入编码器,容易受单词翻译错误的影响。同时,较之基准系统,Factored编码器在方式一和方式二的评测上并没有优势,说明本文按3.1节字典方式获取的单词翻译性能还不够好,有待进一步提高。
表3 Factored编码器,Gated编码器与基准系统单词翻译准确率比较(%)
5.3 长句子分析
类似于Bahdanau[1]等的工作,本文将句子按照单词长度划分,然后分别测试系统在不同长度的句子上的翻译性能。如图3所示,本文提出的Gated编码器和Factored 编码器方法在短句子上(<=30)要优于原本的Transformer基准系统。有趣的是,随着句子长度的增加,特别是当句子长度介于40和50之间时, Factored编码器的翻译性能甚至低于基准系统;而对于长句子(>50),Factored编码器和Gated编码器均优于基准系统。造成以上翻译趋势的原因在于,Factored编码器和Gated编码器的性能与单词翻译的准确率有着明显的关系。在短句子上(<=30),单词翻译的准确率较高,达到65.3%;在句子长度介于40~50之间时,单词翻译的准确率偏低,仅为58.1%;而对于长句子(>50),单词翻译的准确率上升为62.2%。

图3 不同长度句子翻译结果
6 总结
将单词翻译序列融入机器翻译中,使得系统在翻译时,考虑更多源端的语义信息,有利于翻译系统最终效果的提升。对于每个单词对应的翻译,本文采用字典的方法虽然含有不可避免的错误,在翻译字典中相同的源端单词的单词翻译是一样的,但是类似于源端单词词向量可以模拟不同的语义信息,这种方法依旧是可取的。
为了将单词及其翻译建模进系统中,本文创造性地提出了两种不同的编码器: Factored编码器和Gated编码器。Factored编码器无复制地将单词翻译与单词本身同等看待,直接相加,简单而且直观地使得系统在翻译时考虑到单词翻译信息。Gated编码器可以看作是对Factored编码器的改进,通过门机制自动选择单词的翻译信息,赋予系统一定的自主选择的权利。最终实验结果显示,本文采用的方法,即使相比当前最优的机器翻译系统Transformer,依旧取得了不错的效果。
在未来的工作中,我们将进一步探究两个方向: ①字典方法虽然可以找寻到对应的翻译,是否有其他更优的方法?②对于融合单词翻译进入系统的方式,是否有更加有效的方式?
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
中文信息学报(2019年8期)2019-09-05 12:33:36
数码世界(2019年4期)2019-05-10 09:52:54
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
电子设计工程(2017年20期)2017-02-10 03:39:29
科技视界(2016年22期)2016-10-18 15:53:02
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
读者(2016年14期)2016-06-29 17:25:50
电子器件(2015年5期)2015-12-29 08:42:24
