
多场景文本的细粒度命名实体识别
2019-08-05 01:42向政鹏王莉峰
中文信息学报 2019年6期
盛 剑,向政鹏,秦 兵,刘 铭,王莉峰
(1. 哈尔滨工业大学 社会技术与信息检索研究中心,黑龙江 哈尔滨 150001;2. 腾讯科技(深圳)有限公司,广东 深圳 518000)
0 引言
命名实体识别(named entity recognition, NER)是自然语言处理领域(natural language processing, NLP)的基础任务之一,也是信息抽取中最为重要的一个子任务,并且可以对后续的抽取任务提供帮助。命名实体识别任务意在识别文本中的事物的名称,例如人名、地名和机构名。本文主要在多场景多领域下研究命名实体识别,以LSTM-CRF为基础并引入CNN(卷积神经网络)从文本中进一步提取有用的语义特征。
早期的命名实体识别大多是基于规则的方法,但是由于语言结构本身具有不确定性,制订出统一完整的规则难度较大。基于规则的方法需要构造特定的规则模板,采用的特征包括统计信息、标点符号、关键字、位置词、中心词等,以模式和字符串相匹配为主要手段,尤其依赖于知识库和词典的建立。针对不同领域,需要专家重新书写规则,代价较大,存在规则建立周期长、移植性差且需要建立不同领域知识库作为辅助以提高系统识别能力等问题。
传统的命名实体识别方法大多采用有监督的机器学习模型,如隐马尔可夫模型[1]、最大熵[2-3]、支持向量机和条件随机场[4]等。最大熵模型具有结构严谨、通用性良好的特点,但训练时间复杂度高,需要明确的归一化计算[5],导致计算上的开销比较大。条件随机场在分词和命名实体识别上表现出色,提供了一个特征灵活、全局最优的标注框架,但同时存在收敛速度慢、训练时间长的问题。通常来讲,最大熵和支持向量机在正确率上比隐马尔可夫模型略高,但是隐马尔可夫模型在训练和识别时的速度要更快一些,主要是由于Viterbi算法在解码时具有较高的效率。基于统计的方法对特征的选取依赖性较高,需要从文本中分析选择对于此项任务影响因子较大的特征,并将这些特征加入到特征模板中,通过对训练语料所包含的语言语义信息进行统计和分析,进行有效的特征选择,从训练语料中不断发现强特征。有关特征可以分为具体的停用词特征、上下文特征、词典及词性特征、单词特征、核心词特征以及语义特征等。与基于规则的方法相似,基于统计的方法对于语料库的依赖性也较大,而建立较大的领域语料库又是一大难点。
Naturallanguageprocessing(almost)fromscratch[6]是使用神经网络进行命名实体识别较早的工作,文中,作者提出使用窗口方法和句子方法两种网络结构来进行命名实体识别。窗口方法的输入为预测词的上下文窗口,使用传统的神经网络进行求解。句子方法将整个句子作为当前预测词的输入,加入句子中相对位置特征来区分句子中的每个词,然后使用一层卷积神经网络求解。训练时作者提出两种目标函数,一是词级别的对数似然函数,使用softmax来预测标签概率,当成一个传统的分类问题来做;二是句子级别的似然函数,即考虑到CRF模型在序列标注任务中天然的优势,将标签之间的转移分数加入到目标函数中。这也是后来神经网络——CRF模型的先驱工作。
当前最好的实体识别模型是LSTM-CRF模型[7-8],该网络由两个长短时记忆网络组成,一个前向记忆网络和一个后向记忆网络,前者用于学习前向的序列信息,后者用于学习后向的序列信息,得到每个隐层的表示,将隐层映射到所需分类的特征维度,之后选取概率最大的一维作为其实体类别,该方法也称之为softmax[9]。尽管该模型在独立的序列标注任务中取得了成功,例如词性标注,但是该模型忽略了标签间的依赖关系,这一缺点导致了部分精度的损失。实体识别任务存在某些内在限制,例如I-PER 标签并不能接在B-LOC标签的后边。因此,用条件随机场模型(CRF)来学习标签之间的关系,而不是进行独立的标注。目前将神经网络和CRF模型相结合的模型已经成为命名实体识别的主流模型。由于RNN有天然的序列结构,所以RNN-CRF使用更加广泛。使用神经网络有天然的无需大量人工特征的优势,只需要词向量或者字符向量就可以达到主流的水平,加入高质量的词典特征可以进一步提升效果。
本文提出的细粒度命名实体识别算法以LSTM-CRF模型为基础,并引入CNN从文本中进一步提取有用的语义特征做实体边界划分,之后交给细粒度划分模块做小类别分类。第一步通过使用RNN对命名实体的上下文进行表示,并使用softmax分类确定该命名实体所属的大类别(即领域);第二步利用每个领域下的语料构建模型以确定命名实体所属的细粒度类别(小类别)。实验结果显示,命名实体识别的F1值在全领域上平均值达到80%左右,能在一定程度上说明实现的分阶段方案是有效的。
1 方法描述
本文实现的模型共包含三个模块:语料回标模块、命名实体识别模块、命名实体细粒度划分模块。在获取某个词条为命名实体后,则将该命名实体和命名实体的上下文交由细粒度的命名实体类别划分模块,先由模块确定该命名实体的大类别标签(所属领域),然后再确定该实体的小类别标签。对句子的识别提供了有交叉多标签的命名实体识别结果,即有可能出现输入“ABCDE”,识别结果为“AB”和“BC”为不同领域下的命名实体。另外,在对实体打标签时也会出现一个实体有多个标签的情况,类似于“马龙”可能是一个人名,也是一个体育明星,这时该方案会对命名实体提供属于多个领域的细粒度类别标签。
举例来说,输入文本为:
赵丽颖,1987年10月16日出生于河北省廊坊市,华语影视女演员,毕业于廊坊市电子信息工程学校。
输出文本为:
[赵丽颖][影视明星,人名],1987年10月16日出生于[河北省][地名][廊坊市][地名],华语影视女演员,毕业于[廊坊市电子信息工程学校][机构名,教育机构]。
该文本在经过12个领域的命名实体识别模块后,在传统、娱乐和教育领域均有命名实体被识别出来,将结果全部保留送入细粒度类别划分模型得到最终的分类。此例中,赵丽颖被识别成影视明星和人名,河北省和廊坊市被识别为地名,廊坊市电子信息工程学校被识别成机构名和教育机构名。
模型的整体结构如图1所示。

图1 模型整体结构
1.1 词典回标模块
在词典回标模块中,从网络中爬取了除人名、地名、机构名外其他类别下的细粒度命名实体词典。并从网络中爬取文本数据,利用词典回标数据形成大规模的训练集、开发集和测试集。
实现阶段发现,自动标注的数据里面有很多误标注的数据(噪声)存在,例如把“你的名字是什么”这句话标注为“[你的名字][影视剧]是什么”,即认为“你的名字”是个影视剧,但是显然该词条不是一个命名实体。
通过抽样分析,发现语料回标的质量不是很高,回标结果举例,如表1所示。
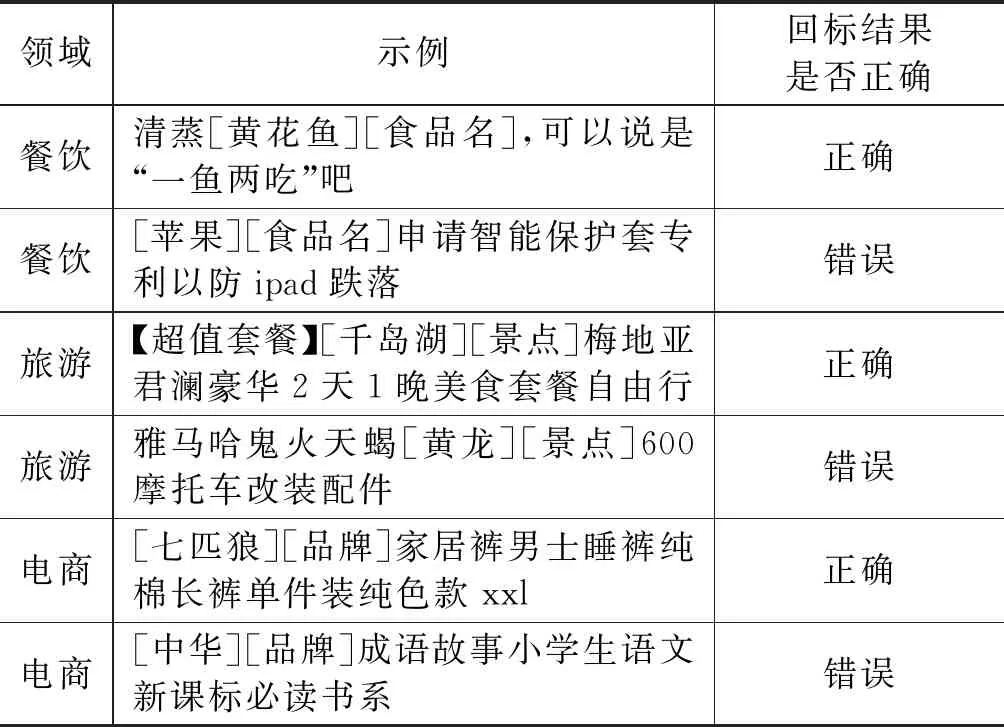
表1 回标结果举例
基于此类问题,人工对粗糙的机器标注的语料进行二次标注,得到了小规模的较为准确的标注语料。
1.2 命名实体识别模块
本文以LSTM+CRF构建基准的命名实体识别模块[10-11],引入CNN特征提取模块[12],用于识别输入文档中的命名实体。
卷积神经网络最早应用在计算机视觉任务上,如今也广泛应用在自然语言处理任务上。
卷积神经网络其实就是多层卷积运算,然后对每层的卷积输出用非线性激活函数做转换。卷积过程中每块局部的输入区域与输出的一个神经元相连接。对每一层应用不同的卷积核,每一种卷积核可以理解为是对一种特征进行提取,然后将多种特征进行汇总。
CNN在句子建模上有着广泛的应用,CNN强大的特征捕捉能力,使得在句子建模过程中,先组合底层邻近的词语信息,逐步向上传递,上层又组合新的短语信息,从而使得相距较远的句子也存在联系,这种联系通常是语义上的联系。
本文卷积的时候是整行进行的,卷积核的高为词向量的维度,宽为2、3不等。如图2最下方CNN提取句子特征部分所示,宽为2的卷积核对整个序列进行卷积得到维度为4的向量。对每个卷积核卷积得到的向量通过max pooling操作,将结果拼接在一起,得到的向量作为整个句子的表示。将此句子表示加入到LSTM获取到的每个词的上下文表示,从而使每个词可以既具有句子表示又可以具有词级别表示。
LSTM+CNN+CRF的基本结构,如图2所示。

图2 LSTM+CNN+CRF基本结构
LSTM+CRF为两层结构,其中输入表示层由双向LSTM组成,通过LSTM中的每个cell单元对输入文档进行编码,将隐层得到的输出与CNN提取的类似n-gram的特征进行拼接[13],通过全连接层进行tag分类,得到的矩阵为CRF层的发射矩阵[14]。
在CRF中,给定一个观察序列x,目的是希望找到一个概率最大的标记序列y。在命名实体识别任务中,x表示词序列,y表示命名实体标记。那么给定的概率可由式(1~3)计算:
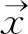

(4)
根据每个被识别出的命名实体在语料中出现的频率和命名实体的置信度(φ(Ne))设定阈值,然后选择大于阈值的命名实体作为可信的标注结果。
条件随机场的目标函数在考虑了状态特征函数的同时,还包含有标签之间转移特征函数。使用SGD学习模型参数,在给定已训练好的模型时,给定输入序列,预测输出序列使目标函数最大化的最优序列,是一个动态规划问题,使用维特比算法进行解码。
1.3 细粒度类别划分模块
本文将命名实体的细粒度类别划分切分为两个步骤:①根据命名实体及命名实体的上下文进行领域(大类别标签)的划分; ②根据第一步得到的领域信息(大类别标签)进行类别的细分,以得到命名实体的小类别标签。
本文模型采用Tang[16]提出的对句子中目标词的建模方法对命名实体的表示进行建模,这个模型在中文零指代消解任务[17]中也发挥了较大的作用。具体来说,在第一步通过使用两个单向LSTM对命名实体的上文和下文分别进行表示,再将上文的表示和下文的表示拼接在一起作为命名实体的表示,最后使用softmax分类确定该命名实体所属的大类别(即领域);第二步利用每个领域下的语料构建同样的模型,以同样的方式确定命名实体所属的细粒度类别(小类别)。在两个步骤中使用同样的模型,区别在于:第一个步骤分类的类别为12个领域,第二个步骤将训练12个分类器,每个分类器只对一个领域下的小类别标签进行分类。 模型结构如图3所示。
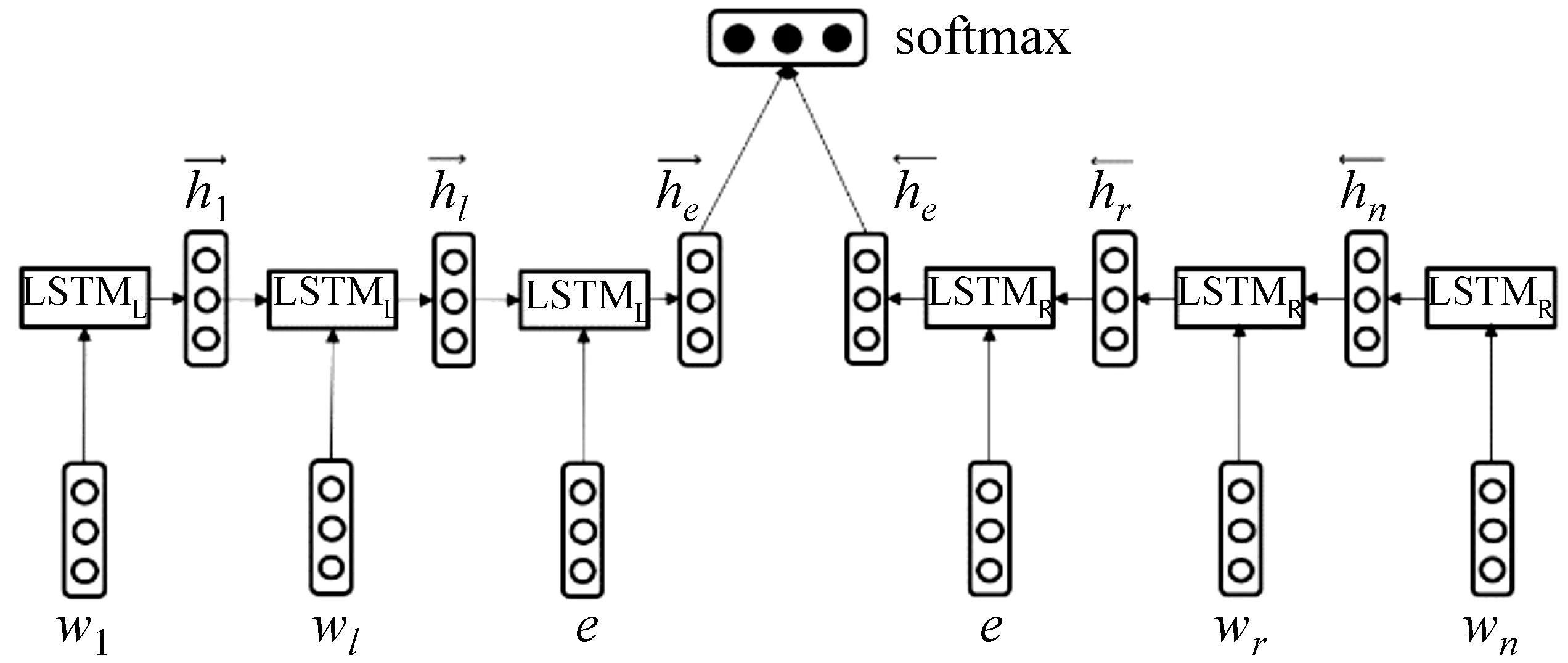
图3 命名实体建模模型

在建模命名实体的上下文时,本文对实体的表示按以下规则进行处理:
(1) 每次仅对一个命名实体进行分类;
(2) 句中如果有多个命名实体,则每次仅处理一个命名实体,将其余的部分都看作是上下文;
(3) 命名实体如果由多个词组成,直接将多个词看作是一个词。
实验过程中,第一个步骤使用12个领域语料的训练集进行训练(在训练的时候会对训练语料随机打乱顺序),然后在12个领域语料的开发集上进行模型的选择,最后保留在开发集上效果最好的模型。在第2个步骤中,对12个领域中每一个领域,分别按上述方法利用该领域的训练语料训练分类器,最终得到12个个分类器。每一个分类器都做一个领域下的命名实体的细粒度划分。
2 实验分析
本文将细粒度命名实体的识别分为两个阶段。第一个阶段利用序列标注算法确定某个词条是否为命名实体(利用12个领域下的命名实体识别器判断某一词条是否为该领域下的命名实体),第二个阶段根据第一阶段识别出的命名实体进行细粒度类别划分。因此实验部分分别对这两个阶段的效果进行检测。最后,检测两个阶段合二为一后的效果,即给定一个句子,模型识别出其命名实体以及命名实体的领域和细粒度标签信息的效果。
2.1 标签体系
本文从领域角度出发,定义一套命名实体(NE,named entity)标签体系,研发面向互联网多场景文本数据的命名实体识别通用解决方案,提升文本词法分析质量。表2中展示了我们所定义的12个领域以及这12个领域下的总计46个细粒度标签。
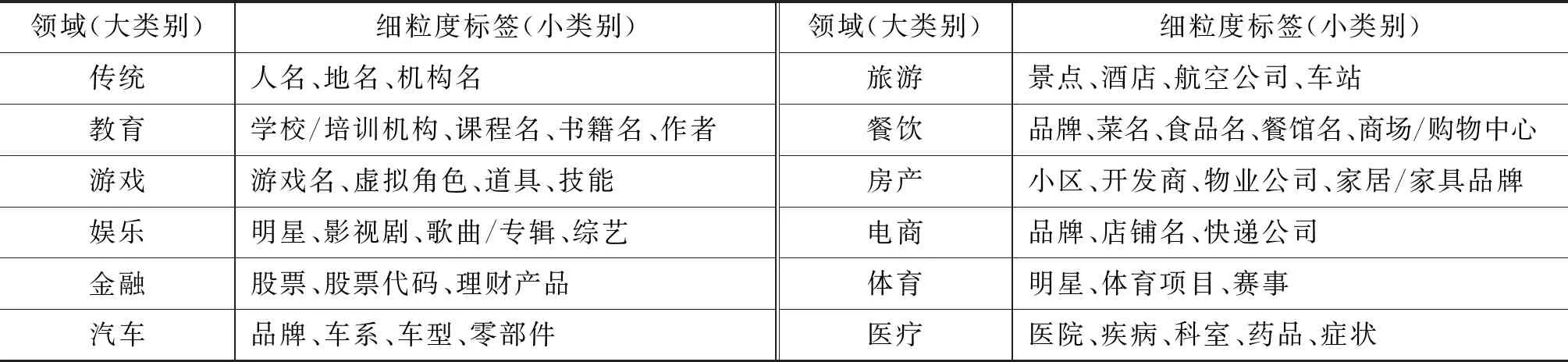
表2 标签体系
2.2 数据集
本实验采集了与需求对应的12个类别下的命名实体构建词典。
在获取词典后,利用从网络爬取和腾讯方面给出的文本数据进行回标,获取每个类别下的数据集,句子级数据集规模(单位:条)如表3所示。
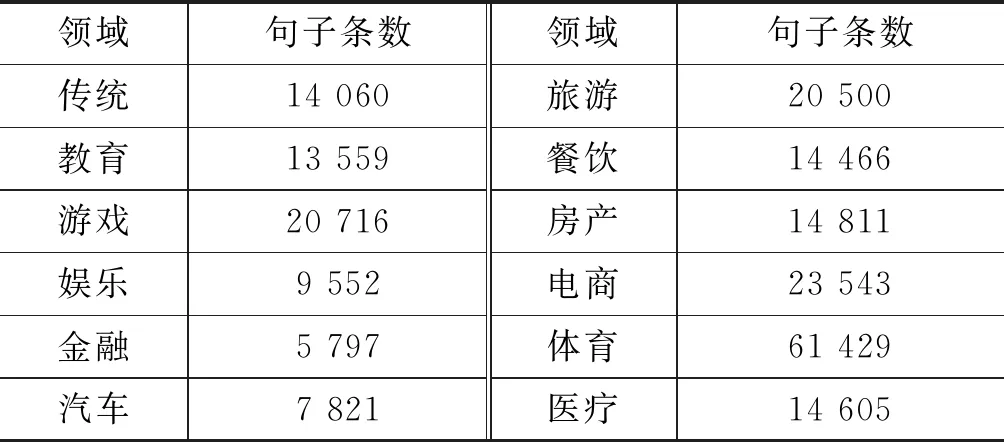
表3 回标数据集统计
在语料中,每个领域分别随机抽样100条语料,并计算出准确率(标注正确实体/所有实体)。抽样的结果如表4所示。
表4 回标准确率抽样(%)
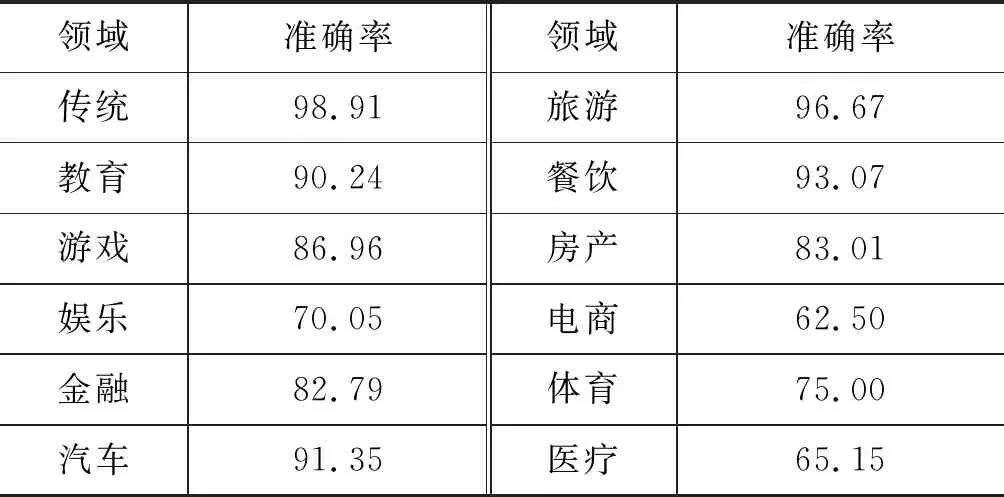
领域准确率领域准确率传统98.91旅游96.67教育90.24餐饮93.07游戏86.96房产83.01娱乐70.05电商62.50金融82.79体育75.00汽车91.35医疗65.15
2.3 词向量
在模型的训练过程中,使用了预训练的中文词向量,使用Python库gensim中的Word2Vec的接口训练中文维基百科的语料得到。
通过对训练集中的问进行统计。对于词表中的词w,如果有对应的预训练词向量,则使用对应的预训练的词向量作为词w的词向量的初始值;如果没有对应的预训练的词向量,则词w的词向量将随机产生。在模型的训练过程中,词向量会随着训练时得到的梯度进行微调。
2.4 实验结果
2.4.1 实体识别模块实验结果
此模块利用12个领域下的语料分别训练12个命名实体识别器,这些命名实体识别器仅进行0-1识别,即确定某词条是否为某领域下的命名实体。因此,本节给出了在各个领域下命名实体的0-1识别结果,并对比了与LSTM+CRF模型的结果,效果有所提高。
实验结果如表5所示。由表5可见,加入CNN后,在大部分领域的命名实体识别效果均有所提高,说明CNN能够从文本中获得对命名实体识别有益的特征。
2.4.2 命名实体的细粒度类别划分模块实验结果
命名实体的细粒度类别划分模块分为两个阶段,因此实验部分也给出了两个阶段的划分结果。第一个阶段的输入为由命名实体识别模块识别出的命名实体及其上下文,输出为该命名实体的大类别标签,这个阶段记为领域划分阶段。在进行此部分实验时,假设输入的命名实体为正确的命名实体。此部分实验能够检测命名实体被划分到了正确的大类别下的准确程度。本部分的实验数据均为词典回标得到的数据,按照7∶1∶1的比例随机划分为训练集、开发集和测试集。
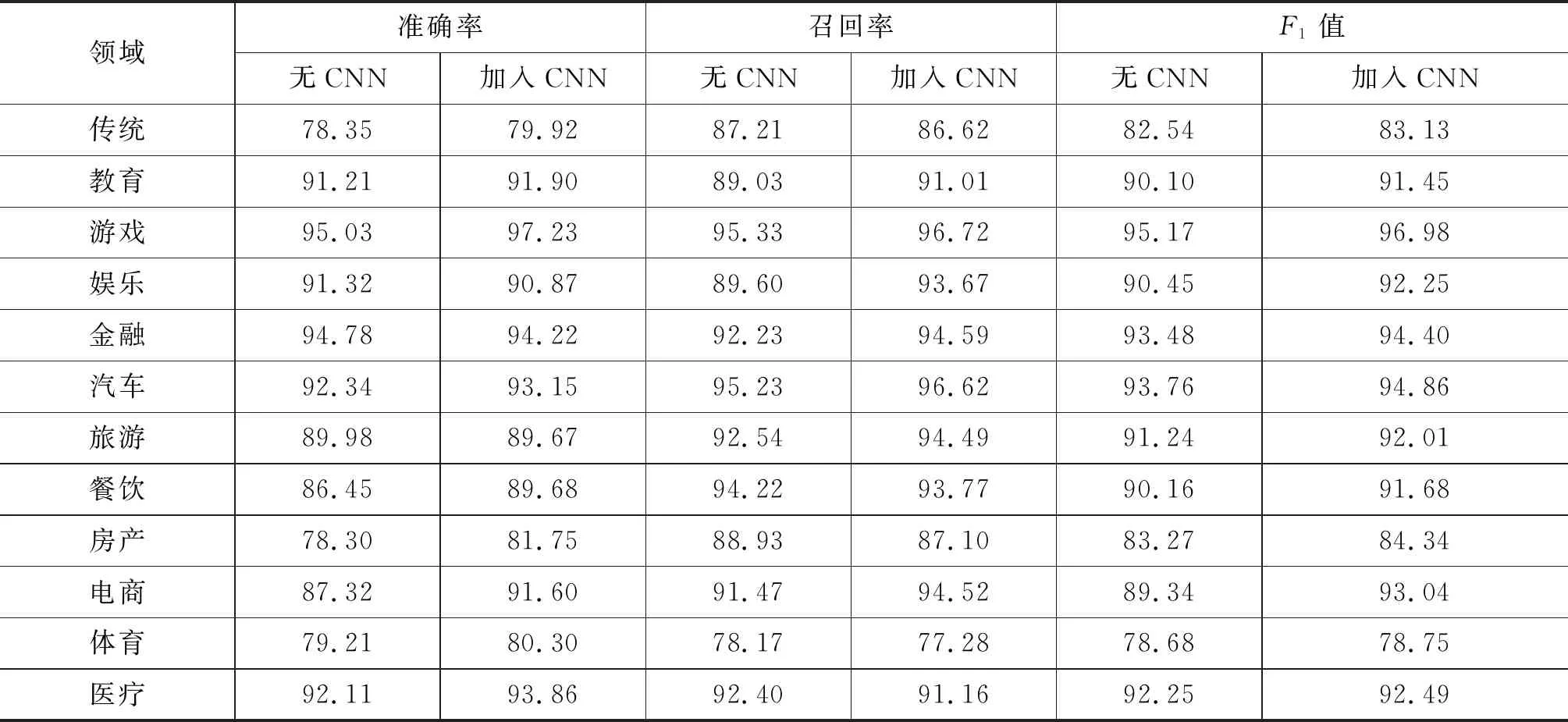
表5 命名实体识别模块实验结果(%)
本模块只对命名实体识别模块识别正确的实体进行细粒度类别划分,并不对实体的识别结果进行修改,因此本模块只对命名实体类别划分的准确率进行分析。领域划分阶段的实验结果,如表6所示。

表6 领域划分阶段的实验结果(%)
由表6可见,领域划分的准确率在95%以上,说明在命名实体识别准确的情况下,依据上下文可以获得较为准确的领域划分结果。因此我们首先对命名实体的领域进行确定,再对命名实体的细粒度标签进行划分。
细粒度类别划分模块的第二个阶段,对命名实体在第一个阶段识别出的领域下进行细粒度划分,记为类别划分阶段。本阶段同样假设输入为由命名实体识别模块识别出的命名实体及其上下文,输出则为该命名实体的细粒度类别标签。此部分实验能够检测命名实体被划分到细粒度的类别下的准确程度。表7给出了实验结果。
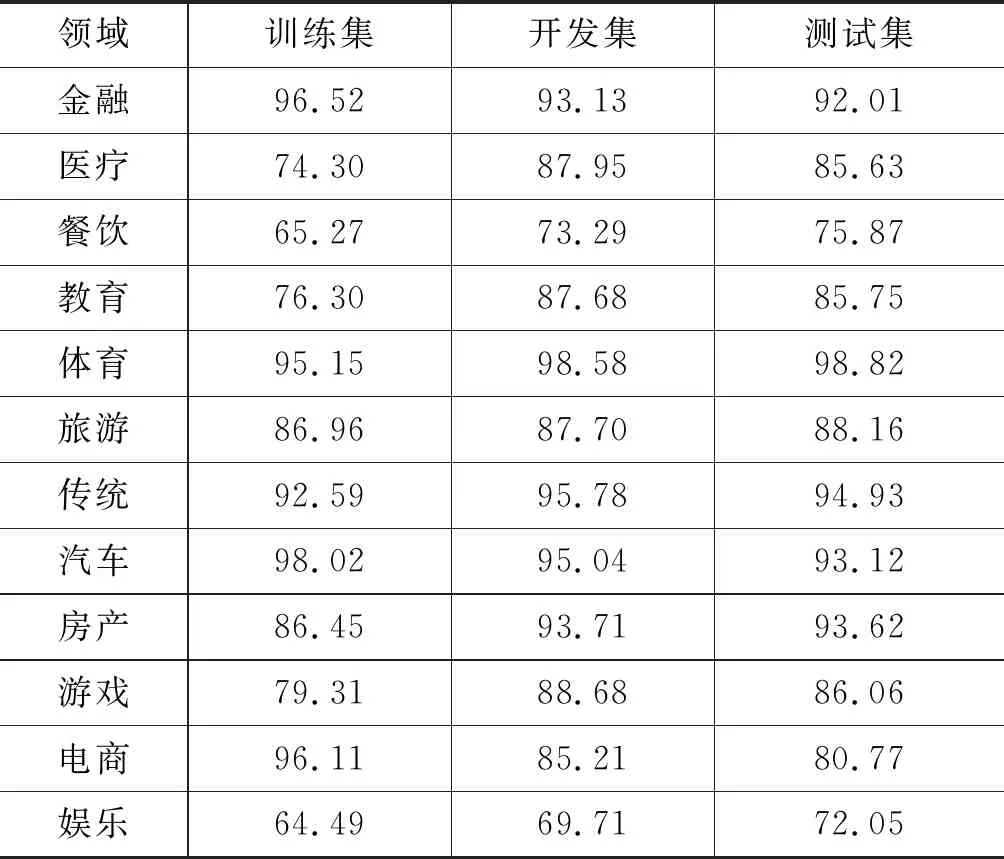
表7 类别划分阶段的实验结果(%)
表7中,医疗、娱乐、游戏等领域实验中训练集的效果不如开发集和测试集的原因是我们的训练数据中有回标误差。
2.4.3 命名实体识别整体实验结果
将命名实体识别和命名实体的细粒度类别划分两个步骤合二为一,测试了本文实现的命名实体细粒度划分的整体准确率,使用的语料是人工标注的语料,结果如表8所示。由于在细粒度类别划分模块中只对命名实体识别模型识别正确的实体进行细粒度类别划分,因此最后结果的准确率等于两个模块准确率的乘积,召回率等于命名实体识别模块的召回率。在此实验中,输入为未经处理的原始文本,而输出为带有细粒度标签的命名实体。

表8 细粒度类别划分模块的实验结果(%)
从表8的实验结果可见,大部分领域的效果都在80%左右,小部分领域效果较差,这些领域效果较差的主要原因是数据在标注的过程中出现了错误,而在人工标注的语料中则不包含这些错误的信息,因而模型学到的更多的是错误的信息。
另外,由于训练语料是由词典回标产生的,所以模型往往可以正确识别常见的命名实体,而对于一些出现次数较少的命名实体就难以正确识别。部分实体的类别在自动标注的过程中被误标,原因是数据回标时将部分非命名实体标注为命名实体。例如,对于文本“losea磨砂拼接小方包2017新款斜挎包迷你锁扣包韩版复古单肩包小”中的“迷你”,在汽车领域的标签是“汽车—品牌”,但是在当前语境下就是错误的标签。在该领域下实验效果较差的原因就是在数据回标时,将大量的“迷你”标注为“汽车—品牌”,所以在训练的时候,模型学习到的信息是将“迷你”的类别识别为“汽车—品牌”。
2.5 实验结果分析
部分抽样的错误样例见表9。其中,由“【”和“】”括起来的为模型识别出的命名实体。
从表9中可以看出,错误样例中的错误是多样的,既有命名实体识别模块识别的错误,也有细粒度类别划分的错误。同时,来源于构建语料时词典回标造成的错误也是难以正确识别的。
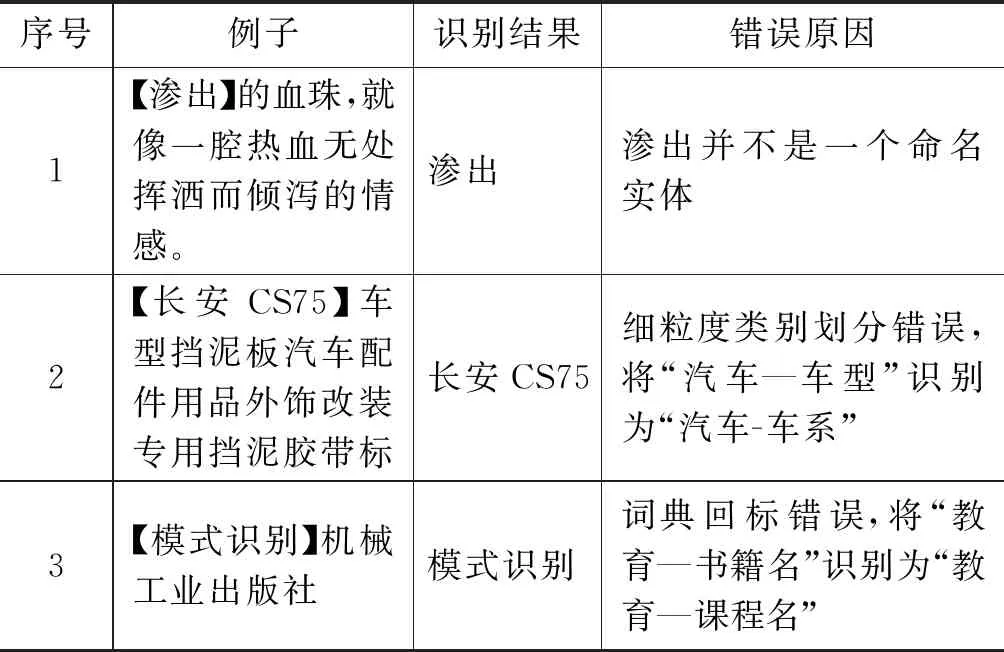
表9 错误样例示例
3 总结
本文设计并实现的分阶段细粒度命名实体识别方案能够将大部分命名实体识别出来,并确定该命名实体的细粒度标签。对于某些细粒度的命名实体,比如药品、影视名、汽车车系等,由于在训练语料中分布稀疏,其中一些类别的命名实体的命名非常随意,比如车系有“唐”“A7”等,使得针对这类的命名实体的细粒度划分变得不准确,但是如果不强调小类别,而是仅进行大类别的划分,本文实现的方法F1值在全领域上平均值达到了80%左右,在一定程度上说明本论文实现的分阶段方案是有效的。
猜你喜欢
红外技术(2022年11期)2022-11-25
通信技术(2021年12期)2022-01-25
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
安阳工学院学报(2020年2期)2020-06-05
计算机应用与软件(2018年9期)2018-09-26
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
外语教学理论与实践(2014年2期)2014-06-21
