
基于情感常识的情感分析
2019-08-05 01:42周逢清林鸿飞殷福亮张一鸣
中文信息学报 2019年6期
杨 亮, 周逢清, 林鸿飞, 殷福亮, 张一鸣
(1. 大连理工大学 计算机科学与技术学院,辽宁 大连 116024;2. 大连理工大学 信息与通信工程学院,辽宁 大连 116024)
0 引言
情感分析一直是自然语言处理领域中的研究热点之一。情感分析通过模型构建,分析文本中蕴含的情绪观点或是对情感施加的影响进行计算。具体表现为分析人们对文本、产品、服务等实体的看法和情感倾向,具有广泛的研究及应用价值[1-2]。
随着机器学习和深度学习方法的不断发展,显式情感分析领域的研究已接近饱和,研究精度的提升已经非常有限,然而隐式情感分析领域仍亟待探索。隐式情感表达中往往不含有情感词,而大多是通过一些常识隐晦地传达情感,需要读者具有一定知识背景,通过推理来理解其中蕴含的隐式情感。常识是人们通过日常生活中的实践而总结的一些面向于大众的具有一定思维逻辑的知识。例如,当人们在谈话中说起“太阳东升西落”,人们的脑海中会自然联想到一天的开始与结束等。在情感分析任务中运用常识知识,就有可能挖掘文本显式表达下的隐含的深层情感,从而提高情感分析的准确性。因此,如何获取并构造中文情感常识库并将其用于情感分析是本文的研究重点。
中文情感常识库的构建离不开语义资源的支撑。目前已有许多公开的语义资源,例如,WordNet词典[3]、HowNet知识库、ConceptNet语义网络[4]等。许多研究工作都在这些语义资源的基础上进行开展[5-7]。ConceptNet是由互联网上众多网民贡献的大量常识概念组成的一个大规模语义网络,涵盖约30万个概念节点以及超过160万条的关系,是构建中文情感常识库的一个优秀语义资源。
本文的贡献主要有:(1)设计了一种二元情感常识结构;(2)基于ConceptNet语义网络构建具有一定规模的中文情感常识库;(3)将构建的情感常识库应用于情感分析任务中,实验结果得到了一定提升。
本文的组织结构如下:第1节介绍与情感词典及情感分析相关的基础工作;第2节阐述中文情感常识库的构建过程;第3节给出基于情感常识库的情感分析实验及结果分析;第4节总结全文并展望未来工作。
1 相关工作
情感分析是自然语言处理领域中的一个传统任务。赵妍妍等[8]指出,按照不同的文本的粒度,情感分析可以分为词语级、方面级、句子级、篇章级等多个研究层次。传统的情感分析的方法大多使用情感词典,其中比较著名的情感词典有SentiWordNet[9]、NTU评价词词典[10]、情感词汇本体[11]等。这类方法主要依据文本中的情感词对文本的情感极性进行判别,进而将文本分成不同的情感类别。情感词典具有结构简单,便于应用等多个优点,但存在模糊性、时变性、缺乏规律性等不足。同时,单独一个词语能表达的内容和情感十分有限。基于词典的方法也不能识别出一些不含有情感词但隐含在常识知识中的情感。
除了基于词典的情感分类方法之外,机器学习与深度学习方法也被广泛应用于情感分析任务,这类方法常与词语的分布式表示相结合。分布式表示是将词语映射为低维空间中的一个连续、实值向量,在一定程度上编码词义信息,使用较广泛的词向量如Word2Vec[12]、GloVe[13]等。以此为基础,结合机器学习模型如SVM[14]或者深度学习模型LSTM[15]、CNN[16]、Attention[17]等,就可以将文本的词向量序列编码成具有深层次的语义的句子级表示,进而完成情感分析的任务。Giatsoglou M等[18]结合词典的特征以及词嵌入特征,通过SVM模型在多个公开数据集上提升了情感分析的效果。冯兴杰等[19]提出一种基于CNN和Attention模型,一定程度上提升了情感分析任务的性能。
上述工作大多局限于显式情感分析层面,对于不含有情感词的文本表达就难以判定其情感极性。因此,本文基于ConceptNet构建了一定规模的中文情感常识库,并以此为基础进行隐式情感分析实验。
2 中文情感常识库的构建
ConceptNet语义网络中众多的概念节点和联系为本文的研究工作提供了重要的参考依据。因此,本文基于ConceptNet构建中文情感常识库,具体构建过程如图1所示。
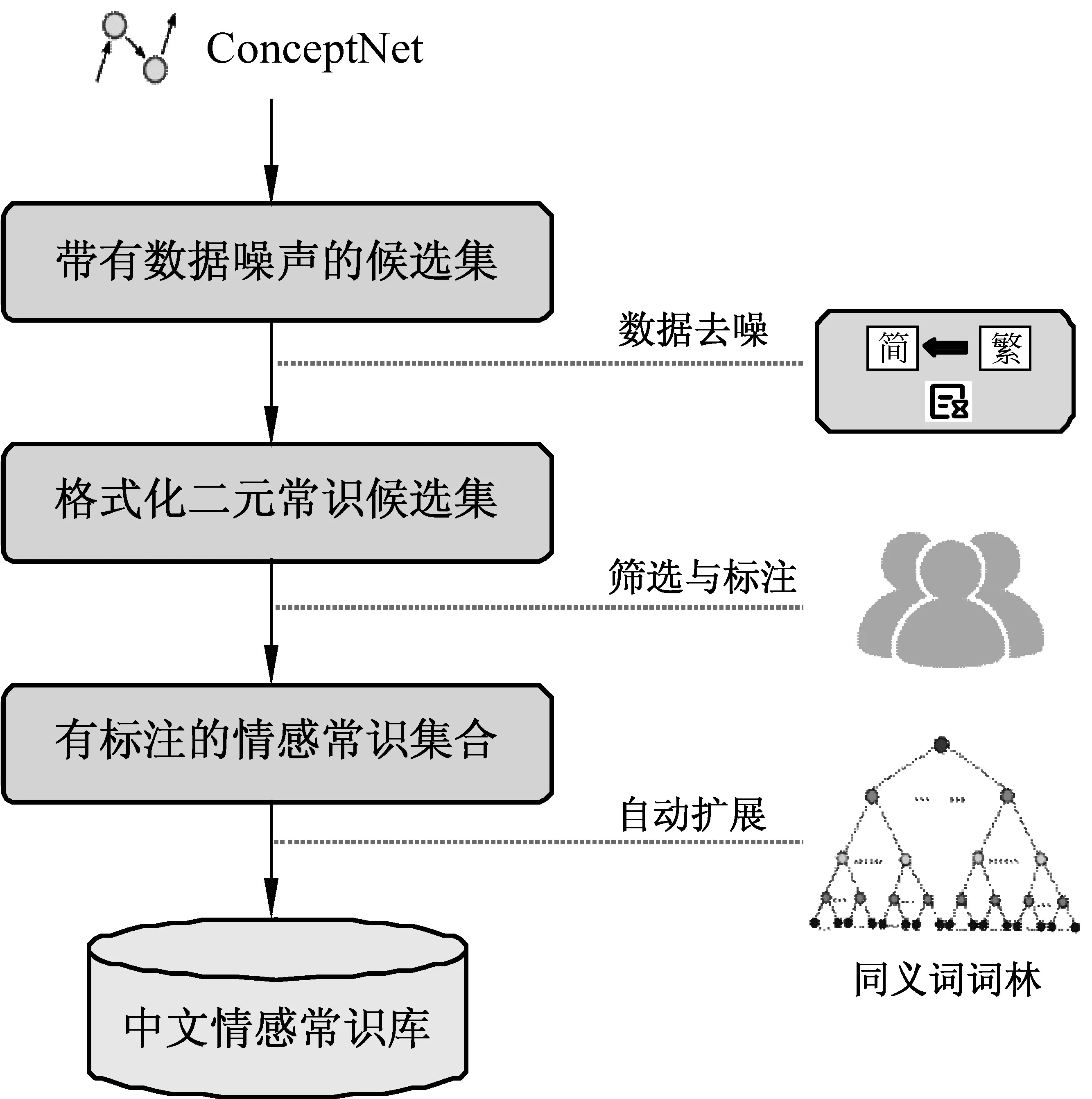
图1 中文情感常识库构建流程
参照ConceptNet中的实体联系结构,本文设计了一种二元情感常识结构,因为两个词语已经可以很大程度上反映出一个常识所要表达的情感。如动宾结构短语:(“收到”,“礼物”),收到礼物一般会表达一种喜悦的心情;或者主谓结构的短语:(“商店”,“倒闭”),商店倒闭关门往往带有一种负向的情感。
由于ConceptNet规模较大,且大量常识知识并不含有情感信息。因此,需对抽取内容的范围进行界定,从而获得一个二元情感常识候选集。本文主要选择ConceptNet中具有“Desires”类型关系的二元实体作为候选集合。因为,这部分的常识组合具有较为明显的情感倾向,最终抽取约160 000条二元词语组合。
ConceptNet中的中文常识知识主要以中国台湾的文化背景及语言习惯生成。所以,在完成候选目标的内容提取后需要进行语言格式转换,即繁转简的过程。对于繁转简后产生的错误项,如缺字,多字等主要依赖规则过滤及人工排错等数据去噪手段。
经过数据去噪的常识候选集合绝大多数含有情感词语,但我们更需要不含显式情感词的二元隐式情感常识。因此,需在候选集中进行筛选和标注。含有显式情感词的可以与情感词汇本体[11]进行匹配并过滤,其他不含有情感词也不构成情感常识的则需要人工筛选过滤。构成情感常识的二元组通过人工标注后可以由一个三元组进行表示。其中,元组的前两个元素为二元情感常识,而最后一个元素为该常识的情感极值(正向为1,负向为-1)。例如,(“收到”,“礼物”,“1”)表示的就是“收到礼物”这个二元情感常识搭配带有正向的情感倾向。经过多轮人工筛选与标注之后,共获得约6 200条的情感常识。
为了进一步扩展上述情感常识的覆盖范围,本文使用哈尔滨工业大学的同义词词林扩展版对获得的情感常识进行扩展。为了避免引入过大的噪声,本文主要进行了行级的扩展。在已标注的情感常识中,先分别对二元组左侧实体和右侧实体进行同义词替换,然后再将其扩展到情感常识库中。如图2所示,(“商店”,“倒闭”,“-1”)表示的就是“商店倒闭”这个二元情感常识带有负向的情感。根据“商店”的同义词“店铺”可以进行左侧拓展形成新的情感常识(“店铺”,“倒闭”,-1)”;根据“倒闭”的同义词“停业”可以进行右侧拓展,形成(“商店”,“停业”,-1)。最终,经过扩展后的中文情感常识库中共有近170 000条的情感常识。
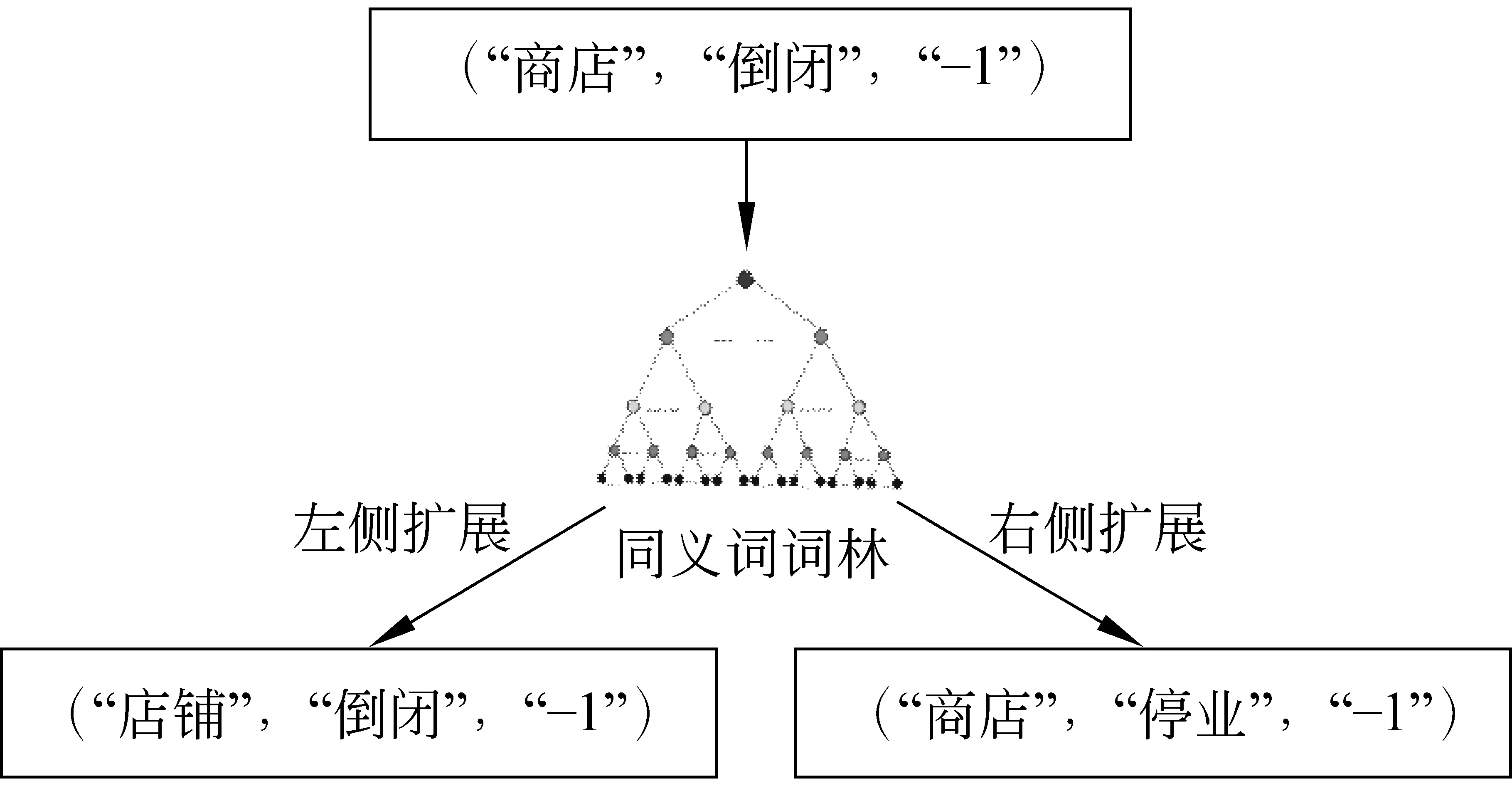
图2 情感常识扩展示例
3 实验与分析
3.1 实验语料与对比实验
本文的实验数据为谭松波等的中文酒店评论语料[20]。该语料是谭松波教授多年实践工作中收集整理而成,在酒店领域评论语料中比较具有代表性。该酒店评论语料规模较大,包含10 000条酒店评论,正向评论7 000条,负向评论3 000条。
为了更好地进行实验与分析,我们需要对数据进行预处理。首先去除重复数据后语料中包含5 322 条正向评论和2 444条负向评论;然后对评论中的非中文部分、酒店对住户评论的回复等无关噪声内容进行剔除;最后使用jieba分词工具得到评论对应的词语序列。情感分析实验设计方面,主要对比下述的三种方法。
3.1.1 基于词典的情感分析方法
基于情感词典是一种传统的情感分析方法,通过评论中的词语与情感词典本体进行匹配,进而累计正向情感词与负向情感词的数目,最后通过比较来判断评论的情感极性。本方法中使用的情感词典是大连理工大学信息检索研究室提出的情感词汇本体[11]。
3.1.2 基于机器学习的情感分析方法
机器学习方法采用SVM模型,结合Li S等[21]在百度百科语料上基于Word2Vec模型训练得到的词向量,词向量维度为300。未登录词则通过均匀分布U[-0.1,0.1]进行随机初始化。模型的输入首先将评论对应的词语序列映射为词向量序列,再将每一条评论对应的词向量序列的平均值作为这条评论的向量表示。实验中训练集与测试集的划分比例为8∶2。
3.1.3 基于深度学习的情感分析方法
在深度学习方面,本文使用LSTM模型进行情感分析实验。因为LSTM模型擅长对序列进行建模,在许多文本分类任务上都取得了较好的结果。因此,本文选用LSTM模型。词向量以及训练集测试集划分与基于机器学习的情感分析方法一致,其他参数设置包括LSTM隐层节点数为300,batch-size为32,损失函数为交叉熵,优化算法为Adam。
3.2 基于情感常识的情感分析
为了检验本文构建的中文情感常识库在情感分析任务中的效果,本文在3.1中设计的基本实验中,引入中文情感常识库对实验结果进行修正。
3.2.1 修正基于情感词典的情感分析
本文在基于词典的情感分析实验的基础上,结合中文情感常识库对该部分进行结果修正。具体步骤如下:对情感词汇的情感极值进行聚合,增加情感常识库的查找匹配操作,即查找评论中是否存在二元情感常识搭配。若存在,则采用该二元情感常识组合的情感标记值替换原来用情感词典分析所得到的情感类别,采用直接覆盖的方式。若不存在,则保持原有结果不变化,按照原情感极值聚合值判断该评论的情感极性。
3.2.2 修正基于SVM的情感分析实验
该部分修正实验主要利用已有的情感常识库对语料的训练集进行扩充,并以此为基础修正基于SVM的情感分析方法。由于外部情感常识资源中共含有170 000条左右的情感常识项,为了避免引入过多的噪音,本文通过对语料中的词语进行词频统计,过滤一些低频词项。
语料通过过滤和去重后共得到28 305个词语,并统计词语对应的词频信息,如表1所示。表1中词频数小于10的词语多达24 382,占所有词语总数量的86%左右;为满足实验需要并减少数据量过大而带来的噪声,本文只利用词频大于200的高频词来结合情感常识库对实验训练集进行扩展。

表1 中文语料的词频统计
基于提取出的高频词汇集,在构建的中文情感常识库中进行检索,若二元情感常识结构中含有高频词汇集中的一项或两项,则将这条情感常识提取作为对训练集的扩展。扩展情况的统计信息如表2所示。

表2 不同匹配方式下的训练集扩展数量统计
匹配样例如下:“服务员”为语料中的高频词汇,且情感常识库含有这样的三元组(“服务员”,“恶劣”,“-1”)、(“服务员”,“热情”,“1”)。则通过高频词“服务员”可以与上述两条情感常识进行左侧匹配(词语“服务员”在二元情感常识结构的左侧)。进而在训练集中拓展出对应的两个新数据样本。同时情感常识的情感倾向作为对应拓展样本的标注。
3.3 实验结果分析
本文共采用了三种类型的方法在语料上进行了情感分析实验。含基于情感词典的情感分析方法(Lexicon),基于机器学习(SVM)的情感分析方法和基于深度学习(LSTM)的情感分析方法。进一步结合构建的中文情感常识库对基于词典和基于机器学习的方法进行修正(Lexcion-R, SVM-R),实验结果如图3所示。
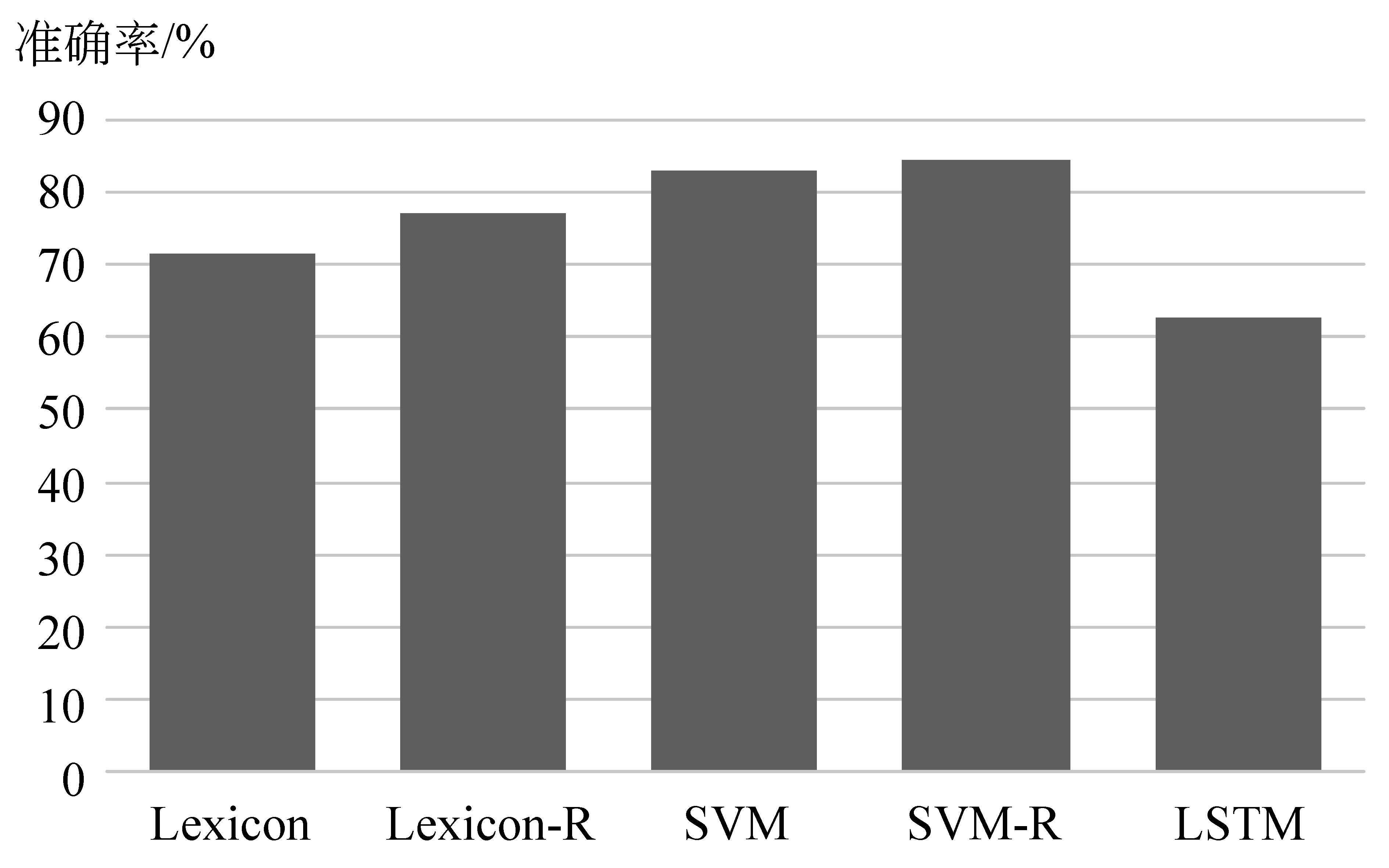
图3 5种方法的准确率对比分析
当引入构建的外部情感常识资源后,基于情感词典的情感分析方法和基于SVM的情感分析方法的实验结果均得到了提升。基于情感词典的方法只由显式出现的情感词判断评论的情感极性,而引入情感常识对其进行修正,弥补了这种方法局限,可以有效地挖掘评论中的隐式情感。
例如,语料库中存在这样一段评论:“房间的设施极其陈旧”。这段评论中并没有显式的情感词语,但(“设施”,“陈旧”)构成了二元情感常识,且在情感常识库中的标注为“-1”。因此,根据基于词典的修正方法中的规则,这个评论被判定为是一种负向的隐式情感表达,与评论者真正想要表达的情感一致。
对于修正的基于机器学习的方法,构建的中文情感常识库具有知识涵盖范围广的优势。结合情感常识库使得模型从扩展的训练集合中学习到更多的“知识”,故实验效果得到提升。
通过图3中的数据结果对比可知,基于机器学习(SVM)的情感分析方法在情感倾向性分析实验上的效果要优于基于深度学习(LSTM)的情感分析方法。基于深度学习(LSTM)的情感分析方法表现结果较差,主要原因可能在于本次实验中的数据集规模较小,LSTM网络未能充分挖掘深层次的语义信息,故未能获得预期的实验结果。
本文进一步对情感常识匹配方式的不同进行分析,分别是单项匹配的数据集(左或右)、左侧项匹配的数据集和右侧项匹配的数据集。通过不同的匹配方式,将基于语料高频词语以及情感常识库扩展而得到的数据集结合原有训练集形成最终用于模型训练的数据集,在修正基于SVM的情感分析方法上进行实验。实验结果如表3所示。

表3 扩充后不同训练集的准确率情况
从表3可看出,加入左侧项匹配的实验准确率优于右侧项匹配的结果。这说明,二元情感常识结构中左侧项对情感分析实验的影响要更大。通过分析情感常识库发现,二元情感常识结构中左侧的实体词性多为名词,往往蕴含更具体的信息。此外,由单侧匹配的实验结果可知,更全面的情感常识信息在情感分类中能发挥更好的作用,使准确率得到进一步提升。
4 结论
本文利用ConceptNet以及同义词词林等语义资源,结合人工筛选以及标注等步骤构建了一个具有一定规模的中文情感常识库。为了验证所构建的情感常识库对文本情感分析的作用,本文设计了3组基本实验并结合情感常识库进行方法修正。实验结果表明,情感常识知识的引入有助于文本的情感分析任务。在未来工作中,如何对情感常识库进行深入扩展,如何设计更合理的多元情感常识结构、构建更加细粒度或者融合领域知识的情感常识库等都需要进一步的探索与研究。
猜你喜欢
通信技术(2021年12期)2022-01-25
北京航空航天大学学报(2021年9期)2021-11-02
文苑(2020年11期)2020-11-19
重型机械(2020年2期)2020-07-24
孩子(2019年9期)2019-11-07
中国航海(2019年2期)2019-07-24
计算机应用与软件(2018年9期)2018-09-26
中国眼镜科技杂志(2017年10期)2017-07-10
互联网天地(2016年2期)2016-05-04
外语教学理论与实践(2014年2期)2014-06-21
