
XML文档加权层次子树模型的建立
2019-08-01 01:52王寅
数字技术与应用 2019年4期
关键词:建立
王寅

摘要:随着互联网的快速发展,具有自描述、半结构化和可扩展特点的XML成为互联网上数据存储和数据交换的标准。本文在树型结构模型和频繁路径模型的基础上,提出针对XML文档结构聚类的模型——加权层次子树模型,能够表示出XML文档的层次关系和层次信息。通过消除重复元素和重复表达式,用更加简洁的表达式表示出XML文档的层次和元素信息,能够快速、准确分辨出具有相同结构的XML文档。
关键词:XML文档;加权层次子树模型;建立
中图分类号:TP311 文献标识码:A 文章编号:1007-9416(2019)04-0208-02
1 绪论
近年来,随着互联网的快速发展,网络信息量呈几何级数增长,从海量数据中快速、准确地检索出用户所需信息成为研究热点。具有自描述、半结构化和可扩展特点的XML(eXtensible Markup Language,可扩展标记语言)成为数据表示和数据交换的标准。
在各种XML文档结构的表示方法中,树型结构模型和频繁路径模型是两种常用表示模型。其中,树型结构模型具有直观、易于理解等特点,但它会随着文档规模的增大而变得复杂,处理时间也随之增加,不能对文檔中的重复元素作出很好的响应。频繁路径模型具有表示形式简单的特点,但它不能完整的描述文档结构,聚类准确类不高。本文综合树型结构模型和频繁路径模型的优缺点,提出针对XML文档结构聚类模型——加权层次子树模型。
2 加权层次子树模型的定义
2.1 模型说明
对XML文档结构进行研究,需要首先建立XML文档的结构表示模型,并考虑表示信息完整、结构简洁、易于理解和操作等要求。加权层次子树模型描述的是元素与元素之间的层次关系,以每一个具体元素为中心,凡具有孩子节点的元素都可以形成一个二层子树,在XML文档树中,每个二层子树都可以描述其父子关系。这样表述出来的模型就很清楚、很简洁的描述了父子关系及兄弟关系。
每一个含有非空子节点的每一个元素节点都对应加权层次子树模型中的一条加权层次子树表达式关系。表达模式即模型中元素之间的父子关系,这一系列父子关系的集合构成加权层次子树模型的主体。
与元素层次模型和元素内容模型不同,加权层次子树模型是一种元素内容模型。元素内容模型由元素及其子元素构成,元素之间的父子关系是其主要描述内容,其子元素是该父元素的全部子元素。由于元素内容模型在表示XML文档模式方面具有优势,它经常被用来进行XML模式的抽取研究。与元素内容模型相似,元素层次模型描述的也是元素之间的父子关系,但其中某个父元素所在的二层子树中包含的子元素集合可能只是这个父元素的所有子元素的一部分,父元素要求有很多元素层次表达式才能全部描述其子元素的集合。
2.2 模型定义
(1)加权层次子树表达式的定义。加权层次子树表达式的定义为:r=(ef,ec,l,w)。其中,1)ef是元素与其子元素形成的二层子树中的父元素,且ef∈E,E表示元素的集合。2)ec是二层子树中的子元素集合,即二层子树的叶节点集合,且ec∈E。3)层次l∈N,N表示自然数,是二层子树中的父元素在整个XML树型结构文档中的层次,其中根节点的层次“l”为1,每向下一层“l”加1。4)w∈N是二层子树中的父元素在整个XML树型结构文档中的权重,其中根节点的权重最大
(2)加权层次子树模型的定义。加权层次子树模型的定义为:M=(E,R)。其中,1)E表示XML文档元素的集合,由元素e组成。2)R是加权层次子树表达式的集合,r∈R。
(3)加权层次子树表达式举例说明。以XML文档BookInfo.xml为例,介绍加权层次子树表达式。部分文档内容如下:
可以看到,加权层次子树模型由加权层次子树表达式集合组成,简洁明了、表达完整,充分体现了元素之间的父子关系。在加权层次子树表达式中体现了元素父节点所在的层次及该层的权重,这样构成的模型可以很好提高XML文档的相似度计算的精确度,从而可以更好的进行XML文档聚类。
3 加权层次子树模型的简化
构造完加权层次子树的表达式后,父元素构成的二层子树的子元素集合中可能有重复出现的子元素。加权层次子树模型考虑的是父元素与子元素的关系,相同的子元素对父元素的影响看作是相同的,所以要去除父元素里包含的相同子元素。XML文档中会包含着很多这样重复的节点,随着XML文档规模的增大,重复节点也会相应增多,会使表达式显得冗余,也增加了表达式的数量,导致执行效率降低。所以,为构造一个良好的结构模型需要对模型进行简化。
3.1 去除重复的元素
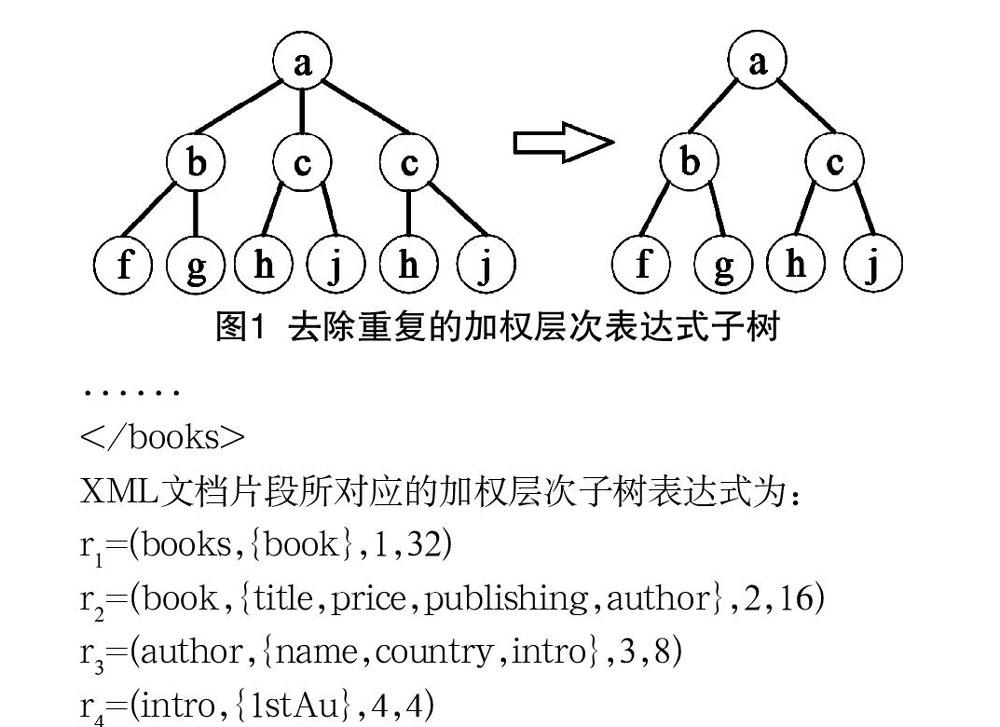
去除重复元素即去除由父元素构成的二层子树的子元素集合中相同子元素,最终只保留一个这样的子元素。例如,以a为父节点的二层子树,子树中子元素集合为{b,c,c,c},存在重复子元素c,需要进行模型简化。只保留一个元素c,其余的元素c都删除,去重后的子元素集合为{b,c},加权层次子树表达式为:r=(a,{b,c},l,w)。
3.2 去除重复的加权层次表达式
重复的加权层次表达式即具有相同的父元素,且在相同父元素下的子元素集也相同,父元素所在的层次和权重也完全相同。多个相同的加权层次表达式会给模型带来很大的冗余。当XML文档规模很大时,重复的加权层次表达式会严重影响执行效率。
如图1所示的以a为根节点的加权层次子树,先去除重复元素。第一层父节点中有重复的子元素c,只保留1个即可。第二层父节点中以c为相同父节点、且具有相同的加权层次表达式的子元素h、j,只保留一个即可。
4 加权层次子树模型的建立
构造加权层次子树模型的步骤分2步,首先将XML文档解析成DOM树,提取加权层次子树表达式;随后精简提取的表达式,删除重复的元素和加权层次表达式,得到精简的加权层次子树模型。
将XML解析为DOM树后,从根节点开始遍历。进行到一个节点,判断其是否有子节点,若没有子节点则放弃,若有子节点则将其作为父节点生成相应的加权层次子树表达式。在子节点集中,判断每一个子元素是否与现有子元素相同,若相同则不将其添加到子节点集合中;若不同则可添加,并将父节点所在的层次和权重加入表达式。通过对DOM树递归调用就可得到全部的加权层次子树表达式,并删除重复元素。删除重复元素后,进一步去除重复的加权层次表达式。加权层次子树模型解决了树型结构模型不易处理、执行效率低的问题,更好的表示了XML文档中的层次关系,弥补了频繁路径模型层次关系表达的欠缺。
5 结语
本文在现有XML文档模型的基础上,提出了加权层次子树模型。模型考虑了层次信息,以元素之间的关系为主体,将元素所在的层次以及层次的权重纳入加权层次表达式中,精确表达了XML文档的结构。
参考文献
[1] 王大伟,崔婉秋,覃飙.基于XML搜索的相关技术及发展[J].小型微型计算机系统,2018,39(07):1390-1397.
[2] 吴海涛,郭丽红,杨洁.基于矩阵存储的XML相似度检测算法[J].计算机应用研究,2018,35(07):2025-2029.
[3] 赵震,马宗民.模糊XML文档与模糊DTD相似性研究[J].东北大学学报(自然科学版),2017,38(02):200-204.
[4] 张沛朋,李杰.基于多层次技术的XML数据挖掘研究[J].兰州文理学院学报(自然科学版),2016,30(03):60-63.
[5] 陈飞飞.基于DOM4J的XML文档解析技术研究与应用[J].软件导刊,2016,15(03):36-37.
猜你喜欢
办公室业务(2016年9期)2016-11-23
科教导刊(2016年26期)2016-11-15
财会学习(2016年19期)2016-11-10
知音励志·社科版(2016年8期)2016-11-05
科学与财富(2016年28期)2016-10-14
科学与财富(2016年28期)2016-10-14
