
基于相似连接的多源数据并行预处理方法
2019-08-01 01:35郭方方潮洛蒙朱建文
计算机应用 2019年1期
关键词:网络安全
郭方方 潮洛蒙 朱建文


摘 要:大规模网络环境和大数据相关技术的发展对传统数据融合分析技术提出了新的挑战。针对目前多源数据融合分析过程灵活性差、处理效率低的问题,提出了一种基于相似连接的多源数据并行预处理方法,该方法采用了分治和并行的思想。首先,通过对多源数据中的相似语义进行统一、对个性语义进行保留的预处理方法提高了灵活性;其次,提出了一种改进的并行MapReduce框架,提高了相似连接的效率。实验结果表明,所提方法在保证数据完整性的基础上,使总的数据量减小了32%。与传统的MapReduce框架相比,改进后的框架在耗费时间方面减小了43.91%,因此该方法可以有效提高多源数据融合分析的效率。
关键词:网络安全;多源数據;数据预处理;相似连接;MapReduce
中图分类号: TP274
文献标志码:A
Abstract: With the development of large-scale network environments and big data-related technologies, traditional data fusion analysis technology faces new challenges. Focusing on poor flexibility and low processing efficiency in current multi-source data fusion analysis process, a multi-source data parallel preprocessing method based on similar connection was proposed, in which the idea of dividing and conquering and paralleling was adopted. Firstly, the preprocessing method was improved to increase the flexibility by unifying similar semantics in multi-source data and retaining personality semantics. Secondly, an improved parallel MapReduce framework was proposed to improve the efficiency of similar connections. The experimental results show that the proposed method reduces total data volume by 32% while ensuring data integrity. Compared with traditional MapReduce framework, the improved framework decreases 43.91% of time consumed; therefore, the proposed method can effectively improve the efficiency of multi-source data fusion analysis.
Key words: network security; multi-source data; data preprocessing; similar connection; MapReduce
0 引言
多源数据的预处理过程是网络环境进行安全分析的重要环节,根据实际的应用采取相应的具体措施[1]。一般性地,包括数据清理、数据格式转换、数据简约等过程。其中数据清洗作为一个重要的环节,通过按照一定规则筛选数据,去除数据中的冗余部分。好的数据清洗方法不仅能够降低系统处理数据所需的时间,并且能够提高数据分析结果的准确度。
为了对数据源进行灵活的数据清洗,尽量保留数据源的个性属性,本文采用基于相似连接的数据清洗方法。相似连接在相似对象匹配问题中得到广泛应用,如互联网、数据分析、数据库等,匹配对象也日益多样,如串、图、字符串和集合等。为了适应各种各样的场景和对象,相似连接相关算法也得到了优化和改进。无论是基于单行串行数据还是集合数据,或是基于树结构还是图结构,优化和改进的方案主要以提高效率和灵活性或伸缩性为主。为了解决单行串行的相似连接候选集过多的问题,Li等[2]提出了一种基于划分的传递性的相似连接,该相似连接的过程进行的划分,该方法在此句不通顺,请修改相似匹配过程中利用传递性没有使用全部子串,从而减少了匹配的候选集数目,提升了匹配的效率。为了提升算法的灵活性与伸缩性,Wang等[3]提出了一种快速相似连接算法,该算法既考虑到了相似的准确度,又考虑到了相似连接属性的模糊度,可以进行灵活的筛选;然而随着大数据与云计算等的出现,由于数据量的庞大导致算法效率低,这也是相似连接算法面临的难题之一。
MapReduce作为一种并行框架,由于其扩展性好、易实现等特点,被广泛使用在数据并行处理中。陈一帆等[4]提出一种基于MapReduce的图相似连接的处理方法,使用“过滤验证”框架下的MGSJion与Bloom Filter相结合,并使用MapReduce框架提升了算法整体的效率。陈子军等[5]提出基于MapReduce框架的相似连接算法,该算法应用对象是空间文本,在MapReduce框架实现了相应的划分和裁剪工作,提升了算法效率;然而MapReduce框架在被普遍应用的同时,MapReduce框架本身的缺点也显现出来,如:迭代计算比较乏力,计算中产生的Mapper数量过多,装载和卸载较频繁等问题。据此,Bu等[6]提出一种HaLoop可扩展框架,通过添加循环控制模块来解决迭代乏力的问题。为了进一步提升效率,Zhang等[7]提出一种基于内存的iMapReduce框架,通过Map和Reduce阶段长期驻留内存和适时的中断迭代次数来提升框架的计算效率;然而现有的基于内存的框架处理方式比较粗糙,浪费内存空间比较严重。
据此,为了提高数据清洗的效率,本文提出了一种基于相似连接的数据预处理方法,并且采用改进的MapReduce框架实现该算法。该框架基于内存的思想来提升框架的并行效率,能够高效地完成相似连接操作。
1 基于相似连接的数据预处理模型
为保障分析的全面性,传统的安全分析方法尽可能多地获取数据特征,构建分析模型;然而大数据环境中数据源的特点致使数据量太大,并且会包含大量无用的、冗余的数据。若将这些多源数据直接导入作为源数据进行分析,则会出现数据不完整、数据冗余等问题,从而影响系统效率和准确率,因此,在进行数据分析前,需要增设一个数据预处理过程,从中提取有用的数据,进而提高数据挖掘结果的準确性。数据预处理是很有必要的环节。
多源数据的清洗工作需要充分利用数据源之间的互补性,融合多方面的数据源信息。为了保留数据源的个性信息,并且最大化压缩数据量,本文提出了多源数据预处理模型。主要环节包括以下几个方面:首先,通过选取各自属性特征模式对数据源进行独立筛选;其次,对于不同数据源的属性中的相似语义进行统一,对个性语义予以保留;最后将各个数据源的处理结果进行连接合并。如图1所示,本文提出的方法可以对不同的数据源进行个性、灵活的处理,最后形成一个多维度的数据源。其中在连接合并环节本文采用了基于相似连接的数据预处理方法[8],本文采用Jaccard系数来度量数据之间的相似性,Jaccard系数定义如(1)所示:
其中X和Y分别代表两个集合。
对于安全分析数据而言,上述预处理模型可以通过动态调整阈值将信息不完整、缺失严重、无分析价值的日志条目清洗掉,从而保证数据源的可分析性和可靠性,但由于大数据环境数据量的庞大导致对每一条数据据计算其Jaccard系数将耗费大量的时间,因此在本文的第2章将重点介绍如何通过MapReduce框架实现上述预处理模型,从而提高其效率。关于相似连接算法也将在第3章设计Map函数和Reduce函数时进行详细介绍。
2 基于改进的IAE-MapReduce数据聚合方法
MapReduce框架作为一个并行计算框架,能够大幅度提高预处理算法的效率,但对网络数据源的互补性分析而言,MapReduce框架计算过程中会产生大量相似的键值对。为了解决Map端计算结果中的键值对过多的问题,目前有两种方法:一种方法是引入Combine[9]组件,将中间结果聚合,相当于做了一小的Reduce,但这样做将会进行两次I/O,系统开销较大;另一种方法将Map端计算结果中的键值对在内存中聚合,一次计算,一次I/O,这种方法的优点是速度快,但由于Map端聚合的不足容易导致最终的计算结果可能和外聚合的结果不同。
针对上述问题,本文提出了一种改进的IAE(Internal And External)-MapReduce数据聚合方法,将聚合分为两个阶段,第一个阶段为测试阶段;第二个阶段为聚合阶段。两个阶段的具体步骤如下。
2.1 测试阶段
测试阶段的任务是测试Map端计算后的数据是否能够进行内聚合,具体做法是将要进行计算的部分数据通过内聚合方法和外聚合方法计算后,比较得到的结果是否相同。因为使用的数据少,所以时间测试阶段使用的时间将很短,相对于整个MapReduce的计算总时间,可以忽略不计。如图2所示,具体步骤如下:
1)分别通过外聚合和内聚合计算出相应的结果。
2)比较两个结果是否相同。
3)若相同则进行内聚合,若不相同则进行外聚合。
2.2 聚合阶段
1)内聚合方法。内聚合方法的作用是将聚合操作放置到内存中进行。具体步骤如下:
a)建立〈Key,Value〉倒排索引。根据读入的〈Key,Value〉中Key值建立倒排索引,在索引中记录〈Key,Address〉,Address为〈Key,Value〉在内存中的地址值。
b)对Address建立指向Count的索引。为了在内存不足时,能够及时地将匹配次数少的〈Key,Value〉调出内存,对Address建立匹配次数Count的索引,并对其进行匹配,将匹配成功的〈Key,Value〉进行合并。
c)在进行下次匹配之前,查看内存是否足够,如果内存不足够,将内存中Count值小的部分〈Key,Value〉写回磁盘。如果内存足够,查看是否还有未计算的〈Key,Value〉:如果有未计算的〈Key,Value〉,将未计算的〈Key,Value〉调入内存进行计算并返回a)继续执行;如果没有未计算的〈Key,Value〉则结束。
2)外聚合方法。〈Key,Value〉外聚合模块的作用是将聚合操作放在Map端的Map函数计算完成后统一进行。具体步骤如下:
a)将〈Key,Value〉调入内存进行计算,将计算结果写入磁盘,记为S〈Key,Value〉。
b)将磁盘中的S〈Key,Value〉重新调回内存,执行内聚合的操作。
本文提出的方法通过对Map端数据在内存中建立索引,根据数据特点选择不同的Map端数据聚合方法,减少I/O次数,同时减少了生成Mapper的数量,减少了传输的通信量和Mapper装载和卸载所消耗的时间。在下一部分,本文将介绍如何通过本文提出的IAE-MapReduce框架实现基于相似连接的预处理方法。
3 算法实现与性能分析
3.1 基于IAE-MapReduce的相似连接预处理算法实现
IAE-MapReduce框架的聚合过程中需要三个阶段:测试阶段、内聚合阶段、外聚合阶段。其中内聚合算法的核心部分如算法1所示。为了提升算法的效率,在进行相似连接算法的实现时,使用多重集合的相似连接算法,该算法需迭代三次得出结果:第一阶段得出集合中各个元素的出现次数;第二阶段分别将两个集合联合得出所含元素的次数;最后阶段根据Jaccard相似度计算公式,分别计算集合之间的相似度。其中相似连接算法的第二阶段的核心部分如算法2所示。
多重集合相似连接第二阶段主要完成的是对两个集合共有特征数量的统计,〈〈M1,M2,c1,c2〉,〈count1,count2〉〉表示集合M1和集合M2分别有c1、c2个属性值,而它们共有的某个属性的个数分别为count1、count2。
3.2 实验结果与算法性能分析
为了验证本文所提出的基于IAE-MapReduce框架的相似连接预处理算法的性能,实验首先将预处理前后的数据集大小进行比较,其次针对算法的效率,将本文方法与传统的MapReduce方法进行比较。
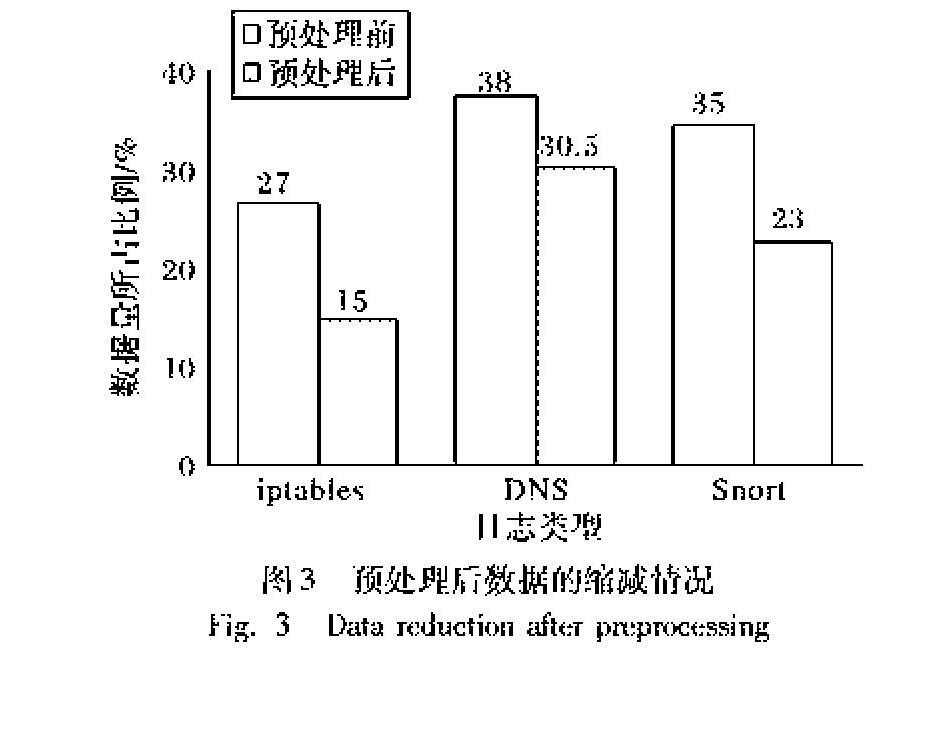
图3显示的是对防火墙(iptables)日志、域名系统(Domain Name System, DNS)日志和Snort日志进行预处理后数据量的变化。本实验共采用3GB数据进行预处理,其中约800MB为防火墙日志,约1150MB为DNS日志,约1050MB为Snort日志。使用相似连接算法对数据源进行处理时,根据相似度的不同约简出的结果略有不同,但总体上是相似的。实验结果表明本文所提出的基于相似连接的预处理方法使总的数据量减小了30%左右。
4 结语
多源数据融合分析是网络安全领域用户行为分析预测的基础,而数据清洗是其重要环节。大数据网络安全分析环境下,由于数据量的庞大,导致传统的数据清洗技术效率低,难以满足态势分析实时性的需求,据此本文提出了一种基于相似连接的多源数据预处理方法,并且采用改进的IAE-MapReduce并行处理框架去实现该方法。最后通过实验验证本文提出的预处理方法使总的数据量减小了30%,并且相比传统的MapReduce框架,效率提高了43.91%。
参考文献 (References)
[1] MAJIDI M, OSKUOEE M. Improving pattern recognition accuracy of partial discharges by new data preprocessing methods [J]. Electric Power Systems Research, 2015, 119: 100-110.
[2] LI G, DENG D, WANG J, et al. Pass-join: a partition-based method for similarity joins[J]. Proceedings of the VLDB Endowment, 2011, 5(3): 253-264.
[3] WANG J, LI G, FE J. Fast-join: an efficient method for fuzzy token matching based string similarity join[C]// Proceedings of the 2011 International Conference on Data Engineering. Piscataway, NJ: IEEE, 2011: 458-469. 本文文獻列表存在重复现象,如文献3与文献14是同一个文献,请作相应调整,因为在正文中的引用文献的顺序是依次进行的,所以建议将文献3(或14)改为另外一条文献,注意彼此间不要再重复了。
[4] 陈一帆,赵翔,何培俊,等.BMGSJoin:一种基于MapReduce的图相似度连接算法[J].模式识别与人工智能,2015,28(5):472-480.(CHEN Y F, ZHAO X, HE P J, et al. BMGSJoin: a MapReduce based graph similarity join algorithm [J]. Pattern Recognition & Artificial Intelligence, 2015, 28(5): 472-480.)
[5] 陈子军,张娟娜,刘文远.MapReduce框架下基于范围的空间文本相似连接[J].小型微型计算机系统,2015,36(10):2245-2251.(CHEN Z J, ZHANG J N, LIU W Y. Range-based spatial text similarity connection under MapReduce framework[J]. Journal of Chinese Computer Systems, 2015, 36(10): 2245-2251.)
[6] BU Y, HOWE B, BALAZINSKA M, et al. HaLoop: efficient iterative data processing on large clusters[J]. Proceedings of the VLDB Endowment, 2010, 3(1/2): 285-296.
[7] ZHANG Y, GAO Q, GAO L, et al. iMapReduce: a distributed computing framework for iterative computation [J]. Journal of Grid Computing, 2012, 10(1): 47-68.
[8] 荣垂田,徐天任,杜小勇.基于划分的集合相似连接[J].计算机研究与发展,2012,49(10):2066-2076.(RONG C T, XU T R, DU X Y. Partition-based set similarity join [J]. Journal of Computer Research and Development, 2012, 49(10): 2066-2076.)
[9] STUART J A, OWENS J D. Multi-GPU MapReduce on GPU clusters[C]// Proceedings of the 2011 International Conference on Parallel & Distributed Processing Symposium. Piscataway, NJ: IEEE, 2011: 1068-1079.
[10] LIN F, SONG C, XU X, et al. Sensing from the bottom: smart insole enabled patient handling activity recognition through manifold learning[C]// Proceedings of the 2016 International Conference on Connected Health: Applications, Systems and Engineering Technologies. Piscataway, NJ: IEEE, 2016: 254-263.
[11] LU J, WANG G, DENG W, et al. Multi-manifold deep metric learning for image set classification[C]// Proceedings of the 2015 International Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1137-1145.
[12-7] ZHANG Y, GAO Q, GAO L, et al. iMapReduce: a distributed computing framework for iterative computation [J]. Journal of Grid Computing, 2012, 10(1): 47-68.
[13-4] 陳一帆,赵翔,何培俊,等.BMGSJoin:一种基于MapReduce的图相似度连接算法[J].模式识别与人工智能,2015,28(5):472-480.(Chen Y, Zhao X, He P, et al. BMGSJoin: a MapReduce based graph similarity join algorithm [J]. Pattern Recognition & Artificial Intelligence, 2015, 28(5): 472-480.)
[14-3] WANG J, LI G, FE J. Fast-join: an efficient method for fuzzy token matching based string similarity join[C]// Proceedings of the 2011 International Conference on Data Engineering. Piscataway, NJ: IEEE, 2011: 458-469.
[12] 刘雪莉,王宏志,李建中,等.基于实体的相似性连接算法[J].软件学报,2015,26(6):1421-1437.(LIU X L, WANG H Z, LI J Z, et al. Entity-based similarity join algorithm[J]. Journal of Software, 2015, 26(6): 1421-1437.)
猜你喜欢
档案天地(2022年2期)2022-02-21
计算机世界(2020年36期)2020-09-27
科学大众(中学)(2019年2期)2019-04-08
湖北教育·综合资讯(2017年7期)2017-07-29
瞭望东方周刊(2017年22期)2017-06-22
计算机世界(2016年1期)2016-02-24
