
基于智能视频识别技术的机车司机行为辨识系统的设计与实现*
2019-07-29 09:47张瑞芳杨红运卢万平杨旭林
铁道机车车辆 2019年3期
张瑞芳, 苗 勇, 杨红运, 卢万平, 杨旭林
(1 中国铁道科学研究院集团有限公司 机车车辆研究所, 北京 100081;2 北京纵横机电科技有限公司, 北京 100094)
近几年来,视频分析与识别技术已取得突飞进展,理论成果已广泛应用于交通、安防、金融、建筑、医学、军事等领域,主要应用有人脸识别[1]、视频客流统计、疲劳状态检测、人群聚集度检测、移动物体跟踪[2]、可疑行为识别[3]等,取得了令人瞩目的成果。
和谐机车上已批量安装机车车载安全防护系统(6A系统)[4]的视频监控设备,对机车乘务员在值乘当中标准化作业执行不到位、精力不集中、盹睡、间断瞭望、错输命令号等违章行为通过网络或电话形式及时给予提醒纠偏,避免列车发生冒进信号、冲动冲撞、撞牲畜甚至撞人等事故。目前,对该装备的视频数据的地面分析任务采用人工浏览察看方式,一方面分析全部机车的视频录像需要配备大量且足够的地面视频数据分析人员和设备,分析效率低,特别对于特定事件查找的情况下,分析工作量巨大,且容易遗漏。另一方面,由于是事后做人工分析,无法对乘务员在机车运行过程中不当行为进行实时提醒。因此,基于智能视频识别技术,设计了机车司机行为识别系统。
1 系统框架设计
机车司机行为辨识系统主要由摄像机、存储设备、报警设备,以及内置行为识别模块的视频智能识别板卡4部分组成,如图1所示。行为识别模块主要通过采集摄像头拍摄到的机车司机室的实时监控图像,采用深度学习的算法,自动检测识别出在机车运行环境下乘务员的行为,识别速度快,在服务器上能达到实时,板卡上能达到0.45 m/s的速度。
对机车司机行为进行分类,总结出6大类动作,具体定义如下:

图1 机车司机行为识别系统总体框架
(1)离开座位检测:列车驾驶员在工作时间段内,擅自离开了岗位,这种情况判断为离岗行为。
(2)正常工作检测:列车驾驶员在工作时间段内,按照要求一直坚守在自己的岗位,则判定为正常工作。
(3)接听电话:列车驾驶员在工作时间段内,有接听电话的动作时将会被识别出来。
(4)向前挥手:列车驾驶员在工作时间段内,有检测到右手向前方示意,则判定为挥手。
(5)扒着睡觉:驾驶员在工作时间段内,检测到有扒在驾驶操控台上睡觉的动作时,将其检测出来。
(6)站立:在工作时间段内,当有人在驾驶室站立或者随意走动,算法将会检测到并标注为站立状态。
视频中人体的动作识别不同于图像的检测与识别,动作是一连贯的子动作构成的序列,传统的图像检测大都不能有效的识别复杂场景中的动作。另外,视频分析与识别技术在机车环境下的应用与常规应用有较大区别,机车运行中振动幅度较大,成像模糊,影响视频画面的稳定、列车运行过程中光照变化比较大,影响识别的准确度、机车环境下识别对象差异较大,也会影响视频识别的适应性等。视频图像的处理同时面临光照、遮挡、旋转等因素的影响,导致传统动作识别的精度并不高。近几年,深度学习技术在图像和语音识别等领域获得巨大成功,其识别率已经远远超过传统识别算法,因此,本系统将机器学习(深度学习)的相关技术应用于机车司机行为识别当中。
2 系统实现
本系统主要分为模型训练和行为判别两个阶段,其中,模型训练在历史视频司机行为分析系统完成,行为识别在实时视频司机行为分析系统中完成。
2.1 模型训练
基于6A历史视频司机行为分析系统主要完成数据训练,大量视频数据的分析、处理,完成对6类司机行为动作的检测,存储盘采用8T企业监控盘,主要完成6类结果的分类存储。针对铁路司机室视频,目前在服务器上处理速度能达到110帧/s,可以对数据进行训练、预测并将结果保存下来。
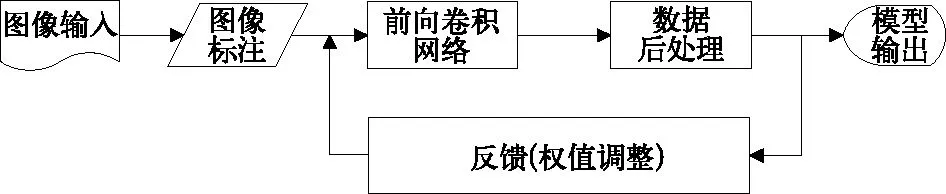
图2 模型训练流程
模型训练基于6A系统视频监控子系统的大量视频数据,通过图像输入、图像标注、前向卷积网络模块、数据后处理模块、反馈网络模块5个流程后输出模型,每个模块内容及作用如下:
(1)图像输入:待训练的机车司机室内的6类预先定义好的图像集合,包含正常作业、打电话、向前挥手、在岗、站立、睡觉共计6类常见的机车司机行为。但该动作的定义是开放的,用户也可以根据需要自定义动作的类别。
(2)图像标注:该步骤主要是手动标注目标框,并保存目标矩形框的相关信息(起始位置,宽、高等)的过程,为适应算法需要,在实际使用过程中,这些信息被预先做出相应的处理(归一化)并保存。
(3)前向卷积网络[5]:该模块是识别算法的核心,是当下最适合应用于图像识别的卷积网络,该模块包含若干层卷积层和一些降采样、非线性变换等,对训练图像集进行一级一级的抽象化,最终得到一些对训练以外的图像也具有一定识别能力的模型特征(以模型权重的形式存储)。输入图像经过一系列处理,代表性信息逐渐减少,也意味着经过卷积网络处理后,有价值的信息得以保存,而一些冗余的信息被摒弃,也即是图像特征被抽象化了,大量图像特征信息的相互作用,共同训练出一个鲁棒的模型输出。
(4)数据后处理:该模块也是训练过程特有的一个环节,主要对前向卷积网络得出的结果进行一些后处理,以备下一步骤使用。
(5)反馈网络:该步骤起到对前向卷积网络得出的权重进行调节的作用,利用梯度下降法优化代价函数,从后向前逐级调整每一层卷积网络的权重值,从而使得输出模型的泛化能力得到较大的提升。
视频行为识别模块作为系统的应用层,内置于ubuntu14.04操作系统。由于本算法需要用到深度神经网络模型,训练需要GPU加速,因此需要使用CUDA应用程序。
图像标注和前向卷积网络为整个系统的核心,将接收到的摄像机拍摄的视频图像进行去除噪声、灰度变换、几何校正等预处理,尽量降低机车环境对于视频分析的影响。该模块对预处理后的图像进行以下检测识别:离开岗位检测、坚守岗位检测、接听电话、向前挥手、睡觉检测、站立检测,一方面将识别后的报警信息发送至司机室的报警装置,对司机进行提醒,同时在识别后的图像上打上特定的标签,并进行编码存储,通过标准的检索工具,则能实现对已经被记录的特定事件的查询。
2.2 实时视频司机行为分析
实时视频司机行为分析系统主要由摄像机前端、存储设备(16G)、视频智能识别板卡、报警设备等组成,摄像头前端主要完成对司机室视频的采集,视频智能识别板卡内置的行为识别模块主要完成对常见的6类动作检测和识别,用户可以自定义并添加新的动作类别。存储设备主要用来存储已经识别过的视频图像,报警设备主要完成对司机不良行为的在线提醒。通过对机车司机室视频6大类日常行为进行在线识别,可对于机车运行过程中乘务员不符合规则的行为进行在线提醒,提高机车运用的安全性。
建立基于视频图像的事件检测与行为分析系统,检索关心的状态项点,可以避免大量垃圾信息干扰的麻烦。同时通过对图像自动化的检索,便于解脱繁重的人工工作,提高分析的效率和准确性。

图3 行为判别流程
行为判别环节是使用训练环节得到的模型对图像(视频)进行识别的过程,正如以上模型训练环节提到的那样,该环节不包含图像标注、反馈网络、数据后处理3个步骤,输入图像和模型直接加载到卷积网络,得到识别结果,图3描述了行为识别的整体流程,其中的步骤内容及作用如下:
(1)模型加载:模型指的是训练得出的各网络层的权重值,共几十万~几百万个参数,整个识别过程模型只需要加载一次
(2)前向卷积网络:和训练环节的前向卷积网络几乎相同,只是增加了一个Detection层,以便对识别结果进行约束,该行为识别算法双管齐下,能同时准确地标注出物体的位置,并同时预测出物体的类别,两者相辅相成,从而提高了检测识别的可信度。
(3)识别结果:最终输出结果可预测出司机动作是属于含正常作业、打电话、向前挥手、在岗、站立、睡觉6类中的哪一类。司机动作识别目前仅限于上述6类特定的动作,只有上述6类经过模型训练过的动作才能被识别。
3 结束语
基于智能视频识别技术的机车司机行为辨识系统主要由模型训练和实时视频司机行为分析两部分组成。其中,模型训练基于6A系统视频监控子系统的大量视频数据,利用深度学习技术,通过图像输入、图像标注、前向卷积网络模块、数据后处理模块、反馈网络模块5个流程后输出模型。该系统大大降低视频监控人员的工作量,并对机车司机不安全行为及时提示,保障了机车运行安全。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
哈尔滨铁道科技(2020年3期)2021-01-18
文萃报·周二版(2021年51期)2021-01-02
电子制作(2019年13期)2020-01-14
杂文月刊(2019年19期)2019-12-04
电子制作(2019年11期)2019-07-04
铁道通信信号(2019年2期)2019-03-26
小天使·一年级语数英综合(2019年11期)2019-01-13
北京航空航天大学学报(2018年1期)2018-04-20
今古传奇·故事版(2017年24期)2018-02-07
