
SSRC:时延敏感流的数据源端速率控制算法
2019-07-26 02:33杨洋曹敏杨家海车嵘刘伟
通信学报 2019年7期
杨洋,曹敏,杨家海,车嵘,刘伟
(1. 国防科技大学信息通信学院,陕西 西安 710106;2. 清华大学网络科学与网络空间研究院,北京 100084;3. 清华信息科学与技术国家实验室(筹),北京 100084)
1 引言
当前,数据中心95%以上的数据流都是TCP流[1],随着业务种类急剧增长,流量的多样性越来越突出。这些流量可以分为2类:一类是吞吐量敏感型的流量,例如,大量云计算业务由于虚拟机迁移、数据备份等操作产生的长流;另一类是时延敏感型的流量,例如,Web请求(包括搜索流量)业务、基于MapReduce[2]的并行计算业务以及社交网络等在线业务产生的短流。数据中心为业务提供高可用聚合带宽保证的同时,网络拥塞也频繁发生,同时网络中出现的Incast现象逐渐成为数据中心区别于传统互联网的标志性事件。由于当前数据中心产生的短流类型业务大部分是有流传输截止时间要求的业务,一旦传输路径中出现链路拥塞,就会导致传输超时并严重影响用户体验。由于TCP长流的“贪婪性”会导致交换机缓存中数据分组排队队列增长,直到缓存溢出产生分组丢失。如果链路中长短流共存,会导致2种情况发生:一种是短流分组丢失导致Incast出现;另一种是虽然短流分组不丢失,但由于在缓存中排队的短流数据分组转发优先权低于长流数据分组,导致短流数据排队时间超出流传输截止时间。由于数据中心短流具有突发、不可预测特性,网络中任何一条传输链路都有可能存在因链路拥塞而产生的长短流碰撞,导致出现短流分组丢失的可能性。因此,为保证数据中心时延敏感流的传输时间,有必要在数据源端对引起交换机缓存队列长度超过阈值的长流进行速率调节,以避免链路中长短流碰撞而导致短流分组丢失。
当前数据中心产生短流类型的业务大部分是有流传输截止时间要求的业务,例如,Web请求类业务、基于MapReduce并行计算业务等,一旦传输路径中出现链路拥塞,就会导致传输超时并严重影响用户体验。另外,由于网络中存在大量采用分割/汇聚(partition/aggregate)技术的业务,例如,MapReduce以及搜索请求业务等,这种“多对一”的通信方式带来的TCP Incast问题也越来越突出[3]。由于 Incast问题通常是由承载汇聚信息的短流分组丢失引起的,因此,Incast问题的解决可以转化为针对时延敏感的短流进行避免传输链路拥塞的研究[4-6]。当前针对数据中心时延敏感流量进行数据源端速率控制的研究工作可以分为以下2类。
1) 终端设备解决算法
终端设备的解决算法是指在数据发送端通过调整发送窗口值的大小来控制发送速率的算法。例如,TCP Newreno是对TCP的改进版本,通过引入快速恢复机制避免了快速重传之后马上进入慢启动阶段而导致发送窗口减小过大的问题,是当前网络通信普遍采用的协议。文献[7]通过将最小超时重传时间RTOmin(retransmission time out)减小到微秒级,缓解由于产生Incast问题而造成的吞吐量下降。另一类算法是设计改进的TCP,例如,D2TCP[8]通过提前获取数据流传输的截止时间,并根据流截止时间作为调整拥塞窗口的惩罚因子,计算拥塞窗口大小,达到通过控制数据流传输速率来消除拥塞的目的。ICTCP[9]以接收端实际测量吞吐量与期望吞吐量之间的差值比率是否超过某个阈值,作为调整接收窗口大小的依据,并将调整的窗口信息以ACK信号反馈给发送端,达到控制数据流速率的目的,从而避免链路拥塞导致的短流分组丢失。文献[10]提出 MMPTCP(maximum multi-path TCP),在终端设置数据流传输阈值,数据流传输初始阶段是基于分组粒度的多路径负载均衡,使时延敏感型的数据流受益;当传输数据量超过阈值时,进入第二阶段,即由基于数据分组粒度的多路径负载均衡方式切换到 MPTCP(multi-path TCP)[11]模式,有效地保证长流吞吐量。文献[3]则提出了应用层的解决算法,以一定的随机概率刻意延迟服务器对请求的响应,从而在某个时间段减少同时参与请求响应的服务器数量,解决Incast的同步屏障问题。
2) 交换设备支持的解决算法
交换设备支持的解决算法是指由交换机(或路由器)与终端主机共同解决拥塞避免的算法。例如,DCTCP(data center TCP)[1]基于 ECN(explicit congestion notification)[12]的功能,通过设置交换机缓存队列长度阈值,对超过阈值的数据分组进行标记,数据源端则根据反馈的拥塞程度信息按照一定的衰减因子动态调整发送窗口,被标记的分组数量越多、衰减因子越大,发送窗口就越小,从而始终保证交换机队列长度低于某个阈值,防止由于缓存溢出而丢弃数据分组。D3[13]则采用带宽资源预留的方式,提前为数据流分配所需传输带宽。数据源端首先获取数据流截止时间以及流大小信息,在每一轮 RTT(round trip time)周期内发送相关传输数据的带宽需求信息,交换机收到该信息后计算出预留带宽并将预留带宽值写入数据分组头。数据分组传输路径上的所有交换机将执行相同的操作,从而保证数据流在截止时间内传输完毕。另外还有通过交换机向数据源端发送“暂停”帧实现流控的EFC(ethernet flow control)[14]机制以及基于IEEE 802.1Qau以太网标准提出的链路层拥塞控制算法 QCN(quantized congestion notification)[15]。
尽管当前的研究算法对于避免数据中心出现拥塞链路而导致短流分组丢失,以及针对Incast问题的解决都起到了积极的作用,然而在实际部署的可扩展性、实施开销以及时效性方面都存在不足。其中,终端设备的解决算法对于TCP的改进方法需要接入终端设备修改协议栈,实施难度高,可扩展性不强。例如,D2TCP 、ICTCP、MMPTCP都需要在终端进行阈值的设定以及相应的判断、计算操作,D2TCP还需要提前获取数据流截止时间等信息;对TCP参数进行调整实施难度虽然低,但是需要其他机制配合,否则效果不理想。例如,减小RTOmin虽然可以提升吞吐量,但也会导致欺骗性重传。交换设备参与解决的算法需要设备的硬件支持,例如,DCTCP需要在交换机缓冲区的队列长度达到阈值时对数据分组进行标记;D3则需要交换机根据数据源端的带宽需求信息计算出预留带宽,并要求传输路径上的所有交换机对这条数据流执行相同的操作;EFC和QCN都需要特定的交换机支持。交换设备参与的解决算法对设备硬件要求高,部署开销较大,尤其对于数据中心大多使用低成本的商用交换机的情况,更不适合大规模的部署。另外,基于TCP连接的反馈回路调节源端速率的算法还存在时效性不强的问题,例如,当反馈回路出现链路拥塞或者发生故障时,将影响算法执行的效率。
综上所述,本文基于SDN/OpenFlow的架构,提出了数据源端控制算法SSRC(SDN-based source rate control)。SSRC依据网络的全局视图,能够快速定位可能发生拥塞的节点,并及时对目标流的源端速率进行调节,缩短算法的响应时间。本文的主要贡献如下。
1) 利用SDN的架构设计能够对链路中出现的长流以及交换机缓存的队列长度进行监测,快速定位拥塞可能出现的位置,并确认需要进行源端速率调节的目标长流。
2) 控制器利用目标长流建立反馈回路,修改携带接收窗口大小的TCP_ACK数据分组,并直接将该数据分组推送到连接数据源端的接入层交换机,极大地缩短了算法机制的响应时间,提高了算法的时效性。
3) 通过将NS3网络仿真工具与FloodLight外部控制器相结合,形成基于 SDN架构的网络仿真平台,仿真实验结果证明SSRC能够保证时延敏感流的传输时间,同时能够很好地解决Incast问题。
2 算法设计关键问题分析
TCP长流的“贪婪性”会导致交换机缓存中数据分组排队队列增长,直到缓存溢出产生分组丢失。如果链路中长短流共存,会导致2种情况发生:一种是短流分组丢失导致Incast出现;另一种是虽然短流分组不丢失,但由于缓存中排队的短流数据分组转发优先权低于长流的数据分组,导致排队时间超出流传输截止时间。当前在集群化存储的系统内,客户端的应用请求都以服务请求数据单元(SRU, service request unit)方式分别存储在服务器上,只有当客户端收到所有服务器的 SRU后,才能继续下一个服务请求。然而在链路出现拥塞造成排队队列处理时延增大甚至导致短流分组丢失严重时,会使完成一个TCP应用请求至少经历200 ms的超时[16]。对于时延敏感的业务,将严重影响用户体验;对于MapReduce之类的并行计算业务,将严重浪费计算资源。所以,时延敏感的短流受链路拥塞影响最大,其根本原因是交换机缓存队列的积压导致链路中出现的长流与时延敏感的短流出现碰撞,造成短流分组丢失。
D2TCP和D3都是针对时延敏感的短流提出的解决算法,但是两者都需要提前获取数据流的截止时间,然而实际中这样的信息可能无法提前获取。ICTCP主要解决Incast问题,但只是针对最后一跳的链路提出的解决算法,没有考虑承载 SRU的短流分组丢失发生在中间交换节点的情况,并且通过接收端窗口大小来控制源端发送速率需要通过ACK将窗口信息反馈回发送端,如果反馈回路拥塞或者发生故障则严重影响算法的执行效率。DCTCP通过设定交换机队列长度阈值的方式并基于 ECN将拥塞程度信息反馈回发送端,这样的算法除了对交换设备要求高之外,也存在反馈回路影响算法执行效率的问题。
综上所述,本文提出基于SDN/OpenFlow框架的解决算法,能够克服现有算法存在的不足。由于SDN具有集中化管控的优势,控制器拥有全局的网络资源视图,因此更容易提前发现可能出现拥塞的节点,通过控制器下发策略避免拥塞;其次,当发现可能的拥塞节点后,控制器能快速进行响应,相对于传统网络中接收端通过反馈回路进行数据源端速率调节的算法,能够极大地缩短响应时间,提高算法的时效性。本文提出的基于 SDN/OpenFlow的数据源端速率控制算法需要解决2个关键问题:一是设计算法的触发机制,二是需要获取数据源端优化后的目标发送速率。
3 算法设计
3.1 算法触发机制
由于交换机缓存队列积压而出现长短流碰撞是导致短流分组丢失的根本原因。同时,必须注意到分组丢失发生的位置除了包含最后一跳网络节点设备外,网络中间设备都有可能由于交换设备的缓存溢出而导致分组丢失。因此,算法设计的目标是能够通过全局网络视图,提前发现有可能出现拥塞的网络节点,通过触发算法避免链路由于TCP长流的“贪婪性”造成交换机排队队列长度增加从而导致短流分组丢失。因此,算法的触发机制由2个关键条件决定:一是链路中出现长流,二是出现长流的交换设备中的队列长度超过阈值。当2个条件同时满足时算法被触发,这样设计的目的是,针对链路中容易引起短流分组丢失的目标长流,快速进行拥塞避免策略响应,增强算法执行的时效性。
1) 长流的发现
当前OpenFlow的版本都支持2种方式统计数据流信息[17]:一种是基于控制器发送Read_State消息,对交换机状态信息采用轮询的方式统计;另一种由交换机发送异步消息对控制器进行数据流信息的推送。由于交换机推送数据流信息的方式是当该流传输结束或者流表删除时向控制器推送消息,并不适合对长流的探测,因此本文采用的方法是控制器以周期轮询的方式获取交换机相关数据流信息,并以此发现长流。采用轮询的方式探测长流属于OpenFlow自带的原生测量,不会产生额外的探测开销,但需要注意的是轮询周期不能设置过小,否则会加重控制器与交换机之间的通信负担。通过对比实验,在保证能够探测到目标长流的前提下,将控制器轮询周期设置为5 s。
2) 队列长度阈值
设置交换机缓存队列长度阈值Kt,如式(1)所示。

其中,C代表瓶颈链路带宽,单位为 packet/s,即每秒传输数据分组的数量;RTT代表往返时延,单位为 s。在数据中心实际环境中,考虑到流量的突发特性,Kt往往不能取下限值,通常当链路带宽为1 Gbit/s时,设置Kt= 20;当链路带宽为10 Gbit/s时,设置Kt=65。
3.2 算法优化问题
当算法触发时,控制器需要计算出合理的数据源端发送速率,而发送速率值是由数据源端的发送窗口大小决定的。以往的研究工作中,对于数据源端发送窗口大小的反馈调节机制大部分都是基于一个前提条件,即N个数据源端发送的响应请求数据分组同时到达接收节点。通过获取并发窗口数从而计算出交换机缓存队列的长度或者瓶颈链路中剩余带宽的大小,作为调整数据源端发送速率大小的关键参数。然而在实际环境中,由于中间节点排队时延以及传输路径的差异,N个数据源端发送的请求数据分组同时到达最后一跳节点的概率非常小,以此为计算基础所带来的误差不可避免。因此,本文采用的方法是基于排队论对数据流的到达行为进行建模,从而设计更为合理的发送窗口调节机制。
3.2.1 数学模型
目前,数据流到达行为的研究主要针对 TCP流,所采用的研究方法主要分为2种:一种是基于长时间粒度统计发现 TCP流具有自相似[18]或者长相关的特性[19],对此特性进行具体研究;另一种是根据排队论的相关理论进行研究,例如文献[20]通过实际测量和仿真分析指出在链路带宽足够的情况下,数据流的到达行为服从泊松分布。由于数据中心链路具有高带宽、低时延特性,因此更适合采用排队论对数据流的到达行为进行数学建模并分析[21]。
文献[1]指出,当前数据中心普遍使用浅缓存的商用以太网交换机,此类交换机的特点是采用共享缓存交换结构。共享缓存结构是指交换机所有的输出和输入端口都共享一个缓存池,并且所有经过交换机转发的数据分组都需要在缓存中存储转发,那么一台交换机就可以抽象成一个服务窗口,此外,可以认为交换机对数据流的转发即对数据流的服务时间服从指数分布。由于算法被触发时,控制器需要立即响应,因此需要对源端发送速率进行调整,假设t时刻算法执行时需要数据源端减小数据分组进入系统的概率,那么数据流的到达率就不再是稳定值,而是依赖t时刻缓存队列长度k的函数,因此可以采用基于可变到达率的G/M/1/∞排队模型进行建模分析[22],图1描述了具有可变到达率的数据流生灭过程。

图1 可变到达率的数据流生灭过程
以图1为例,假设缓存队列长度为k(k≥1),数据流以的概率进入排队系统,λ为到达率,μ为交换机服务速率。可以得到该生灭过程稳态下的数据流到达概率分布函数,如式(2)所示。

其中,Pk为t时刻队列长度处于k状态的概率分布,ρ为数据流的排队强度。
3.2.2 优化问题
当t时刻算法触发时,交换机缓存中队列长度超过设定阈值,控制器需要计算出数据源端合适的发送窗口大小以防止缓存溢出。此时,t时刻超出阈值部分的队列长度为
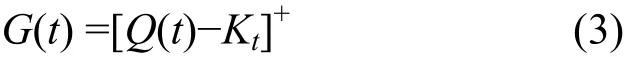
其中,Q(t)为t时刻交换机缓存队列长度;Kt为所设队列长度阈值;[•]+表示正值,保证优化问题有意义。那么优化问题就是使式(3)的队列长度差值G(t)最小,优化问题的目标函数为

排队系统进入稳定的工作状态时与时刻t无关,因此式(4)优化的目标函数G(t)可以变形为

其中,K为当前队列长度。将式(2)代入式(5)并对其求和,整理后得到式(6)。

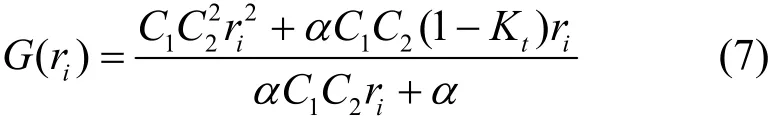
优化问题总是伴随着约束条件。首先,链路实际负载不能超过链路自身承载能力,链路负载能力用Cl表示,即其次,优化问题变量的非负取值约束,即ri>0。最终的优化问题为
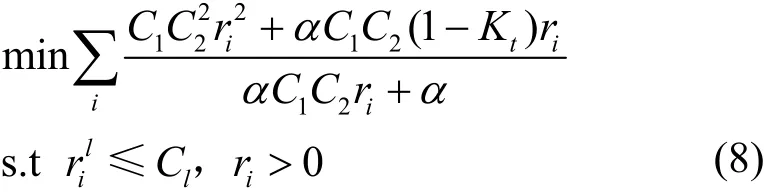
算法1 SWAA


步骤2)定义了发送窗口修改函数,参数是优化后的数据源端目标速率值ri以及链路的平均时延步骤 3)~步骤 20)具体实现了数据源端目标速率调节机制,其中,步骤8)链路的平均时延由时延抽样值 sampled_rtt和抽样次数sampled_num确定;步骤9)通过控制器轮询周期及轮询周期内统计到的数据流计数器中的传输字节值计算出数据流i初始速率,从而获得该流的到达率;步骤 17)通过调用发送窗口修改函数,得到数据源端的发送窗口目标值并返回存储,控制器通过将new_cwnd重新写入从反馈回路获取到的TCP_ACK分组,最终达到调节数据源端速率的目的。
4 算法实现
当前的研究工作中,通常依靠 TCP连接建立的反馈回路传递拥塞链路信息或者拥塞窗口大小调节信息,以达到调节发送速率的目的,避免链路拥塞的发生。但是,如果反馈回路拥塞或者发生故障则严重影响算法的时效性。本文SSRC算法能够利用SDN/OpenFlow架构的优势,很好地解决当前研究算法时效性不高的问题。首先,通过对链路中出现的长流以及交换机队列长度的监测,快速定位拥塞可能出现的节点位置并触发算法;控制器利用TCP会话建立的反馈回路修改接入层交换机的反向流表匹配规则,极大地提高数据源端对拥塞节点的响应时间,提高算法的时效性,在保证短流的传输截止时间的同时,防止出现Incast问题。算法流程如图2所示。具体步骤如下。

图2 算法设计流程
1) 控制器定时向交换机查询流表计数器值,同时监控交换机缓存队列长度。当计数器值大于长流阈值(判断为长流),且队列长度大于设定阈值时,触发算法。
2) 控制器向接收端接入交换机下发 FlowMod命令。该 FlowMod关键参数如下:匹配项为TCP_ACK,优先级为最高,HardTimeOut为RTT+ε(ε<RTT)。
3) 在接入层交换机上,如果数据流与更新后的流表匹配成功,则将数据分组发送到控制器。
4) 控制器收到packet_in消息,判断其reason== OFPR_ACTION后,修改数据分组cwnd值。
5) 将修改后的ACK分组,通过packet_out消息,直接推送到数据流源端的接入层交换机。
步骤2)的操作是由于数据源端速率更新后,至少在一个 RTT时间后接收端才能收到更新的数据分组,因此,在RTT+ε内都应保持SSRC更新后的发送窗口值。
将上述步骤转换成控制器端可执行的算法程序,并提出数据源端控制算法 SSRC(SDN-based source rate control),如算法2所示。
算法2 SSRC


步骤1)~步骤4)设置了SSRC算法的初始值。步骤 5)~步骤 11)定义了长流判断函数。步骤 12)~步骤 16)定义了队列长度是否超过设置阈值的判断函数。步骤18)~步骤33)是SSRC的核心代码,其中,步骤18)~步骤24)判断当目标长流出现并且队列长度超出阈值,也就是步骤18)的判断为真时,控制器会向交换机下发 FlowMod的命令,即步骤 19)~步骤 23)代码;步骤 25)~步骤 33)执行了当控制器接收到 packet_in消息时,判断出产生packet_in的原因是FlowMod匹配项得以匹配,此时控制器会对数据分组进行解析,获得数据分组头中的拥塞窗口值,调用SWAA算法进行修改(步骤30)),并将修改后的数据分组直接推送到源端的边缘层交换机。至此,SSRC执行完毕。由于算法 2是在一段时间内遍历 n条数据流并进行长流的判定,因此算法2时间复杂度为O(n)。
5 仿真与评估
5.1 仿真平台构建
集中架构的仿真平台采用NS3+Floodlight进行搭建。平台运行的宿主机是戴尔OptiPlex9020服务器,设备硬件的性能参数为:8核/3.4 GHz主频的64位处理器,10 GB内存,操作系统采用Ubuntu16.04版本。同时,宿主机部署了支持对OpenFlow协议分析的wireshark软件。
NS3仿真器采用v3.6版本,使用Floodlight控制器作为外部控制器,并通过Tapbridge与NS3相连。由于NS3具有离散时间仿真的特点,即一旦仿真开始,就不能中途修改参数。为了实现SSRC的控制功能,本文编写2个功能模块预置在Floodlight的应用程序中:一个是 AddDSCPFlowMod,实现下发流表和添加meter entry;另一个是DSCPController,实现解析数据分组和修改发送窗口值后,将携带发送窗口目标值的数据分组直接推送到连接发送端的接入层交换机。
仿真拓扑选择当前数据中心普遍采用的以交换机为核心的多层拓扑结构,实验将构建K(交换机接入端口数)值可变的胖树(fat-tree)拓扑,并以K=8即具有8个POD(performance optimization datacenter)的拓扑规模进行仿真实验,如图3所示。其中,核心层的交换机编号为S101~116,汇聚层的交换机编号为S201~S232,边缘层的交换机编号为S301~S332,终端主机的编号为H001~H128。
5.2 实验设计
5.2.1 实验对象选择
SSRC性能实验的对比算法选择TCP_NewReno以及先前研究工作中具有代表性的2个解决算法。其中,代表终端解决算法采用文献[3]的方法,即减小最小超时重传时间 RTOmin,该算法依然基于NewReno算法,只是减小了RTOmin值,实现方法简单,易于部署;DCTCP则代表交换设备解决算法,基于ECN的标记功能,但是不同于ECN对交换机平均队列长度阈值做出响应,DCTCP是对交换机瞬时队列超过阈值的数据分组进行标记,其次,ECN的发送端在收到接收端标记的响应数据分组后,发送窗口减半,而DCTCP发送端通过感知网络中间节点的拥塞程度来动态调节发送窗口大小,具体做法是被标记的分组数量越多、衰减因子越大,发送窗口就越小。相比ECN,DCTCP对网络拥塞的响应更加及时并且能保证网络吞吐量的需求,是针对Incast问题比较有效的解决算法。
5.2.2 关键变量设置
考虑到NS3仿真平台与实际部署的差距,设计实验时首先需要对仿真过程中的关键变量(即会对实验结果产生重要影响但不是实验研究对象的变量)进行设定,关键变量设置的合理性将直接关系到实验结果的准确性。本实验需要设置的关键变量是仿真系统默认的 RTOmin值以及背景流个数(长流)。
1) RTOmin值
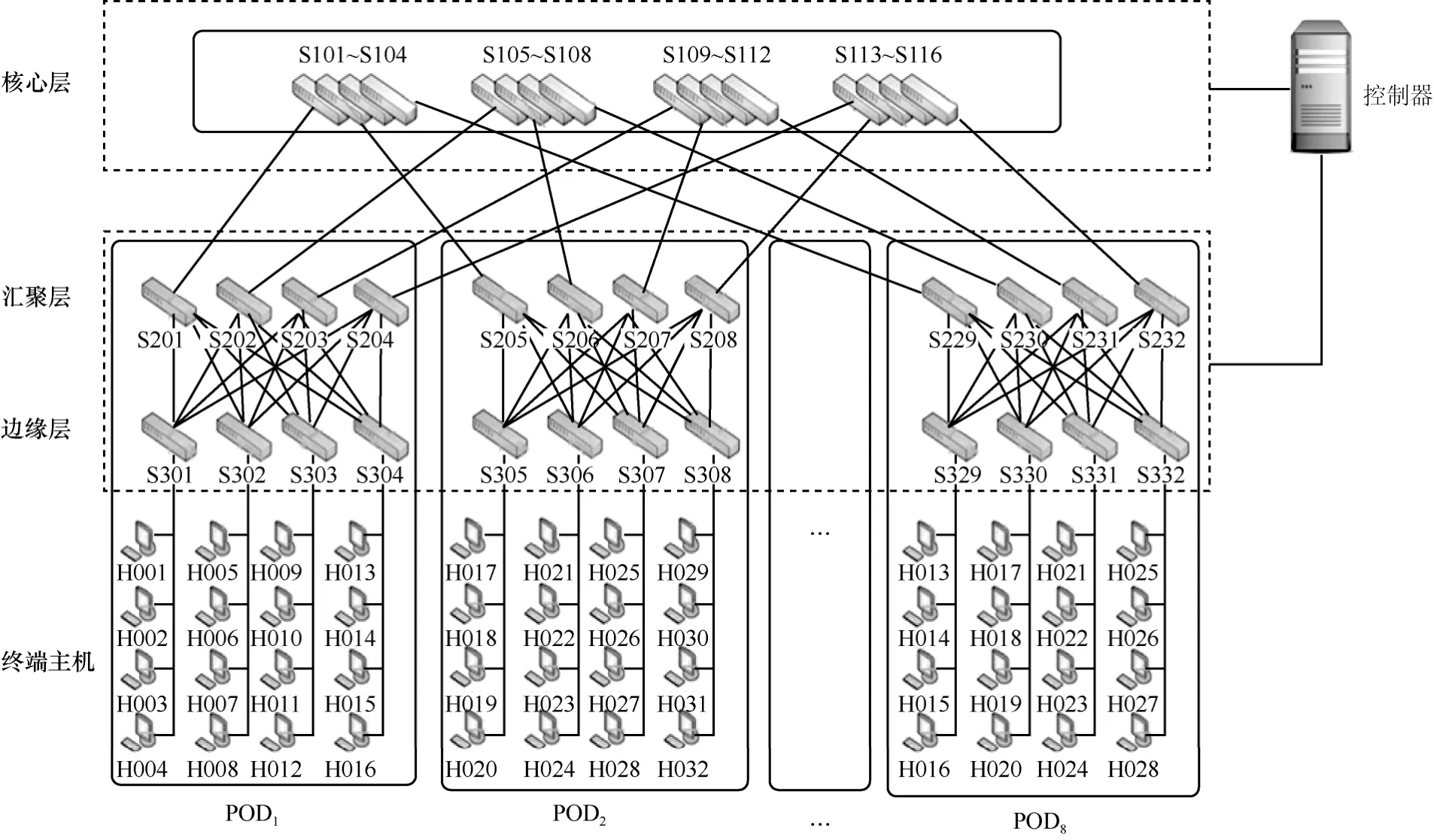
图3 实验拓扑
NS3-3.26版本内核的默认 RTOmin=1 s,但是在实际实验过程中发现了虚假重传的现象。证明实验如下。20个数据源端在没有背景流的条件下同时发送请求短流,并保证足够的链路带宽以及数据接收端的缓存容量完全可以容纳所有的数据分组。通过对实验数据统计发现并没有出现分组丢失现象,然而经过wireshark抓取分组分析却发现了虚假重传现象,如图4所示。当RTOmin=1 s时,所有发送短流都存在虚假重传。因此,为了准确还原对比算法的实验效果,仿真中针对RTOmin参数值的设置需要考虑2个关键要素:首先,需要模拟出DCTCP运行的默认RTOmin值,既能保证不发生虚假重传,又能保证不会因为 RTOmin值过大而增大时延;其次,需要模拟出 Linux内核中默认的RTOmin=200 ms的TCP连接传输效果。为了满足以上目标,实验重新设计如下:20个主机同时发送请求短流,在没有背景流的情况下,以0.1 s为步长改变RTOmin,统计这20条数据流在不同RTOmin值下发生虚假重传的比例。实验结果如图4所示,可以观察到当RTOmin<3.1 s时,所有的数据流都会发生至少一次的虚假重传,随着RTOmin值增加,发生虚假重传的百分比减少,当RTOmin>5 s时,基本达到稳定值,即所有数据流都不会受到虚假重传的影响。

图4 最小超时重传时间设置分析
为了保证实验结果的准确性以及还原比较对象原本的实验效果,需要进一步确认RTOmin值。从图4的分析中可以观察到,RTOmin≥5.8 s时性能比较稳定,通过多次测试,最终确认RTOmin=10 s。为了验证合理性,以默认值 10 s为基准,比较了当RTOmin设置过小的情况下虚假重传的表现。图5显示了主机10.1.1.3在RTOmin= 1 s和RTOmin= 10 s下的实验结果对比。
从图5可以观察到,当RTOmin=1 s时,在TCP通信连接建立的过程中,所有数据分组几乎同时在22 s左右发送,导致数据流时延增大,而此时的RTOmin值又太小,因此导致在24 s源端又发送了一次连接请求。当 RTOmin=10 s时,可以明显看到源端3次握手后顺利地建立了连接,缩短了流传输的时间。
此外,实验也模拟了 RTOmin设置过大的情况,并以保证 Linux内核中默认RTOmin=200 ms时的TCP并发连接时的网络性能表现(吞吐量下降2个数量级),测试后发现RTOmin=100 s时可以满足对比要求。最终,对比实验结果发现,当RTOmin=10 s时,流完成时间为 6.3 s,当RTOmin=100 s时,流完成时间变成了103.4 s,因此本实验设置 RTOmin=10 s能够模拟出真实的网络情况。
2) 背景流个数

图5 RTOmin分别为1 s和10 s设置分析
在以往研究工作的同类实验中,一般选择背景流为5条。但是实际应根据实验规模来确定,因为背景流数目太大,占总数据流的比重过大,一方面会加剧请求短流的分组丢失;另一方面在模拟 Incast环境时,即使请求短流并发数目很小也会有严重的分组丢失现象。背景流数目太少又无法提供客观的比较值,在计算吞吐量时会有较大误差。因此应选择与实际环境中请求短流和背景流比例相匹配的数据流个数为宜,具体的比例参见DCTCP[1]。图6是在并发服务器个数分别为 20和 30下,改变背景流个数,对20条请求短流完成时间的统计结果,目标为尽量减小背景流数目变化对不同并发数下流完成时间的影响,最终选定本次实验的背景流数为6条。

图6 背景流数量设置分析
5.2.3 实验部署
通过对实验关键变量的分析与设置,本文实验部署如下:实验瓶颈链路带宽设置为100 Mbit/s,网络节点交换机的缓存容量为64 KB。实验拓扑如图3所示,每个POD连接16台服务器主机,共8个POD,编号为1~8。数据发送端和接收端属于不同POD,故设定POD8中一台主机为接收端,同时为了避免服务器接入链路成为瓶颈链路,发送端主机由其余 POD平均分配,其中,POD1~POD6分别随机选择一台主机,以随机时间依次开始向接收端发送的长流作为背景流量;每个POD另外选择1~12台主机并发产生SRU,每个SRU大小设为256 KB,因此接收端共计请求数据源端发送流量大小为N×SRU,N为并发数,1≤N≤80。SSRC的性能表现将基于数据流完成时间、网络平均吞吐量以及分组丢失率这3个指标进行评估。
5.3 性能评估
5.3.1 数据流完成时间
由于NS3仿真平台的特殊性,在实际环境中,平均流完成时间正比于并发服务器个数,系数为同时,考虑到NS3平台中使用了CSMA信道,以及其他可能的干扰因素,为了保证实验的严谨性,进行图7 (a)所示的实验,找出在没有背景流的情况下,增加并发服务器个数与数据平均流完成时间拟合的二次函数。图7(b)为4种算法在增大并发服务器个数下的表现。首先,由于背景流的存在,所有算法下短流的传输时间都受到了很大的影响。例如比较并发数为45条,增加6条背景流,共 51条数据流同时竞争信道时,短流的平均流完成时间最优可达到10.50 s(SSRC、NewReno下为30.12 s),而没有背景流存在时,45条数据流传输的平均流完成时间为5.33 s,也就是说出现了成倍的增长。此外,对比4种算法的表现可以得出,并发数较少时,不同算法表现没有太大差异,流完成时间基本维持在7 s左右;随着数据流并发数的增多,流完成时间开始增加。相比于其他3种算法,SSRC增加幅度为 62.3%,NewReno、RTOmin和DCTCP分别为411.4%、273.2%和168.1%,SSRC的优化效果十分明显。

图7 流完成时间比较
5.3.2 网络平均吞吐量
吞吐量主要针对长流来分析。长流对于时延不是十分敏感,但是对于吞吐量的要求很高,当链路发生拥塞时,长流分组丢失会造成吞吐量的断崖式下降。另一个特征是TCP NewReno下不同背景流的吞吐量方差很大,反映出部分长流在传输过程中的分组丢失可能更多,而一旦发生分组丢失,很难再和其他正常传输的数据流竞争信道,最终表现为链路资源分配的不均匀。因此实验就上述 2个方面进行比较。由图8(a)可以看出,相比于其他算法,随着并发数的增多,SSRC依然能保持较高的吞吐量;图8(b)进一步从吞吐量的标准差对比来验证 SSRC性能。图 8(b)中不同的虚线是对不同并发数下吞吐量标准差的一次线性拟合,可以清晰地看出,通过 SSRC对源端速率的精确控制,能够保证链路充分利用,并且较为平均地将资源分配给每一条数据流。
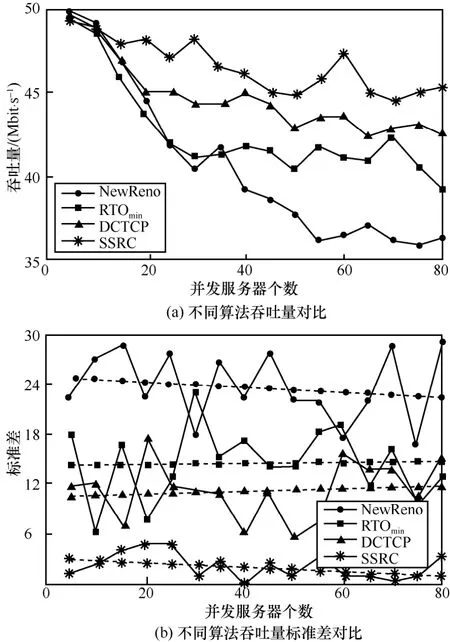
图8 吞吐量性能比较
5.3.3 分组丢失率
分组丢失对于长流会造成吞吐量的明显下降,对于时延敏感的短流会造成超时重传。为了明确NS3中长流和短流在并发时各自的特性,设计了以下实验:数据中心拓扑中维持6条背景流,在仿真开始后的 23 s左右(此时背景流传输稳定),30个服务器并发发送大小为2 KB的SRU,统计在这30个服务器第一个分组发送后,每秒内长流和短流各种传输的数据分组数目,以及分组丢失的数目(在RTOmin算法下)。仿真实验中,第一个短流的数据分组在23.484 645 s发出,最后一个数据分组在35.837 998 s收到,统计后得到的结果如图9所示。

图9 长短流分组丢失比较
短流在开始的4 s内,发生了严重的分组丢失现象,而长流的分组丢失不严重,说明在开始竞争信道时,交换机缓存中基本上都是长流的数据分组,后来到达的短流很容易超过阈值而被丢弃,也就是说短流在与长流的竞争中处于劣势。5~8 s,链路依然繁忙,此时已经有部分的短流占据了缓存,导致之后的长流分组丢失率上升,而且短流本身只有2 KB,很容易塞满交换机而不被丢弃。9 s后短流基本已经传输完成,通过交换机的数据分组占比快速下降,即使缓存溢出,被丢弃的概率也很小。此外,整个实验结果都反映了长流的“贪婪性”,因为如果链路资源均匀分配,每个时间段内发送的数据分组平均应该有 16.67%来自长流,而实际中长流占比最少时(第 7 s)也达到了总传输量的33.33%,而且长流占比的下降很可能是之前连续的分组丢失使源端退避而暂时降低了链路资源的占用。通过上面的实验可以看出,NS3环境下长短流基本的特性和实际网络环境中一致。在长短流特性已知的前提下保证背景流数目为 6且不变,增加并发服务器个数,对短流的分组丢失率进行统计,如图10所示。对比发现,SSRC的控制算法降低分组丢失率的表现优越,即使在链路状态十分恶劣的情况下,也基本能够保证分组丢失总数在10个以内。

图10 分组丢失率比较
6 结束语
本文针对数据中心网络如何保证时延敏感流的传输时间问题进行了相关研究,在
SDN/OpenFlow的架构下,提出了一种基于数据源端速率控制的算法 SSRC。该算法能够准确定位可能发生拥塞的节点设备,通过控制器快速进行应对策略的响应,相较于传统网络中接收端通过反馈回路进行数据源端速率调节的算法,能够极大地缩短响应时间,解决现有算法时效性不高的问题。最后,通过将NS3仿真工具与Floodlight外部控制器相连,实现SDN/OpenFlow架构下的数据中心网络环境中进行,同时与 DCTCP等 3种解决算法进行比较,仿真实验结果证明SSRC能够保证时延敏感流的传输时间,同时能够很好地解决Incast问题。
猜你喜欢
数据与计算发展前沿(2021年5期)2021-11-30
汽车维修与保养(2020年10期)2021-01-22
科学导报·学术(2020年26期)2020-10-21
汽车维修与保养(2020年11期)2020-06-09
小学生学习指导(低年级)(2020年4期)2020-06-02
中国人民公安大学学报(自然科学版)(2020年1期)2020-05-15
软件(2020年3期)2020-04-20
小型微型计算机系统(2019年3期)2019-03-13
军营文化天地(2018年2期)2018-12-15
计算机与生活(2018年3期)2018-03-12
