
基于深度学习的铁路图像场景分类优化研究①
2019-07-23 02:08代明睿马小宁
计算机系统应用 2019年6期
赵 冰,李 平,代明睿,马小宁
1(中国铁道科学研究院 研究生部,北京 100081)
2(中国铁道科学研究院 铁路大数据研究与应用创新中心,北京 100081)
铁路检修及监控任务产生大量的图像数据,图像 后续分析一般与图像拍摄场景相关联,但目前图像储存后缺乏科学有效图像场景分类方法,限制了图像价值的分析与挖掘.由于铁路领域缺乏专业大规模图像数据集,与自然图像相比,图像包含大量前景语义,铁路领域因素明显,同时复杂光照条件、恶劣环境因素、设备素质局限均影响成像效果,增加了铁路图像场景分类任务的难度.快速准确的图加了铁路图像场景分类任务的难度[1].快速准确的图像场景自动分类方法有助于图像分析研究工作,可为铁路部件检测、安保监控、周界防护等研究工作提供图像分类预处理流程,具有切实研究应用价值.
目前图像场景分类方法可分为两类:基于手动特征提取方法与基于深度学习的方法.基于手动特征提取的分类方法在几十年的发展中已趋于完善,Harris 角点检测子[2]、DoG 算子[3](Difference of Gaussian )等兴趣点检测算法选择局部明显特征,在较小的计算开销下能够获得一定的空间几何不变性;方向梯度直方图HOG[4](Histogram of Oriented Gradient)、尺度不变特征转换SIFT[5](Scale Invariant Feature Transform)、局部二值模式LBP[6](Local Binary Pattern)等方法采取密集的特征提取方式,结合支持向量机SVM[7](Support Vector Machine)获得了更优的特征提取效果.基于深度学习方法的CNN 网络可对数据进行自动特征提取,克服了传统提取特征方法需要手动设计特征提取算子的弊端,随着2012年ImageNet 大规模视觉识别挑战赛上AlexNet 超越传统方法,在图像分类任务上取得优异成绩后,后续VGG、GoogLeNet、InceptionNet、ResNet 等CNN 网络模型的提出,使得基于CNN 的深度学习技术成为图像分类任务的主流方法[8].尽管表现出色,但CNN 模型的可解释性问题一直为人诟病,在对CNN 进行可视化的解释的方面,Zeiler 等人[9]提出建立反向卷积神经网络,产生高分辨率和可理解的特征可视化图像;类激活映射CAM (Class Activation Mapping)[10]通过改变CNN 的网络结构并对数据集进行重新训练,获得类别定位激活图,观察CNN 的感兴趣区域;梯度类激活映射Grad-CAM (Grad Class Activation Mapping)可对训练好的分类网络模型输出计算梯度全局平均权重,减少了模型重构及训练的时间.
本文提出了将DCNN 应用于铁路图像进行特征提取实现铁路图像场景分类,所建立的网络结构级联Grad-CAM 可视化层实现模型原理可解释性.本文对比了不同的DCNN 网络在铁路场景图像下迁移学习的能力,同时提出了通过可视化方法降低数据集内部偏差提升模型分类能力的优化流程,结果显示本文提出方法可有效降低数据集偏差,提升模型分类能力.
1 研究方法
为实现在小样本量下的铁路图像场景分类任务,本文基于迁移学习思想,将在ImageNet 数据集上预训练好的网络模型进行迁移调参训练,比较了现有网络及本文改进网络在铁路图像场景分类任务下的性能;为实现CNN 分类模型可解释性,本文基于Grad-CAM 思想,在经过下采样后的最后一层特征映射图上,对梯度权重添加ReLU 层,实现图像不同区域对分类类别激活的热力图解释.全文研究流程如图1所示.

图1 铁路图像场景分类及可视化分析流程
1.1 迁移学习
为避免CNN 模型在小型场景数据集训练出现难以收敛的问题,本文将在ImageNet 数据集上预训练好的网络模型迁移至铁路场景数据集进行训练,表1展示ResNet50 和ResNet101 的模型结构,图片进入模型后裁剪成固定分辨率,经过CNN 完成特征提取工作,结合本文特定问题,提出改进后ResNet50 网络模型如下:
1)在conv1、conv2、conv3、conv4 层后分别连Dropout 层抑制过拟合,Dropout 率设定为0.2;2)全连接层修改为12 维,接softmax 层完成对各类别概率计算;3)固定前端所有层参数,仅对最后一层全连接层进行调参训练.
以ResnetV1-50 模型为例,如图2所示,图片输入尺寸为224×224 像素,在第一阶段中,图像经过卷积层1,卷积核为7×7 像素,步长为2 像素,维数为64,输出尺寸为112×112 像素,进而连接批量归一化层及非线性变换层以加快收敛,最后经过卷积核为3×3 像素,步长为2 像素的最大池化层;第二阶段,图像经过一个层数为3 的残差块,标准残差块的卷积核为1×1 或3×3 像素,输出的图像尺寸为56×56 像素;第三阶段图像经过一个层数为4 的残差块,输出尺寸为28×28 像素;第四阶段图像经过一个层数为6 的残差块,输出尺寸为14×14 像素;第五阶段图像经过一个层数为3 的残差块,输出尺寸为7×7 像素;最终经过平均池化层、12 维的全连接层及归一化指数层,求得图像分类概率.
1.2 CNN 可视化模型
(1)梯度反向传播(guided backpropagation)[11]:
对CNN 各层输入和梯度均大于0 的所对应的梯度进行反向传播,可在一定程度上展示该层提取到的全部特征,相邻步梯度定义为:

其中,Ri为迭代过程中的梯度,根据反向传播可由l+1 步的梯度求解出l步的梯度.

表1 ResNet 网络结构

图2 ResNet50 网络迁移学习流程
(2)类激活映射(Class Activation Mapping)[12]:
通过多次卷积和池化后,CNN 最后一层卷积层包含了丰富的空间和语义信息,引入全局平均池化替换全连接层,保留下丰富的语音信息,对每一个特定类别c,类激活映射可显示其类激活映射,如:

其中,MC指针对类别C的类别激活映射,fk(x,y)表最后一层卷积层上单元k的位置,指利用CA方法生成的激活值.
(3)渐变类激活映射(Grad Class Activation Mapping,Grad-CAM)[13]:
利用梯度全局平均来计算权重可在不改变原网络结构的情况下实现对类别的加权热力图及激活分数,如:

2 铁路场景分类数据集
ImageNet[14]、SUN[15]、Places[16]等大型数据集的提出推动了深度学习的发展,但这些数据集仅关注自然图像,目前没有专门用于铁路目标或场景分类的铁路图像(如包含接触网,涵洞,机车,线路等铁路专有目标)数据集.为了弥补缺乏数据集对深层学习方法的制约,本文制作了一个名为Railway12 的铁路场景图像数据集,,Railway12 包含12 种典型场景 (隧道、候车大厅、购票大厅、火车站广场、接触网、维修车间、站台、货场、车厢、铁路道口、铁路桥梁、防护网),数据集总图片量为1.2 万幅图像,每个类别包含1000张图像.图3显示了Railway12 数据集的一些图像样本.

图3 Railway12 数据集图像样例
3 实验结果分析
3.1 场景分类结果
本节对深层CNN 的场景分类能力进行了评估.选择三种典型的TF-Slim CNN 模型(ResNetV1,ResNetV2,Inception-ResNet-v2)进行训练,这些模型已经在ILSVRC-2012-CLS 图像分类数据集预先训练过,以具有良好的并行处理能力.实验在数据集按7:2:1 的比例划分为训练集、验证集、测试集.出于后续工程化考虑,实验在linux 环境下基于Tensorflow 深度学习框架搭建,计算机配置为:Inter Core i7,显卡为1080Ti,参数设置如下:学习率(learning_rate)=0.0001,训练批次尺寸(batch_size)=32,训练周期(num_epochs)=75-85.除logits 层之外,所有网络层均固定参数.我们在表1中提供了训练集的top-3 的分类精度,以及测试集的top-1 和top-3 的分类精度.
实验结果表明,将在ImageNet 预训练的CNN 模型迁移到铁路场景分类任务是可行的,模型分类精度优异,考虑到铁路行业庞大的图像数据量,模型具有实际的应用价值.实验表明,网络结构越深,提取特征模型的能力越强.模型的精度和损失历史如图4所示.

图4 模型训练准确率及损失历史
3.2 模型可视化分析
3.2.1 模型激活区域分析
利用Grad-CAM 方法将CNN 最后一层卷积层的梯度信息生成类激活图,热力图可以显示模型对不同类别感兴趣的区域,根据这种方法,我们可以对CNN 模型的训练结果进行直观解释.
本文发现丰富的前景语义不是造成分类错误的主要原因 (如图5(a)和(b),在图像包含大量的前景语义情况下,模型仍根据背景信息实现了正确的分类.
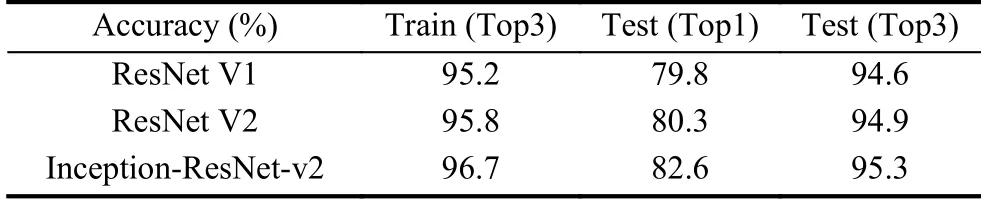
表2 不同网络结构的分类准确率

图5 CNN 对不同图像类型感兴趣的区域:(a)和(b)为具有丰富前景语义的图像,(c)和(d)为具有很大类内差异的图像,(e)和(f)具有不同场景复杂度的图像
当类别内部图片差异性较大时,模型在训练中会形成不同的关注模式,对于售票大厅类别,一部分图片由售票窗口组成 (如图5(c)),其他图片由自动售票机(如图5(d))组成.网络仍然可以进行正确判断.
当构成场景的对象较少时,场景比较直观,此时神经网络的判断策略类似于目标分类,根据图像中出现的典型目标判断其归属类别,如图5(e)所示;当图像场景更加复杂时,构成场景的对象是随机而大量的,它将场景理解为前景和背景语义的组合,作为如图5(f)所示,座椅、行李、窗户和乘客区域均对分类有贡献.
一般情况下,我们只能从CNN 模型输出中获知top-n 预测类别和概率值.但如图6所示,利用Grad-CAM 方法可以对同一张图片的不同预测结果展示模型感兴趣的区域.尽管模型对这张图片做出了错误的判断,但仍可以帮助我们分析模型做出错误分类的依据,为看似不合理的分类结果提供合理的解释.

图6 模型对同一输入图片的top5 预测结果及Grad-CAM 可视化展示
3.2.2 模型激活特征分析
在Grad-CAM 方法的基础上,结合梯度信息可以揭示在CNN 的决策过程中激活了哪些特征,对CNN 的运行机制做出深入的解释.
如图7(a)所示,网络在top1 预测中进行正确预测,网络提取建筑尖顶作为显著特征,而在top3 中的其他预测中,模型提取的特征为窗户和行人,这些特征导致了错误的预测;但在图7(b)中,模型在top1 预测中做出了错误的预测,但当模型做出让人疑惑的决策时,Grad-CAM 和Guided Grad-CAM 可以解释模型受到了怎样的干扰.
3.3 降低数据集偏差优化模型分类性能
本部分我们分别计算测试集中12 类别图片的错误率,结果见表3.选定ResNet V1 模型作为基准,分析数据集对于模型分类准确率的影响模式.我们发现维修车间,车厢,桥梁场景为分类准确率最高的三个场景,而隧道,候车大厅,车站为分类准确率最低的三个场景.
分类准确率较高的类别均体现类别内场景单一,可识别目标较明显的特点;分类准确率较低的类别体现出类内场景丰富的特点,例如不同国家的火车站广场建筑风格差异巨大,同时由于可能出现类别间相似性较大的问题,导致某些类别的分类准确率较低.

图7 结合多种可视化方法展示对于预测对应激活特征

表3 测试集不同类别图片的准确率
数据集偏差会对分类准确率造成严重的影响,当数据集出现各类别图片数据量相差较大时,网络模型对各类图片的分类准确率会出现明显波动,可以考虑使用数据增强技术进行弥补;应注意训练集中同一场景类别内各种类型图片的比例,如果某种类型数量占比过大,其他类型占比过小,在这样有偏差的数据集训练得到的模型其泛化能力较弱,容易产生有偏差和定势的模型.
4 结束语
在本文中,我们建立了铁路专用场景分析数据集Railway12,基于迁移学习的思想,将主流深度网络模型迁移到场景分类任务中,获得能够胜任于铁路场景分类任务的高准确率模型.利用Grad-CAM 等可视化方法,直观的解释网络的工作原理,从网络感兴趣区域和分类激活特征两个层面分析模型在场景分类任务中的典型判断模式.最终,利用可视化方法分析数据集存在的偏差,通过改进数据集提高模型的场景分类准确率.未来我们计划对数据集建立准确的类别字典,规范数据集类别内各子类图片比例,完善数据集结构,提高数据集统计学分布意义,同时利用可视化手段指导网络模型的修改,提出更加适用于铁路场景分类的网络模型.
猜你喜欢
北京测绘(2022年6期)2022-08-01
师道·教研(2022年1期)2022-03-12
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
少儿画王(3-6岁)(2020年4期)2020-09-13
冰雪运动(2019年3期)2019-08-23
智富时代(2019年7期)2019-08-16
智富时代(2019年7期)2019-08-16
