
面向输变电工程数据存储管理的分布式数据存储架构*
2019-07-19 10:23韩文军余春生
沈阳工业大学学报 2019年4期
韩文军, 余春生
(1. 国网经济技术研究院有限公司 工程数据中心, 北京 102209; 2. 德信东源智能科技(北京)有限公司 科技研发中心, 北京 100088)
随着计算机与大数据技术的快速发展,数据管理系统已逐步向电子化存储、集中管理、大数据整合及全方位应用方向转变[1].但由于技术水平的参差不齐,管理模式存在较大差异,我国输变电工程数据管理系统仍停留在初步的电子化档案存储及基本信息查询阶段[2],缺乏专业技术支撑输变电工程数据管理,并累积了大量有待挖掘其深层次价值的数据[3].
为了有效描述和管理各种数据,国内外研究者和机构提出了诸多数据存储技术,如使用RDBMS数据库管理系统存储关系型数据[4];使用Key-Value数据库、Redis、Tokyo Cabinet和Tokoy Tyrant等NoSQL数据库存储非关系型数据[5];使用MongoDB和CouchDB数据库存储具有海量存储需求和访问需求的文档数据[6];Cassandra与Voldemor数据库存储具有高可扩展性及可用性的特点[7].然而这些方法并不适用于多源、异构的输变电工程数据,且需要浪费大量的存储空间,降低了计算分析效率.
输变电工程数据包括文档资料、三维设计模型及工程地理信息数据3类[8-10],根据对现有输变电工程数据的调研,每个工程项目移交数据的数据量及其形态表述如下:
1) 文档资料数据包括初步设计阶段、施工图设计阶段和竣工阶段的变电站与架空线路数据,约占30~50 Gbit,以非结构化的PDF和图片文件为主,基本没有结构化数据;
2) 三维设计模型数据包括工程模型(CBM)、物理模型(DEV)、组合模型(PHM)和几何模型单元(MOD)4大类,约占0.5~5 Gbit,其中,10%~30%为结构化数据,70%~90%为GIM格式的三维模型文件;
3) 工程地理信息数据包括影像数据、数字高程模型数据、基础矢量数据、电网专题数据、电网空间数据和输电线路通道数据等,约占0~10 Gbit,其数据格式以非结构化的图片文件为主,包括img、tif、grd、asc和shape等.
按照此数据量,平均每个工程项目包含结构化数据500 Mbit,非结构化数据50 Gbit,而我国各省拥有存量的输变电工程项目约为1 000~10 000个,每年新增项目为几十到几百个[11-12].包含存量项目在内的所有输变电工程项目总数约在5万个以上,工程数据总量有可能超过50 Tbit结构化数据和2.5 Pbit非结构化数据.然而,传统的单主机、单数据库的简单存储模式无法满足海量数据存储的需求[13],必须采用阵列式或分布式的数据存储模式来提升整个存储体系的容量和性能.
基于上述分析,本文针对输变电工程数据的多源、异构、迭代更新和集成应用等特性,提出了一种分布式数据存储架构来存储各种输变电数据.首先基于元模型设计了输变电工程数据的数据模型,然后提出了一种面向输变电工程数据存储管理的分布式数据存储模式,并设计了一种数据完整性分析方法以保证完整、准确地存储各种数据,最后,基于Hadoop分布式存储平台对提出方法进行了仿真实现与分析.
1 输变电工程数据模型
输变电工程数据具有“多源、异构”特点,即每个工程物理实体在时空中均是唯一存在的,从不同角度出发可以得到不同的数字化描述.本文在元数据模型框架基础上,按照输变电工程的数据种类和特性,对相关对象类型作进一步细化后得到适用于输变电工程组织与管理的数据模型.按照如图1所示的元数据模型,从以下5个方面对输变电工程数据模型进行细化:1)物理对象分类细化;2)工程结构化描述,即数据的上、下文信息;3)数据结构化描述,即对数据对象、数据属性和数据值集合的统计分析;4)元数据结构,即用数据来源、数据对象、数据属性和数据值表示数据信息;5)文件结构化,即数据的来源和数据包的结构化信息.
1.1 物理对象分类细化
物理对象代表在工程中所形成的、具有一定物理特性的相关对象.本文根据输变电工程的特点,将物理对象细分为以下3种对象:

图1 电力工程数据细化流程Fig.1 Refining process of power engineering data
1) Project工程对象,代表某个输变电工程的整体,对应GIM模型中的project.cbm信息,根据工程类型的不同,可进一步细分为Substation-Project变电工程和TransmissionProject输电工程;
2) FunctionalObject功能对象,代表输变电工程的某个组成部分,体现该组成部分的功能特性,对应GIM模型中的*.cbm信息;
3) Device设备对象,代表某个能实现一定功能特性的物理实体,广义上包含组合设备、子设备、设备部件等衍生对象,对应GIM模型中的.dev信息.
1.2 工程结构化描述
通过FunctionalObject功能对象,对每个Project工程项目建立了一套层次结构.对功能层次结构中的每一个设备节点设置一个Device设备对象,并根据对设备技术参数的设定,将设备对应到具体的物料项上.同时随着采购和施工的进行,将设备对应到具体的产品项上.
1.3 数据结构化描述
每一个PhysicalObject物理对象可以具有多组设计数据,即对应多个DesignData设计数据对象.每个数据对象可以具有一组PropertyValues结构化数据和一组KeyValues半结构化数据,其中,PropertyValues可通过ValueObject值对象来管理复杂值.每个数据对象根据其数据来源可归属于某一个数据包,在数据包上进行版本控制与来源跟踪.
1.4 元数据结构
将元数据细化为ObjectType、ObjectProperty、ValueType和PackageType这4种类型.ObjectType定义了物理对象和数据对象的类型,重点是根据物理对象的设备分类,结合数据种类划分来对数据对象进行细分;ObjectProperty定义了每种数据对象的属性集合,对应PropertyValues属性值集合;ValueType对复杂值进行分类和定义,对应ValueObject值对象;PackageType定义了DataPackage数据包的分类.
1.5 文件结构化
通过Folder文件夹来构建一个用于存储文件的层次结构,每个File文件均位于特定的Folder文件夹节点中.每个File文件根据其数据来源可归属于某一个数据包,在数据包上进行版本控制及来源跟踪.
2 分布式数据存储架构
对于输变电工程数据而言,每个工程项目均具有较强的整体性.在同一个工程项目内部,不同数据之间存在紧密的关联,不同环节的工作开展也通常依赖于其他环节所产生的数据.而在不同的工程项目之间,该种关联性相对较弱,对于工作的影响一般是在参考、借鉴、引用等方面.本文根据工程项目数据的整体性和海量数据分散存储的需要,提出了如图2所示的面向输变电工程数据存储管理的分布式数据存储架构.
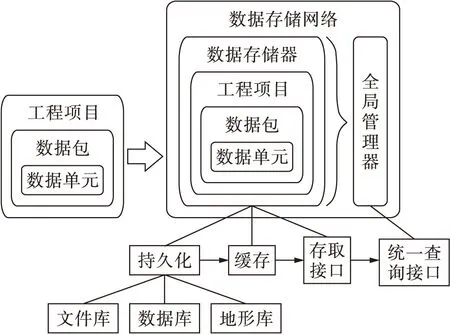
图2 输变电工程数据分布式存储架构
Fig.2 Distributed storage architecture for power transmission and transformation engineering data
在该数据存储管理架构中,输变电工程数据被抽象为数据单元、数据包和工程项目3个层级.数据单元是数据管理中的最小单位,每个数据单元代表一个数据对象及其附属的数据属性集、值对象以及键值对集;数据包用于承载数据管理信息,每个数据包一般由一组或多组数据对象按照一定规则进行排列或组合而成,对数据的存储与管理活动一般会被对应到数据包对象上;工程项目是数据存储管理中的基本单位,对每个工程项目的所有数据进行集中存储.
整个数据存储体系采用分布式存储、集中式管理的实现方式,包含一组全局管理器和多个并列的数据存储器.每个数据存储器可以管理多个工程项目、数据包和数据单元,将其持久化到数据库或数据文件中,并建立数据缓存以改善数据存取性能.全局管理器集中管理所有的元数据、主数据以及工程数据的索引信息.同时使用分布式存储平台可以便于数据的统一加密和处理,本文使用HDF5编码对存储的数据进行加密处理.
从便于数据管理和使用的角度进行考虑,结合数据量估算与典型硬件性能等因素,本文按网省和年份来组织输变电工程数据存储体系,并设计了如图3所示的数据管理架构.该管理架构以工程项目的归属网省和启动日期为依据,将某个网省在某一年所有工程项目的数据集中存储在一个数据存储器中,并统一注册到全局管理器中.在应用数据时,用户或第三方应用可通过全局管理器提供的统一查询接口进行全局的数据检索,或者连接特定的数据存储器进行本地数据的检索及存取.
基于上述数据存储和管理架构分别设计了不同类型数据的存储模式:
1) 工程地理信息数据.本文将与输变电工程相关的地理区域作为物理对象,将该区域的各种地理信息作为数据对象,按时间、精度、级别、坐标系等方面进行组织,并将所包含的DEM、DOM文件通过文件库进行集中管理,再通过GIS系统进行使用.工程地理信息数据存储模式如图4所示.

图3 数据管理架构Fig.3 Data management architecture

图4 工程地理信息数据存储模式Fig.4 Data storage mode for engineering geographic information
2) 三维设计模型.本文将与输变电工程相关的系统或设备等功能设施作为物理对象,将该系统或设备的各种属性集、几何建模、层次结构、连接关系等作为数据对象,将所包含的工程模型、物理模型、组合模型、几何模型单位等文件通过文件库进行集中管理,并建立起物理对象与文件对象的对应关系.在数字化移交管理中,将获取到的每个GIM模型文件作为一个数据包,而将其中的每个数据对象及其对应的文件作为一个数据单元,三维设计模型的数据存储模式如图5所示.

图5 三维设计模型数据存储模式Fig.5 Data storage mode for 3D design model
3) 文档资料数据.本文将与输变电工程相关的所有文档资料作为文件对象,按文件内容、文件类型、文件夹等方面进行组织,并分别关联到对应的系统/设备等功能对象上.将数字化管理中获取到的每一套文件作为一个数据包,而其中的每个文件对象及其相关的关联关系作为一个数据单元,数据存储模式如图6所示.
3 实验与结果分析
为了验证本文所提分布式存储架构的有效性,使用2017年某地的输变电工程数据进行仿真测试.基于Hadoop平台搭建和部署了输变电数据存储系统,该系统使用9台普通PC机作为分布式存储节点,各节点硬件配置为4 Gbit内存、Core i5 CPU@2.60 GHz,100 Mbit/s网络带宽,并为各节点安装Ubuntu16.04系统和Java JDK,系统平台示意图如图7所示.

图6 文档资料数据存储模式Fig.6 Data storage mode for documents

图7 测试系统平台示意图Fig.7 Schematic diagram of testing platform system
本文对比了不同大小数据时使用单机单数据库架构存储方式和使用Hadoop分布式存储架构两种情况下的效率,以验证所提存储架构的存储效率,对比结果如图8所示.

图8 不同大小文件的存储效率比较Fig.8 Comparison of file storage efficiency with different sizes
从图8中可以看出,随着数据块的增大,本文架构产生标识的时间基本不变;而传统存储方法所需的时间随着文件大小的变化呈线性增加.由此表明,本文存储架构更适合存储海量输变电工程数据.
此外,文中比较了不同大小的输变电数据,验证其完整性的时间开销,即系统解析不同类型的数据时,检测算法所需的时间开销.图9为设置数据块大小为2、4、8、16、32、64、128 kbit时,数据完整性检测所需的时间与通信开销.从图9中可以看出,对本存储架构所存储的数据进行完整性检测时,所需要的时间基本不随数据块大小的变化而变化.
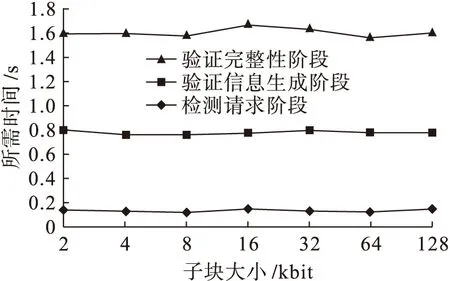
图9 完整性检测所需时间开销Fig.9 Time overhead required for integrity detection
本文存储架构在保证存储效率和数据完整性的同时,也需要保证数据的安全.图10、11分别为本存储架构存储的原始数据与使用Storm平台加密后的数据.从图11中可以看出,本系统将数据以加密的形式进行分布式存储.

图10 原始数据Fig.10 Raw data

图11 加密后的数据Fig.11 Encrypted data
4 结 论
本文在充分考虑输变电工程数据的多源、异构、迭代更新及集成应用等特性的基础上,提出了一种分布式数据存储模式,实现输变电工程数据的分散存储、全面关联与统一管理.文中先基于元数据模型框架对输变电工程数据进行了细化,然后使用面向输变电工程数据存储管理的分布式数据存储架构分别对工程地理信息数据、三维设计模型和文档资料数据进行存储设计.系统实现与仿真实验结果表明,所提出的分布式存储架构在保证存储效率和数据完整性的同时,也能保证数据的安全.
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
河北理科教学研究(2021年4期)2021-04-19
军民两用技术与产品(2021年2期)2021-04-13
民用飞机设计与研究(2020年4期)2021-01-21
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
物联网技术(2018年8期)2018-12-06
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
雷达与对抗(2015年3期)2015-12-09
