
基于WaveNet的源终端识别研究
2019-07-19 01:24:16刁则鸣周神保罗海涛
网络安全与数据管理 2019年7期
刁则鸣,周神保,罗海涛
(1.国家计算机网络应急技术处理协调中心广东分中心,广东 广州 510000;2.长安通信科技有限公司,广东 广州 510000)
0 引言
基于音频特征对录音设备的识别从2007年开始成为学术研究热点[1]。2017年,中华人民共和国民事诉讼法[2]把视听材料作为法庭认可的八大证据之一,此后,国内也掀起了对音频取证研究的热潮。音频取证主要研究目的在于通过音频信息推断音频信号是在何时(录音时间)何地(录音环境)由什么设备录制的[3],通常是对原始录制音频进行分析。AGGARWAL R等人认为,假设把录音设备看作一个对音频的滤波器,则寻找表征录音设备的特征参量就是从音频信号中提取录音设备的传递函数[4]。因此,音频取证中对录音设备的识别首先需要提取非话音段,从非话音段中对设备本底噪声进行估计[5-7]。
与音频取证的录音设备识别有所不同,经电话网传输后的源终端的识别不能完全考虑非话音段,因为非话音段在网络传输中受编解码的影响很大,往往会丢失很多设备特征参量。近些年网络传输后的音频溯源研究也引起了学术界的重视,王一平等人在提取音频特征的基础上,基于随机森林筛选出贡献度高的特征作为来源特征[8];Pindr0p公司则研究了传输音频数据的相关特征并提出可以利用这些特征构造呼叫声纹(call fingerprint),再利用这些声纹识别来源地点、来源网络、呼叫路径等[9],但Pindr0p研究成果未完整公开。
上述研究都没有就来源终端的识别提出解决方法,本文将在阐明来源终端识别的可行性的基础上,提出一种用神经网络对来源终端的特征进行建模的方法,为判断来话意图研究提供一些参考思路。
1 源设备音频特征
为了在网络传输过程中既保证音频的保真度,又提高带宽利用率,网络设备在传输音频时会通过端点检测(Voice Activity Detection,VAD)技术找到话音段,并只对话音段进行压缩编码,静音段则不受保护。因此,在提取源设备本底噪声特征时,比较合理的方法是从非静音段中提取。Mel频率是一种基于人耳听觉特性提取的频率特性,与Hz频率成非线性对应关系,梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)则是描述这种对应关系的系数,可以用来计算得到Hz频率。可见,MFCC适合用于描述传输音频的非静音段部分特性。
标准的倒谱参数MFCC只反映了语音参数的静态特性,当需要考虑不同说话人、不同音频内容等区别时,往往还可以综合考虑这些标准MFCC的差分谱。本文设计了几组音频聚类实验,来验证利用MFCC描述音频来源终端特征的可行性,总体实验思路如图1所示。首先利用测试手机拨打一定量的电话,通过同款手机接收并录制下电话音频,然后对每个音频的非静音段提取13维的MFCC(每帧提取一组),考虑到每个音频长度不一,再对每个音频计算统计MFCC特征,最后在聚类前对这些统计特征做降维处理。

图1 实验流程图
为了确保实验结果有明确指向性,实验中的音频内容、呼叫网络、被叫设备须保持一致,相同来源设备用同种标记符表示,如:(x、v、_),可输出如图2所示的聚类结果。
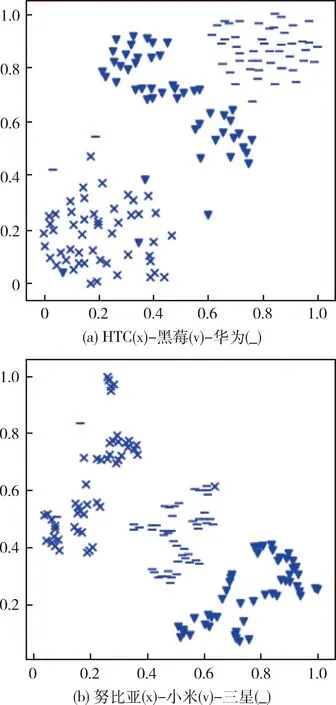
图2 聚类结果
从实验结果来看,不同来源设备的音频用MFCC描述后区分度较高,实验中不同来源设备的音频聚类效果较好。同时,通过聚类结果还可以看到,不同来源设备的音频也存在串类的情况,也就是说用MFCC描述来源设备还是存在一定的误差。下文将通过实验来验证用MFCC构建识别模型的准确率。
2 模型构造
WaveNet[10]是DeepMind提出的一种生成网络,其主要思想是认为语音是由一个个采样点组成的,每个采样都受到历史采样的约束,因此每个语音片段的联合概率可以用下式表示:
(1)
即一个长度为T的音频可以用每个历史语音采样点(x1,…,xt-1)预测的采样点(xt)的联合概率表示。这种音频的理解方式反映了WaveNet对时序信号前后因果关系的重视,也是其模型设计的核心思想所在。
在模型结构方面,WaveNet使用了多层因果空洞卷积(Causal Dilated Convolution),通过扩大输出感受野(Receptive Field),来表达音频时序特征。为了避免模型深度增加导致梯度消失(Vanishing Gradient),WaveNet使用了残差网络结构(Residual Network),跳跃某些时序特征的约束,提高训练深度。因此,WaveNet的模型深度得到了保证,对音频的特征学习很充分。为了使WaveNet可以用于执行来源终端类型识别任务,需要在该模型中引入一定规模的dropout以优化训练效果,并将模型输出进行池化(Pooling)操作以实现降维调整,模型总体结构如图3所示。
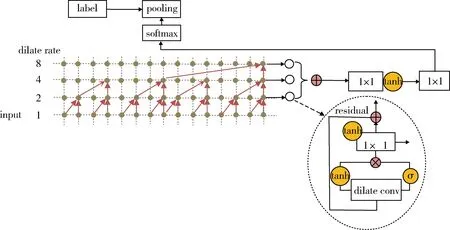
图3 模型图
3 实验验证
3.1 数据采集
本实验收集了8款手机的呼叫录音,分别为HTC、诺基亚、华为、三星、苹果、努比亚、黑莓、小米。每个手机平均呼叫400次左右,通过同一个手机接听并采集录音,共采集录音3 600余个,每个通话时长60 s左右。
3.2 数据预处理
实验中,对音频的非静音段按帧提取13维MFCC,这样每帧音频将由一组13维的数据表示。为了避免奇异样本对样本全体的不良影响,本文在模型训练之前对所有音频帧的MFCC按下式进行归一化处理:
(2)
其中,xmean和xstd分别为所有音频帧MFCC的均值和标准差,所有音频帧通过归一化处理可以得到新的x′。
3.3 模型训练及验证
本文选取90%数据作为训练集,9%数据作为验证集,再预留1%数据作为模型通用性的测试集。设定模型epoch为20,在每个epoch中监听验证集的损失(val_loss),当该指标波动变缓时调低学习率(learning rate),并在每个epoch后输出一个模型,实时输出训练结果,完整训练过程记录如图4及图5所示。
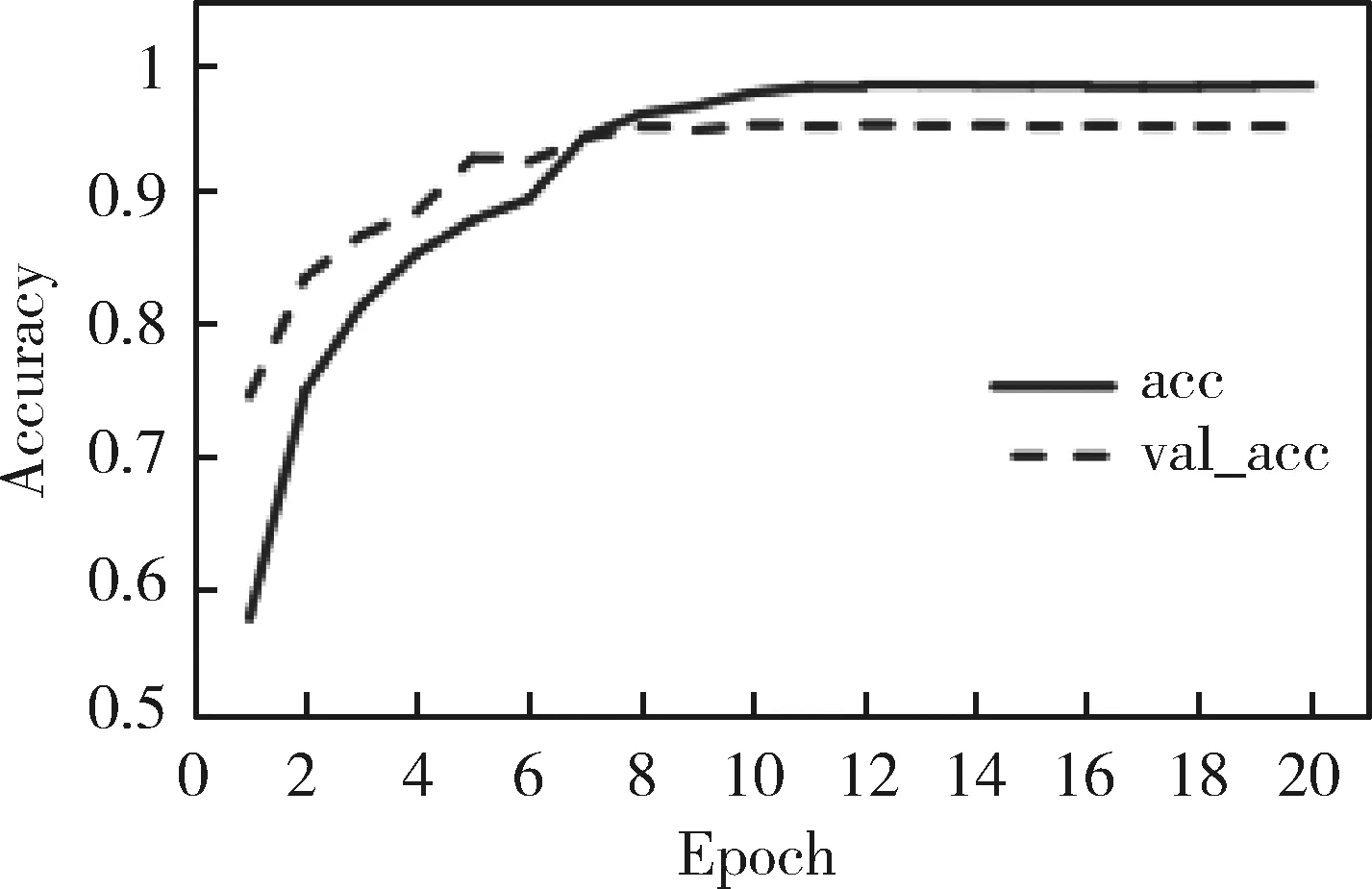
图4 模型分类准确率

图5 模型分类误差
从训练指标的走势可以看出模型的训练效果较好,训练准确率(acc)达到98.5%,验证准确率(val_acc)达到92.8%左右,损失在训练过程中总体呈下降趋势,模型表现稳定。为了测试模型的通用性,本文用测试集对输出的模型进行测试,测试结果如表1所示。
表1测试结果显示,模型平均准确率为89.6%,与模型验证准确率接近。注意到HTC、诺基亚和苹果有不同程度的错分类情况,本文认为有两方面的原因,一是训练样本集有限,模型训练还不够充分;二是以非静音段的音频MFCC作为输入还不足以完整刻画音频的来源特征。
4 结论
本文提出了一种基于神经网络的来源电话类型识别方法,由于经过网络传输的来源特征在静音段难以提取,本文提出聚焦于非静音段音频分析,从音频聚类效果来看,用MFCC作为模型输入是具有一定可行性的。分类实验结果表明,本文所提出的方法对来源电话终端类型具有较好的识别效果。
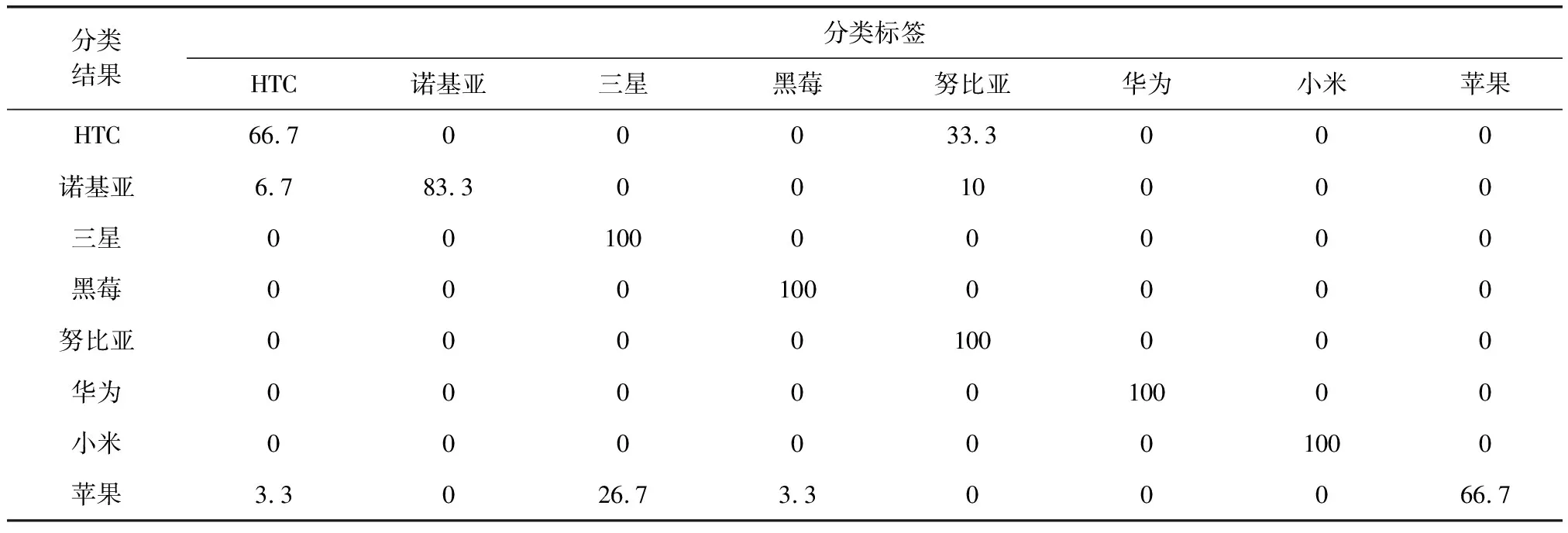
表1 通用性测试结果 (%)
然而,本文的方法是对来源电话终端识别的初步探索,还有很多局限性,如样本音频不足可能导致模型过拟合,音频在不同接收终端录制可能导致模型通用性不够,用MFCC作为模型单一输入可能降低识别准确性。本文后续将继续深入研究,期待形成行之有效的识别方法。
猜你喜欢
文萃报·周五版(2024年11期)2024-04-09 17:59:20
学苑创造·A版(2022年5期)2022-05-19 05:42:43
橡胶科技(2022年11期)2022-03-01 22:55:23
石油沥青(2021年3期)2021-08-05 07:41:08
阅读(快乐英语中年级)(2021年10期)2021-03-08 14:23:24
阅读(快乐英语中年级)(2020年10期)2020-12-09 05:42:47
汉字汉语研究(2019年2期)2019-08-27 00:47:56
流行色(2018年11期)2018-03-23 02:21:22
阅读(快乐英语中年级)(2017年5期)2017-05-30 10:48:04
阅读(快乐英语中年级)(2017年3期)2017-05-30 10:48:04
