
深度学习常用优化算法研究
2019-07-19 01:30:48贾桐
网络安全与数据管理 2019年7期
贾 桐
(华北计算机系统工程研究所,北京 100083)
0 引言
随着人工智能技术的盛行,深度学习越来越受到学术界和工业界的关注,而优化算法的选择和使用则直接决定了一个深度学习任务的成败[1]。本文将依次介绍深度学习领域常用的梯度下降和其启发式变种优化算法,从理论角度剖析每种算法的设计思想和原理,分析算法的优缺点,并在实际数据集上对比不同优化算法的性能,最后对深度学习任务中优化算法的使用技巧和注意事项进行总结。
1 深度学习建模
1.1 优化建模
深度学习[2](deep learning)本质为一个无约束优化问题,可以将其建模为一个最小化期望风险(expected risk)的问题,形式化表示如下:
minJ(θ)εD~p(x,y)L(f(x;θ)
(1)
其中,x和y分别为样本的特征向量和监督值;f为模型的推理函数,θ为该推理函数的参数,形式固定;L为损失函数,一般情况下回归问题的损失函数定义为平方误差(mean squared error),分类问题的损失函数定义为交叉熵(cross entropy)。
通常情况下假设所有样本满足独立同分布的条件,因此目标函数可以定义为所有训练样本上的经验风险[3](empirical risk):
minJ(θ)=εD~p(x,y)L(f(x;θ),y)
(2)
因此求解一个深度学习模型的最优解,可等价地转换为求解式(2)表示的一个无约束优化问题。
1.2 优化策略
一般而言,考虑到深度学习庞大的参数量和高度非凸性,通常采用迭代式、基于梯度信息的优化求解策略。选择迭代式的算法,使得可以持续优化目标函数,逐步逼近并收敛于最优解所在位置。而采取梯度信息而不计算Hessian矩阵,从理论角度,算法迭代的每一步都使用采样数据进行优化,因此具有很强的随机性,所以此时采用更精确的方式计算优化方向并无太大意义;从工程角度,由于深度学习模型本身巨大的参数量,计算Hessian矩阵会带来非常巨大的时间和空间开销,甚至实际设备资源和任务实效要求根本无法满足支持计算Hessian[4]。
因此一般而言,只计算目标函数关于训练参数的梯度,并且在具体每一步优化迭代中,会随机从所有训练样本中抽样部分样本用于当前梯度计算,即选择批数据量。
1.3 批数据量选择
以最基本的梯度下降(gradient descent)优化算法为例,根据批数据量大小选择的不同,优化算法可分为批梯度下降算法(batch gradient descent)、随机梯度下降算法(stochastic gradient descent)和迷你批梯度下降算法(mini-batch gradient descent)。批梯度下降算法在每一步迭代过程中使用全部训练样本,因此参数更新方向最稳定,但是时间开销和空间开销最大;与之恰恰相反,随机梯度下降算法在每一步迭代过程中只使用随机抽样的一个样本,因此时间和空间开销都是最小的,但是由于样本的随机性,参数的更新方向是最不稳定的;迷你批梯度下降算法则是二者的折中,算法每一次迭代随机从n个样本中采样m个样本,因此该方式中和了批梯度下降和随机梯度下降的优势和劣势,使得在空间开销和时间开销合理的情况下,获得相对较为稳定的参数更新方向。注意其中迷你批量m的大小为优化算法的超参数,一般而言当样本分布的随机性强时,m可设置为相对较大的值以平稳化随机性[5]。
在实际优化问题中一般均采用迷你批梯度下降算法及其变种。
2 基于梯度计算的优化算法
2.1 随机梯度下降
随机梯度下降[6](Stochastic Gradient Descent,SGD)是最基本的基于梯度的优化算法,并且是其他一阶优化算法的基础。在每一步迭代中,选择最优优化方向的最直观方式为:沿最陡峭的方向,即最速下降的方向进行迭代更新,因此随机梯度下降算法又被称为最速下降(steepest descent)算法,而这个方向就是梯度(最速上升方向)的反方向。因此算法每一步迭代的更新公式如下:
(3)
θ←θ-η⊙g
(4)
其中,η表示当前迭代步的学习率(learning rate)。
2.2 动量法
随机梯度下降算法在每一步优化方向更新时只使用了当前步随机采样样本的信息,因此具有相对较强的随机性,从而使得优化方向一直“震荡”,同时由于震荡的原因,收敛速度相对较慢,因此引入了动量优化算法[7](Momentum)。该算法在每一步迭代过程中,保留上一轮更新后的参数动量,并加入该轮的梯度,从而降低算法在收敛过程中的震荡程度,同时提高收敛速度。迭代更新公式如下:
(5)
v←α·v-η·g
(6)
其中,α为动量累积系数,一般设置为0.9,动量算法相当于累积过去最近1/(1-α)步更新方向。
2.3 Nesterov动量法
Nesterov[8]动量算法是2.2节所述动量算法的更新,该算法与Momentum唯一的不同在于,Nesterov算法会先根据当前位置预判前方地形,从而移动到一个新的预估位置,然后在该位置计算梯度,最后将所得梯度与历史累积动量加权后的方向作为真正更新方向。因此算法迭代更新公式如下:
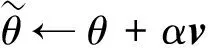
(7)
(8)
v←α·v-η·g
(9)
θ←θ+v
(10)
对于式(7)、式(8)可以理解为优化过程中顺应大势所趋,在主流的方向上先行迈出一步,因此在一定程度上会加速收敛速度。
2.4 AdaGrad
上述动量法和Nesterov动量法虽然相较于SGD优化了更新方向,但是对于学习率却没有起到调节作用,因此在实际深度学习的优化过程中,存在以下问题:(1)在每一步迭代更新中,学习率的大小需要人为设置。学习率太小导致收敛速度太慢,学习率太大又会导致在损失函数最小值点附近波动甚至发散,因此找到一个合适的学习率十分困难。(2)若想要调节学习率,就得人为设置学习率衰减策略,然而在训练过程中,人为设置衰减策略的学习率不能够自动匹配数据的特征。(3)所有参数维度的更新都使用相同的学习率。如果数据非常稀疏,并且特征的频率大为不同,那么不应该对所有的特征使用相同的学习率,而应对出现频率低的特征使用相对较大的学习率以保障学习充分,对出现频率高的特征使用相对较小的学习率以防止过度学习。(4)很难避免鞍点(saddle point)。因此解决办法是使用自适应学习率的优化算法(adaptive learning rate optimization algorithm)。
AdaGrad[9]就是最基本的自适应学习率优化算法,其更新方式如下:
(11)
r←r+g⊙g
(12)
(13)
θ←θ+Δθ
(14)
该算法利用变量r累积二阶动量,从而使得更新频繁的维度拥有较大的累积动量平方值,因此实际更新的学习率较小,从而避免了过度更新;而总是得不到更新的维度对应有较小的累积动量平方值,因此实际更新时会执行较大的学习率,从而保障了充分更新。
该算法虽然实现了不同维度上学习率自适应地调节,但是存在一个严重的问题:训练后期更新速度停滞不前甚至终止更新。因为随着动量平方的不断累积,每一个维度r的对应值都不断增大,导致每一个维度的学习率逐渐变小,从而当训练到后期阶段时,由于学习率过小使得训练停滞甚至提前终止。因此为了解决这个问题,之后又出现了更为智能的优化算法,使得在任意特定维度上,随着训练阶段的变换,学习率也可以进行增大缩小的自适应调节。
2.5 RMSProp
RMSProp[10]优化算法是对AdaGrad算法最直接的改进,参考于动量方法在累积动量上采用滑动平均,RMSProp在累积动量平方上采取滑动平均,从而避免了累积动量平方越来越大的问题,因此该算法只是将式(12)替换为了如下形式:
r←ρr+(1-ρ)g⊙g
(15)
于是该变量相当于累积过去最近1/(1-p)个迭代的动量,如果某一维度上变量相较于过去一直没有得到有效充分的更新,那么其对应的累积动量平方值将会变小,因此学习率将会变大,这就是RMSProp算法可以使同一维度在不同时间段进行学习率自适应调节的原因。
2.6 Adam
Adam[11]算法为集大成于一身的优化方式,其对于优化方向的选择采取了Momentum动量法的方式,对于学习率的选择采取了RMSProp的方式。在此基础上,该算法还对一阶动量累积和二阶动量累积进行了校正,近似为对期望的无偏估计。算法的迭代更新公式如下:
(16)
t←t+1
(17)
s←ρ1s+(1-ρ1)g
(18)
r←ρ2r+(1-ρ2)g⊙g
(19)
(20)
(21)
(22)
θ←θ+Δθ
(23)
3 算法应用选择策略
实际应用算法时有以下选择策略:
(1)算法孰优孰劣尚无定论。一般而言入门建议选择Nesterov优化算法或Adam优化算法。
(2)选择自身熟练的优化算法。这样在优化过程中可以更熟练地利用经验进行超参数调优,大大减少模型优化过程带来的意外性和不确定性。
(3)在训练前期选择较大批数据量,在训练后期选择较小批数据量。批数据量较大时,数据方差理论上较小,因此计算所得梯度更加稳定,从而使得在前期的训练优化中少走弯路,以较为平稳的方式到达最优点附近;在训练后期选择相对较小的批数据量可以充分利用数据的不稳定性,增强随机震荡的程度,从而更有可能跳出鞍点。
(4)在选择优化算法前需要先充分了解数据,如果数据维度之间的分布均匀,那么推荐使用譬如SGD的非自适应的算法;而当数据非常稀疏时,则需优先考虑譬如Adam等自适应优化算法。
(5)需要根据阶段需求选择优化算法。在模型设计实验阶段,因为需要快速验证新模型的效果,所以可先使用Adam算法进行快速实验;而在模型上线或待发布阶段,因为需要追求极致的效果,所以可用精调的SGD优化算法或动量算法进行模型的极致优化。
(6)先用小数据集进行实验。因为一般而言数据都是从原始特征空间中抽样而得到的,因此优化算法的收敛速度与数据集的大小关系不大[12]。因此可以先利用一个具有代表性的小数据集进行实验,测试得到最好的优化算法,并通过参数搜索寻找最优的优化超参数。
(7)考虑不同算法的组合。实际优化的时候,可以先采取Adam优化算法进行快速逼近收敛,而后在某个特定条件下切换至SGD算法进行精确搜索。
(8)训练数据集一定要充分打散。这样在使用自适应算法时,可以避免因为学习过度或不足,导致优化方向出现偏差的问题。
(9)训练过程中需要持续监控训练集和验证集。具体是监控目标函数值以及一系列评价指标。其中监控训练集是为了保障模型进行充分、正确的训练,即优化方向正确,学习率适宜充足;而监控验证集是为了避免模型训练过拟合,当出现训练集上得分很好而验证集上评价准则得分过低时,需要及时终止训练过程,重新评估数据、模型、目标函数和优化算法,制定新的学习策略。
(10)为训练过程制定合适的学习率衰减策略。因为需要保证训练前期的学习率足够大,快速收敛,而后期学习率相对较小,从而避免不收敛甚至发散的问题。具体的制定策略有很多,譬如每遍历N遍数据集就衰减一次。一般采取余弦周期学习率衰减策略,有助于跳出鞍点。
4 实验与结果分析
4.1 数据集介绍
实验中使用MNIST[13]数据集,该数据集为全球最权威的手写体识别数据集,由美国邮政系统开发,手写内容为0~9阿拉伯数字,内容采集于美国人口统计局的员工和高中生。
4.2 实验设置
实验选取其中的37 000张图片作为训练集,5 000 张图片作为测试集,模型选择经典的LeNet[14],所有优化算法的初始学习率均设置为0.001 5。
训练阶段,数据在进入训练前均已充分打散,同时在所有优化算法的训练中批次读入顺序相同。每种优化算法对应的模型使用相同的初始化方式和种子,每300步迭代记录一次训练集上的损失函数值,所有模型总训练迭代次数均为6 000步。
测试阶段,选择针对所有类别的准确率作为评价指标,利用每种优化算法对应的训练好的模型,分别在相同测试集上进行测试,得到对应的准确率评分。
4.3 实验结果
4.3.1 训练集上交叉熵损失结果
六种优化算法在训练集上的交叉熵损失记录如图1所示,可见Adam优化算法和RMSProp优化算法拥有最快的收敛速度;SGD算法的收敛速度最慢。
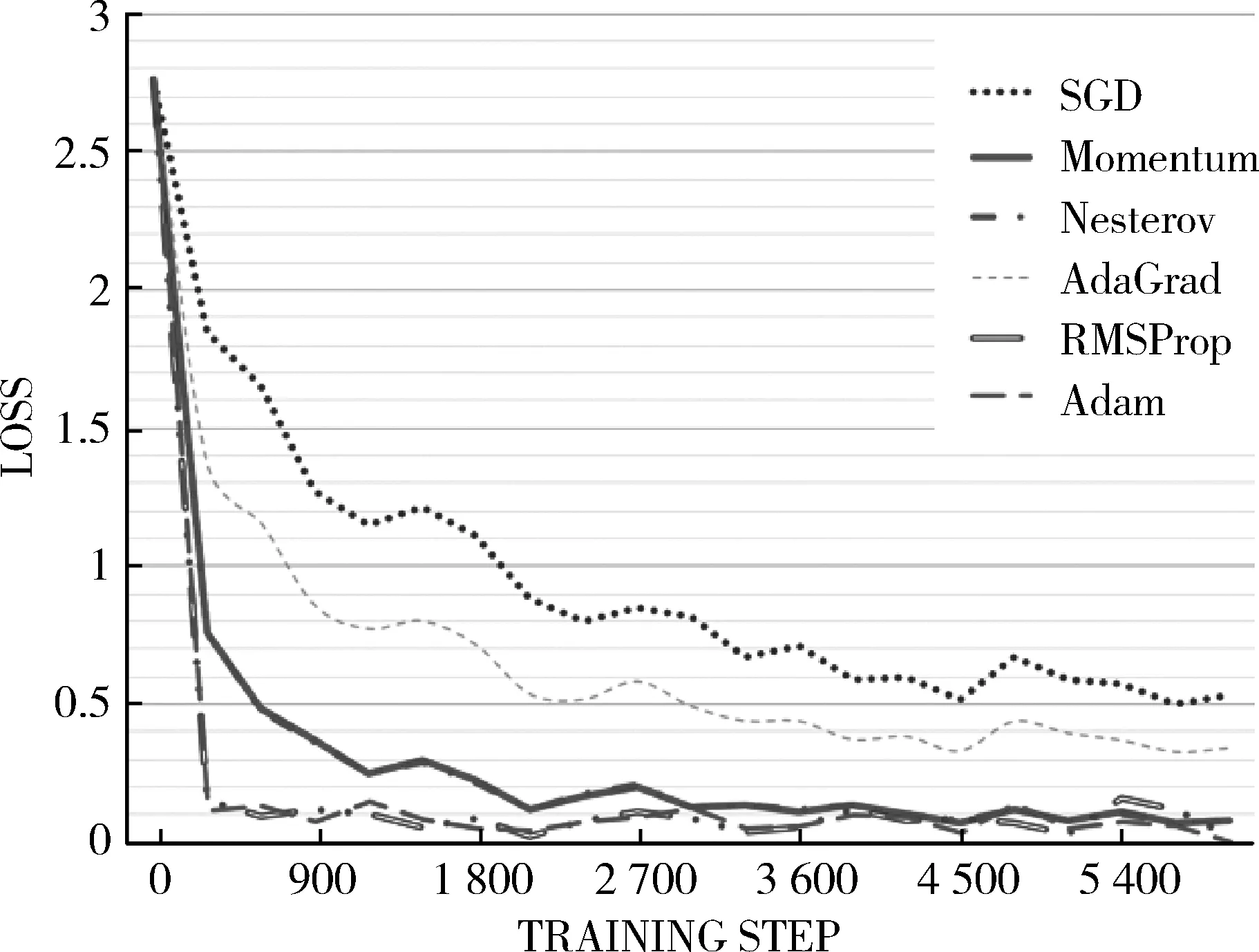
图1 算法训练损失对比
4.3.2 测试集上准确率结果
六种优化算法在相同测试集上的损失及准确率评价指标对比结果如表1所示。RMSProp优化算法的泛化性能最佳;综合在训练集上的表现,SGD算法存在欠拟合的问题,而AdaGrad存在易过拟合的问题。
4.4 结果分析
根据上述实验结果可得,SGD算法的收敛速度最慢;Momentum动量和Nesterov动量算法加速了SGD的收敛速度;AdaGrad算法由于梯度平方的不断累积导致学习率不断变小,影响了学习效率,因此收敛效果不如动量算法;RMSProp和Adam算法拥有最佳的收敛速度,同时RMSProp算法在测试集上拥有最佳的泛化效果。
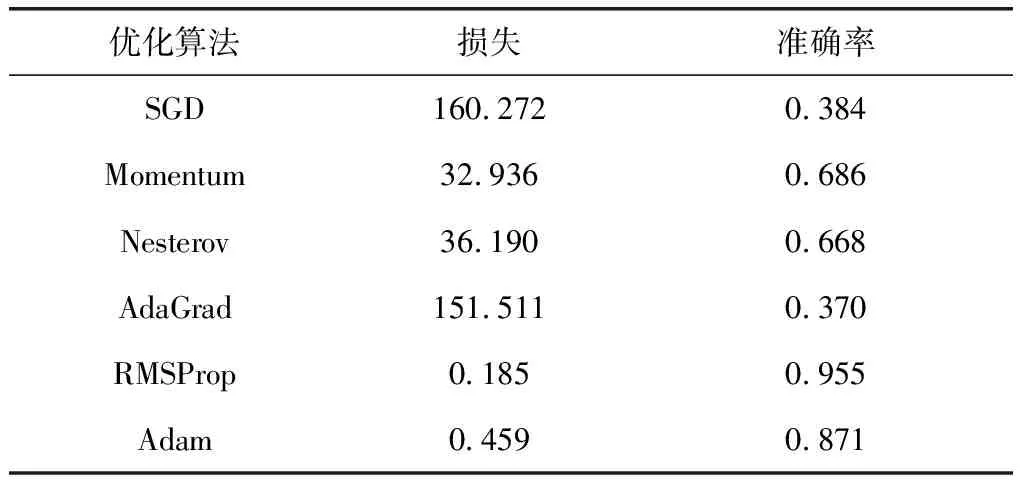
表1 六种优化算法验证集评价指标对比
5 结论
通过对深度学习各种常用优化算法的理论分析和实验,可得各种优化算法针对学习率和更新方向进行了启发式设置。动量算法对更新方向进行了优化,提升了收敛速度,但需要精细设置超参数;自适应优化算法对学习率和方向均进行了优化,超参数设置相对简单,拥有较快的收敛速度,普遍作为首选优化算法,且特别适用于稀疏数据。
猜你喜欢
高中数理化(2024年8期)2024-04-24 05:21:33
数学物理学报(2021年6期)2021-12-21 06:24:38
中学生数理化(高中版.高考理化)(2020年9期)2020-10-27 02:30:46
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
应用数学(2020年2期)2020-06-24 06:02:50
中学生数理化(高中版.高考数学)(2020年1期)2020-02-20 13:23:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
数学物理学报(2017年5期)2017-11-23 07:51:31
河南科技(2014年3期)2014-02-27 14:05:45
