
基于SIFT和感知哈希的图像复制粘贴篡改检测方法
2019-07-15 01:37马伟鹏林敏锐吴泽宇黄国铨
现代计算机 2019年15期
马伟鹏,林敏锐,吴泽宇,黄国铨
(韩山师范学院,潮州 521041)
0 引言
近年来,随着信息科技的发展,多媒体技术已经广泛的应用在我们的生活和学习之中,改善质量。逐渐的,数字图像已经成为了一种非常重要的信息载体,成为生活中不可分割的一部分。在如今计算成像技术的发展下,计算机软件可以制造出与真实照片一样让人肉眼难辨的“PS”照片,这种信息来源的真实性受到严重的威胁。在现在成熟的图像处理技术之下,对数字图像的篡改事件比比皆是。例如2005年韩国科学家黄禹锡带队的干细胞研究突破造假图片、2007年《巴黎竞赛画报》法国总统萨科齐“赘肉门”事件、2008年伊朗导弹造假事件等,让这种“眼见为实”的传统观念彻底打翻,造成政治、文化、新闻和科学真实性方面很大程度上受到负面的影响。
设计该作品主要的目的是帮助人们更好地辨认图片的真假,提高信息的可靠程度,不让虚假信息传播,一定程度上遏制对虚假信息对政治、文化、新闻和科学真实性的负面影响。
如今发达的图像处理技术之下,篡改方式有很多种,但主要分为同幅图像的复制粘贴篡改检测和异幅图片的拼接篡改检测两种方式。本文讨论在同幅图像的复制粘贴篡改检测,本系统在复制粘贴篡改检测中利用局部特征提取的方式进行特征提取,再利用局部的相似型进行全局匹配,找到相似度高的位置定位出来,分析情况。
在同幅图片的复制粘贴篡改检测研究与实现中,技术关键为SIFT与SURF算法,感知哈希降维和K-means聚类定位篡改区域。
1 算法
1.1 SIFT与SURF算法
SIFT算法即尺度不变特征变换(Scale-Invariant Feature Transform)算法,是由David Lowe于1999年在计算机视觉协会提出并发布[3],到了2004年得到较好的完善[4]。SIFT算法在图像处理中非常成熟,因为尺度不变性,在人脸识别、图像拼接、图像检索等领域得到很好地使用。SIFT的特征提取过程主要分四个步骤[1]:尺度空间极值点检测、关键点的精确定位、关键点的方向确定和关键点的描述,如图1所示。

图1
虽然,SIFT的尺度不变性对图像的篡改检测带来很好的效果,但是提取出来的特征向量维度高的问题,给匹配过程中欧氏距离运算带来速度极慢的问题。所以很多学者对其不足进行优化,优化的方法大多是特征匹配和特征提取环境中进行的。文献[5]中Herbert等人提出了SURF算法,在特征提取中利用Hessian矩阵构建尺度空间,在图像积分过程中大大减少了其运算量;在文献[6]Yan Ke和Rahul Sukthankar提出了PCA-SIFT算法,是在描述子环节中对SIFT特征向量进行了降维,提高算法效率。本文将会利用感知哈希对SIFT算法在特征提取环节中对特征数据信息进行压缩,在特征匹配环节使用汉明距离比较两个特征点的相似度,从而提高特征匹配的速率和匹配效果的质量。
1.2 感知哈希降维
感知哈希是这些年来在对媒体信息安全领域出现的新技术。它将数字媒体映射成一小段小的数字序列,可反应数字媒体的重要视觉或听觉特征。图像哈希是使用特定的哈希算法对原图像进行数字序列化,该数字序列可以代表图像的特征,相当于一个指纹,只要图像独一无二,数字序列也就独一无二。在进行感知哈希的时候需要对SIFT特征转换成一个中间矩阵,再对中间矩阵用离散余弦变换(DCT)进行图像空间域转换,再提取左上角的低频部分,原理图像压缩一样[2]。转换后得到的系数矩阵,左上角大部分是图片内容信息。DCT的二维转换公式如下:
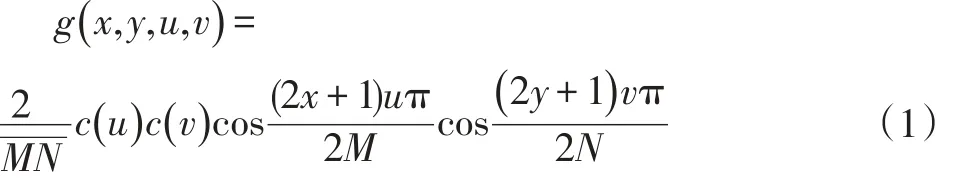
二维DCT定义如下:设f(x,y)定义M*N的数字图像矩阵,则:

式中 x,u=0,1,2,…,M-1;y,v=0,1,2,…,N-1。
程序的现实过程如下:
(1)输入数据:输入128维的SIFT特征向量作为初始数据。
(2)构建DCT矩阵:将输入的数据重整,重整为32×4的矩阵。
(3)计算DCT:把数据分解成频率聚集和梯度的形状。
(4)提取低频系数:选取DCT系数矩阵数据中左上角呈现的低频部分32维,其代表了图像的内容信息。
(5)计算系数均值:在32维的数据中计算平均值。
(6)系数序列化:根据32维的数据,设置0或1的二进制(如果该数值大于DCT均值则设置为1,小于DCT均值的设置为0)。
(7)计算HASH值:将32维的二进制设置为8位的十六进制的HASH表示。
将一维的SIFT特征向量转成二维的DCT矩阵输出后都会拥有一个特点:随着元素离DCT系数越来越远,它的模就倾向于越来越小[2]。这说明将DCT处理后的数据,已经将图像表示部分集中在DCT矩阵的左上角的系数(低频部分,体现图像的目标轮廓和灰度值分布特性),而矩阵的右下角部分系数几乎不包含有用信息。
1.3 K-means聚类定位篡改区域
经过了SIFT特征提取和感知哈希的降维之后,需要设定一个阈值,当两个感知哈希进行汉明距离的比较之后,但大于设定的阈值则判为相似的特征向量。但是提取的大部分的相似特征向量之后,需要把篡改区域标志出来,过程中往往存在很多异常,距离大的差错点。这时,需要使用K-means距离,把差错点剔除。K-means是机器学习中无监督学习中最常见的一种聚类算法,也是应用最广泛的聚类算法。它是一种基于目标函数划分的聚类算法,实际上基于距离划分的,它的任务是把相似的对象分到一个簇中,在迭代运算中可以自动分类。它是几乎可以运用与所有的对象,簇内的对象越相似,聚类效果就越好。本文中对篡改区域划分的过程如下:
(1)找出k个相似的区域作为初始化聚类的中心,在区域内随机选取一个坐标点。
(2)对剩余的每个坐标计算其距离(欧氏距离),把他划分给最近的那一类。
(3)重新计算已经得到的各个聚类中心点,不停的迭代运算。
(4)重复2、3步,知道中心条件停止为止,如果达到迭代次数则聚类中心不变。
图2为整个复制粘贴篡改检测过程。
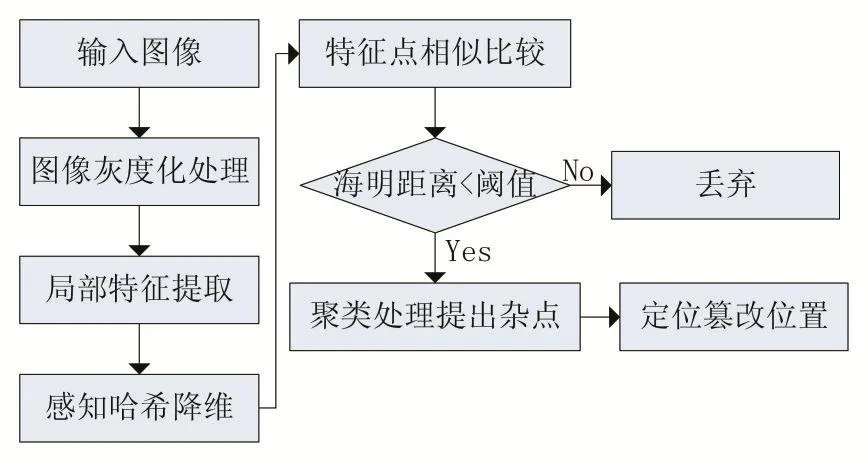
图2
2 实验结果及分析
通过举例子的方法进行实验结果及分析,以下例子中篡改者对图像进行了不同程度的篡改,系统均可以将其检测出来。

图3
图3中(1)是原图,篡改者以背景沙地当作被克隆的图像块,将复制到人物区域中,达到篡改目的。是已经篡改了的图片。(3)是使用特征描述的方式检测出相似的特征点。(4)是使用聚类处理,剔除误差点区域,使用区域的方式定位出篡改的地方。系统均可以达到比较理想的检测效果。

图4
图4中(1)是原图,篡改者以三辆坦克的其中一辆为克隆的图像块,将复制到空白的区域,达到看起来变成4辆坦克为篡改目的。(2)是已经篡改的图片。(3)是使用特征描述的方式检测出相似的特征点。(4)是使用聚类处理,剔除差错点区域,使用区域的方式定位出篡改区域的地方。

图5
首先对一张原图进行4种不同情况的克隆篡改,验证本系统算法的鲁棒性。图5中(1)是对克隆出来的目标进行平移处理,平移到其他不相交的地方,检测效果如图所示。(2)是对克隆的目标进行旋转和平移操作处理,选择操作60度,移至其他不相交的地方,检测效果如图所示。(3)是将克隆的目标进行缩放和平移处理,平移至不相交的地方,检测效果如图所示。(4)是将克隆的目标进行选择平移和加噪声处理,检测的效果如图所示。
3 结语
近年来,伪造图像的事件日益增多,给各大网络媒体曝光,给社会新闻和舆论带来很多的虚假性信息等安全问题。如果一些伪造图像继续被滥用,这可能会造成涉及经济、政治、军事等领域上真实性的问题,给社会带来巨大的危害,损失无法估量。针对目前较为流行篡改检测方法——复制粘贴篡改,总结出较为实用且效果较好的检测方法。开发了一个基于Web应用的平台给予用户和相关的政府机构使用,希望能给信息安全等问题带来一些解决方案。本文介绍了同幅图像的复制粘贴篡改检测方式,和目前效果较优的特征描述子;针对目前较有的特征描述子特征维度高,检查效率低等问题使用感知哈希的方法进行降维,针对提取出不稳定的特征点使用K-means方法进行聚类;最后检测效率和效果都比较理想。尽管如此,本系统还是存在一些不足的,只对于合成这种篡改手段有比较好的检测效果,对于变种、增强、计算机合成等篡改方式任然存在缺陷,但在之后将会结合深度学习方面的知识,不断完善,创造出一个令人满意的作品。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机应用与软件(2021年7期)2021-07-16
电脑爱好者(2021年8期)2021-04-21
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电机与控制学报(2018年9期)2018-05-14
