
网页分类技术研究现状与发展趋势的图谱分析
2019-07-08 05:33库尔班·麦麦提吾守尔·斯拉木
现代电子技术 2019年13期
库尔班·麦麦提 吾守尔·斯拉木
摘 要: 以Web of Science中1998—2017年间收录的1 277篇网页分类领域文献为研究对象,采用CiteSpace可视化工具,并使用科学计量学方法,系统回顾了网页分类领域中主要的研究机构、研究热点及研究脉络等内容。研究发现,目前的网页分类技术已完成理念界定和概念推广,并形成较为完善的研究体系结构。在该领域中,中国科学院和北京大学具有较强的科研能力,而美国在国际影响力上处于领先地位。另外,文中发现机器学习和数据挖掘是近几年网页分类领域的研究热点。文中的分析结果将为我国网页分类技术领域的研究提供一些参考。
关键词: 网页分类; 文献计量学; 图谱分析; CiteSpace; 研究机构; 研究热点; 研究脉络
中图分类号: TN915.03?34 文献标识码: A 文章编号: 1004?373X(2019)13?0081?05
Atlas analysis of webpage classification technology research status and developing trend
Kurban Mamat, Wushour Silamu
(College of Information Science and Engineering, Xinjiang University, Urumqi 830046, China)
Abstract: 1 277 webpage classification field documents collected from Web of Science in 1998—2017 are taken as the research object, and the CiteSpace visualization tool and scientometrics method are used to systematically review the main research institutions, research hotspots and research contents in the field of webpage classification. It is found that the concept definition and concept generalization of current webpage classification technology have completed, and a relatively complete research system structure was formed. In this field, the Chinese Academy of Sciences and Peking University have strong scientific research capabilities, but the United States is in the leading position of international influence. It is also found that the machine learning and data mining are the research hotpots of webpage classification field in recent years. The analysis results of this paper will provide some references for the research of webpage classification technology in our country.
Keywords: webpage classification; bibliometrics; atlas analysis; CiteSpace; research institute; research hotspot; research context
0 引 言
隨着互联网技术飞速发展,网络信息量呈指数级增加,网页浏览成为直观展示各类信息的主要途径。如今,各式各样、不同功能的网页层出不穷,如何快速定位并发现所需信息是人们一直以来关注的重点。为了能够高效地获得所需信息,人们一般对网页文档先进行分类,然后在此基础上寻找所需信息。研究人员对于网页分类研究已经进行了大量卓有成效的工作。本文通过研究国内外当前有关网页分类的大量文献,从而了解国内外网页分类研究领域的现状与研究趋势。
目前,国内虽然有研究人员从不同的角度对网页分类进行研究,却对于分析国际上网页分类领域的研究并不全面。因此,本文以Web of Science的核心数据库为数据源,运用CiteSpace工具对收集到的文献进行可视分析并阐述以下三个方面:国内外近20年在网页领域的主要研究机构;国内外近20年来网页分类领域的研究热点;国内外近20年网页分类领域的研究脉络。
首先,阐述了数据来源与研究方法;其次,对网页分类研究进行可视分析,得到该领域的主要研究机构、研究热点及演化脉络;最后,对分析结果进行讨论和比较,试图客观和形象地展示国内外网页分类领域研究现状与发展趋势,帮助我国网页分类的后续研究人员能更准确地掌握该领域的研究动态。
1 数据来源和研究方法的说明
1.1 数据来源
本文数据来源于信息检索平台Web of Science的核心数据库,该数据库覆盖学科较广,是一个综合性学术信息资源平台。本文采用以下方式收集数据:
1) 主题词检索方法,TS=((web page classification)OR (web page categorization))为检索式。
2) 文献时间跨度限定为1998—2017年。
3) 文献类型限定为“ARTICLE OR PROCEEDINGS PAPER”。
最终得到1 277篇核心合集文献并下载文献的题录,题录包括25个基本属性信息。
1.2 研究方法说明
科学知识图谱是将某领域的知识脉络及其演进历程进行集中展现的引文网络图谱,可自动标识知识基础的引文节点文献,以及共引聚类所表征的研究前沿[1]。本文通过CiteSpace可视化工具对收集到的1 277篇网页分类领域文献进行研究,并通过对机构及作者的合作网络、研究热点的共词以及演化过程进行分析,为未来研究网络分类技术提供宏观了解该领域的视角和思路。可视化工具CiteSpace是由陈超美博士开发的知识图谱工具。该工具可以对海量文献进行可视化定量分析,有效探测并发现某个研究领域的研究热点、研究趋势等关键信息。该工具可以直接导入Web of Science上下载的文献题录,免费供研究人员使用,适用于很多研究领域的文献分析工作。
2 研究结果与分析
2.1 主要研究机构分析
研究机构是进行学科研究的专门性组织。通过制作、研究机构的知识图谱,可以及时了解某一研究领域的权威机构,从而了解和把握该领域的研究趋势,紧跟研究热点。
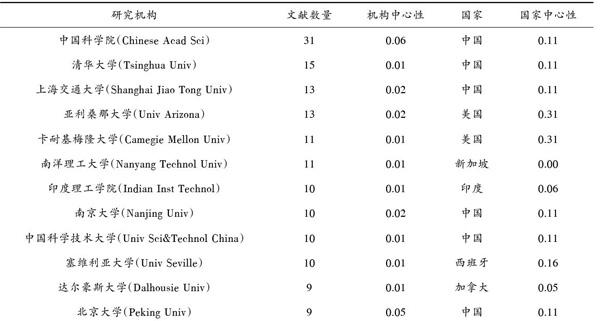
表1 按文献发表数量排名Top12 的研究机构
本文对收集到的文献进行基本统计分析。其中,发表文献量超过5篇以上的研究机构有35个,发文量在6~10篇的有19个,发文量在11~20篇的有5个,发文量在20篇以上的只有1个。
表1所示为多产文献数量排名Top12位的研究机构。以国家或地区来看,Top12榜单里中国的研究机构占6个, 美国的研究机构有2个,新加坡、印度、西班牙及加拿大各1个。以研究机构来看,中国科学院发表文献量以31篇位于榜首,排名第二位的清华大学发表文献量是15篇。
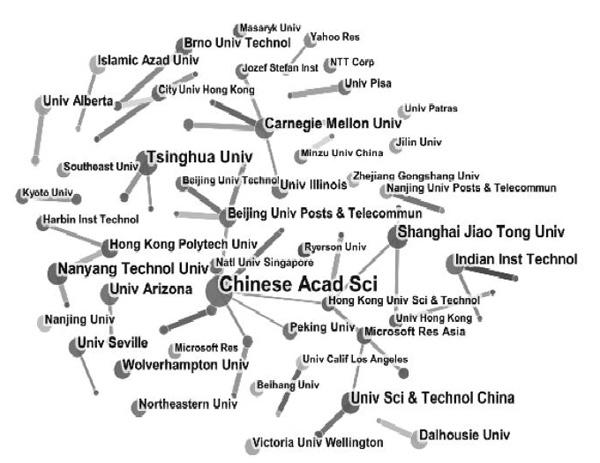
图1所示是设定一系列阈值后得到的研究机构的合作网络图。其中,圆形节点的大小代表研究机构发文量的多少,而连接线的粗细代表研究机构间合作关系的紧密程度。
中心性可以代表該节点在整个网络图谱中的影响力。中心性的大小与节点的影响力成正比,中心性越大,影响力越大。中心性大于0的研究机构有36个,从表1研究机构的中心性来看,中国科学院与北京大学的中心性最大,表示这两个研究机构的文献质量较好,对其他研究机构影响较大。
图1 研究机构合作网络共现分析
总体来说,中国的研究机构在国际网页分类领域上有着非常重要的地位,发文量及研究机构的数量相比其他国家较多。但从国家中心性的角度来看,美国的中心性排首位,其次是西班牙,中国的中心性排在第三位。这表明,美国和西班牙的研究机构的发文量虽然少,但是国际影响力比较大,而中国的研究机构相互之间影响和联系比较大,但国际影响力较小。我国在该领域的研究仍然具有较大进步空间。
2.2 基于共词分析的研究热点
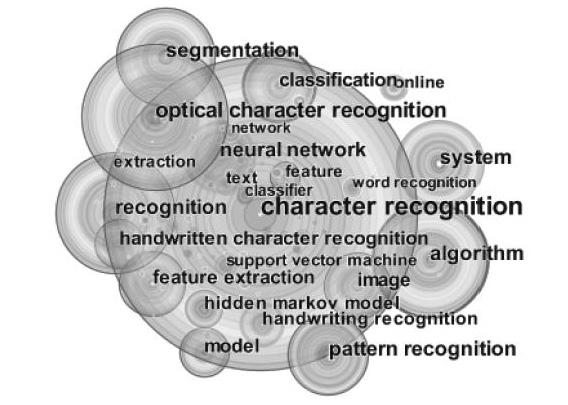
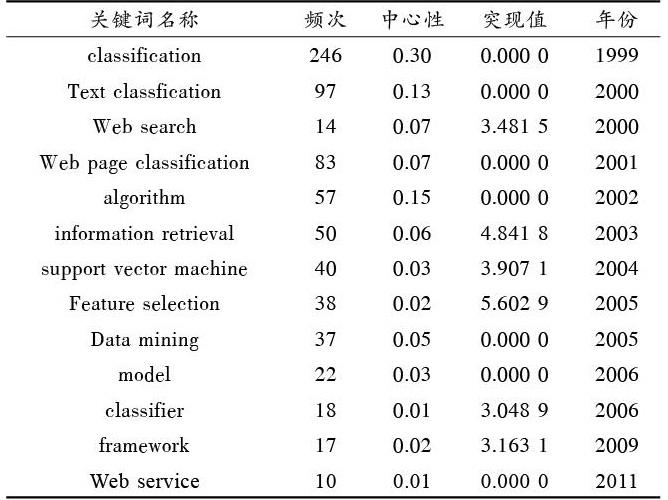
关键词是论文核心内容的凝练与浓缩,对关键词进行图谱分析,能揭示网页分类领域的研究热点,并可以发现论文之间的内部联系和研究领域的前沿问题[2]。鉴于此,为了了解近29年国际上网页分类领域的研究热点,本文通过关键词共现分析来鉴别该领域的主要热点,并对该研究领域主题结构的发展变化做出判断。通过运行CiteSpace之后可以得到关键词共现网络图谱,如图2所示。其中的圆形节点代表关键词,节点越大表示关键词出现的频次越多。不同层次的圆环代表关键词出现的不同年份,颜色越冷关键词被引的年份越早。表2所示是中心性大于0频次较高的主要关键词。
1) 频数(Freq)指标计量分析
频次是对节点进行统计后得到的数值,对文献的关键词进行统计分析后可以发现该领域的研究现状。如表2所示,1999—2001年关于分类的关键词频次较高,且文本分类技术的发展早于网页分类,是网页分类技术发展的基础。2002—2005年,首次出现的高频词有“algorithm”“information retrieval”“Feature selection”等,文献[3]使用基于同义词合并的特征选择的方法对文本进行分类。从2006年开始,首次出现的关键词较多,但频次较低。1999—2006年间数据分析表明网页分类领域开始逐渐成熟,延伸到多个研究领域,从该时期网页分类技术开始快速发展,国内外的众多研究者给予了更多的关注。
图2 关键词共现网络图谱
表2 关键词Top13的排名统计及首次出现年份
2) 中心性(Centrality)指标计量分析
通过关键词的中心性,可以更直观地发现该研究领域的热点问题。中心性较高的13个主题见表2。“classification”“Text classfication”“algorithm”是中心性排名靠前的关键词。由关键词的中心性可知,在网页分类技术研究领域中,算法的研究对网页分类提供了重要支撑。文献[4]使用超文本诱导主题搜索(HITS)算法对网页进行分类。2004—2006年,出现的高中心性关键词有“support vector machine”“Data mining”“classifier”等。支持向量机是机器学习领域中的一种学习模型,数据挖掘是横跨多个学科、多个领域挖掘信息的技术,分类器可以构造分类模型,而分类是数据挖掘中的一种重要方法。通过上面的关键词,发现关键词之间联系紧密,网页分类涉及的领域非常广泛,机器学习、数据挖掘等技术对网页分类领域的发展奠定了最扎实的基础,为后续的发展提供了强有力的技术支撑。近几年,人工智能技术开始融入到网页分类领域上,该技术对网页分类的运用使该领域突破了新的高度,也带来了新的机遇和挑战。
3) 突现(Burst)指标计量分析
Burst指标是指变量在一段时期内发生显著变化的值,用突现值来分析文献深层变化的信息。“Web search”是最早出现的突现值,突现值为3.148 15,从该突现值发现网页分类技术在2000年左右还处于初步发展阶段,网页搜索技术在该阶段变成研究热点。2003—2005年每年都有突现值,分别是“information retrieval”“support vector machine”“Feature selection”,该时间段网页分类领域发展迅速,研究热点逐渐变多,研究者通过不同的视角分析网页分类。2009年出现的突现词是“framework”,文献[5]提出对短文本分类的框架。通过对突现词的整体分析,可以发现典型的基础技术在该领域的一段时期内发生显著的变化,并引领该领域的后续发展。
3 研究演化分析
1973年美国情报学家Henry Smal首次提出了共被引分析的概念。共被引分析(Co?Citation Analysis)是指当两篇文献同时出现在另一篇文献的参考目录时,则这两篇文献已构成共被引关系。原始数据集中的共被引文献可以当作该研究领域的知识基础,知识基础的聚类和演变研究是探究热点主题、研究演化的重要依据。在CiteSpace中设置一系列参数并运行之后得到共被引文献共现聚类图谱,如图3所示。
图3 共被引文献共现聚类图谱

1) 1998—2005年:通过图3的聚类和分析,该阶段的共被引文献量较多,并且文献之间的内在联系较密切。通过该阶段的大量文献发现,该阶段的研究主要集中在“网页分类算法研究”和“网页分类技术的理念推介”两个方面。于2002年发表的文献[6]的共被引次数较多,该文献主要研究的是机器学习在文本自动分类中的应用。文献[6]详细讨论了文本表示、分类器构造和分类器评估三个方面的问题,为后期研究提供了重要理论支持。 文献[7]在关于网页分类研究中参考了该文献,这也表明文本分类技术是网页分类领域的前沿分支。研究网页分类算法是推动网页分类技术发展的基础研究,文献[4]提出超文本诱导主题搜索算法,该算法通过减少输入数据的大小来减少网页分类所需的时间。通过图3的分析,可以发现该阶段网页分类领域有很多优秀的研究成果,这些研究成果为后续的网页分类技术的发展提供了丰富的理论和实践基础。
2) 2006—2011年:该阶段的共被引文献量相比第一阶段少了很多,文献之间的联系还算密切,该阶段的高共被引文献是于2009年发表的文献[8],该文献主要有三方面的贡献,分别是:针对网页分类,探索并总结了有用的网页特性和算法;列举网页分类的主要应用程序;讨论未来的研究方向。该文献最大的优点就是系统地总结了国内外专家的研究结论和成果,并在此基础上对未来的发展方向进行分析和讨论。文献[9]在关于网页分类优化方法和网页分类模型改进的文献中参考过该文献。文献[10]是该阶段的第二个高共被引文献,该文献主要介绍支持向量机的库文件LIBSVM的实现细节,并详细讨论了支持向量机优化问题、理论收敛的多类分类概率估计和参数选择等问题。支持向量机应用到网页分类技术上不仅提高了网页分类的效率,还提高了准确率。文献[11]利用支持向量机提出了高效的网页自动分类方法。通过该阶段的共被引文献分析,该阶段的网页分类领域不管是在理论研究上还是在实用系统上都取得了很多优秀的成果,尤其是與机器学习技术的结合产生了很多有效率、有准确率的网页自动分类系统。
3) 2012—2017年:如图3所示,该阶段的高共被引文献相较于前两个阶段少很多,导致该结果的原因有两个:第一是因为年代比较近,很多优秀的文献还没有被人挖掘并引用;第二是因为网页分类领域的研究分支越来越细化,研究中心呈现多态化,因此文献分布越来越广。该阶段共被引次数较多的是文献[12],主要讲的是基于关键词抽取技术的文本分类。通过多个分类算法的对比实验发现,决策树算法具有非常好的文本分类精度,文献中的朴素贝叶斯、决策树和K?近邻算法的对比实验分析给后面的研究者提供了很好的参考作用。文献[5]在关于短文本分类中就参考过上述文献。该阶段网页分类领域不断扩大,不断涉及其他领域的技术,如数据挖掘、机器学习、特征选择等技术。
本文利用CiteSpace工具对国内外近20年有关网页分类领域的文献进行可视分析,对网页分类领域的主要研究国家、研究机构、研究热点和演化过程有了一定的了解。通过以上分析和介绍,网页分类领域分为以下三个阶段:初创期(1998—2005年);发展期(2006—2011年);深化期(2012年—至今),如表3所示。
表3 主题词阶段分析表

4 结 语
结合前文分析对本文的总结如下:
1) 国际网页分类领域的发展已经趋于稳定状态。从研究机构的影响力来看,在文献的数量和质量上,中国的研究机构处于领先地位,尤其是中国科学院不仅发文量多影响力也比较大。从国家的角度来看,美国对其他国家的影响力最大,其次是西班牙,中国排名第三。
2) 国际网页分类领域的研究热点主要在机器学习和数据挖掘两方面较突出。这两方面的研究成功地让网页分类技术不管在效率上还是正确率上相较以前提高了很多。
3) 国际网页分类领域现在已经形成了较为完善的研究网络。有很多优秀的文献提供了理论基础和实验论证,该领域还在不断地拓展自己的领域,研究分支越来越细化。
参考文献
[1] 陈悦,陈超美,刘则渊,等.CiteSpace知识图谱的方法论功能[J].科学学研究,2015,33(2):242?253.
CHEN Yue, CHEN Chaomei, LIU Zeyuan, et al. The metho?dology function of CiteSpace mapping knowledge domains [J]. Studies in science of science, 2015, 33(2): 242?253.
[2] 胡海霞.基于CNKI的计算机科学期刊论文的计量分析[J].宜春学院学报,2017,39(6):50?54.
HU Haixia. Quantitative analysis on the journal article of computer science based on CNKI data [J]. Journal of Yichun University, 2017, 39(6): 50?54.
[3] YAO H, LIU C, ZHANG P, et al. A feature selection method based on synonym merging in text classification system [J]. EURASIP journal on wireless communications & networking, 2017, 166: 1?8.
[4] MEADI M N, BABAHENINI M C, AHMED A T. New use of the HITS algorithm for fast web page classification [J]. Turkish journal of electrical engineering & computer sciences, 2017, 25(3): 2015?2032.
[5] NANDINI V, JANANI C R, MAHESWARI P U. A framework for measuring similarity between terms in short text categorization [C]// 2016 Online International Conference on Green Engineering and Technologies. Coimbatore: IEEE, 2017: 1?7.
[6] SEBASTIANI F. Machine learning in automated text categorization [J]. ACM computing surveys, 2002, 34(1): 1?47.
[7] LEE J H, YEH W C, CHUANG M C. Web page classification based on a simplified swarm optimization [J]. Applied mathematics and computation, 2015, 270(C): 13?24.
[8] QI X, DAVISON B D. Web page classification: features and algorithms [J]. ACM computing surveys, 2009, 41(2): 1?31.
[9] LI H, XU Z, LI T, et al. An optimized approach for massive Web page classification using entity similarity based on semantic network [J]. Future generation computer systems, 2017, 76: 510?518.
[10] CHANG C C, LIN C J. LIBSVM: a library for support vector machines [J]. ACM transactions on intelligent systems and technology, 2011, 2(3): 1?27.
[11] BHALLA V K, KUMAR N. An efficient scheme for automatic Web pages categorization using the support vector machine [J]. New review of hypermedia & multimedia, 2016, 22(3): 223?242.
[12] MNAKA S, RADHA N. Text classification using keyword extraction technique [J]. International journal of advanced research in computer science and software engineering, 2013(4): 128?132.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
少先队活动(2020年12期)2021-01-14
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年10期)2018-08-04
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
中成药(2017年3期)2017-05-17
电子制作(2017年2期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
电子测试(2015年18期)2016-01-14
