
改进YOLO的车辆检测算法
2019-07-08 05:33刘肯何姣姣张永平姚拓中常志国
现代电子技术 2019年13期
刘肯 何姣姣 张永平 姚拓中 常志国

摘 要: YOLO目标检测算法在进行目标检测和识别时具有识别精度高、检测速度快的特点。但也存在明显的问题,由于网络采用的结构是端对端模型,没有经过预选框进行匹配预选,直接进行回归产生最后的结果框,所以存在定位不准的问题。同时,YOLO网络将图片整体resize到固定的尺寸后,进行网格划分,当单个网格存在不止单个目标时,容易出现漏检的情况。DenseNet网络使用一种全新的网络结构,结合前面特征层的信息,在一定程度上提升了对物体的检测精度。在此基础上提出YOLO?D算法,结合前面特征层的信息,在不影响检测速度的同时,提高车辆检测精度,与此同时使得定位有所改善。
关键词: YOLO; 端对端模型; DenseNet; 车辆检测; YOLO?D; 检测精度
中图分类号: TN911.73?34 文献标识码: A 文章编号: 1004?373X(2019)13?0047?04
Improved YOLO vehicle detection algorithm
LIU Ken1, HE Jiaojiao1, ZHANG Yongping2, YAO Tuozhong2, CHANG Zhiguo1
(1. School of Information Engineering, Changan University, Xian 710064, China;
2. College of Telecom, Ningbo University of Technology, Ningbo 315211, China)
Abstract: The YOLO target detection algorithm has the characteristics of high recognition accuracy and fast detection speed for target detection and recognition, but also has obvious problems. The network adopts an end?to?end model, and directly generates the final result framework after regression without matching and pre?selection of pre?selection framework, so the positioning is inaccurate. The YOLO network can resize the entire image to a fixed size, and divide the mesh. When there is more than one target in a single mesh, it is likely to result in the missed detection. A brand?new network structure is used in DenseNet network, and combined with the information of the front feature layer to improve the detection accuracy of the object to a certain extent. Thus, the proposed YOLO?D algorithm combined with the information of the front feature layer can improve the vehicle detection accuracy and positioning accuracy while maintaining the vehicle detection speed.
Keywords: YOLO; end?to?end model; DenseNet ; vehicle detection; YOLO?D; detection accuracy
0 引 言
随着人们生活质量的提高,越来越多的汽车走进了大众家庭,随之产生的问题也很多,如车辆乱停乱放,闯红灯等。依赖传统的人力解决这些问题是远远不够的,因此提出用计算机去解决这类问题。Seki等人提出将背景差分用于动态车辆检测[1],在此基础上STAUFFER等人提出了自适应背景更新[2],将其应用于车辆检测。KOLLER等人提出用3D模型检测和跟踪车辆的方法[3]来提高识别率。传统的目标检测算法虽然在识别精度上基本满足识别车辆的要求,但是其速度慢、过程复杂的问题也比较明显。随着近些年人工智能的火热,越来越多的研究人员开始关注基于深度学习的车辆检测算法,相比于传统的方法,基于深度学习的方法能够学习到更多的目标特征。如文献[4]提出基于卷积神经网络的车辆检测方法,运用滑动窗口生成候选区域,采用卷积神经网络的卷积层和池化层提取车辆特征,最后用全连接层进行候选验证,由于是通过滑动窗口来产生候选区域,在滑动的过程中会有很多重复的区域,非常消耗时间,影响算法的效率。文献[5]提出R?CNN算法,在速度上相比CNN提升很多。R?CNN提出选择性搜索(Selective Search)方法,使用一种过分割手段将图像分割成小区域,通过颜色、纹理、面积等合并方式产生候选区域。R?CNN算法流程主要分为3个步骤,首先使用Selective Search[6]提取约2 000个候选区域,接着用CNN提取每个候选框中的特征向量,最后用SVM算法判断候选区是否是目标。在VOC 2007测试集上的MAP被提升至48%,2014年通过修改结构将MAP提升到66%,与此同时,在ILSVRC2013测试集上的MAP也被提升到31.4%。R?CNN在目标检测领域取得了突破,随后出现了SPP?NET[7],Fast R?CNN[8],Faster R?CNN[9],R?FCN[10],YOLO[11],SDD[12]等目标检测算法。其中,Faster R?CNN将检测和分类模块都放在同一个深度学习框架之下,就检测准确率相比其他目标检测算法要高,但是随之带来的缺点是速度慢,YOLO算法的网络设计策略延续了GooGleNet[13]的核心思想,实现端对端网络的目标检测,发挥了速度快的优势,但是其精度有所下降,本文提出一种YOLO?D算法,在不影响检测速度的情况下提高了检测准确率。
1 YOLO目标检测模型介绍
YOLO算法模型包括18个卷积层,2个全连接层和6个池化层,如图1所示。其中,卷积层用于提取图像的特征;全连接层用于预测图像位置与类别估计概率值;池化层负责缩减图片像素。YOLO直接对输入的图片进行回归分析,输出多个滑动窗口位置以及该窗口检测到的目标类别。
图1 YOLO网络框架
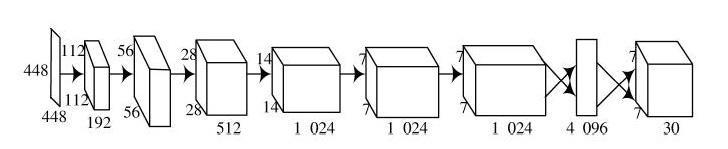
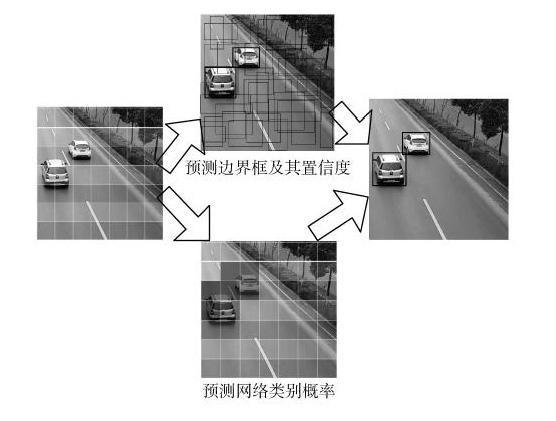
YOLO将输入图像分为[S×S]个单元格,每个单元格负责检测“落入”该单元格的对象,若某个物体的中心位置落到某个格子,那么这个格子就负责检测出这个物体。每个格子输出[B]个bounding box(包含物体的矩形区域)信息,以及[C]个物体属于某种类别的概率信息。Bounding box信息包含5个数据值,分别是[x,y,w,h]和Confidence(置信度),边界框的大小用4个值来表示:[(x,y,w,h)],其中,[(x,y)]是邊界框的中心坐标,而[w]和[h]是边界框的宽与高。经过删选,最终每个单元格会预测两个单元格但只预测一个类别概率(即就是两个边界框共享一个类别),最后的prediction是[7×7×30](即[S×S×(B×5+C))]的张量,整个流程大致如图2所示。
图2 YOLO过程示意图
2 YOLO?D
YOLO算法使用回归思想,把目标检测问题作为一个回归问题处理,可以一次性实时预测多个目标边框的位置和类别。由于YOLO没有选择滑动窗口或提取候选区域的方式训练网络,而是选择直接选用整幅图像来做训练,提升了训练速度,与此同时牺牲了一些精度。DenseNet网络,其核心思想是skip connection,对于某些输入直接进入之后的layer,从而实现信息流的整合,避免信息在层间传递的丢失和梯度消失,同时加强层与层之间的特征联系。在此基础上提出YOLO?D算法,在YOLO算法的基础上添加DenseNet结构,使其学习很多的层与层之间的特征联系,提高预测精度。
如图3所示,每个块代表当前特征图的大小,在YOLO算法中,每一个相同大小的特征图有多个,为了方便表示,用特征块代替。在每一个特征块中,当前特征向后面卷积层传递时,选择特征块中的最后一层。
图3 YOLO?D网络结构
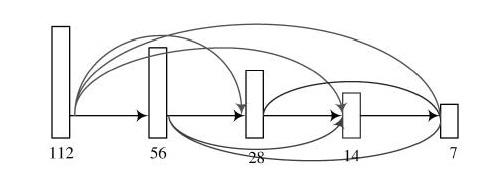
由于DenseNet不是像素之间的相加,而是通道之间的连接,为了保证通道之间的连接不出现tensor过大,资源耗尽的情况,通过使用1×1的卷积核进行通道的压缩,如在14×14的卷积块中,一共有三个输入,其中,由28×28卷积块传递的是YOLO网络原始的结构,将其作为主线,旁边两条为分支输入,由YOLO结构可知,14×14卷积块中的第一个卷积层通道数为1 024,为此通过使用1×1的卷积核分别将两个分支的通道数变为512,其他类似连接,从而保证主线的特征为主要特征输入,同时也缩短计算量。
3 实验及结果讨论
3.1 数据集
数据集主要分为两部分:一部分为自己手动标注的数据集;另一部分来自于UA?DETRAC[14]数据集。DETRAC数据集主要拍摄北京和天津的道路过街天桥,图片大小为960×540,包含多个角度车辆照片,先把数据集所出的XML格式转换成需要的VOC2007格式。另一部分是用摄像机手动采取的数据,大小为1 920×1 080,由于YOLO网络使用的是全连接层,所以对输入图片的大小有要求,为了统一数据集,将训练图片的大小统一为960×540。所有的数据集都只有一类(car)。选取DETRAC数据集和自制数据集各1 000个训练样本,同时为了扩增训练样本,对所有的训练样本进行水平镜像翻转操作。YOLO?D的算法模型训练过程如图4所示,经过转换增强后得到最终的模型。
图4 YOLO?D训练模型获取过程

3.2 实验平台
实验主要是在PC端完成的,PC主要配置为:CPU(i5?8600),GPU(NVIDIA GTX?1080)和16 GB内存,实验是在TensorFlow框架下进行,使用的是python语言。
3.3 评估方法和结果对比
在测试阶段,把测试集分为两部分:[15]的原图片,[45]的原图片。如图5所示。
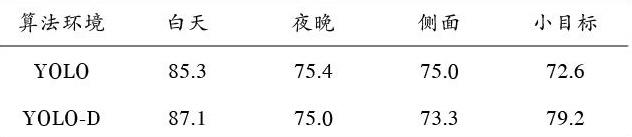
实验中给出YOLO算法和本文的YOLO?D算法分别在晴天、雨天、夜晚时分的数据对比。由于YOLO?D网络注重结合之前特征层的特征,因此对远处的小目标(车辆)测试集1进行检测。表1中的白天、夜晚、侧面中的数据仅从测试集2中检测。从表1中可以看出,YOLO?D对白天和夜晚的预测改进有效,尤其是对小目标的检测有很大的提升,对侧面的车辆检测改进效果不明显;从表2中可以看出,YOLO?D的查全率针对小目标有所提升,其他情况影响不大,甚至在侧面情况稍微有所下降。
图5 测试集

表1 網络性能查准率对比
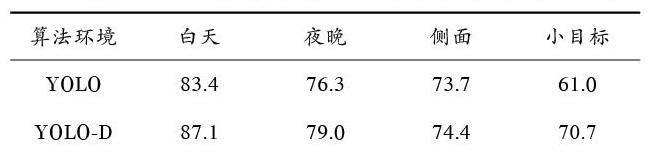
表2 网络性能查全率对比
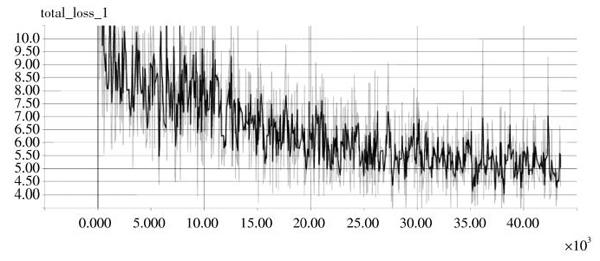
图6 Total_loss
3.4 结果分析
本次实验只要预测的目标和真实目标框的IOU大于0.5,就认为目标被正确检测定位。分别在不同场景的测试集进行测试,效果优于YOLO算法。由于YOLO算法本身没有采用滑动窗口进行定位回归,所以容易出现定位比较差的情况。YOLO?D在尝试增加特征层的特征的同时,发现对目标框的定位有所改进。从图7中可以看出,尽管增强了后面卷积层的特征输入,但还是存在部分漏检的情况,以及对远处的车辆未能准确识别的情况。
图7 YOLO?D算法部分识别结果
4 结 语
本文对深度学习目标检测算法YOLO进行改进,把目标检测算法问题变成二分类问题,从而实现对目标车辆的检测。通过对YOLO算法的改进,提高了对远处小目标的检测,虽然还存在漏检车辆,但是在近处有较高的识别精度和差不多30 f/s的识别速度,基本上满足交通道路车辆检测的准确定位和实时性需求。
参考文献
[1] SKEI M, FUJIWAEA H, SUMI K. A robust back?ground subtraction method subtraction method for changing background [C]// The 5th IEEE Workshop on Applications of Computer Vision. Palm Springs: IEEE, 2000: 1?7.
[2] STAUFFER C,CRIMSON W E L. Adaptive back?ground mixture models for real?time tracking [C]// 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Fort Collins: IEEE, 1999: 1?7.
[3] KOLLER D, DANILIDIS K,NAGEL H H. Model?based object tracking in monocular image sequences of road traffic scenes [J]. International journal of computer vision, 2013, 10(3): 257?281.
[4] BAUTISTA C M, DY C A, MANALAC M I, et al. Convolutional neural network for vehicle detection in low resolution traffic videos [C]// 2016 IEEE Region 10 Symposium. Bali: IEEE, 2016: 277?281.
[5] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// 2014 IEEE Conference on Computer Vision and Pattern Recognition. USA: IEEE Computer Society, 2014: 580?587.
[6] UIJLINGS J R, VAN DE SANDE K E, GEVERS T, et al. Selective search for object recognition [J]. International journal of computer vision, 2013, 104(2): 154?171.
[7] HE K, ZHANG X, RENS, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition [J]. IEEE transactions on pattern analysis & machine intelligence, 2014, 37( 9): 346?361.
[8] GIRSHICK R. Fast R?CNN [C]// Proceedings of 2015 IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 10?15.
[9] REN S, HE K, GIRSHICK R, et al. Faster R?CNN: towards real?time object detection with region proposal networks [C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal: MIT Press, 2015: 1?15.
[10] DAI F, LI Y, HE K M, et al. R?FCN: Object detection via region?based fully convolutional networks [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona: Curran Associates Inc., 2016: 379?387.
[11] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real?time object detection [EB/OL]. [2015?07?11]. http://ai2?website.s3.amazonaws.com/publications/YOLO.pdf.
[12] LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// Proceedings of 2016 European Conference on Computer Vision and Pattern Recognition. [S.l.]: Springer, 2016: 13?17.
[13] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2014: 1?12.
[14] WEN Longyin, DU Dawei, CAI Zhaowei, et al. DETRAC: new benchmark and protocol for multi?object detection and tracking [EB/OL]. [2015?11?03]. https://www.researchgate.net/publication/283986610_UA?DETRAC_A_New_Benchmark_ and_Protocol_for_Multi?Object_Detection_and_Tracking.
[15] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2015: 770?778.
