
基于双卷积神经网络的铁路集装箱号OCR
2019-07-08 06:46陈力畅李宇波
计算机时代 2019年6期
陈力畅 李宇波

摘 要: 针对尚缺乏识别准确率高的铁路集装箱箱号OCR系统这一现实,设计了一套识别准确率能够达到98%以上的铁路集装箱箱号OCR系统。该系统对采集到的图像进行字符的自动分割,在训练CNN时针对目前数据集多样性不足、样本较少的情况,采用了数据增强的方法扩充数据集,并且基于LeNet-5进行了网络结构搜索,训练了分别用于数字和字母识别的卷积神经网络Digit Net和Letter Net,其在测试集上的识别准确率分别能够达到99.7%和99.2%。
关键词: 铁路集装箱箱号; OCR; 数据增强; 网络结构搜索; 双卷积神经网络
中图分类号:TP391.4 文献标志码:A 文章编号:1006-8228(2019)06-01-04
Abstract: In China, there is still a lack of high-accuracy railway container number OCR system. This paper designs a railway container number OCR system with recognition accuracy of over 98%. This system automatically divides the characters in acquired image. When training CNN, to cope with the insufficient diversity of current datasets and the lack of samples, data augmentation is used to enlarge the dataset. This system performs network structure search based on LeNet-5, training the convolutional neural networks Digit Net and Letter Net for digital and letter recognition respectively. The recognition accuracy on the test set reaches 99.7% and 99.2%.
Key words: railway container number; OCR; data augmentation; network structure search; double convolutional neural networks
0 引言
隨着我国“一带一路”战略的顺利实施,无论是海运集装箱还是铁路集装箱过关数目均大幅度上升。这也给近些年来随着卷积神经网路发展而飞速进步的OCR[1]识别技术带来了新的应用场景。国内已经有众多学者对OCR技术做出了改进并且运用于港口与码头集装箱的箱号识别上,如陈永煌[2]等提出了基于模板匹配与特征匹配的港口集装箱箱号字符识别算法;黄深广[3]等提出了基于CNN和模板匹配的港口集装箱箱号智能识别系统, 其识别的准确率能够达到97%,而且能够适应恶劣天气。
相对于港口与码头集装箱箱号OCR技术的广泛应用,铁路集装箱箱码OCR系统的研究则较为缺乏,目前识别率最高的是刘璇[4]提出的基于改进开源的Tessaract-OCR[5]的OCR算法,其识别精度为96.453%,但是这一精度显然无法最大化满足边境检查人员的实际需要,还是有部分箱号因为识别错误需要重新转由人工记录集装箱箱号导致清关的速度没有办法最大化。
针对上述问题,本文在OCR识别算法上做出了改进,采用了自主设计的CNN网络并开发了一套识别准确率在98%以上的铁路集装箱OCR系统。
1 OCR系统总体流程
本文所述的铁路集装箱OCR系统的总体流程图如图1所示。为了实现这一系统,首先需要在铁轨的两端固定红外接收与发射装置,由于火车所运输的两节集装箱之间会有一小段空隙,一端的红外接收器将在这段间隙中接收到另一端传输过来的红外信号,此时就达到了拍摄照片的触发条件,接收器将向摄像机发送一个控制信号,示意图见图2。而根据这个触发条件,我们可以预先固定好摄像机的位置和角度,在控制信号到来的时候拍摄图片,并将拍摄完成的图片传回到后端作为OCR识别算法的输入,最后运用提前训练的CNN模型进行字符识别并输出结果。
2 字符提取
2.1 箱号标准
集装箱箱号编码采用的是ISO6346(1995)标准,由11位编码组成,其中前4位为大写的英文字母,后面的7位为数字。需要明确的是,本文所构建的铁路集装箱箱号OCR系统只识别集装箱号,其余数字或者字母以及标志均不在识别的范围内。
2.2 图像预处理
⑴ 图像灰度化:为了加快图像的处理速度,同时也为了使得图像上的特征更为明显,通常需要对图像进行灰度化处理。本文采用的是加权平均值法的灰度化方法,采用B,G,R三通道的平均值描述图像灰度值。
⑵ 中值滤波:在进行灰度化处理之后,为了使得图像的噪声减小,通常还需要进行滤波处理。本文在尝试了高斯滤波,中值滤波以及均值滤波之后发现,对于需要处理的集装箱图片来说,中值滤波的效果更好,故采用中值滤波。
⑶ 图像二值化:本文将经过灰度化以及中值滤波之后的图像进行二值化处理,并通过自适应的OTSU法选取阈值T,具体的二值化公式见⑴:
2.3 投影法分割字符
所谓的投影法,就是沿水平方向或者垂直方向统计每一行或每一列中的目标像素个数。针对本文所述的特定场景,就是统计每一行和每一列的白色像素个数。再根据每一行和每一列的白色像素个数进行字符分割。由于本文只针对集装箱箱号进行识别,所以对于垂直投影来说,只需要分割出第一个波峰,对于水平投影来说则需要依次将所有的波峰切出。虽然已经将图片进行了预处理,但是不可避免地会存在噪声的干扰,所以,需要选定一个切割阈值,将阈值以下的部分视为噪声,将阈值以上的部分进行切割。而根据在多张图片上所进行的实验,本文选取的阈值为10。
3 CNN的训练与优化
3.1 数据集的构建
通过在实地采集的样本,将图片上的数字与字母一一分割取出,本文设计并构建了训练数据集和测试数据集。训练集一共有36个类包含数字0-9,大写字母A-Z,2958张包含单个数字或者字母的图片;与数据集相对应的测试集上有786张图片,同样是36个类。
由于铁路集装箱在运输的过程中不可避免地会受到风化,侵蚀而导致集装箱码有不同程度地磨损,如何让CNN能够准确识别这些破损的数字或者字母也是本文所构建OCR要提高识别准确率所面临的难点。受到LeCun[2]训练MNIST数据集时加入较多的模糊数字样本的启发,本文采用的方法为:在训练集中加入较多的破损数字和字母的图片,用来增强神经网络的泛化能力。
用于LeNet-5训练的MNIST数据集的大小为—训练集60,000个样本,测试集10,000个样本。前面所提到的自建数据集规模(见表1)显然远远小于这个数目,为了使得训练的神经网络具有更高的识别准确率以及更强的鲁棒性,本文对数据集进行了数据增强。
3.2 数据增强
所谓数据增强,就是将原始数据集通过图像反转,翻转,旋转,缩放等手段进行数据集的扩充。本文所采用的数据增强为图像随机在[-30?,30?]之间旋转,在[0.8,1.2]倍之间放缩。对于增强后可能带来的像素填充问题,为了防止引入噪声,本文采取了将空缺像素填0的操作。
3.3 LeNet-5
LeNet-5一共由7层组成,C1为卷积层(Convolution Layer),P1是池化层(Pooling Layer)接下来是另外一组卷积层加上池化层的组合C2和P2,最后是3个全连接层F1,F2,F3(Fully-Connected Layer)。由于切割后的图片大小为64×48,所以需要将LeNet-5的输入层改为64×48,输入层改动后的LeNet-5参数列表见表2。
3.4 双卷积神经网络
根据前文所述的集装箱码的编码规则,前面的4位为字母,后面的7位为数字,所以本文采取的策略是训练两个卷积神经网络,Digit Net和Letter Net分别针对数字识别和字母识别。本文首先运用LeNet-5对分割好的图片训练,采用提前终止的训练策略——就是在测试集上的准确率不再上升时停止。分别训练单独识别数字0-9的LeNet-5[6],识别字母A-Z的LeNet-5,以及识别数字+字母一共36个类别的LeNet-5,得到图3所示结果。由曲线的对比可得,对于此问题,数字和字母分开识别的效果远远比不分开的效果好。
3.5 基于LeNet-5的网络结构搜索
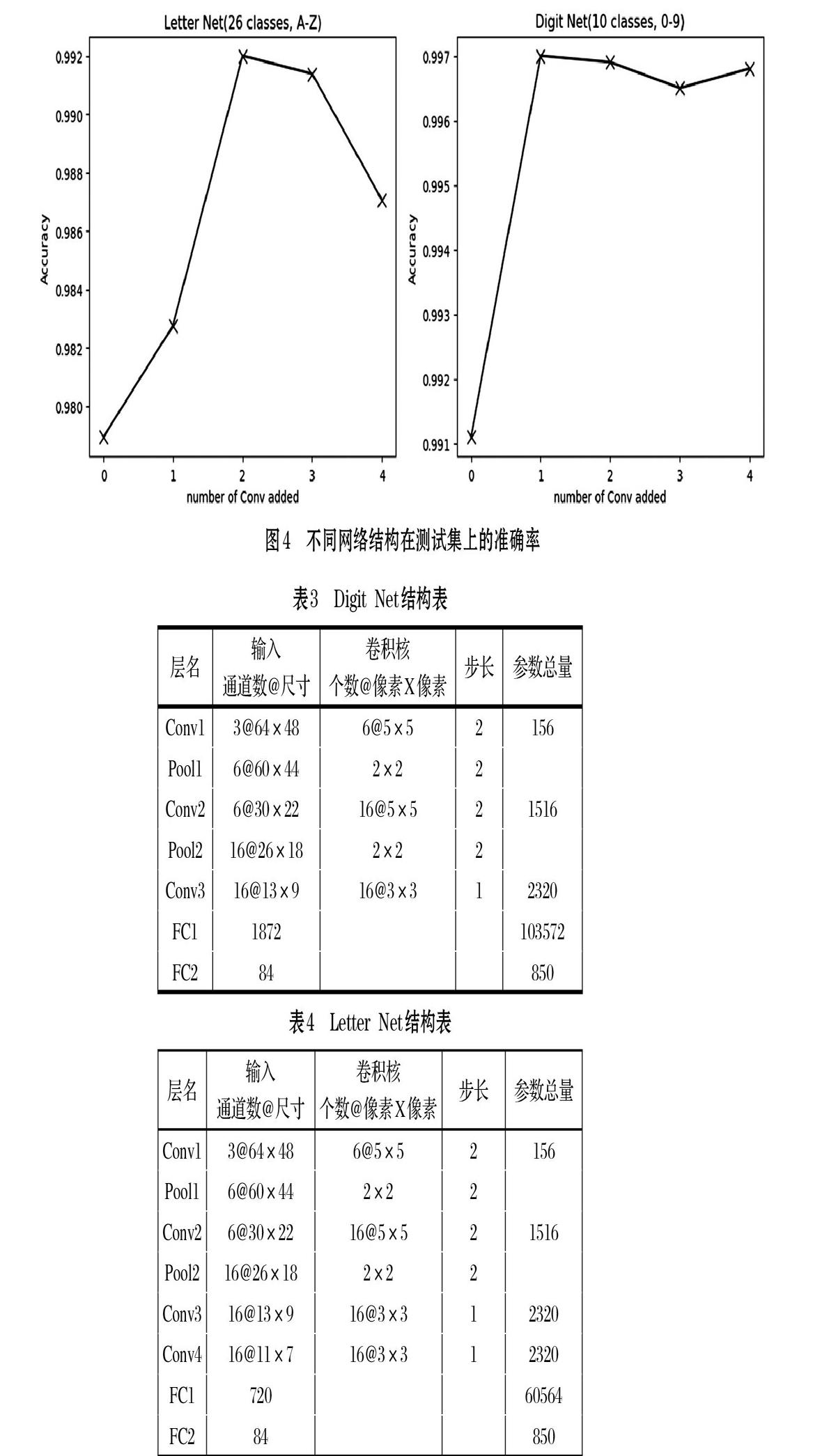
由图3得,前述的LeNet-5网络在数字测试集上的最高识别准确率98.5%,在字母训练集上的最高识别准确率为98.4%,显然这与在MNIST数据集上的最高识别准确率99.2%还有差距。分析其原因如下。
⑴ 数据集的规模过小(对比见表1)。
⑵ 输入图片尺寸不一致可能导致前述网络结构不是最优:由于本文所输入的图片尺寸为64×48,但是LeNet-5是用在MNIST数据集上进行训练的,MNIST数据集的图片大小均为32×32,原来的卷积层数目以及卷积核的大小5×5可能不是在本问题上的最佳选择。
⑶ 網络参数的数目过多而导致的模型复杂度上升,进而导致网络在小数据集上难以收敛。应该考虑降低网络的复杂度。
针对上面所述的问题,本文提出了如下的解决方案。
分析表2我们可以得到,F1层所占的参数数量为总参数的94.66%,是最主要的增加神经网络参数复杂度的一层。而这一全连接层的参数计算如下:先将P2进行展平(Flatten),得到s维向量,再将这s维向量与F1层的神经元数目f进行相乘加上f个神经元偏置b。具体见公式⑵:
要减小参数的数目,就要减小s和f,对此,本文采取的做法是直接将F1层去掉,从而减小了f。而为了减小s可以采取的是多叠加几层卷积层,因为多增加卷积层可以使得最后的P2展平后的参数数目变小而又能保证网络的总体参数只有少量的增加。
下面以在P2层后面增加一层带有16个卷积核,且卷积核大小为3×3的卷积层C3为例来说明增加卷积层带来的参数减少:C3卷积前,此时网络的输出shape为13×9×16,卷积后的输出shape为11×7×16,此时如果连接上F1则参数数目减少为:(13×9×16-11×7×16)×(120+1)=77440,算上C3卷积层参数数目的增加:(3×3×16+1)×16=2320,一共减少参数的数目为:77440-2320=75120。
为此本文采取了网络结构搜索的办法搜索最优的网络结构,也就是在P2层后面添加卷积层来实现。
本文基于上述方法,对增加0-4层卷积层的网络进行了训练,同样采取提前终止的训练策略,并分别记录在测试集上测试精度最高的模型,得到如图4所示结果。由准确率曲线我们选择识别率最高的Digit Net,99.7%和Letter Net,99.2%,其网络结构分别见表3和表4。
最后,将前面所述的OCR算法在含有298张铁路集装箱箱码的图片的测试集上进行了测试,测试的结果为能够正确识别292张图片上的集装箱箱码,由此得到此OCR系统的识别准确率为98%。
4 结束语
本文设计了一套针对铁路集装箱码识别的系统,并且详细说明了此套OCR系统的开发流程。在数据集的构建方面,本文采用了数据增强技术,将原始的图片通过旋转,放缩进行了扩充,使得样本的多样性大幅度提高,从而增强了后续训练的卷积神经网络的泛化能力。
本文还详细说明了两个网络Digit Net和Letter Net的结构搜索方法以及参数寻优过程,最终开发的针对铁路集装箱箱码的OCR系统识别准确率能够达到98%。希望本文网络参数寻优的经验能够为其他OCR系统的开发者提供参考。
参考文献(References):
[1] Islam N , Islam Z , Noor N . A Survey on Optical Character
Recognition System[J]. ITB Journal of Information and Communication Technology,2017.
[2] 陈永煌.集装箱箱号识别技术的研究与实现[D].华中科技大学,2013.
[3] 黄深广,翁茂楠,史俞,刘清.基于计算机视觉的集装箱箱号识别[J].港口装卸,2018.1:1-4
[4] 刘璇.铁路集装箱号码与车型智能识别系统研究[D].西南交通大学,2018.
[5] Smith R. An Overview of the Tesseract OCR Engine[C]// International Conference on Document Analysis & Recognition,2007.
[6] Lécun Y, Bottou L, Bengio Y, et al. Gradient-basedlearning applied to document recognition[J].Proceedings of the IEEE,1998.86(11):2278-2324
