
基于聚类分析的网络舆情倾向性分析研究
2019-07-04 10:25:00胡欣杰路雨楠
兵器装备工程学报 2019年5期
胡欣杰,路雨楠,路 川
(1.航天工程大学, 北京 101416; 2.哥伦比亚大学, 美国 纽约 10027)
网络舆情就是通过网络表达或传播的舆情,是指在互联网上传播的公众对某一“焦点”和“热点”话题所表现的有一定影响力和带倾向性的意见或言论。
近年来,随着国内外政府、企业和科研机构越来越重视网络舆情的开发利用,舆情信息源的探测、获取、处理、分析等关键技术取得了较大的发展,各个特定领域的网络舆情分析模型日益完善,依托计算机软件进行网络舆情监测分析已经进入全面实用阶段。
1 网络舆情倾向性分析研究现状
网络舆情倾向性分析研究的历史可以追溯到有了互联网时代就有了网络舆情研究并有相应的协会和组织,代表性的有英国坎特伯雷大学设立的欧洲舆情研究中心、美国的舆情研究协会以及欧盟舆情分析官方网站等;重要的会议和论坛有话题检测与跟踪会议(TDT)、情报检索专业组会议(SIGIR)和文本信息检索会议(TREC)等。
在网络舆情倾向性分析系统研究方面,国内外的公司、大学和研究机构先后开发设计了多种系统,主要包含3种类型:调查问卷型、系统自动分析文本数据型、自动分析网页数据型。调查问卷型主要设计调查软件,其解决方案是通过对调查问卷的收集,利用计算机来自动分析问卷中的信息,最后得出所反映的事件倾向性分析进而给出舆情的热点或焦点问题;系统自动分析文本数据型是指设计一个分析文本数据的软件系统,通过系统分析判断得出其事件的倾向性进而判断出舆情热点或焦点问题;随着网络技术的快速发展,网络上的数据、信息快速增长,网络信息数据发布平台多样,包括网页、论坛、博客、微博、微信及各种APP软件等,更有效和常用的方法是采用通过计算机自动分析互联网上的数据,形成舆情倾向性分析,例如英国Coppola软件公司发布的“感情色彩”软件,通过读取新闻资料并进行资料中相关语义的自动计算和分析,判断所分析的文章中对预先设定的事件的情感倾向是正面的、负面的还是中立的,从而确定其舆情信息;IBM公司研发的话题检测系统的工作原理是基于两次聚类,首先计算两篇新闻报道的相似性,然后把它先放入临时分配的类别子话题簇中,在一定的时间延迟后,观察话题类别是否变化,如果结果不变,再将该新闻报道归入最后所在的类;谷歌公司研制的谷歌趋势(Google Trends)软件,用于分析用户使用谷歌搜索引擎搜索过的关键词并显示该关键词的被关注程度的服务,分析的结果会显示出不同地区对于该关键词关注度的差异等;我们国家的大学和研究院等也先后开展舆情分析研究。总之,自动分析网页数据的网络舆情倾向性分析系统广泛应用于网络舆情倾向性分析实践中[1]。
在网络舆情倾向性分析关键技术研究方面,Martin 提出了一种以语言模型为基础的话题检测方法;以K-mean聚类算法为基础的网络舆情监测算法得到了较多的应用,通过计算相关话题的相似度,再将话题中的关键词进行聚类就可以发现话题的特征表述;使用自然语言处理技术来帮助设计话题检测的统计方法,使得之后话题检测的正确率和追踪的正确率都有很大程度的提高;James Allan 在话题追踪的研究过程中使用了Rocchio算法,在一定程度上减少了进行话题追踪所需要的时间,但其缺点是需要对阈值进行很精确地设置等。
总之,在网络舆情倾向性分析研究方面,学者和工程技术人员做了大量的工作,但随着网络上大数据的产生,网络舆情事件常常以较快的速度爆发,因此各种算法也在不断的优化改进中。
2 网络舆情倾向性聚类分析模型及算法
网络舆情的倾向性分析是了解舆情产生和演化的重要手段,舆情倾向性分析主要是分析内容信息和行为信息,内容信息是网民情绪与态度的直接反映,行为信息是网民情绪与态度的数据反映,二者结合能够有效的表征网络舆情的倾向性和演化过程。其中网络舆情内容信息包括时间、地点、人物、关键词以及内容信息的变化趋势等,行为信息包括信息发表时间,文档数量、评论数、点赞数等内容。经过分析研究和实验,根据聚类分析的特点,使用聚类分析方法判断网络舆情的倾向性、热点和焦点问题取得了较好的效果。
聚类分析(clustering analysis)是依据数据相似度或相异度将数据分群归属到数个聚类的方法,使得同一群内的数据或个体相似程度大,而各群之间的相似程度小。相似度代表个体间的近似或相关程度,相似度越大,表示数据间的关联程度越高,相似度越小,表示数据间的关联程度越低,同一组样本数据根据所选参数不同,特征属性不同,判断准则不同,形成不同的分群结果。因此,利用聚类分析适合于对网络舆情样本数据,通过选择合理的特征属性、判断准则等参数的设置形成网络舆情的倾向性分析结果。 网络舆情倾向性分析模型建立在两个度量参数上,一是距离,二是相似性。
2.1 距离模型
聚类分析(clustering analysis)是依据数据相似度或相异度将数据分群归属到数个聚类的方法,使得同一群内的数据或个体相似程度大,而各群之间的相似程度小。相似度代表个体间的近似或相关程度,相似度越大,表示数据间的关联程度越高,相似度越小,表示数据间的关联程度越低,同一组样本数据根据所选参数不同,特征属性不同,判断准则不同,形成不同的分群结果。因此利用聚类分析适合于对网络舆情样本数据,通过选择合理的特征属性、判断准则等参数的设置形成网络舆情的倾向性分析结果。 网络舆情倾向性分析模型建立在两个度量参数上,一是距离,二是相似性。
距离用来衡量两笔数据或两个个体在一维或多维下的相异程度,距离越大,表示相异越大,反之则越小。距离衡量方式有多种,针对网络舆情倾向性分析的特点,拟采用加权距离(weighted distance)和马氏距离(mahalanobis distance)作为度量模型,其模型如下:
1) 加权距离。加权距离是指当各个变量的重要性不相同时,通过给定不同的相对权重wj进行加权,来衡量变量之间的距离的方法,加权距离的计算如式(1)所示:
(1)
其中:D(y1,y2)表示加权距离,所有加权权重wj总和为1,当权重都相同时,加权距离等价于欧式距离[2]。
2) 马氏距离。当网络变量之间不仅仅有尺度差异,变量间也有相关性时,用马氏距离衡量数据点之间的距离更能反映实际情况,如式(2)所示:
D(y1,y2)=(x1-x2)′S-1(x1-x2)
(2)
其中:D(y1,y2)表示群体间的马氏距离,x1=(x11,x12,…,x1p)与x2=(x21,x22,…,x2p)均为P×1的向量,S为P个变量的共变异矩阵,当变量间没有相关性时(相关系数等于0),并且所有变量的方差都为1时,马氏距离也就是标准化的欧式距离,马氏距离的计算较为复杂,但其优点是可以考虑变数间的相关性。针对网络舆情信息相关性强的特点,马氏距离模型更适合网络舆情话题的分析和预测[2-3]。
2.2 相关系数
相关系数使用两随机变量的变动方向与程度大小来衡量其相关性,是一个变量的相似度测量参数,在网络舆情倾向性分析模型中,由于数据的类型具有一定的连续性,因此拟采用线性相关系数模型,对于V1和V2两个变量,假设有M组数据(x11,x12)(x21,x22),…,(xM1,xM2)则其相关系数O(v1,v2)如式(3)所示:
(3)
相关系数值在-1与1之间,且与单位无关。
2.3 基于时间片的k中心点聚类分析算法
由于网络信息具有不确定性、广泛性和数据量巨大等特点,其舆情的倾向性和演化主题不明显、演化过程不明确,因此通过改进k中心点(k-mediods method)聚类算法,挖掘舆情主题、变化规律及倾向性。k中心点算法使用距离作为衡量数据间的相似度,以聚类中最接近中心位置的数据点作为聚类的中心,研究最小化数据点与聚类中心点的总变异,因此k中心点算法容易去除噪声使之不受异常值的影响,其算法如式(4)所示:
(4)
其中:xik为聚类k中的某一个数据点,xmk为聚类k中最接近中心的数据点,聚类划分的原则是围绕中心划分。
使用k中心点聚类算法实现网络舆情倾向性分析的步骤如下:
步骤1:选取k个具有代表性的数据作为聚类的中心点,在舆情系统中选择聚类中离平均值最近的对象作为中心点;
步骤2:依据距离S(基于加权距离和马氏距离模型进行验证)的远近,将数据分配到最近的聚类中;
步骤3:随机选取一个非聚类中心的数据点y取代任意一个聚类中心点;计算用y取代中心点的聚类代价,即距离改变量S,当S为负数时,以数据y取代原有的聚类中心,形成新的中心点,当该S为正数时,则原有的聚类中心保持不变,不需要替代。
步骤4:重复步骤3,直到k个中心点不再变化为止[2-3]。
k中心点聚类算法的优点是,当数据存在噪声与异常值时,k中心点法能形成较稳定的分群结果,不容易受到异常值的影响而产生偏差,担当数据点与聚类数目增加时,k中心点法的计算成本将大量增加,而对网络舆情数据量的不确定性,当舆情数据量增大时,需改进K中心点聚类算法,其方法是建立基于时间序列的K中心点聚类模型,在时间片上进行数据的分类整合,整合得到的数据代表着这个时间片内的演化主题[4-5]。
假设舆情的原始数据{x1,x2,…,xi},初始化k个随机数据{o1,o2,…,ok},时间为{t0,t1,…,tn}。在一个时间片内根据下列K聚类的两个迭代公式求出最终所有类的聚类中心o,步骤如下:
步骤1:求出时间片内所有数据和初始化的随机数据的距离,找出距离每个初始数据最近的原始数据pi,如式(5)所示:
(5)
步骤2:计算初始数据和最近原始数据的距离,距离计算采用马氏距离;
步骤3:随机选取一个非聚类中心的数据点替代聚类中心点,计算取代聚类中心点的代价,不断迭代,直至oj的大小不再变化为止,如式(6)所示:
(6)
通过上面的算法,提高了聚类的迭代时间效率和查全率,尤其当数据量巨大时,时间效率的提高效果显著。
3 实验结果分析及评估
使用聚类分析方法获得的聚类中心是舆情产生倾向性分析的主要依据,也即是舆情的主题,在时间序列下聚类中心的变化情况代表了舆情的演变。以论坛和微博作为实验数据抽取平台[6],按照时间片进行信息的随机抽取,时间间隔以天为单位,T{T1、T2、T3、T4、T5}表示{第1天、第2天、第3天、第4天、第5天},抽取数据样本数量如表1所示。

表1 抽取数据样本 篇
使用改进的基于时间片的k中心点聚类算法,得到的聚类中心如表2所示。

表2 聚类中心
从聚类结果看,使用k中心点聚类,聚类过程中加入了时间序列,反应出网络舆情演化的倾向性,同时由于使用了时间片,按照时间片再进行聚类的迭代,降低了聚类的维数,增加了聚类的可靠性。同时k值相对集中,在第2和第3天相对较大,表明在舆情发生的第2天和第3天事件关注度及网民讨论程度能达到最高峰。
为了衡量改进的基于时间片的k中心点聚类算法的有效性,使用查全率和时间效率两个指标作为评价标准[7],设网络舆情信息聚类查全率用P表示,P越大表示信息聚类覆盖的越全面,P越小,表示样本聚类覆盖效果越差,与P相关的参数集如下:
P∝P{标题,作者,发布时间,网民数量,发帖数量,跟帖数量、网民数量变化率,发帖数量变化率,持续时间}
网民是事件讨论的主体,统计每个阶段参与事件讨论的网民数量可以评估网民对此事件的参与程度;发帖数量加上跟帖数量反应了网络舆情的热度;网民数量变化率和发帖数量的变化率一定程度上反映了网络舆情的倾向性。
时间效率Q用来衡量舆情信息聚类的效率,Q越大表示聚类成舆情信息越快,更有利于舆情的研判,与Q相关的参数集如下:
Q∝Q{样本数,样本属性,分类数,时间片,主题词,特征值,特征值权重,事件属性}
针对表1和表2中的样本数和聚类中心,设k中心点聚类P和Q均为1作为比较基准,表3列出了采用基于时间片的k中心点聚类的P和Q值。
表3中看出,经过改进的基于时间片的k中心点聚类从每一个时间片上其查全率P和时间效率Q比没有改进时均有提升,当样本数值越大时,时间效率Q提升就越大,在所有的时间段内T1~T5,如果不划分时间片聚类,由于样本数为T1~T5所有样本的和,其时间效率会更低,而通过划分时间片,在每个时间片上聚类,时间效率显著提高。
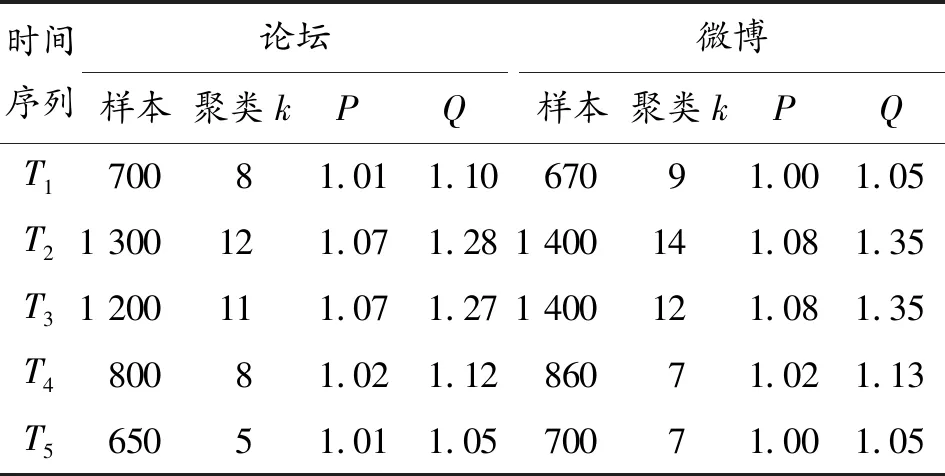
表3 基于时间片的k中心点聚类查全率P和时间效率Q
比较基准为:k中心点的P和Q值均为1。
4 结论
本文提出的基于时间片的k中心点聚类分析算法,提供了网络舆情分析的有效途径,这些方法在开发研制网络舆情系统中得到了很好的应用,取得了较好的效果,今后随着网络平台不断增多,智能手机的广泛应用,网络舆情产生的渠道会越来越广,基于时间片的k中心点聚类分析算法还要进一步的完善,以应用于更多的平台。
猜你喜欢
有色金属(矿山部分)(2021年4期)2021-08-30 06:10:42
电脑报(2020年12期)2020-06-30 19:56:42
电脑报(2019年4期)2019-09-10 07:22:44
中国民政(2016年16期)2016-09-19 02:16:48
中国民政(2016年10期)2016-06-05 09:04:16
中国民政(2016年24期)2016-02-11 03:34:38
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
新闻研究导刊(2015年17期)2015-12-25 12:36:42
大众摄影(2015年9期)2015-09-06 17:05:41
语言与翻译(2015年4期)2015-07-18 11:07:43
