
个人贷款违约预测模型研究
2019-07-03 09:42冯宁
现代商贸工业 2019年17期
关键词:违约
冯宁


摘 要:随着全球经济的快速发展以及资本市场的垄断,无论是企业的发展还是人们超前消费观念的提前到来,贷款已成为企业和个人解决经济问题的一种重要手段。对于银行业或者小贷机构而言,信用卡以及信贷服务是高风险和高收益的业务,如何通过用户的海量数据挖掘出用户潜在的信息即信用評分,并参与审批业务的决策从而提高了风险防控措施,该过程不仅提高了业务的审批效率而且给予了关键的决策,同时风险防控如果没有监测到位,对于银行业来说会造成不可估量的损失,因此这部分的工作是至关重要的。通过某银行脱敏的信用卡客户数据,通过建立现阶段比较热门的机器学习Logistic模型来研究客户信用的关键指标对模型的作用,从而对信用卡用户的违约情况进行提前预测分析。个人贷款违约预测模型的建立以及后期的关键指标的探索,在银行业或者小贷机构的贷前审批以及贷中的管理决策中都有很好的指导作用,并且具有很强的实践性和意义。
关键词:python;Logistic模型;违约
中图分类号:D9 文献标识码:A doi:10.19311/j.cnki.1672-3198.2019.17.080
1 引言
本文建立个人贷款违约预测模型的目的是利用银行脱敏的数据进行描述性统计分析,来提前预测客户在贷款期间的违约概率,从而帮助银行的业务人员明确客户的更多有意义的指标变量,及早发现贷款的潜在损失。本章主要对项目的背景与选题来源,国内外发展状况,以及研究意义和目的,相关研究成果进行大致说明,并讨论了创新点。
1.1 项目背景与选题来源
目前,在经济快速发展的时代,贷款的风险审批是商业银行面临的首要问题。贷款中风险的产生,不仅在贷款审查阶段出现,而且贯穿整个贷款流程中:在实际贷款审批流程中,大多数的审贷过程并非十分严谨和周全,因此不良贷款的概率会日渐飙升,在这样的背景下,建立一个科学有效、有解释力度的模型对贷款客户的信用进行评估与判定,从而将违约的风险降到最低并将利润最大化是刻不容缓的事情。对信用风险的识别与防控是商业银行风险管理研究的重要内容,是金融机构不可回避的核心问题,也是各国政府与金融机构风险管理的焦点。因此,为了更好解决风险管理中的问题,本文涉及的数据包含银行客户的交易数据,而且涉及大部分贷款信息与众多信用卡的数据,通过分析这些数据可以获取与银行服务相关的业务知识,例如,提供增值服务的银行客户经理,希望明确客户有更多的业务需求,而风险管理的业务人员可以及早发现贷款的潜在损失。
1.2 国内外发展现状
21世纪大数据信息和互联网金融得到了前所未有的巨大发展,个人消费经济市场空间也得到了拓展,与此同时,人们提前消费经济观念的转变导致全球个人信贷规模急剧扩大,我国的一些大城市居民债务比率已经达到甚至超过美国等发达国家的平均水平,为有效应对这一趋势的发展,我国已经采取措施对商业银行加强信用风险管理,并改进管理技术。截至2006年底我国已经全面实现了金融业对外开放,面对全球的激烈竞争,我国若想要保住全球的经济地位并使之发扬壮大,需要自身依靠内部评级体系的建设和发展。然而近几年,我国涌现出了很多研究数据科学的高端人才,对于模型的建立和探索已经在国内外取得了不小的成就,在未来的数据科学以及商业应用中,预测模型也会应用到我们生活中的方方面面,并且会得到空前的发展和巨大的进步。
1.3 本论文的创新点
相较于传统模型而言,本文采用了机器学习中的逻辑回归模型(logistic regression),该模型是基于现阶段国内外发展状况和项目背景以及相关业务场景的探索研究,该模型属于概率型非线性回归模型,它是研究二分类观察结果(被解释变量)与一些影响因素(解释变量)之间关系的一种多变量分析方法。如果用线性回归分析,由于应变量Y是一个二值变量(通常取值1或0),不满足应用条件,尤其当各因素都处于低水平或高水平时,预测值Y值可能超出0~1范围,出现不合理都现象。用logistic回归分析则可以较好的解决上述问题。
2 相关技术介绍
数据科学是一个发现和解释数据中的模式,并用于解决问题的过程。
2.1 数据科学过程
数据科学中的过程,主要分为以下几个步骤:相关数据和主题结合生成信息,信息通过规则的加工生成知识,知识通过业务经验的丰富生成相关管理人员的决策和行动,这些步骤在业务场景中的流程如图1所示。
2.2 模型的实际应用过程
分析建模人员通过分析数据建立模型,在该过程中主要是找出隐藏在数据背后的模式,这些模式能把数据转化为知识,而这些已发现的知识就是我们所谓的模型,业务人员把模型用在实际数据上,从而预测未来的行为,在这个过程中主要是部署,即应用已发现的知识达成实用的目的。
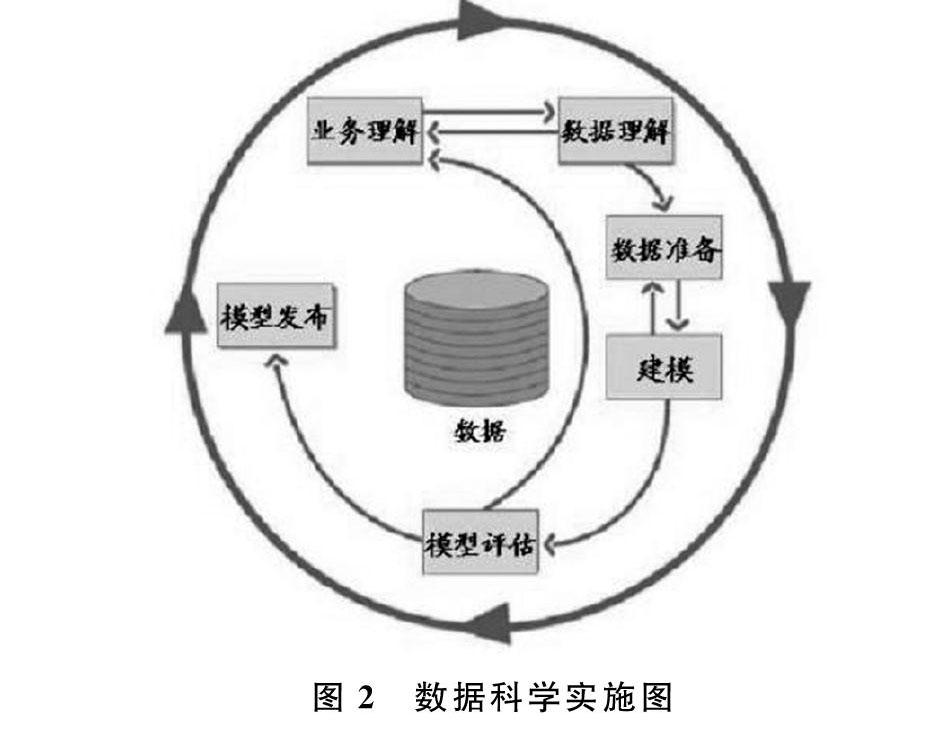
2.3 数据科学实施路线图
在数据科学中,数据挖掘的实施路线图贯穿整个数据建过程中,如图2所示为数据科学实施路线图。
3 个人贷款违约预测模型的创新点介绍
个人贷款违约预测模型的建立包括:业务理解、数据获取、数据清洗与处理、数据建模等过程,每个过程的创新点在后面会展开讨论。
3.1 业务理解
业务理解是数据建模中关键的环节,若业务理解不到位则直接关系到业务目标的偏离,从而导致最后的模型预测不准确,不仅浪费较长的时间人力成本,而且会对公司的经营状况造成巨大的损失,因此好的业务理解对数据建模起到关键性的作用。
本文涉及的数据业务是在银行场景下进行个人客户业务分析和数据挖掘进行的,笔者希望明确哪些客户有更多的业务需求,而风险管理的业务人员可以及早发现贷款的潜在损失,那么根据客户的贷款属性、交易信息、状态信息怎样预测客户的贷款违约行为呢?这是本文需要重点探索的问题。
而拆分这些数据的指标,我们可以分为三大类:属性、状态、行为信息,而这三大类指标对建模的特征变量的筛选有重要的指导意义。整理这些变量通常会与两个指标变量息息相关-还款意愿和还款能力指标,而在贷款审批前业务人员会重点关注其还款意愿情况,若客户得到的收益高于成本,则客户的还款意愿不足,从而导致违约;在贷款后业务人员会关注客户还款能力情况,若客户的经济条件恶化,从而导致违约,而还款能力不足包括欲望大于能力,生活状态不稳定等情况。而描述这些还款指标的变量基本都是衍生变量,而这些衍生变量分为:
一级衍生变量,比如资产余额;二级衍生变量,比如资产余额的波动率、平均资产余额;三级衍生变量,比如资产余额的变异系数等。因此在接下来的章节中将详细阐述这些变量提取的过程。
3.2 数据获取
本案例的数据来自一家银行的真实客户与交易数据,设计客户主记录、账号、交易、业务和信用卡、地区等数据,下面分别介绍这几张数据库表的重要字段。
贷款表(Loans):该表记录每个账户上的一条贷款信息,包括以下字段:权限号(disp_id)、贷款号(loan_id)、账户号(accout_id)、发放贷款日期(date)、贷款金额(amount)、贷款期限(duration)、每月归还额(payments)、还款状态(status)。其中还款状态A代表合同终止,没问题;B代表合同终止,贷款没有支付;C代表合同处于执行期,至今正常;D代表合同处于执行期,欠债状态。
账户表(Account):该表记录账户相关信息,包括以下字段:账户号(account_id)、开户分行地区号(district_id)、开户日期(date)、结算频度(frequency)。
客户信息表(Clients):该表记录客户的基础属性相关信息,包括以下字段:客户号(client_id)、性别(sex)、出身日期(birth_date)、地区号(district_id)。
权限分配表(Disp):该表每条记录描述了客户和账户之间的关系,以及客户操作账户的权限,包括以下字段:权限设置号(disp_id)、客户号(client_id)、账户号(account_id)、权限类型(type)。其中权限类型字段中只有“所有者”身份可以进行增殖业务操作和贷款。
支付命令表(Orders):该表每条记录描述了一个支付命令,包括以下字段:订单号(order_id)、发起订单的账单号(account_id)、收款银行(bank_to)、收款客户号(account_to)、欠款金额(amount)等。
交易表(Trans):该表每条记录代表每个账户上的一条记录,包括以下字段:交易序号(trans_id)、发起交易的账户号(account_id)、交易日期(date)、借贷类型(type)、交易类型(operation)、欠款金额(amount)、账户余额(balance)等。
信用卡表(Cards):该表每条记录描述了一个账户上的信用卡信息,包括以下字段:信用卡ID(card_id)、账户权限号(disp_id)、卡类型(type)、issued(发卡信息)。
人口地区统计表(District):该表记录描述了一个地区的人口统计学信息,包括以下字段:地区号(A1)、GDP总量(GDP)等。
其中各表与表之间的联系即E-R图如图3所示。
3.3 数据清洗与处理
数据清洗与处理是数据建模中重要环节,如果源数据不经过处理以及处理不够精确,则会直接影响模型的预测准确度。本小节主要介绍该案例背后的数据处理的相关过程以及代码实现的小细节。
(1)首先需要对贷款违约预测模型的被解释变量Y值定义违约和非违约的状态,通过数据获取章节中的贷款表可知,状态为B和D为违约状态,C为未知状态,D为正常状态,因此对贷款表新增解释变量Y值字段bad_good,实现的相关代码如下:
Loans[‘bad_good] = loans.status.map({"B":1,"D":1,"C":0,"A":2})
(2)由于貸款信息需要知道详细贷款人的基础属性信息,因此需要将loans表和用户clients表进行连接,但是中间需要权限表disp表建立中间桥梁进行连接,并且只有权限为“所有者”的用户才能操作所有相关的表:
df = pd.merge(loans,disp,on="account_id",how="left")
df = pd.merge(df,clients,on="client_id",how="left")
df = df[df.type==”所有者”]
(3)由于对取数的时间有要求,因此需要对现有的时间格式进行转换,方便后续计算:
df2["date"] = pd.to_datetime(df2["date"])
df2["date_trans"] = pd.to_datetime(df2["date_trans"])
(4)对于动态数据,其观察期的取数窗口的规则是交易日期在贷款日期之前,并且交易日期在贷款日期前一年的时间内:
import datetime
df3=df2[df2.date-datetime.timedelta(days=365) [df2.date_trans (5)由于账户余额和贷款金额为无法正确计算的字符串,需要对字符串进行清洗处理得到数值形式,对于每个账户的交易类型,有两种情况,‘借代表支出,‘贷代表收入,需要将收入和支出标准化,方便后续计算: df2["amount1"]=df2["amount"].map(lambdax:int("".join(x[1:].split(",")))) df2["balance1"]=df2["balance"].map(lambdax:int("".join(x[1:].split(",")))) 3.4 数据建模 数据建模是模型建立的最后一个环节,该过程包括数据特征变量的筛选和模型的选取。 3.4.1 特征变量的选取 (1)账户余额的变异系数:账户的平均余额/账户的标准差。 df4=df3.groupby("account_id")["balance1"].agg(["mean","std"]) .reset_index() df4["cv_balance"] = df4.apply(lambda x:x[2]/x[1],axis=1) (2)账户的平均收入和平均支出: df5=df3.groupby(["account_id","type1"]).balance1.sum().unstack() .reset_index().fillna(0) df5["r_out_in"] = df5.apply(lambda x:x[2]/x[1],axis=1) (3)贷存比和贷收比:贷存比=贷款总额/平均余额、贷收比=贷款总额/总收入 df6 = pd.merge(df1,df4,on="account_id",how="left") df7 = pd.merge(df6,df5,on="account_id",how="left") df7["r_lb"] = df7[["amount","avg_balance"]].apply(lambdax: x[0]/x[1],axis=1) df7["r_lincome"] = df7[["amount","income"]].apply(lambdax: x[0]/x[1],axis=1) 3.4.2 模型的选取 由于被解释变量是二分类变量,因此模型选取该业务场景下常用的模型-逻辑回归模型(Logit Regression)。而用于预测模型的训练集和测试集都是从贷款表中的状态类型进行筛选的,其中训练集和测试集从状态为C的情况下选取的,训练集随机选取几何的07,测试集为0.3。使用了逻辑回归的向前逐步法模型直接调用逻辑回归的函数,代码如下所示: fpr,tpr,th = metrics.roc_curve(test.bad_good,lg_m1.predict(test)) plt.figure(figsize=[6,6]) plt.plot(fpr,tpr,'b--') plt.title('ROC curve') plt.show() print('AUC = %.4f' %metrics.auc(fpr,tpr)) for_predict['prob']=lg_m1.predict(for_predict) for_predict[['account_id','prob']].head() 最后生成的是ROC曲线,求得的AUC为0.8780。曲线如图4所示。 4 总结 本论文通过对案例的数据进行一系列的分析和挖掘得到比较精准的模型,并且已在实际的业务场景中进行了测试和监控,最后的反馈结果都得到了非常不错的效果,在未来的日子里,笔者也会继续探索相关的机器学习模型,例如决策树、组合算法等模型,通过这些模型的比较看能否得到更符合业务场景并且相对精准的模型。 参考文献 [1]舒扬,杨秋怡.基于大样本数据模型的汽车贷款违约预测研究[J].管理评论,2017,29(09):59-71. [2]王粟旸.商业银行小微企业违约风险管控及违约概率估计模型研究[D].南京:南京大学,2014. [3]章宁,陈钦.基于TF-IDF算法的P2P貸款违约预测模型[J].计算机应用,2018,38(10):3042-3047. [4]朱伟义,乔琳霏.基于多维特征逻辑回归识别模型的排队监测方法[J].电气自动化,2018,40(06):94-97. [5]李佳,黄之豪.银行信用风险预测——基于SVM和BP神经网络的比较研究[J].上海立信会计金融学院学报,2018,(06):40-48. [6]姚兰兰.浅析商业银行信用风险管理存在的问题与对策[J].现代商业,2018,(31):84-85. [7]金美子.我国商业银行信用风险管理存在的问题及监管对策[J].现代商业,2018,(28):73-74.
