
BP神经网络车牌识别技术优化研究
2019-06-27 05:50:28杨洪臣蔡能斌王华鹏翟金良
中国刑警学院学报 2019年3期
杨洪臣 党 京 蔡能斌 王华鹏 翟金良
(1 中国刑事警察学院声像资料检验技术系 辽宁 沈阳 110035;2 上海市现场物证重点实验室 上海 200083)
1 引言
随着信息技术的不断发展、监控摄像头硬件布局的逐步完善及公安图像云计算技术的进一步应用,视频监控所获取到的时空轨迹信息在案件侦破工作中发挥着越来越重要的作用,如何高效的利用城市监控卡口网络维护城市安全成为公安机关十分关注的问题[1]。通过道路摄像头及交通卡口的视频内容快速识别,追踪嫌疑车辆可以提高侦查效率,因此如何保证车牌识别的高速性和准确性成为了其中的研究热点。当前车牌识别系统常用的字符识别方法有模板匹配、支持向量机和神经网络等等,每种方法都有各自的优势及存在的局限性。模板匹配对字符倾斜变形、背景复杂和存在污损情况的车牌识别精度不足。支持向量机对车牌倾斜、大小、颜色甚至照明条件影响具有较强的鲁棒性,但经常因为支持向量集过大,使得识别时间较长[2]。借助车牌颜色特征的字符识别方法存在对光照亮度的敏感性。神经网络法因其具备良好的学习能力、容错能力和强大的分类能力,引起了越来越多人的注意,但由于收敛性和收敛速度的矛盾,使其无法满足实际工作中对于车辆识别系统精准性和实时性的需求。为此,本文将从特征数据降维及神经网络参数调整等字符识别改进的层面,对BP神经网络车牌识别方法的优化进行探讨。
2 基于Gabor滤波特征提取的BP神经网络车牌识别
本质上来说,所有的车牌识别系统都有着一个相同的流程,分为车牌图像获取、图像预处理、车牌定位、车牌字符分割及车牌字符识别5个步骤。车牌识别方法具体流程如图1所示。
2.1 车牌图像的预处理、车牌定位及字符分割
2.1.1 车牌图像的预处理
车牌图像的预处理主要包括图像灰度化、图像边缘检测、图像二值化及滤波去噪等步骤。
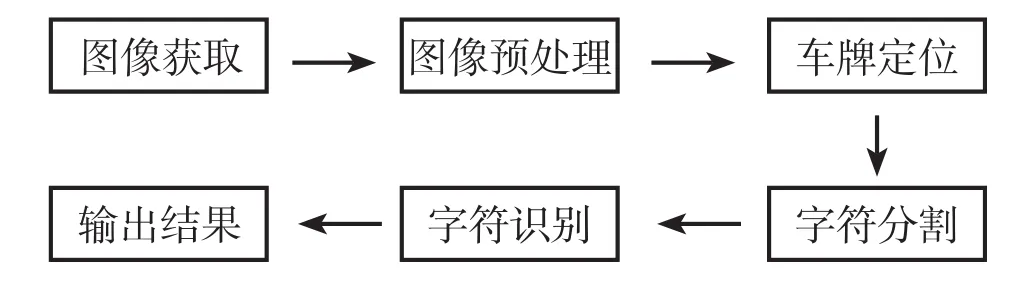
图1 车牌识别的完整过程
现实生活中,车牌图像多是通过设置于停车场和天桥等地的摄像头和卡口拍摄获取的,得到的多为彩色图像,基于识别系统的运行条件,为降低图像原始数据量,减少后续处理图像时的计算工作,要求对获取的原始图像进行灰度化处理。一般将灰度范围量化在(0,255)之间,可以使图像的对比度和分辨率加强,使图像呈现出来的效果更加清晰[3]。
图像边缘是原始图像中灰度急剧变化的区域边界,边缘检测通过检测图像中不同区域的边缘来达成分割图像的目的,是图像分析和理解的第一步。常用的边缘检测算子有Roberts、Sobel、Canny和LOG算子等。由于Sobel算子对于灰度渐变和噪声较多图像的处理效果较为理想,使得图像中部分噪声滤除的同时达到削弱背景区域的目的,可以提供精准度较高的图像边缘信息,故本文系统使用Sobel算子进行检测。
二值化的目的是通过调整阈值,将车牌字符信息与背景信息划分开,提取有效信息。随后利用均值滤波将多余噪声去除。二值化和降噪这两步的质量将对后期图像中定位牌照位置和分割处理字符的效果有着直接影响。
2.1.2 车牌定位
车牌定位的主要目标在于将图像带有字符的牌照部分,从有干扰背景的图像部分中有效分离,常用方法为形态学定位法。对二值化后的图像进行开运算、闭运算和移除小对象等步骤来突出车牌的连通区域,根据牌照的矩形宽度和高度分离出正确的车牌区域。依据坐标记录牌照区域在原图中的位置,即可在原图中得到定位的车牌部分图像。
2.1.3 字符分割
字符分割是将定位后得到的带有字符的车牌图像分割为单字字符图像的步骤。完成车牌区域的定位后,经过图像水平和垂直方向的矫正和图像预处理,将车牌图像分割为单字字符图像。此步骤最为常用的方法为垂直投影法。字符垂直方向上投影的局部最小值处,势必处于牌照单字字符的两侧或者单字字符之中,此外这个位置也必然满足车牌的字符书写格式、字符、尺寸限制等其他制式规格条件。使用垂直投影法对复杂环境下的汽车图像中字符图像分割有着较为良好的效果。通过上述步骤得到的车牌字符可能大小各异,为使车牌识别的准确率提高,需要再对分割处理后的字符尺寸进行大小归一整定。
2.2 基于Gabor滤波特征提取的BP神经网络字符识别
字符识别主要由特征提取和分类器这两部分组成。由于Gabor滤波提取的特征对颜色变化具有较强的鲁棒性,而BP神经网络具有良好的学习机制、快速的分类方式和较强的容错能力,在面对较为复杂情况的干扰时,有着较高的识别速度和准确性。
2.2.1 Gabor滤波器提取特征
Gabor变换是一种短时傅里叶变换方法,其实质是在傅里叶变换中加入一个窗函数,通过窗函数来实现信号的时频分析。当使用高斯函数作为窗函数时,短时傅里叶变换称为Gabor变换[4]。将Gabor小波扩展到2维,可得到Gabor 滤波器(图像实际上就是一种2维信号):

可以分为实部与虚部的形式:

其中

式(1)为Gabor滤波器的公式化定义,可将其分为式(2)和式(3)的实部与虚部形式,其中λ为正弦函数波长;θ为Gabor核函数的方向;ψ为相位偏移;σ是高斯函数的标准差;γ是空间的宽高比。
相较于其他不同方法,Gabor小波变换有其突出优势:①这一方法处理的数据规模小,能够满足实时系统研究需求。②小波变换对光照变化不敏感如图2~3所示,解决了浅层网络和基于颜色特征识别方法对光线敏感的问题。③对于图像变形和旋转有一定容忍度,欧氏距离下的识别过程,特征模式与待测特征不必严格的对应,有益于系统整体鲁棒性的提高。上述特点使得Gabor滤波应用于车牌特征提取有着得天独厚的优势。
2.2.2 BP网络模型及其局限

图2 亮度较高条件下的“京”幅值及相位谱

图3 亮度较低条件下的“京”幅值及相位谱
BP人工神经网络是一种多层前馈神经网络,由输入层、隐含层、输出层3部分组成如图4所示[5],是基于梯度下降算法的反向传播神经网络,目标函数是误差的平方,在参数众多,结构复杂的函数关系下,通过精细化误差来逼近函数关系,有简单、易行、计算量小、并行性强等优点,是具有很强的非线性映射能力和柔性的网络结构。由于BP算法采用非线性规划中的最速下降方法[6],按误差函数的负梯度方向修改权值,因而通常存在以下局限:
(1)学习效率低,收敛速度慢。
(2)训练过程易陷入局部极值,需多次训练。
(3)网络层数、神经元个数的选择没有相应的理论指导。
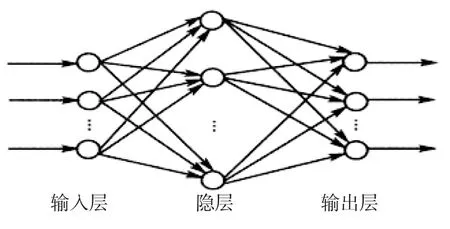
图4 全连接形式的的神经网络
受限于图像获取时拍照设备的成像质量,为了满足系统实时性和准确性的需求,除了优化网络输入的数据质量,在防止过拟合和增强系统稳定性的同时,对网络参数的优化显得尤为重要。目前对BP神经网络的优化主要从两个层面进行:①加快网络收敛速度。②防止陷入局部极小值。
3 BP神经网络字符识别优化及实现
3.1 优化的字符识别流程图
车牌识别的不同步骤功能各异,均与最终所得结果及整个系统的效率有直接关系。本文主要对字符识别部分进行优化,优化后的字符识别流程如图5所示。
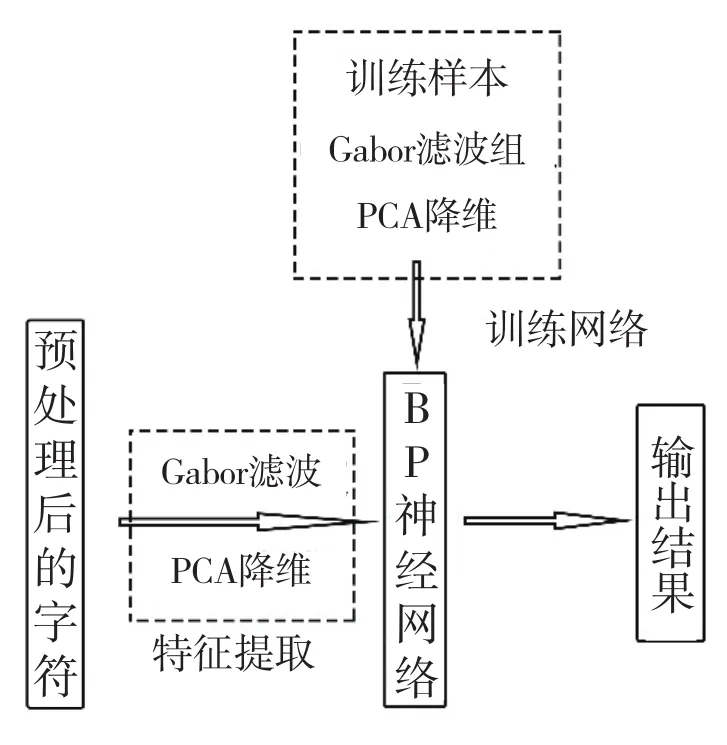
图5 本文字符识别流程图
3.2 字符识别优化方案
为了保证实验过程的流畅性及实验结果的准确性,本实验在Intel i7-5500 CPU,8G内存,64位Microsoft Windows 7操作系统的计算机上运行,使用Matlab 2018a作为实验的仿真平台。实验所用样本均为生活中的真实车牌图像。
为简化实验条件,训练样本为部分经过预处理、定位及分割处理所得到的车牌单字字符图像:10个数字,24个字母和5个汉字(川、京、苏、陕和湘)。总共39类字符,每类字符选取50张PNG格式的灰度字符图像,共1950张。测试样本为图像条件较恶劣情况下的川、京、苏、陕和湘字开头的车牌图像共300 张。
3.2.1 主成分分析法(PCA)对特征降维
由于Gabor变换中的小波基函数往往不正交,所以大量信息线性相关,Gabor变换处理所得到的信息是冗余的,需要对数据进行降维,简化了提取数据的同时也节省了计算资源,为之后缩短网络的训练时间做准备。选用PCA进行降维的优点是,它是完全无参数限制的,避免了因为经验性的参数设置而得不到预期效果的问题。
3.2.2 附加动量项
附加动量项是一种加快梯度下降法收敛的优化方法,使网络在修正其权值时,不仅考虑误差在梯度上的作用,还考虑在误差曲面上变化趋势的影响,减少学习过程中产生的震荡,加快网络收敛速度,降低对于误差曲面局部细节的敏感性[7]。核心思想为:在梯度下降搜索过程中,若当前时刻梯度下降方向与上一时刻梯度下降的方向相同,则加快搜索速度,反之则减速。
标准BP算法的权值变化量:

添加动量项之后,基于梯度下降的权值变化量为:

由式(4),式(5)可以得到改进后的公式:

其中,Δω(t)为第t次迭代的权值变化量,η是学习率,g(t)为第t次迭代所计算出的负梯度,ω(t)为权值向量。μ为动量因子,取值范围在0-1之间,式(7)为其数学表达式:

3.2.3 自适应学习率
学习率通常会被设定为一个固定的常数,针对特定问题,通常很难选取到合适的学习率。学习率过大可能出现超调现象,使得函数无法收敛,学习率过小,则会对收敛速度造成影响,造成了收敛速度和收敛性的矛盾。为此,本文采用自适应学习率,如式(8)所示:

采用该优化后的算法可以获得较优的学习率,确保网络得到相对较快收敛速度的同时,部分防止出现局部极小值的情况,促进系统的稳定性,使得系统识别效率进一步提高。
3.2.4 从激活函数角度优化网络性能
通常BP神经网络采用Sigmoid函数作为其神经元激活函数,输出为0到1之间的连续量,通过S型函数可以实现从输入到输出任意的非线性映射[8]。相对于sigmoid函数和,使用tanh函数的输出区间是在(-1,1)之间,而且整个函数是以0为对称中心的,由于它的输出均值是0,使得tanh相较于sigmoid函数权重更新效率更高,以此提高了网络的收敛速度,减少迭代次数。由于采用PCA对数据进行降维,降维后数据的特点使得tanh函数比目前较为流行的relu函数对网络学习的效率更高。
3.2.5 初始权重的选择
与输入和输出的道理相同,过大的初始权重将会在偏置方向上偏置激活函数,使激活函数饱和,从而降低网络更好学习权重的能力,因此应该避免大的初始权重值。假设某个节点的传入链接增多,则会有越多的信号被叠加在一起,因此如果链接更多,那么减小权重取值的范围就会从一定的层面防止了激活函数的饱和。本文将遵循数学家总结得到的经验规则:初始权重在一个节点传入链接数量平方根倒数的大致范围内随机采样。
3.2.6 网络层数和隐藏层节点个数的确定
网络构建过程中,隐藏层和节点数量选取并无明确的理论指导。在隐藏层和隐藏层节点足量的情况下可以逼近任意函数的非线性关系,虽然能保证训练精度但也会需要更多的计算时间。
根据已有理论证明:只有一个隐含层的3层BP网络就能够精确地实现非线性函数的逼近。为使得计算工作减少,确保运行速度更快,所以本文系统采用3层网络。
隐藏层节点数量对于网络性能有着严重的影响效果。隐藏节点太少,那么映射容量也会随之变少,导致训练精度不足。隐藏节点个数太多,虽然网络学习能力强,但网络所需学习时间也将增多,同时也是过拟合现象的潜在成因。为了在减少训练时间的同时,防止过拟合现象的发生,本文将依据经验公式(9)确定隐藏层节点个数H,其中m为输入层节点个数,n为输出层节点个数。最终选定隐藏层节点为7个。

3.3 实验结果
实验结果如表所示。在图像条件较为恶劣的情况下,优化后BP算法的车牌识别率相较于模板匹配法和优化前BP算法有了较为显著的提高,并且由实验过程可以看出本算法使得系统鲁棒性增强的同时,识别速度和识别精度也有了较为显著的提升。本文算法效果如图6~7所示。
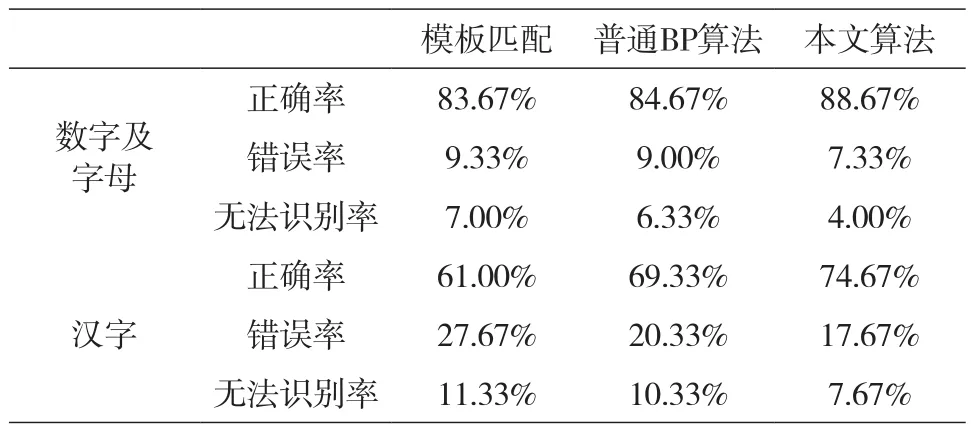
表 各种识别算法识别率

图6 车牌号为苏*MB936络

图7 车牌号为**B5178
4 结语
本文提出的优化算法运用Gabor滤波对字符进行特征提取并降维,较好地解决了光照条件变化大及欧氏距离内图像的变形和旋转对于识别系统的影响。通过添加动量项及使用自适应学习率等方法对BP神经网络进行优化,较好的解决了系统收敛速度和收敛性的矛盾。经过实验,算法使得系统能在图像条件较差的情况下对部分车牌文字、字母及数字进行识别,相对于其他识别算法,从识别精度、识别速度及鲁棒性有了较好的提升,说明了该算法的有效性,对于其他未涉及的复杂情况的识别效果有待进行考证。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
电子制作(2019年12期)2019-07-16 08:45:16
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
成都信息工程大学学报(2017年3期)2017-11-09 02:56:12
小猕猴智力画刊(2017年5期)2017-05-25 21:44:09
电子制作(2017年22期)2017-02-02 07:10:11
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:38
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:29
