
通过CWLS−DL优化St−OMP 算法的盲信号重构
2019-06-24 02:56郭凌飞张林波
应用科技 2019年3期
郭凌飞,张林波
哈尔滨工程大学信息与通信工程学院,黑龙江哈尔滨150001
压缩感知(compressive sensing,CS)已是当前信号处理领域中的一个重要理论,相关的信号重构算法更是备受国内外众多学者的关注。相比于传统的信号采样,具有采样频率低、耗时少、压缩占有空间小等一系列优势[1−3]。压缩感知理论中有3个重点问题,分别为学习字典设计、观测矩阵构造和信号重构算法[4],每一个问题都对信号重构起着重要的作用。
本文利用压缩感知模型和欠定盲源分离模型的等效性,研究了压缩感知在欠定盲源分离中的源信号重构问题,并针对学习字典设计与重构算法的某些缺陷进行改进。首先,提出相关性加权最小二乘字典学习方法,与K−SVD字典学习方法相比,具有超线性收敛速度,提高了字典的学习效率,并有助于信号重构质量的提高[5]。然后,利用分段正交匹配追踪算法来重构源信号。接着,将字典学习法与信号重构算法结合,可在算法复杂度与重构精度上,实现更好的折中。最后通过实验仿真分析证明,压缩感知可以较高的精度实现源信号的精确分离。
1 压缩感知问题描述
1.1 盲源分离与压缩感知等效模型
在无噪声条件下,盲源分离混合系统的数学表达式为:

将式(1)转换成式(2)的矩阵相乘形式:

假设系统中的信号均为离散实值信号,且采样点数均为 T ,此时 X(t)为 M×T维的观测信号,S(t)为 N×T 维的源信号,A为混合矩阵。
压缩感知系统模型的数学表达式为:

同样转换成式(4)的矩阵相乘形式:
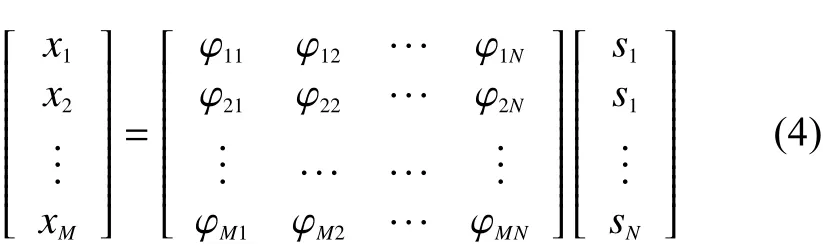
式中: X 与 S 均 为一维信号, X 为长度 M的压缩信号;S 为 长度 N 的原始信号; Φ为观测矩阵。其中的信号 S可以表示 S=ΨB,Ψ 为正交稀疏矩阵(字典), B为稀疏系数向量。同时 S也可表示为一组共 N维正交稀疏矩阵与稀疏系数的线性组合,表示形式如式(5):

综合上面的表达形式,压缩感知系统模型的数学表达式改写为式(6)的形式:

令 Γ=ΦΨ ,Γ为感知矩阵。
对比这2种模型,可以发现表达形式很相近。为了结合这2种模型,将式(2)中的 X(t)和S(t)写成一维向量形式[6],得到:

套用观测矩阵的格式,将混合矩阵 A的元素融合进观测矩阵 Φ, 使得 Φ中 的元素 φij成 为 Φ的子矩阵,每一个都是对角矩阵,如式(9)所示。这样一来,将式(7)~(9)结合在一起,使得式(3)有一种新的表达形式,即将压缩感知模型与欠定盲源分离模型结合起来。

此时 X∈RMT×1, S∈RNT×1, Φ ∈RMT×NT。
1.2 压缩感知盲源分离主要内容
利用压缩感知理论完成源信号重构的基本内容有3个:字典学习方法、观测矩阵构造、信号重构算法。
1.2.1 字典学习
将源信号作为学习信号,根据源信号的先验知识并运用学习方法,得到稀疏字典,常见的有最优方向法、K−奇异值分解(K−SVD)算法等[7]。本文采用一种改进的加权最小二乘算法,进行字典学习,该算法可根据信号内部信息,提高信号重构精度。
1.2.2 观测矩阵构造
将欠定盲源分离的数学模型转换成压缩感知的数学模型,将混合矩阵转化为压缩感知中的测量矩阵。可按照1.1节内容实现。
1.2.3 重构算法
压缩感知重构算法有很多,一类算法为凸优化算法,例如基追踪(base pursuit,BP)算法等;另一类算法为贪婪追踪算法,例如正交匹配追踪(orthogonal matching pursuit,OMP)算法、互补匹配追踪(complementary matching pursuit,CMP)算法等[8]。本文重点研究贪婪追踪算法中OMP算法的改进算法,求出信号的稀疏系数。最后实现源信号的重构,解决欠定盲源信号的分离问题。
2 压缩感知盲源分离算法
2.1 CWLS-DL方法
本文采用一种名为含相关性的加权最小二乘字典学习(correlation-based weighted least square–dictionary learning,CWLS−DL)方法,它是一种能充分挖掘信号内部相关性特征的字典学习方法,能够提高过完备字典在压缩感知中的信号重构精度。
首先,给出原始的训练样本,如式(10)所示。

训 练 字 典 为 D=[d1,d2,···,dN]。 在 这 里 将si(t)与 di分 别称为第i个 子训练样本和第i个子训练字典。同理,给出稀疏系数矩阵,如式(11)所示。

式中: bi(t)为 第i个 子稀疏系数向量, t=1,2,···,T,为书写方便,后面将变量t省略。训练字典的初值一般是从训练样本中选取得到[9]。
然后,进行字典学习阶段,分为稀疏编码和字典更新2个环节[10]。稀疏编码,先将子训练字典固定,基于选定的匹配追踪(matching pursuit,MP)算法,求出子稀疏系数向量。字典更新,固定已求出的子稀疏系数向量,使用加权最小二乘法算法更新子训练字典。
下面给出利用加权最小二乘法,得到训练字典更新公式的简要推导过程。在字典更新中,要解决带权重的重构信号与输入信号误差的F−范数最小化问题,也就是式(12)与(13)所表示的关系:

式中: W0为 误差加权矩阵; K0为大于零的常数;且函数 f(di)满足式(14)中的关系:

式中
对函数 f(di)求 偏导数并令 ∂f(di)/∂di=0,计算后得到字典迭代公式为:

式(15)表示为N组方程组,将式(15)的结果带入式(16),计算误差矩阵 R,计算式为
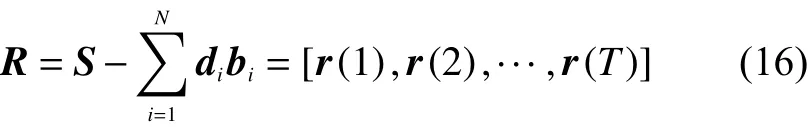
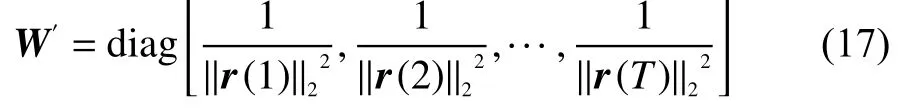
式中 为一个 维的对角矩阵。
所以, W′的初始化过程为:从 S 中随机选取样本得到D的初值,将D的初值与S代入到匹配追踪算法中,得到稀疏系数矩阵B,再根据式(16)计算得到R,最后将R中的元素代入到式(17)中求得权重矩阵 W′的初值。
得到权重矩阵 W′的初值后,将赋值 W=W′,并代回到式(15)中,不断重复直至字典D收敛,并到达正交且接近稀疏为止,记此时,得到的字典 D′就是要求的正交稀疏矩阵Ψ ,如式(18)所示,其中有 d′i=ψi。

2.2 分段正交匹配追踪算法
分段正交匹配追踪(Stage wise-OMP,St-OMP)算法是OMP的一种改进算法,也是压缩感知理论中的核心[11]。St-OMP算法在OMP算法基础上,增加了单次迭代选择的原子数,并且不受到信号稀疏度的影响,相比于OMP算法和其他改进的OMP算法,有独特优势。
2.2.1 算法涉及到的变量与成分
输入成分:

输出成分:
1)稀疏系数向量估计值:Bˆ。
2)残差: rS
其他变量:
1)迭代次数:t 。
2)每次迭代找到的索引(列序号): J0。3)t次迭代索引(列序号)集合:Λt。
4) Γ的 第 j 列: γj。
5)按 Λt选出的矩阵 Γ 的列集合:Γt。
1)将参数初始化
2)计算 u并 选择 u中大于门限的TTh值,将计算出的值对应 Γt的列序号构成集合 J0( 1⩽j⩽N),u的计算式如式(19):

3)按式(20)进行集合并运算,若 Λt=Λt-1(即没有新列被选中),则停止迭代,进入步骤7);

6)迭代次数增加,即 t=t+1。 若 t⩽S,则返回步骤2)继续执行;若 t>S或 残差 rt=0,停止迭代,进入步骤7)。
7)得到最终的 Bˆ后,再乘上前面得到的字典Ψ,可重构信号 Sˆ=ΨBˆ。在 Λt处有非零项,其值分别为最后一次迭代得到的。
2.3 组合算法流程图
组合算法流程图如图1所示。
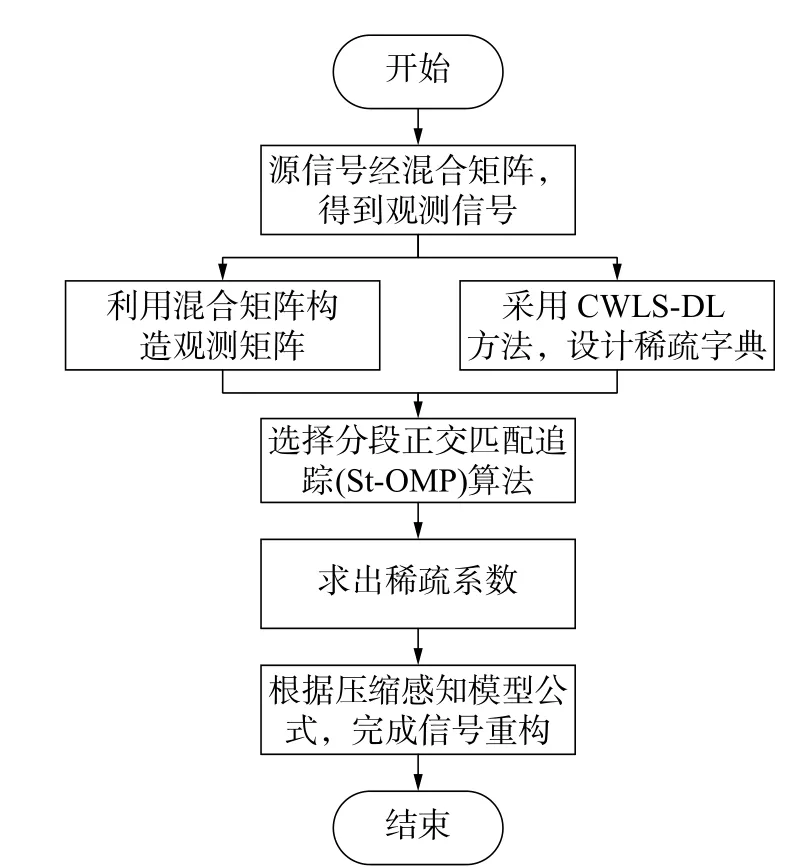
图1 压缩感知盲源分离组合算法
2.4 算法性能评价标准
评价混合矩阵估计性能的标准有2个[12],分别为:
1)信干比

式中:si代 表第i路 源信号;代 表第i路恢复源信号。利用信干比作为源信号的恢复性能评价准则时,信干比越大,表示源信号恢复效果越好越理想。一般认为当信号的信干比不小于10dB时,恢复效果较好,重构精度高。这里的信干比定义与其他地方不同,表示的是重构信号与源信号的误差,而和干扰没有关系。
2)相关系数
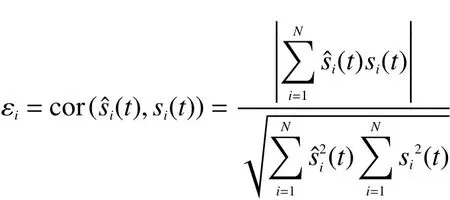
式中: si(t)是 第i路 源 信 号 ;(t)是 第i路恢复源信号。当相关系数越接近1,说明分离效果越好,恢复信号越接近源信号;反之,则分离算法性能越差。一般情况下,相关系数不小于0.8时,信号恢复程度已较好。
3 仿真实验及结果分析
为验证算法的性能,我们通过语音信号的盲源分离仿真实验来完成。实验采用的源信号为随机选取的4段英语听力音频,数据采样点长度为80000,采样频率为10kHz,源信号时域波形图如图2所示。

图2 源信号波形
首先,利用混合矩阵模拟声音传播的信道,将4路源信号混合成3路观测信号,本文中混合矩阵 A为随机生成的,混合矩阵为:

3.1 语音信号重构的仿真实验(无噪声环境)
3.1.1 信号重构情况
根据本文提出的字典学习方法与重构算法,进行信号分离重构仿真实验,并命名算法1为K−SVD字典+OMP算法,算法2为CWLS字典+OMP算法,算法3为K−SVD字典+St−OMP算法,算法4为CW−LS字典+St−OMP算法。分别通过上述组合算法进行源信号重构,得到重构源信号分别如图3~6所示。

图3 算法1分离信号波形(无噪声)

图4 算法2分离信号波形(无噪声)

图5 算法3分离信号波形(无噪声)

图6 算法4分离信号波形(无噪声)
3.1.2 算法性能检验
接下来,通过对比所得相关系数与信干比的数据,来检验算法的性能。
首先是相关系数,表1中的数据为通过算法4重构信号得到的相关系数,主对角线上的数据代表源信号与自身重构信号的相关系数,其他位置代表源信号与其余重构信号的相关系数。可以看到主对角线上的相关系数均大于0.8,证明通过算法4能够较好恢复信号。

表1 通过算法4仿真得到的相关系数
下面将对比通过不同算法得到的相关系数来验证算法重构源信号的精确度,数据如表2所示。其中,在算法4下计算得到的相关系数最大,意味着重构源信号的精确度最高。所以,CWLS字典与St−OMP算法的组合在信号重构精度方面,在这4个算法组合中性能最佳。

表2 不同算法相关系数对比结果
下面将对比不同算法完成仿真实验的消耗时间,来验证算法重构源信号的复杂度。数据如表3所示,按算法消耗时间由少到多的顺序排列,分别为算法2、算法1、算法4、算法3。这证明了CWLS字典与St-OMP算法的组合,在算法复杂度上有一个降低的趋势。

表3 不同算法消耗时间对比结果
对比相关系数之后,下面是信干比的比较。数据如表4所示,其中算法4得到的信干比最大。和相关系数的验证结果一样,CWLS字典与St-OMP算法的组合在信号重构精度方面,是这4个算法组合中性能最好的。
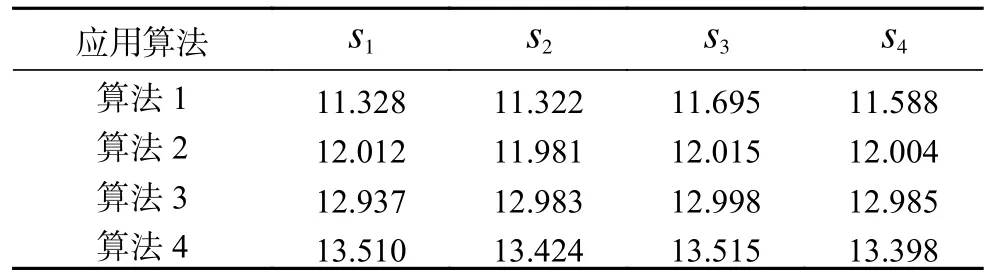
表4 不同算法信干比对比结果
3.2 语音信号重构的仿真实验(有噪声环境)
3.2.1 信号重构情况
本小节实验将在加性高斯白噪声(additive white Gaussian noise,AWGN)的环境下进行。依旧遵循3.1.1节中的算法命名方式,分别通过前面的4种组合算法进行源信号重构。设置信噪比为20dB,得到重构源信号分别如图7~10所示。

图7 算法1分离信号波形(信噪比为20dB)

图8 算法2分离信号波形(信噪比为20dB)

图9 算法3分离信号波形(信噪比为20dB)

图10 算法4分离信号波形(信噪比为20dB)
3.2.2 算法性能检验
这里对比在AWGN环境下所得相关系数与信干比的数据,来检验算法的性能。
图11为不同信噪比下的相关系数曲线图,可看到算法4是上述4种组合中,当相关系数相等且不小于0.8时,所需信噪比最小的组合,最小信噪比约为18dB。
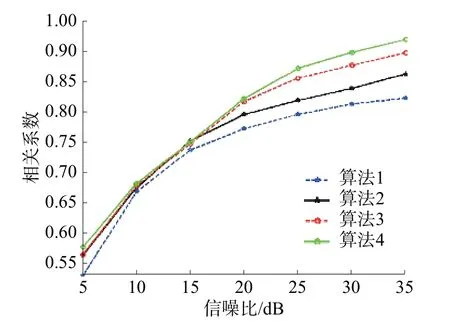
图11 不同信噪比下的相关系数(含AWGN)曲线
图12为不同信噪比下的信干比曲线图,可看出算法4的组合是上述4种组合中,当信干比相等且不小于10dB时,所需信噪比最小的组合,最小信噪比约为17dB。
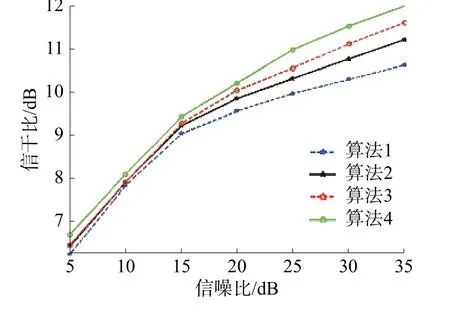
图12 不同信噪比下的信干比(含AWGN)曲线
所以,CWLS字典与St-OMP算法的组合在含噪声环境下同样有着较优的性能。
4 结论
本文就欠定盲源分离中源信号的恢复问题,与压缩感知理论结合,并针对其中的字典学习与重构算法进行改进,提出了CWLS字典学习与St-OMP算法组合,并完成语音信号的信号重构仿真实验。所得结论如下:
1)提出的组合算法能够解决带权重信号误差的F−范数最小化问题,并通过增加单次迭代的原子数改变算法复杂度。
2)仿真实验结果表明,CWLS字典学习与St-OMP算法组合在原有算法基础上,可提高信号重构精度,同时在算法复杂度上有着不错的折中效果;而且在含噪声环境下同样有着较优的性能。
文章在对算法的复杂度验证上还不够完善,而且其稳定性也要进一步验证,这也是后面的研究过程中需要考虑的地方。
猜你喜欢
现代仪器与医疗(2022年1期)2022-04-19
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2019年9期)2019-10-26
小学阅读指南·低年级版(2019年11期)2019-07-01
雷达学报(2017年3期)2018-01-19
小天使·一年级语数英综合(2017年11期)2017-12-05
现代防御技术(2017年1期)2017-03-02
读者(2016年14期)2016-06-29
西南石油大学学报(自然科学版)(2015年5期)2015-04-16
海军航空大学学报(2015年4期)2015-02-27
