
Hadoop3.0大数据平台性能
2019-06-20 10:31李士果卢建云
电子技术与软件工程 2019年5期
李士果 卢建云


摘要 针对发布的Hadoop3.0,本文研究了Hadoop3.0大数据平台性能。首先,采用华为云服务器搭建大数据平台;其次,利用Hadoop框架提供的基准性能测试程序进行性能验证,测试指标包括TestDFSIO、MRBench和TeraSort。最后,对比分析不同负载、不同数据量对平台性能的影响。实验结果表明,Hadoop3.0在HDFS读写能力、MapReduce计算能力上均表现出较优的性能。
【关键词】大数据 Hadoop3.0 性能测试
1 引言
Hadoop作为开源的分布式系统基础架构,具有高扩展性、高可靠性、高容错性、低成本等特性,在政府、金融、工业、教育等领域得到了广泛的应用。Hadoop平台发展至今,发布了三个大版本,分别是Hadoop1.0、2.0和3.0。从Hadoop1.0到Hadoop2.0,增加了资源管理系统Yarn,使得Hadoop2.0具有更好的扩展性和性能,并支持多种计算框架。近来,Apache发布了Hadoop3.0版本,该版本在功能和性能方面做了多项改进,使得Hadoop3.0在存储和计算性能方面得到很大提升。因此,对Hadoop3.0平台性能进行研究具有重要的实际应用意义。本文基于华为云服务器搭建Hadoop3.0完全分布式集群,使用Hadoop3.0提供的基准测试程序对平台进行性能测试。分析对比不同负载、不同数据量对Hadoop3.0平台的性能影响。
2 Hadoop3.0平台特性
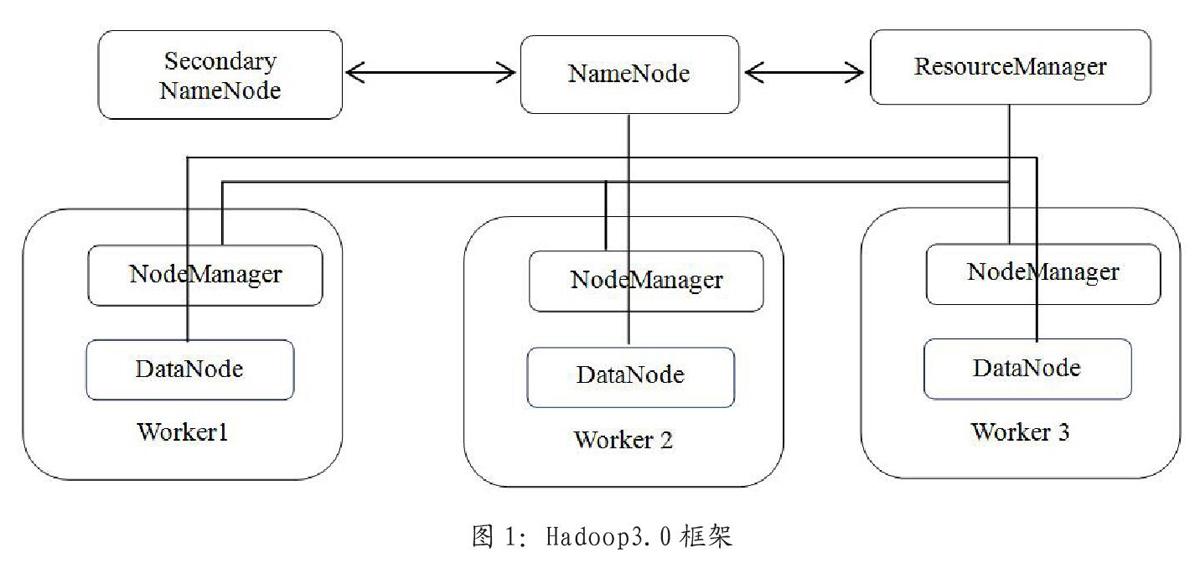
Hadoop是Apache旗下一个顶级分布式计算开源框架项目,主要包括两个核心组件:分布式存储子系统HDFS和分布式计算子系统MapReduce。Hadoop采用主/从架构管理存储和计算。通常,在Hadoop完全分布式集群上,运行了一系列后台程序。这些后台程序代表了不同的服务,例如NameNode、DataNode、Secondary NameNode、JobTracker、TaskTracker等。其中NameNode、Secondary NameNode、JobTracker运行在Master节点上,而在每个Worker节点上,部署一个DataNode和TaskTracker,以便这个Worker服务器运行的数据处理程序能尽可能直接处理本机的数据。Hadoop3.0框架如图1所示。
Hadoop3.0引入了一些重要的特性,如HDFS可擦除编码技术、支持多NameNode、Yarn基于cgroup的内存和磁盘IO隔离、MR Native Task优化等,综合性能有很大提升。
3 实验与结果分析
为了测试Hadoop3.0平台性能,方便对平台性能进行调优。实验采用Hadoop3.0具有代表性的基准测试工具TestDFSIO、MRBench和TeraSort对HDFS读写性能、MapReduce并行计算能力进行测试,通过吞吐量、执行时间等指标对测试结果进行分析。
3.1 实验环境
实验采用4台华为云服务器搭建Hadoop3.0完全分布式集群。该集群包含4个节点,其中2个节点部署为Master,全部4个节点作为Worker。Linux操作系统版本是Centos7.4,Java版本是1.8.0_191,Hadoop版本是3.1.0。表1列出了Hadoop3.0完全分布式集群部署信息。
3.2 實验与分析
3.2.1 TestDFSIO测试Test
DFSIO是Hadoop提供的基准测试工具,用于测试HDFS的读写性能。TestDFSIO设计原理是每个文件读写都在单独的Map任务中进行,Map任务以并行方式读写文件,Reduce任务用于收集和汇总文件处理性能数据。该实验数据总量为20G,不断增加文件数量进行测试。测试结果如图2和图3所示。
图2和图3表明,在20G数据量保持不变的情况下,随着文件数量的增加,并发Map数量不断增加,HDFS读写吞吐量和读写时间均呈下降趋势。其中,写数据的吞吐量明显低于读数据的吞吐量,写数据的执行时间明显高于读数据的执行时间。
3.2.2 MRBench测试MRBench
用于检验小作业是否可重复高效运行,它通过多次重复执行一个小作业来验证MapReduce的并行处理性能。本实验使用MRBench默认配置重复执行小作业进行测试。MRBench配置如下:inputLines=1,mapper=2,reducer=1,分别重复执行10次、50次、100次、200次、500次和1000次,运行结果如图4所示。
图4结果显示,随着重复执行次数的增加,作业的平均执行时间缓慢下降并趋于稳定。从最后两次测试结果发现,重复执行500次和1000次的时间相对持平,说明小作业重复执行500次到1000次的性能趋于稳定。
3.2.3 TeraSort测试
TeraSort是Hadoop压力测试最具代表性的工具之一。TeraSort不仅测试HDFS文件系统的读写性能,也是对MapReduce自动排序能力的一种测试。TeraSort包含三个工具,其中TeraGen用来生成排序的随机数据,TeraSort用来将随机数据排序,TeraValidate用于校验TeraSort的排序结果是否正确。实验分别对1G、2G、5G、10G、20G、50G和100G文件进行TeraSort测试,测试结果如图5所示。
从图5可以看出,随着数据量的增加,TeraSort排序时间呈曲线增长。当数据量在20G以内时,排序时间增长比较缓慢,当数据量增加到50G,甚至100G时,排序时间增长显著。
5 总结
本文采用华为云服务器搭建Hadoop3.0平台,利用Hadoop3.0提供的基准测试工具TestDFSIO、MRBench和TereSort对平台性能进行测试。实验结果表明,Hadoop3.0大数据平台在HDFS读写能力、MapReduce计算能力上均表现出较优的性能。后续我们将对Hadoop2.0与3.0平台进行性能对比研究。
参考文献
[1]White T.Hadoop权威指南[M].清华大学出版社,2015.
[2]Apache Hadoop website, http://hadoop. apache.org.
[3]MichealG.Noll. Benchmarking and Stress Testing an Hadoop ClusterWith TeraSort, TestDFSIO& Co., http:// www.michaelnoll.com/blog/2011/04/09/ benchmarking-and-stress-testing- an-hadoopcluster-with-terasort- testdfsio-nnbench-mrbench/.
[4]Apache Hadoop3.0, http://hadoop. apache.org/docs/r3.0.0/.
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
北京大学学报(自然科学版)(2021年3期)2021-07-16
东北师大学报(自然科学版)(2021年1期)2021-03-27
科普童话·学霸日记(2020年1期)2020-05-08
电子制作(2019年13期)2020-01-14
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
