
人工智能用图像和生物组学解码癌症
2019-06-20 07:16编译陆默
世界科学 2019年6期
编译 陆默

机器学习可以对癌症照片、肿瘤病理切片和基因组进行分析。如今,科学家正准备将这些信息整合到癌症超级模型中。
每个癌症患者都在思考的一个问题是:我还能活多久?基因组学家迈克尔·斯奈德(Michael Snyder)希望他能找到答案。
目前,所有医生能做的就是将患有类似癌症的患者分组,然后对他们和其他组患者的相同药物反应或预后进行评估,但目前的分组方法粗略而不完善,而且往往都只是基于人工收集的数据。
斯坦福大学基因组学和个体化医学中心主任斯奈德指出:“病理学家根据解读图像的结果来诊断病情的准确率通常只有60%。”2013年,他和当时的研究生余坤兴(Kun-Hsing Yu,音译)开始琢磨,人工智能是否能够为医生提供更准确的预测。
余将组织学图像连同病理学家确定的诊断一起输入机器学习算法,训练它区分肺癌和正常组织,以及两种不同类型肺癌之间的区别。然后输入相关患者的生存数据,让系统了解这些信息与图像之间的关系。最后,他在模型中补充了一些新的病理切片资料,并向AI提出了一个至关重要的问题:患者的存活时间。
计算机可以预测患者的生存期高于或低于某些特定癌症的平均存活时间,这是病理学家很难做到的。计算机预测“效果出奇的好。”如今任哈佛医学院讲师的余说道。
但是斯奈德和余认为他们还可以做更多的事。斯奈德的实验室也在研究生物组学,所以他们决定向计算机提供的学习资料不仅只有组织病理切片资料,还提供了肿瘤转录组资料。结合这些数据,该计算机模型对患者生存做出的预测甚至比单独使用图像或转录组资料更好,准确率超过了80%。如今的病理学家通常根据组织显微照片的视觉评估来进行生存情况预测,通过显微照片对肿瘤进行评估分级,包括肿瘤的大小和严重程度,以及肿瘤进一步生长和扩散的可能性。但这种肿瘤分级方法并不总能准确预测生存情况。
斯奈德和余并不是唯一认识到人工智能在分析癌症相关数据集(包括图像、生物组学以及两者结合的数据集)方面威力的研究人员。尽管这些方法进入临床前还有很长的路要走,但快速做出准确诊断,预测哪些治疗方法对哪些患者最有效,甚至更准确地预测生存情况,人工智能显然在这些方面做得更好。
伦敦癌症研究所的计算生物学家安德里亚·索托里瓦(Andrea Sottoriva)表示,目前其中一些应用仍然还处于“科幻小说”的阶段,索托里瓦正在用人工智能预测癌症的演变以及选择合适药物治疗特定肿瘤方面的研究。
输入:图像;输出:诊断结果
在癌症发展到一定程度之前,发现和治疗癌症是提高患者生存的关键。例如,早期发现宫颈癌可使患者生存5年的情况超过90%,医生可以采取冷冻或切除位子宫颈转化区顶端4毫米处癌前细胞等治疗手段。然而一旦癌症转移,5年存活率就会下降到56%甚至更低。
癌症早期治疗在发达国家是很常见的做法,那里的妇女定期接受巴氏涂片检查宫颈细胞异常,并检测导致癌症的人类乳头瘤病毒。但发展中国家却很少见这样的癌症筛选法。美国国家癌症研究所流行病学家马克·希夫曼(Mark Schiffman)指出一种更便宜的测试方法,即医护人员在女性子宫颈上涂上醋酸,以寻找可能表明癌症的白色区域,但“这种方法非常不准确”,结果导致一些健康女性被误诊为癌症而接受治疗,而另一些人的癌前细胞却可能漏检,导致癌症发展后需要采取更激进的治疗方法,如化疗、放疗或子宫切除术。
希夫曼和其他研究小组一直在尝试寻找某种途径,以让醋酸筛选的结果更加准确,例如,利用白光以外的其他光谱成像,希夫曼的团队从美国和哥斯达黎加的不同来源收集了数千张宫颈照片,其中包括医疗专业人员用阴道镜或手机拍摄的照片。但是他已经准备放弃这种尝试了。“我们无法让它像其他测试方法那样灵敏、准确或重现真实情况。”
2017年底,比尔和梅林达·盖茨基金会旗下的非营利组织全球友好(Global Good)组织也开始用希夫曼收集的图像尝试机器学习,他们想知道,在医生无法提供确切诊断的情况下,计算机是否能够进行准确预测。
希夫曼与Global Good和其他合作者一起,利用一种叫作卷积神经网络的机器学习方法来分析宫颈图像。算法目标是识别图像中的一些特征,例如,并排像素的相似度或差异度,以得出准确诊断。一开始,机器的准确性并不比巧合好多少。在分析了越来越多的图像后,机器会对这些图像的相似或差异特征进行权衡,以帮助寻找最佳答案。“这是一个反复权衡的过程,直到它尽可能地接近答案。”希夫曼解释说道。
研究小组从哥斯达黎加9 000多名妇女的宫颈图像开始的这项研究历时7年多时间。希夫曼还从这些妇女更准确的筛查测试结果中,以及18年来有关癌症前期或癌症诊断的跟踪随访的信息中收集了大量数据。研究人员使用了其中70%的完整数据集来训练模型,然后用剩下30%的图像数据测试机器性能。机器学习预测在区分健康组织、癌症前期和癌症之间区别的出色表现令希夫曼难以置信,机器学习预测的准确率达到了91%,相比之下,人类视觉检查的准确率仅为69%。希夫曼说:“我所知道的任何方法都做不到这样的精确度。”之前他认为机器也难免会出差错。
有了擅长识别癌症前期和癌症的人工智能新工具,希夫曼希望开发低成本的宫颈癌筛查测试技术,将手机式相机与基于机器的图像分析结合起来。首先,他要利用世界各地数以万计的手机子宫颈图像来训练其算法。
希夫曼并不是唯一关注智能手机进行癌症诊断的人。皮肤损伤可能会癌变,也可能是良性的,因为它就在表面,任何人都可以给它拍照。斯坦福大学的研究人员建立了一个包含近13万张皮肤病变照片的数据库,并利用它来训练卷积神经网络,区分良性肿块和三种不同恶性病变之间的区别。机器学习的诊断准确率通常至少可达到91%,机器算法的表现明显优于对同批照片进行评估的21名皮肤科医生的诊断结果。
建立癌症预测模型的主要挑战是要获取足够多高质量的数据。斯坦福大学的研究小组在整理从斯坦福医学院获得和从网上收集到的皮肤癌图片时发现,这些图片的拍摄角度、缩放比例和光线明暗参差不齐,研究人员还必须将图片标签翻译成各种语言,然后与皮肤科医生合作,将这些皮肤病变分为2 000多个不同种类。
当然,大多数癌症诊断需要的不仅仅是智能手机摄像头,观察肿瘤中单个细胞还需要用到显微镜。余说,科学家希望尽可能多地收集到有关某个患者的临床治疗和治疗效果的相关信息,以及基因组等分子数据,但这很难获得。“我们很少能找到这样的一个病人,他拥有我们所想要的所有数据。”
输入:图像+组学; 输出:生存率
正如斯奈德和余所发现的那样,结合组学数据可提供关于某种特定癌症所涉及的分子通路的信息,有助于识别癌症类型、生存率或治疗效果的可能反应。在最初基于图像的研究中,研究人员手中有2 186张肺组织切片图片,来自人类病理学家对疾病的分类,以及患者存活时间数据。研究人员使用计算机算法从这些图像中提取了近10 000个特征,比如细胞形状或大小,他们用这些特征训练了几种机器学习算法。
一种很有效的方法叫做“随机森林”,它可以生成数百种决策树,然后这些“决策树”对答案进行投票,根据票数多少做出决策,多者胜出。该算法在区分健康组织和两种癌症类型方面的准确率超过75%,而且在预测存活率方面比单纯基于癌症分期的模型更准确。“这已经超出了目前病理学诊断的水平,”余说。
在后续研究中,研究人员运行经过训练的图像分析算法系统,对538名肺癌患者的组织病理学切片资料进行分析,然后又输入了这些患者的转录组和蛋白质组数据,要求“随机森林”对患者进行癌症分级。15个基因的表达水平预测癌症分级的准确率为80%,这些基因参与了DNA复制、细胞周期性调控和p53信号传递等过程,众所周知,这些过程在癌症生物学中扮演了重要角色。研究小组还确定了15种与细胞发育和癌症信号有关的蛋白质(并非由15个基因编码的蛋白质),其预测癌症分级的准确率为81%。虽然研究人员没有将这一结果与人类医生的诊断进行比较,但一项病理学研究发现,79%的肺腺癌诊断结果与人类医生的诊断结果是一致的,表明机器和人类的诊断结果一样准确,但机器更强大,它们将目标瞄准了促进癌症发展的特定基因表达因子。
最后,研究人员要求计算机根据基因表达、癌症分级和患者年龄来预测生存率。有了所有这些数据,该模型的
链 接
人工智能诊断癌症
科学家一直在使用图像(图像包括照片或病理切片)和生物组学这两种主要形式的临床数据来预测癌症的结果。将越来越复杂的机器学习方法应用于这些数据集,可以得到准确的诊断和预后,甚至可以推断肿瘤的进化,如今科学家发现可以通过图像预测组学数据。通过这两个数据源的结合,研究人员可以更好地预测癌症患者的生存期。基础生物学实验室里目前正在开发的算法,最终能够帮助医生更好地选择治疗方案和预测患者生存期。准确率达80%以上,能够将患者正确分为长期生存者和短期生存者,胜过人类病理学家、单独使用转录物组或图像技术。
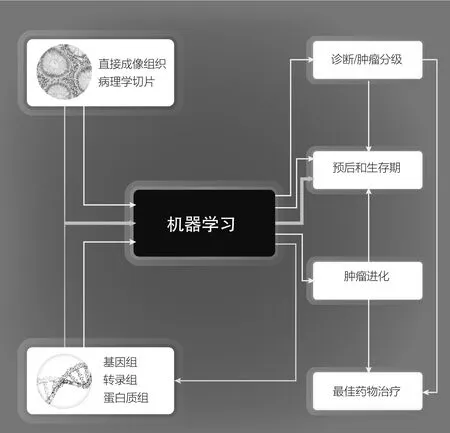
受斯奈德和余的研究成果启发,纽约大学医学院的亚里士多德·齐里戈斯(Aristotelis Tsirigos)和他的同事将1 634张健康或癌变肺组织的病理切片图像资料与遗传学联系起来。仅凭这些图像资料,他们设计开发的卷积神经网络就能将腺癌与鳞状细胞癌区分,准确率约为97%。然后,研究小组将10个最常见肺腺癌突变基因的算法数据输入计算机,计算机学会了从病理切片中预测其中6个突变的存在,准确率从73%到86%不等。“测试效果非常好,作为最初成果,这还是非常令人兴奋的。”索托里瓦说道,虽然他没有参加这项研究。
当然,医生和科学家不需要通过成像来识别突变,其他一些测试方法更直接、更准确,基因测序可提供近乎完美的癌症基因组读数。齐里戈斯解释说,这项研究旨在证明基因和图像特征之间的关系是可以预测的。现在,他正在努力结合组织病理学和分子信息来预测患者的预后,正如余和斯奈德的团队所做的那样。齐里戈斯说,只要输入正确的数据,这些方法应该适用于任何癌症类型。
输入:组学资料;输出:肿瘤进化
即使没有图像资料,组学数据本身也很有用。例如,索托里瓦和他的同事正在利用基因组学来了解肿瘤的进化。一个肿瘤通常由多个细胞系组成,这些细胞系都来自于同一个原始癌细胞。为有效治疗癌症,理解这种异质性和肿瘤进化的方式是很重要的。如果只对肿瘤的一部分进行局部治疗,癌症还会复发。“这是一个生死攸关的问题。”爱丁堡大学计算机科学家、肿瘤进化研究合作者吉多·桑吉内蒂(Guido Sanguinetti)说道。
通过对单个肿瘤的多个部分进行采样,研究人员可以推断出癌症的进化路径,这类似于对现代人类基因组进行采样以追溯种群起源的做法。来自不同患者的肿瘤,即使是同一种癌症,其进化树也往往大相径庭。桑吉内蒂、索托里瓦和他的同事认为,如果能够找到癌症倾向于遵循的共同途径,肿瘤学家就可以利用这些信息对可能有类似疾病发展过程或对药物有类似反应的患者进行分类。
为找到共同的进化树,研究人员使用了一种叫作转移学习的机器学习形式。桑吉内蒂解释说,该算法同时观察患者基因组中的所有进化树,寻找它们之间的共享信息,以找到适合整个患者群体的解决方案。他们将这一机器学习工具称为REVOLVER,意思是“癌症的反复进化”。在最初测试中,他们发明虚构肿瘤进化树,将基于虚构肿瘤进化树的REVOLVER基因组数据输入到机器,然后它真的“吐出”了与虚构肿瘤进化相匹配的种系进化树。

为了验证该工具对常见癌症进化的预测,研究人员将目标转向结直肠癌的恶性转化,当已知驱动基因的良性腺瘤积累突变时就会发生这种恶性转化。研究人员输入了9个良性腺瘤和10个恶性肿瘤的基因组REVOLVER,结果是:该模型绘制了匹配良性腺瘤向恶性肿瘤转化的进化树。
然后,研究小组对肿瘤样本进行了分析,这些样本的进化过程尚不明确。在99名非小细胞肺癌患者的基因组中,REVOLVER根据肿瘤累积的突变序列确定了10名患者的潜在癌细胞集群。其中一些癌细胞集群的生存时间不足150天,而另一些则生存了更长时间。同样,REVOLVER在50个乳腺癌肿瘤中发现了6个癌细胞集群,每个集群之间的生存时间有长有短,索托里瓦说:“之前我们都没想到能发现这样的癌细胞集群,这些结果告诉我们,癌症的进化是可以预测的。”
索托里瓦说,药物治疗可建立在这些可预测模式上。人工智能是强大的工具,可以帮助识别与临床有关的模式。此外,通过从模型的输入中选择剔除特定数据片段,并观察其准确性是否会有所下降,生物信息学家可以弄清楚计算机是根据哪些特征来区分癌症类型的,索托里瓦说道。
就目前来说,人工智能在癌症研究中的应用仅仅是开始。未来的算法可能不仅包括组学和图像,还包括治疗结果、治疗进展以及科学家可以得到的任何其他数据。
“归根结底,处理像癌症这样的复杂疾病时,我们需要完整的信息。”斯奈德说。
猜你喜欢
环球时报(2022-07-13)2022-07-13
昆明医科大学学报(2022年3期)2022-04-19
环球时报(2022-03-14)2022-03-14
昆明医科大学学报(2021年4期)2021-07-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电影(2018年8期)2018-09-21
中国交通信息化(2018年5期)2018-08-21
天然产物研究与开发(2018年2期)2018-04-04
