
多载体图书信息邻近似目标精细化检索系统设计
2019-06-15 03:31刘斌陆尧
现代电子技术 2019年12期
刘斌 陆尧

摘 要: 为了提高多载体图书信息检索能力,提出多载体图书信息邻近似目标精细化检索系统设计方案。采用分位数回归模型构建多载体图书信息筛选模型;采用关联信息熵特征提取方法进行多载体图书信息的近邻特征挖掘,提取多载体图书信息的关联语义特征量;利用语义本体特征重构方法进行多载体图书信息的检索和筛选识别,分析多载体图书信息的输出高维特征信息;采用邻近相关性检索方法实现多載体图书信息的语义信息检索和自适应查询,实现多载体图书信息的信息分类和特征匹配。在算法设计基础上,采用嵌入式的Linux技术进行多载体图书信息邻近似目标精细化检索系统的开发设计。测试结果表明,采用该方法进行多载体图书信息邻近似目标精细化检索的召回性较好,检索效率较高。
关键词: 多载体图书信息; 邻近似目标精细化检索; 语义信息检索; 特征分类; 特征匹配; 自适应查询
中图分类号: TN911.2?34; TP399 文献标识码: A 文章编号: 1004?373X(2019)12?0029?04
Abstract: A design scheme of the proximity?like target refined retrieval system for multi?carrier book information is proposed to improve the multi?carrier book information retrieval ability. The quartile regression model is used to construct the multi?carrier book information screening model. The relevance information entropy feature extraction method is used to mine the nearest neighbor features of multi?carrier book information, so as to extract the associated semantic feature quantity of multi?carrier book information. The semantic ontology feature reconstruction method is used to retrieve, screen, and recognize multi?carrier book information, so as to analyze the output high?dimensional feature information of multi?carrier book information. The adjacent relevance retrieval method is used to realize semantic information retrieval, adaptive query, classification and feature matching of multi?carrier book information. On the basis of the algorithm design, the embedded Linux technology is used to develop and design the proximity?like target refined retrieval system for multi?carrier book information. The test results show that the method has a good recall performance and high retrieval efficiency for proximity?like target refined retrieval of multi?carrier book information.
Keywords: multi?carrier book information; proximity?like target refined retrieval; semantic information retrieval; feature classification; feature matching; adaptive query
0 引 言
随着信息化图书馆建设的快速发展,以传统的纸质图书和网络图书为载体的图书馆信息管理系统得到广泛应用,采用多载体的图书信息管理模式,提高图书馆的电子化水平,在多载体图书管理信息模式下,研究图书管理的智能化信息管理方法,提高图书馆信息的智能检索能力[1]。在多载体图书信息管理模式下,通过邻近似目标精细化检索系统设计,实现图书馆的信息资源优化服务升级,相关的信息管理系统和检索系统设计方法受到人们的极大关注。传统方法中,对多载体图书信息邻近似目标精细化检索方法主要有有源标签识别方法、模糊聚类检索方法等[2?3],上述方法在进行图书馆数据的邻近似目标精细化检索中存在计算开销大和实时性不好的问题。对此,本文采用分位数回归模型构建多载体图书信息筛选模型,采用关联信息熵特征提取方法进行多载体图书信息的近邻特挖掘,提取多载体图书信息的关联语义特征量,结合Linux内核进行检索系统优化设计,最后进行仿真测试,展示了本文设计系统的优越性能。
1 多载体图书信息管理的数据流特征分析
1.1 多载体图书信息标签识别数据采样
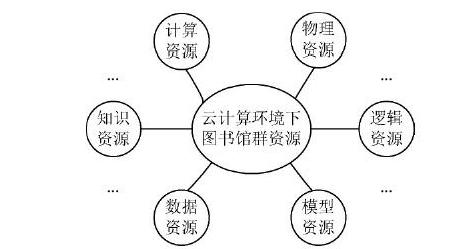
为了实现对多载体图书信息邻近似目标精细化检索模型优化开发设计,采用RFID标签识别技术进行多载体图书信息采样,结合二维码识别和条形码识别的方法,进行多载体图书信息的自动编码和标识位构建,多载体图书信息采集的资源分布如图1所示。
图1 多载体图书信息采集的资源分布
1.2 关联语义特征量提取
构建图书馆信息检索的数据库实体模型,采用自适应均衡调度方法,得到多载体图书信息挖掘的输出信息熵为:
2 多载体图书信息检索
2.1 多载体图书信息的语义信息挖掘
采用动态回归分析方法[7]得到多载体图书信息分布的链路集满足[P∈Rn×n],[R∈Rm×m]和[H∈Rm×n],设多载体图书信息整合的本体指标集定义为:
在重组的图书信息检索系统中,得到多载体图书信息检索的聚簇中心距离为[yj][(j=1,2,…,d)],实现多载体图书信息的語义信息挖掘。
2.2 邻近似目标精细化检索算法
3 系统硬件开发设计
采用Multigen Creator 3.2进行多载体图书信息检索系统的数据库建模,在Vega Prime 2.2.1视景仿真平台进行多载体图书信息检索系统的3D虚拟现实环境开发,设计图书信息检索系统推荐标识位及对应状态见表1。
表1 图书信息检索系统推荐标识对应状态
[taskFlag 指令状态 000 多载体图书信息参数初始化 001 写入多载体图书信息检索系统的C编译器 010 定义多载体图书信息语义检索组件 011 发送准备状态,进行程序指令加载 101 加入系统环境变量,修改配置文件 100 程序加载和指令控制 110 数据管理及命令行输入 111 硬件自动配置 ]
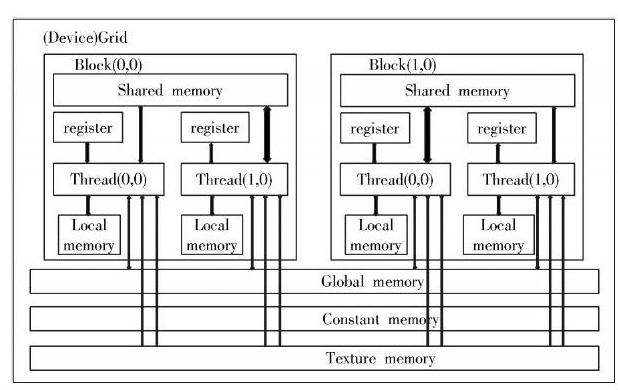
根据上述图书信息检索系统推荐标识状态设计,进行系统开发设计,采用程序加载过程控制方法进行多载体图书信息邻近似目标精细化检索系统的指令设计,在DSP和FPGA集成处理环境中实现精细化检索系统的硬件开发;采用逻辑DSPBF537作为核心处理器,进行多载体图书信息邻近似目标精细化检索系统的指令读/写和编译操作,构建A/D转换控制模块,在DSP系统实现图书信息邻近似目标精细化检索的指令加载和控制信息处理。系统硬件配置如图2所示。
图2 系统的硬件配置
4 仿真测试
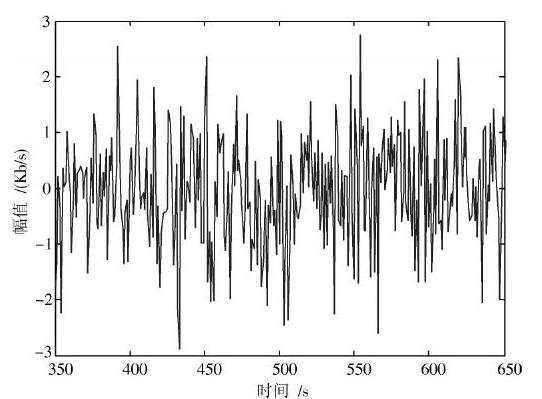
在上述构建系统的算法和硬件配置的基础上,采用多线程总线控制技术进行图书信息邻近似目标精细化检索程序加载,实现系统测试。采用Matlab仿真工具进行算法设计,在Visual DSP++集成信息处理平台中进行系统的硬件调制。假设对图书信息采样的数据集规模为2 000,数据长度为1 024,信息采样的脉冲频率为150 kHz,多载体图书信息数据如图3所示。
图3 待测试的多载体信息数据
以图3采样数据为输入,采用语义本体特征重构方法进行多载体图书信息的检索和筛选识别,分析多载体图书信息的输出高维特征信息,进行图书信息邻近似目标精细化检索,得到检索输出如图4所示。
图4 检索输出

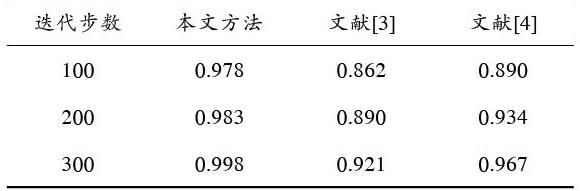
分析图4得知,本文方法能有效实现多载体图书信息筛选和精细化检索,检索输出的区间指向性较好。测试不同方法进行多载体图书信息检索的召回性,得到对比结果见表2,分析得知,本文方法进行多载体图书信息检索的召回率较高。
表2 召回性对比
5 结 语
本文进行多载体图书信息邻近似目标精细化检索系统设计,采用关联信息熵特征提取方法进行多载体图书信息的近邻特征挖掘,提取多载体图书信息的关联语义特征量,采用语义本体特征重构方法进行多载体图书信息的检索和筛选识别,分析多载体图书信息的输出高维特征信息,实现多载体图书信息的信息分类和特征匹配。在DSP系统实现图书信息邻近似目标精细化检索的指令加载和控制信息处理,实现图书信息精细化检索系统的开发设计。研究得知,采用本文方法进行多载体图书信息邻近似目标精细化检索的召回性较好,提高了图书信息的检索能力。
参考文献
[1] 薛胜军,胡敏达,许小龙.云环境下公平性优化的资源分配方法[J].计算机应用,2016,36(10):2686?2691.
XUE Shengjun, HU Minda, XU Xiaolong. Fairness?optimized resource allocation method in cloud environment [J]. Journal of computer applications, 2016, 36(10): 2686?2691.
[2] BACH S H, BROECHELER M, HUANG B, et al. Hinge?loss Markov random fields and probabilistic soft logic [J]. Journal of machine learning research, 2017, 18(109): 1?67.
[3] FARNADI G, BACH S H, MOENS M F, et al. Soft quantification in statistical relational learning [J]. Machine learning, 2017, 106(12): 1971?1991.
[4] BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet: a deep convolutional encoder?decoder architecture for image segmentation [J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(12): 2481?2495.
[5] WEI X S, LUO J H, WU J, et al. Selective convolutional descriptor aggregation for fine?grained image retrieval [J]. IEEE transactions on image processing, 2017, 26(6): 2868?2881.
[6] RAZAVIAN A S, SULLIVAN J, CARLSSON S, et al. Visual instance retrieval with deep convolutional networks [J]. ITE transactions on media technology and applications, 2016, 4(3): 251?258.
[7] 王利,杨征,李洋.特征聚合的遥感图像数据库检索技术[J].激光杂志,2016,37(6):78?81.
WANG Li, YANG Zheng, LI Yang. Retrieval technology of remote sensing image database based on feature aggregation [J]. Laser journal, 2016, 37(6): 78?81.
[8] 文政颖,李运娣.语义指向性特征聚类的图像检索算法研究[J].计算机技术与发展,2017,27(4):83?88.
WEN Zhengying, LI Yundi. Investigation on image retrieval algorithm with semantic directed feature clustering [J]. Computer technology and development, 2017, 27(4): 83?88.
[9] 高翔,郭新东,张凤兰,等.基于安卓平台的井控信息处理系统的设计实现[J].现代电子技术,2014,37(8):82?85.
GAO Xiang, GUO Xindong, ZHANG Fenglan, et al. Design and implementation of well control information processing system based on Android [J]. Modern electronics technique, 2014, 37(8): 82?85.
[10] MIKKONEN A, VAKKARI P. Readers′ interest criteria in fiction book search in library catalogs [J]. Journal of documentation, 2016, 72(4): 696?715.
