
基于网络知识百科的情感语义抽取研究
2019-06-14 07:37:08孙本旺
计算机技术与发展 2019年6期
田 芳,孙 晓,孙本旺
(1.青海大学 信息化技术中心,青海 西宁 810016;2.合肥工业大学 计算机与信息学院,安徽 合肥 230009;3.青海大学 计算机技术与应用系,青海 西宁 810016)
0 引 言
为了使计算机理解人类语言,自然语言处理研究越来越得到研究者的重视。自然语言处理技术的基础是语料知识库,如词汇语义。语义信息概念最早由Bar-Hillel教授和Carnap教授在1953年提出[1]。随后,1992年John F. Sowa教授明确了语义网络(semantic network)[2]。从二十世纪九十年代中期,世界各国研究者研究开发了语义词典[3],包括美国普林斯顿大学的WordNet[4]、美国微软的MindNet[5]、意大利信息研究所情感词典SentiWordNet[6]等。中文语义词典比较著名的有中科院董振东先生提出的知网HowNet[7]、哈尔滨工业大学的同义词词林[8]、北京大学计算语言研究所的中文概念词典[9]、现代汉语语义词典[10]、中国科学院声学研究所黄曾阳教授提出的HNC概念层次网络等[11]。1997年情感计算的概念由MIT媒体实验室Picard教授提出[12],情感词典的构建研究起步。情感语义词典是文本情感分析研究的基础。情感语义词典注重情感词的义元和各类语义关系。基于情感语义词典的词汇间关系,可以更好地分析文本情感信息。但现有的情感语义词典缺乏情感语义关系,如何自动构建情感语义关系显得非常重要。
1 相关研究
国外情感词方面获取研究主要集中在情感倾向词汇获取和极性判断。WIEBE等基于少量标注的词汇种子,根据种子分布相似性对主观形容词进行聚类,实现对未标注主观形容词的分类提取[13]。RILOF等采用基于模式匹配利用步步为营算法实现主观性名词抽取[14]。BARONI和KAJI等基于网络 概念共现互信息识别主观性形容词[15]。MOILANEN等基于语素进行情感新词发现并标注等[16]。文献[17]使用英文连词关系,抽取形容词情感倾向。Turney等利用情感种子在网络搜索引擎查询片段,基于情感词汇的互信息PMI判别词汇的情感倾向的极性[18]。
中文情感词典构建主要的研究思路为基于语料统计以及语义词典等方法。基于语料的情感词典构建方法通过统计词语间的共现频率信息或语义情感词典利用词语相似度来计算词语的语义倾向[19]。主要使用的中文语义词典包括HowNet和同义词词林等。朱嫣岚等提出基于语义相似度和语义相关的计算词汇语义倾向性方法,通过计算目标词汇与HowNet中已标注褒贬性词汇间的相似度得到目标词汇的倾向性[20]。李军等采用机器学习方法进行语义分类[21]。大连理工大学信息检索研究室采用人工标注和自动分类的方法构建情感词汇本体[22]。柳位平等采用人工挑选情感词汇结合HowNet语义相似度计算的方法构建了中文基础情感词词典[23]。台湾大学整理构建了中文情感词典NTUSD。张成功等整理了包含基础情感词典及领域词典、网络词词典及修饰词词典的综合词典[24]。周咏梅等考虑情感词在不同语义环境的情感倾向,基于HowNet和Senti-WordNet建立中文情感词典SLHS[25]。林江豪等利用SO-PMI技术构建中文情感词典[26]。陈建美等基于情感词汇语法特征和CRF自动获取情感词[27]。金宇等提出基于直推式学习的中文情感词极性判别方法,情感词的词源来自《现代汉语大辞典》[28]。很多学者对现有语义词典构建中文情感词典的研究正说明了现有情感词典的不足[29-30]。
互联网汇集了很多人的智慧和知识积累,包括各类网站和知识百科(维基百科、互动百科、百度百科等等)。利用互联网的海量知识获取概念及语义关系,已得到很多学者的共识[31-32]。研究者主要利用互联网的海量信息,基于情感种子词汇或现有词典,利用搜索引擎返回的共现抽取情感词汇,计算情感词倾向和权值等。如阳爱民等在利用NTUSD和HowNet词典构建基础词典的基础上,选用情感种子词,基于搜索引擎构建情感词典[33]。搜索引擎是面向全网搜索,需要经过分词、规则、互信息等过滤词汇,算法复杂度高。
综上所述,目前情感词典的自动构建研究中,主要是面向词汇的发现、情感分类和情感倾向标注,缺乏情感词汇的语义关系抽取。相对全网数据数据源的数据抽取,尚没有利用知识百科针对情感词汇语义关系抽取的相关研究。由此提出基于网络知识百科,获取情感词汇和词汇间语义关系的方法,同时利用抽取的情感同义词语义关系,自动扩展标注情感词汇倾向。
2 情感语义自动抽取
人类情感有复杂性,描述同类情感可选择很多相近词汇来表达,由此提出一个假设:每个情感概念一般都有同义词和反义词。基于这个假设,提出利用情感种子词汇基于同义词和反义词关系抽取情感词汇,并递归抽取新的情感词汇同义词和反义词关系的算法。
2.1 抽取流程
情感语义关系抽取采用的是递归算法,选用网络百科数据源为百度汉语。网络百科是志愿者填写,缺乏审核,选择两类标签抽取,目的是验证数据的准确性。数据源标签具体第一个是情感种子词汇的近义词和反义词标签,第二个是情感词汇的释义标签。
词汇的同义词集合和反义词集合不同,所以这两个集合分别利用递归算法抽取,即每个新抽取词汇被视为新的种子进入递归抽取其同义词或反义词。算法的输入为情感种子词汇Seed(x),用Seed(x)作为同义词种子Syn-Seed(x)和反义词种子Ant-Seed(x)。抽取结果为新的情感词汇R(x),及其同义词集合Syn(x)和反义词集合Ant(x)。抽取算法对于每一个情感词汇种子,首先在过滤规则1和规则2(过滤规则见2.2)的条件下,利用数据源百度汉语中抽取其近义词Syn(x)和反义词Ant(x),同时抽取在数据源百度汉语中的释义Exp(x)。然后,对于抽取获得的近义词Syn(x)和反义词Ant(x)经过规则3过滤,并分别和百度汉语抽取Exp(x)结果进行合并去重,获得的结果添加到Syn-Seed(x)和Ant-Seed(x)。最后,算法返回到第一步实现递归,直到种子集合的所有都使用过,将情感词汇种子R(x)、同义词集合Syn(x)和反义词集合Ant(x)输出为抽取结果。
2.2 抽取规则
抽取规则设计主要是为了减少噪音数据被抽取,提高抽取精度和效率。抽取方法采用递归算法,错误的语义和词汇可视为噪音数据。噪音数据不仅消耗时间,且影响抽取精度。由于数据源百度汉语由非专业人士填写,其中不乏词汇的语义、拼写等错误。如检索词汇“惊讶”,其近义词里发现拼写错误“惊呀”,“惊讶”又出现为自己的近义词。经过多次测试,提出的抽取过滤规则如表1所示。
一个词汇自身不可以定为同义词或反义词,由此设计规则1;一个词不可能既是一个词的同义词又是反义词,由此设计规则2;根据假设,非感情词汇相对的同义词和反义词较少,此外,错误拼写词和错误语义在所有的数据源里出现可能性低,由此设计规则3。

表1 抽取算法过滤规则
2.3 抽取测试与分析
抽取算法测试阶段,任选五个种子词汇抽取了情感语义词汇。表2是从1 532个词中连续取出了30个词示例,表中第2列为不通过规则3抽取出来的词汇,第3列为词汇拼写正确结果(不标注的为抽取结果书写正确的词汇),第4列标注了错误类型,包括5类错误拼写、地方话、非词、不常用词和其他,表中标注“1”表示是该类型,不标表示不是该类型。拼写错误词基本都是情感词汇,这些词对情感词汇抽取没任何意义;地方话基本上是情感词汇如“懆急”;非词主要是由单字和词汇组合构成,这些结果基本上也不是情感词汇;不常用词基本是情感词汇;其他主要包括非情感词如“仙游”、“微博”,专业用词如“解亻亦”是医学专用词,还有很少量情感词汇。经过统计,被过滤的1 532词汇中近48.7%为拼写错误,3%为地方话,16.9%不是常规词汇,4%为不常用词,其他为27.4%。
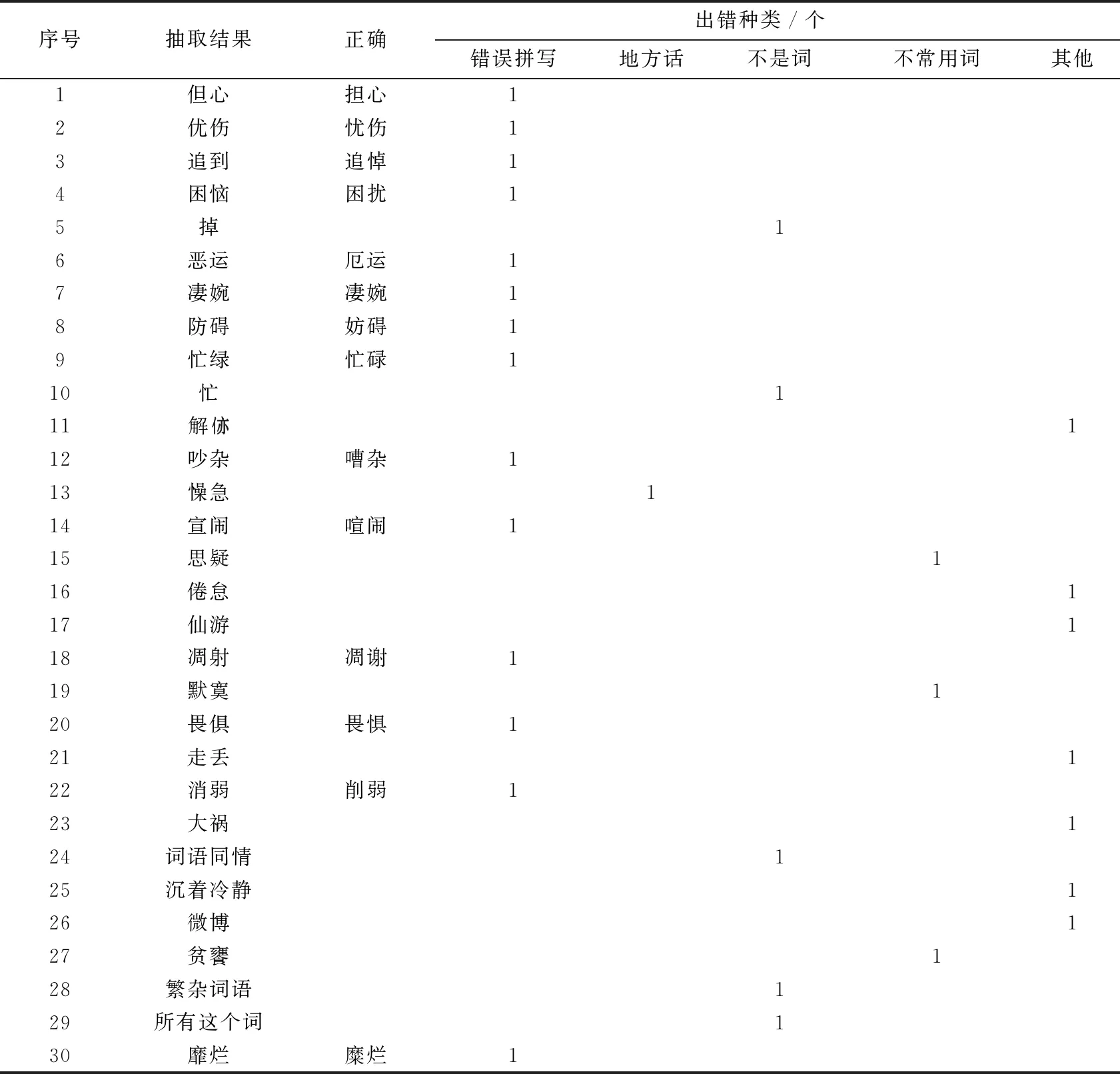
表2 无过滤规则3算法抽取的词汇示例
利用40个情感词汇种子,抽取算法结果经过合并去重,最终抽取结果记作中文情感语义词汇集合CASL(Chinese affective semantic lexicon)。CASL总计22 068个词汇。CASL实现包括中文情感词汇以及这些词汇的同义和反义两个语义关系。
对于CASL中22 068个词汇,通过和现在常用的情感词典做了比较(详见表3),结果说明抽取算法有效地抽取了情感词汇。选择4个词典,包括1个语义词典HowNet(使用情感倾向词汇)和3个常用情感词典:清华大学褒贬义词典、台湾大学NTUSD和大连理工大学的情感本体。表3中“覆盖词量”指CASL与比较词典重合的词汇数量,最高覆盖数量为10 829个词汇。结果表明,CASL有效地抽取了中文情感词汇,及其同义词和反义词等两种语义关系;此外,也表明现有的中文情感词典对情感词汇的认定不同。

表3 CASL对现有情感词典覆盖的词汇量
3 情感倾向标注及结果分析
情感词汇的倾向标注词典对情感计算和分析十分重要,标注词汇的完整性和情感倾向分析精度直接相关。对CASL词汇的情感倾向标注方法是基于现有的情感词典和CASL中词汇的语义关系。抽取算法获得的CASL包括大量的情感词汇、词汇的同义词和反义词关系。基于情感语义关系,近义词的褒贬性一致,反义词的褒贬性相反。基于同义词和反义词关系,利用现有的情感词典(前面4个词典)标注及扩展标注抽取词汇的情感倾向。基于情感语义关系的CASL词汇的情感倾向标注结果如表4所示。CASL的情感倾向标注方法为:首先标注CASL覆盖现有词典的情感词汇,结果为表4中“词典标注词汇数量”。然后,基于CASL中情感词汇的同义词集合,对于CASL中的未标注的词汇Wi进行标注。扩展标注方法是从前向后循环检索Wi的同义词Si,如果发现有情感标注的词汇,则设置Wi的情感倾向和Si一致;然后,基于CASL中情感词汇的反义词集合,对于CASL中的未标注的词汇Wi,从前向后循环检索Wi的反义词Ai,如果发现有情感标注的词汇,则设置Wi的情感倾向和Ai一致;在倾向扩展标注中,如果在Si和Ai都没有找到,就不标注Wi的情感倾向。
基于4个基本词典,CASL的情感倾向扩展标注实验结果如表4所示,结果说明基于情感语义关系的情感词汇的倾向标注方法有效。表中第3列为基于语义关系标注词汇数量和标注正确的数量;表中第4列说明方法对CASL扩展标注了178.7%、167.3%、261.2%和59.1%的词汇情感倾向。情感标注的准确率分别是88.1%、86.9%、86.2%和79.1%。基于4个现有词典,实现CASL词汇平均扩展166.6%情感倾向标注,78.1%准确标注。

表4 基于情感语义关系的CASL词汇情感倾向标注结果
4 结束语
基于情感的复杂性,提出了一个情感词汇的假设,实验结果证明这个假设是可靠的。利用中文网络知识百科,提出了一种简单、高效的方法抽取中文情感词汇,并成功地抽取了词汇的两个重要语义关系即同义词关系和反义词关系。通过和现有情感词典的比较,该方法抽取结果基本覆盖现有情感词典的词汇数量较高。同时,基于现有情感词典和抽取的情感词汇间语义关系,实现了快速地扩展情感词语的倾向标注。
该方法的局限性是过于依赖网络词汇的准确度。虽然可以通过规则去过滤,但规则过滤会减少情感词汇的抽取。抽取数据源的语义错误、错别字等问题影响了数据的抽取结果。情感语义关系词汇CASL的构建,更加方便情感语义词典的构建和文本的情感分析。研究中已经基于情感语义关系,进行了情感词汇倾向自动扩展标注。今后的研究,还可以进行情感词汇情感权值自动扩展标注和计算、情感词语语义相关度计算等等。此外,基于规则抽取算法过滤出来的词汇有很大一部分是错误拼写,这一部分词汇将被考虑生成一个中文的错误拼写词典。
猜你喜欢
小学生学习指导(低年级)(2021年6期)2021-07-19 06:06:50
学生天地(2020年24期)2020-06-09 03:08:54
开放教育研究(2020年2期)2020-03-31 01:54:14
文苑(2019年24期)2020-01-06 12:06:50
小天使·一年级语数英综合(2019年6期)2019-06-27 06:36:15
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
当代修辞学(2013年4期)2013-01-23 06:43:10
