
利用SemRep语义网及MeSH语义网表达单篇论文知识
2019-06-13 08:02:20
中华医学图书情报杂志 2019年1期
知识组织与表达是知识管理领域的核心内容,对科学论文中蕴含知识的表达是文本挖掘和知识发现的基础和核心。语义网络作为知识表达的一种方式,为文本挖掘和知识发现后结果的可视化呈现提供了坚实基础。语义网络是一种文本网络表示模型,随着社会复杂网络逐渐受到关注,越来越多的研究将语义网络应用于文本挖掘、知识发现和知识图谱的表示[1]。
目前,有关单篇科学论文内容表达的研究较为少见。PubMed数据库中揭示单篇论文内容特征的方式包括论文题目、摘要、关键词及MeSH主题词等,缺乏以语义网络为基础的揭示单篇科学论文内容特征的知识表达方式。关于文献集内容语义网络表达的典型代表为Kilicoglu等开发的Semantic MEDLINE自动摘要系统[2],利用自然语言处理工具SemRep将文献摘要集处理为概念及语义关系集,以语义网络图的形式呈现检索结果,为用户提供直观清晰的研究内容,但仅适用于某一研究主题的文献集可视化呈现,未能实现单篇论文内容的揭示与表达。
SemRep作为一种基于自然语言处理技术的数据挖掘软件,以一体化医学语言系统中的超级词表、语义网络和专家辞典为基础[3],专指性较强,反映学科知识也较具体,但从文献中提取出的语义关系分散于其挖掘结果之中,不利于对所提取的关系进行统计分析[4]。以MeSH主题词对论文内容进行标引是生物医学权威文献数据库中组织和表达论文内容的主要形式,其优点是可以排除“多词一义”、“一词多义”和词义含糊现象,使标识与概念尽可能一一对应,具有相当高的专指度[5],能较为确切地表达文献的主题概念,缺点是不能反映MeSH主题词间的语义关系。 本文将语义网络引入单篇论文内容表达研究领域,并结合MeSH主题语言与SemRep对自然语言概念抽取的优势,以SemRep语义网及MeSH语义网的形式呈现单篇论文的研究内容,并对2种网络进行评价比较。
1 数据与方法
1.1 研究样本的选择
本文利用MedSci 2018年期刊智能查询系统对医学期刊进行检索并排行,选取IF值(5年)≥3的10种期刊,每种期刊选取研究主题为diabetes mellitus的代表性论文2篇,共计纳入20篇科学论文作为后续分析的数据集。本文是对单篇论文内容语义网络表达的探索,经反复探索验证后发现,对选取的期刊论文达到以下要求时形成的语义网络效果较好。一是论文篇幅适中。因为论文过长会导致所形成的的语义网络过于庞大复杂,不利于后续分析,过短则会导致形成的语义网络图不足以反映论文具体研究内容。二是选取的论文在PubMed中标注的MeSH主题词数量在10~20个,且主题词概念尽量具体。以降血糖药为例,论文标引的MeSH主题词应为具体的降血糖药如Metformin(二甲双胍)而非其宽泛的上位类Hypoglycemic Agents(降血糖药)。
1.2 SemRep语义网及MeSH语义网的构建
1.2.1 概念间关系的提取
本文使用自然语言处理工具SemRep对单篇科学论文中的概念进行抽取和语义关系表达。SemRep可以实现将单篇科学论文中的实义词映射为UMLS中规范的概念词。目前UMLS术语表已经涵盖了320多万个概念、133个语义类型和54个语义关系,概念不仅被赋予至少一个语义类型,同时规定了语义类型与语义关系搭配的规则[6],为揭示概念及概念间关系提供了独有的优势,也为后期文本可视化分析奠定了基础。
抽取出映射概念之间的关系。对于输入的文本,SemRep将其中的句子处理为形如“主语|谓词|宾语”的语义述谓项( Semantic Predication),其中主语和宾语为UMLS中的概念,谓语为UMLS中的语义关系[7]。示例如下。
Childhood obesity is a predictor of an increased rate of death,owing primarily to an increased risk of cardiovascular disease.(1)
|Obesity|dsyn|PREDISPOSES|Diabetes Mellitus,Non-Insulin-Dependent|dsyn|(2)
项(2)为SemRep对句子(1)处理后所产生的语义述谓项,其中Obesity为主语,PREDISPOSES为语义关系,Diabetes Mellitus and Non-Insulin-Dependent为宾语,主语及宾语的语义类型均为疾病或综合症(disease or syndrome,dsyn)。
1.2.2 SemRep语义网及MeSH语义网的绘制
语义网络图表示模型是以图论为基础构建的,其基本模型可以定义为一个三元组:G=(N,E,W),即图元素包括节点(N)、边(E)及边的权重(W)[8]。本文中,节点(N)表示SemRep处理后的概念,边(E)表示概念间的语义关系,边的权重(W)表示SemRep处理后此概念对共现的频次。利用SemRep处理单篇论文全文所产生的概念及概念间语义关系构建单篇论文SemRep语义网,MeSH语义网由SemRep处理后生成的概念与该篇论文在PubMed中标引的MeSH主题词匹配后形成。构建过程采用的可视化分析工具为Gephi[9]。
1.2.3 SemRep语义网的简化及描述
利用Cytoscape[10]软件中的PEWCC算法精简网络,可找到整体网络的近似最大派系。PEWCC算法[9]首先利用PE-measure评估概念节点间语义关系的可靠性,然后基于加权聚类系数(WCC)的概念检测整体网络,从而抽取出与整体网络最为接近的子图。语义网络简化的目的是为了加深评价人员对SemRep语义网及MeSH语义网的理解,同时对抽取出的SemRep语义网子图的内容进行简要的语言描述以提高评价的准确性。
1.3 SemRep语义网及MeSH语义网的评价指标
设计调查问卷评价最终形成单篇论文SemRep语义网及MeSH语义网是否能够表达该篇论文的研究内容,调查对象为14位中国医科大学文本挖掘相关领域的研究人员,评价纳入数据集(10种期刊的20篇单篇论文)SemRep语义网及MeSH语义网的全面性、准确性和易用性(根据评价人员对语义网络各个指标的满意程度评分从低到高为1~10)。利用SPSS 23.0软件对结果数据进行统计分析,统计方法使用独立样本t检验,评价指标具体如下。
全面性:SemRep处理后得到的概念与MeSH主题词相比是否全面。
准确性:SemRep处理后得到的概念与MeSH词完全对应,未标引为MeSH词,但经SemRep处理后出现次数较多且能反映论文内容的概念。
易用性:语义关系标签表达概念间关系是否准确,可视化网络表达论文内容的方法是否直观清晰。
2 结果与分析
2.1 期刊及论文选取数据集
根据研究期刊及单篇论文选取标准纳入的数据分析集见表1。以期刊TheNewEnglandJournalofMedicine中的论文“Childhood adiposity,adult adiposity,and cardiovascular risk factors.” (PMID:22087679)为例进行实例研究,揭示单篇论文SemRep语义网及MeSH语义网的构建过程。
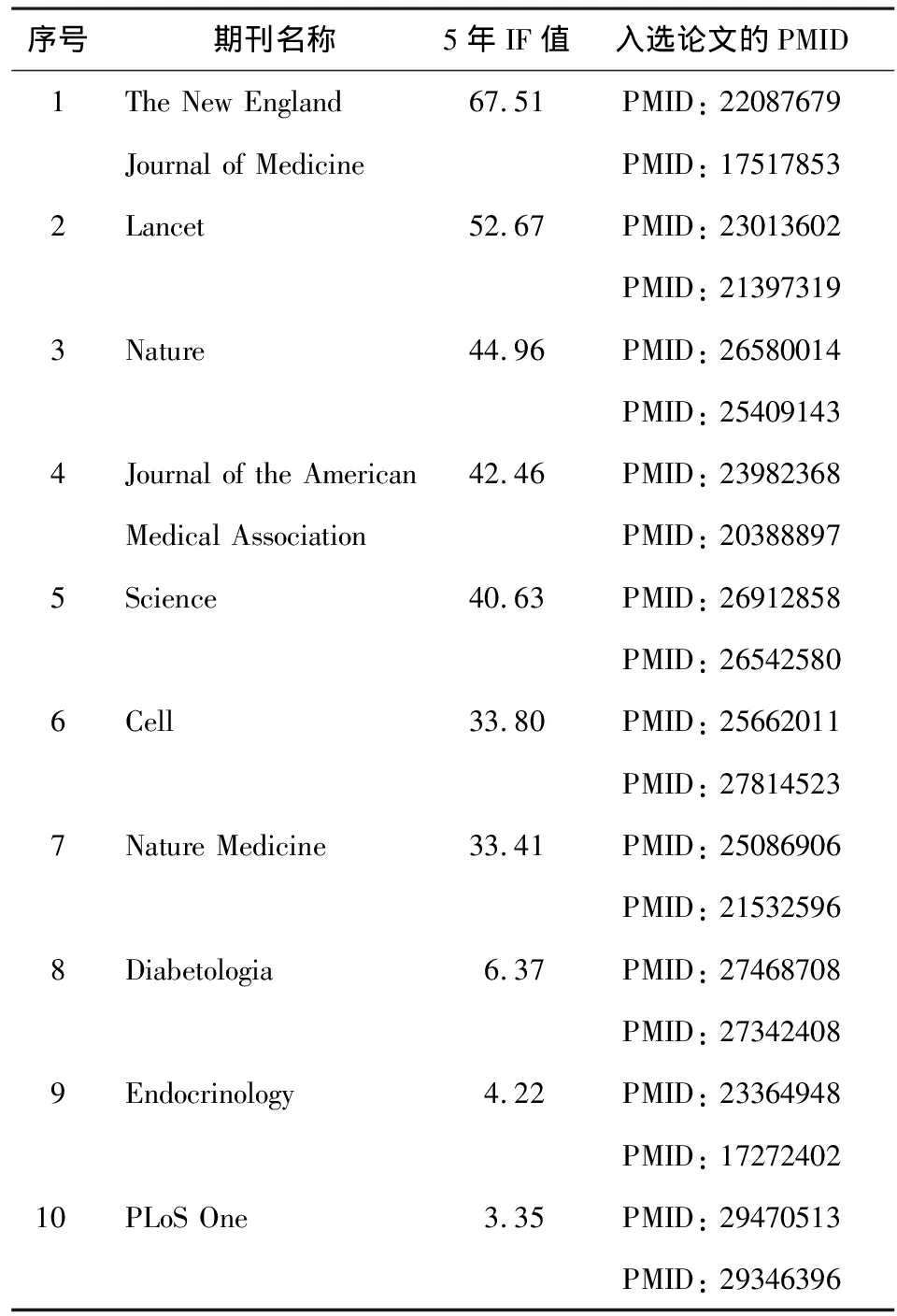
表1 纳入期刊及代表性科学论文的PMID
2.2 实例研究结果
2.2.1 单篇论文语义述谓项提取结果
对选取的期刊论文“Childhood adiposity,adult adiposity,and cardiovascular risk factors.”利用自然语言处理工具SemRep对其全文进行了概念及语义关系的提取,共得到53项语义述谓项,相同语义述谓项经合并后最终形成了34项语义述谓项组成的单篇论文语义述谓项集。前10项语义述谓项及其在该篇论文中相应语义述谓项出现的频次见表2。
2.2.2 单篇论文的机器处理结果与人工标引结果的比较
该篇论文在PubMed上标引的MeSH主题词(去除特征词后)、经自然语言处理工具SemRep处理与MeSH主题词完全对应的概念及部分未标引为MeSH主题词,但经SemRep处理后能反映论文内容的概念(表3)。
从表3中可看出,去除Adult、Child等特征词后,该篇论文标引的MeSH主题词共10个,经SemRep处理与MeSH主题词完全对应的UMLS概念为7个,覆盖率达70%。此外,经人工筛选除去与MeSH主题词完全对应的概念外,经SemRep处理后能反映论文内容的概念为7个,其中Dyslipidemias与MeSH主题词Hypertriglyceridemia、Hypercholesterolemia概念相近,Overweight、Carotid-Atherosclerosis等虽未标引为MeSH主题词但也能反映论文内容的概念,在一定程度上弥补了MeSH主题词反映论文全文内容不足的缺陷。
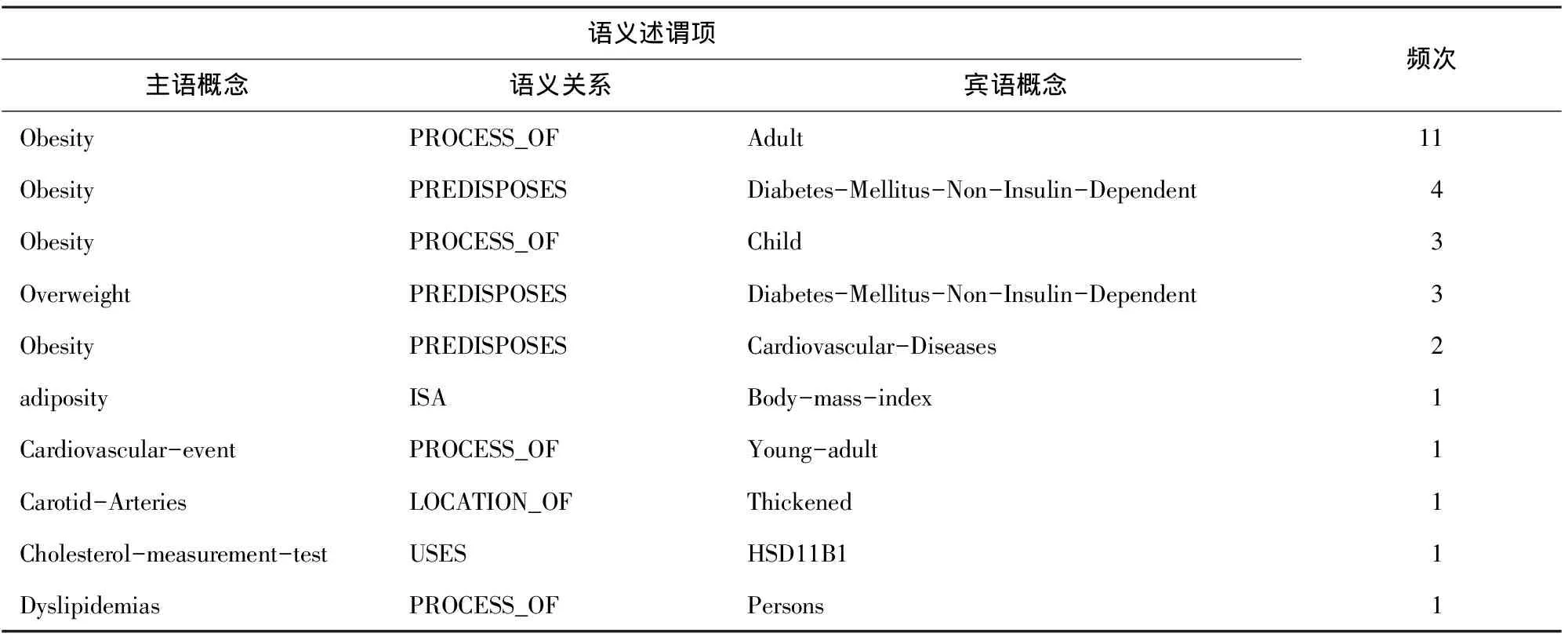
表2 单篇论文语义述谓项表达示例
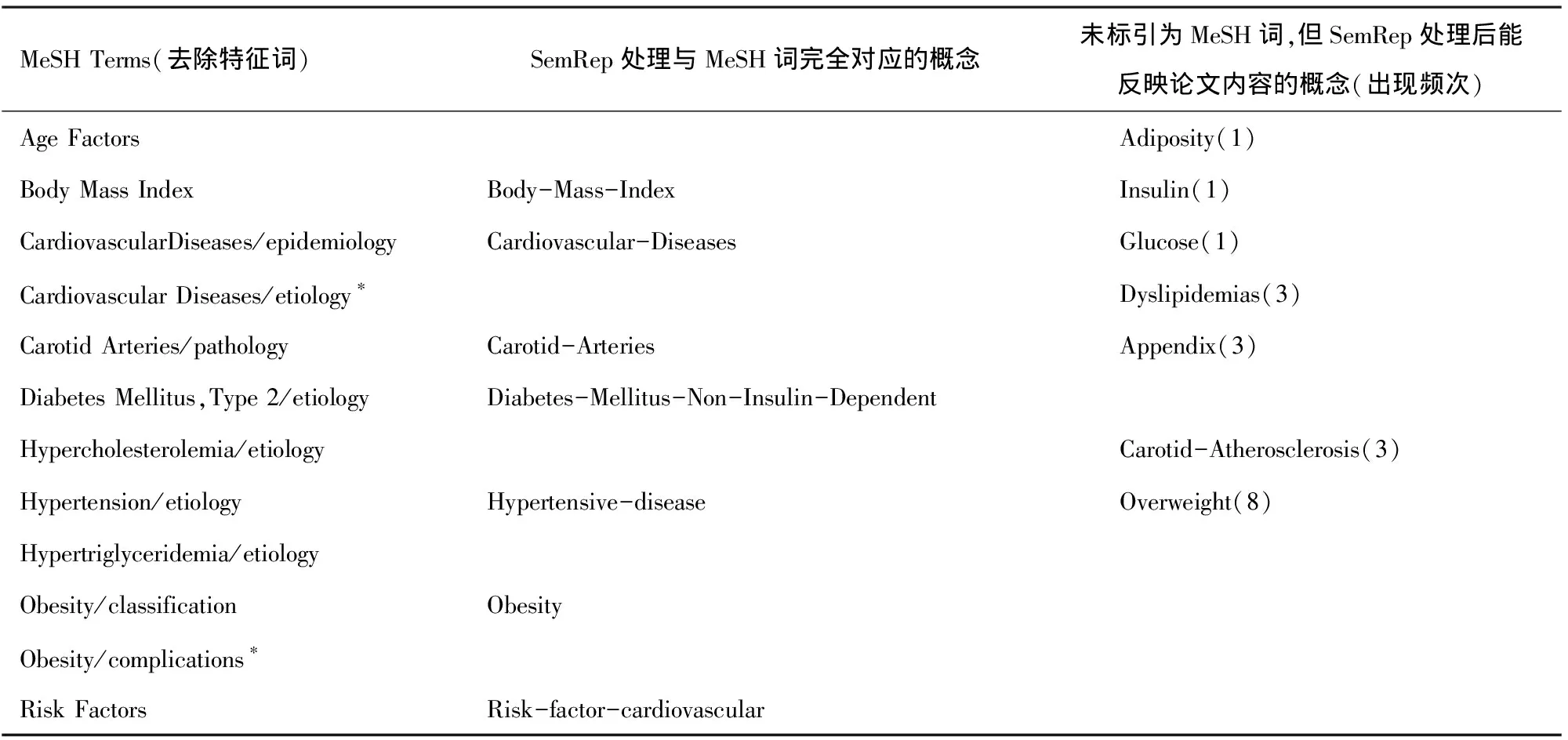
表3 机器处理结果与人工标引结果的比较
2.2.3 单篇论文SemRep语义网及MeSH语义网构建结果
将提取出的语义述谓项集导入Gephi,并利用Gephi中YifanHu的多水平算法生成语义网络图(图1,图2)。其中,图1表示单篇论文经SemRep处理后形成的概念语义网络图(简称“SemRep语义网”),图2为SemRep处理后生成的概念与MeSH主题词匹配后形成的MeSH语义网,即图1去除与MeSH主题词不直接相连的概念节点后所形成的语义网络图。2个图中,边的颜色对应的语义标签为橙色(ISA)、粉色(LOCATION_OF)、深黄色(PREDISPOSES)、绿色(PROCESS_OF)、淡紫色(USES),其中红色填充的概念节点表示与MeSH主题词完全对应的概念。

图1 SemRep语义网
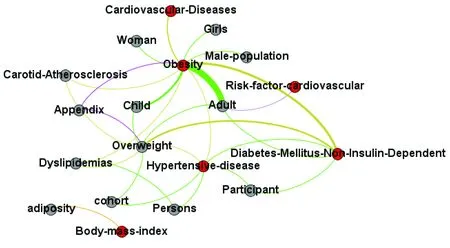
图2 MeSH语义网
2.2.4 单篇论文语义网络简化图及结果解析
利用PEWCC算法对图1所示的单篇论文SemRep语义网进行网络简化,抽取出与整体网络最为接近的子图,经过语义标签设置、重复边移除等处理之后,形成了图3所示的该篇论文的语义网络简化图。
从图3看出,肥胖、超重人群易患高血压疾病及非胰岛素依赖型糖尿病,高血压疾病是非胰岛素依赖型糖尿病的一种过程。
2.2.5 单篇论文语义网络的节点度数中心度分析
将得到的单篇论文语义述谓项集进行Gephi可视化处理的同时,将其导入Ucinet[11]对网络节点度数中心度进行分析。该篇论文的语义述谓项集经Ucinet分析后所示的概念节点度数中心度分布见表4。从表4可见,点的绝对度数中心度(Degree)大于1的概念节点。
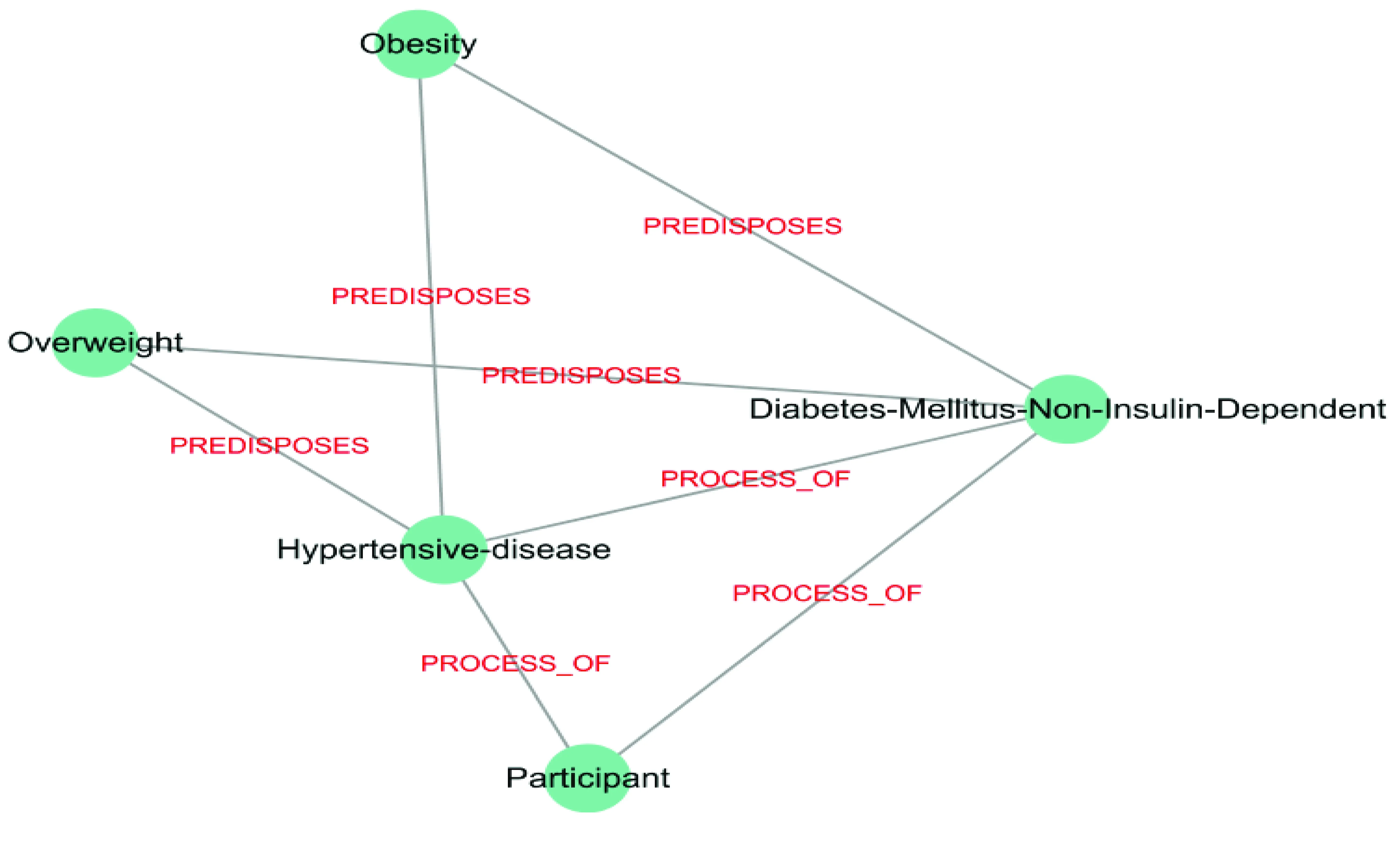
图3 语义网络简化图
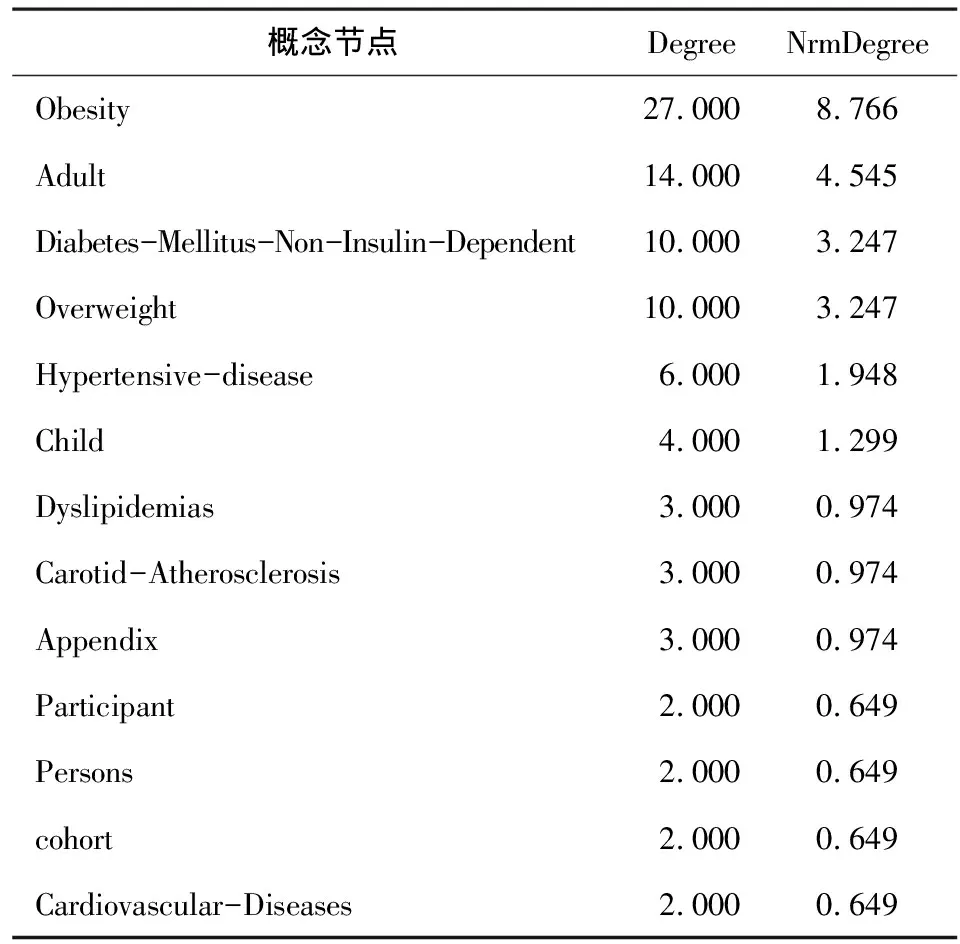
表4 概念节点度数中心度分布
从上述节点度数中心度分布可以看出,Obesity、Diabetes Mellitus,Non-Insulin-Dependent,Overweight,Hypertensive disease等概念节点度数中心度较高,说明在此语义网络中这些概念较为重要。根据这些概念节点的度数中心度分布可初步推断该篇论文的内容为肥胖、超重人群易患高血压、颈动脉粥样硬化、非胰岛素依赖型糖尿病等疾病。
2.3 SemRep语义网与MeSH语义网的结果评价
以语义网络评价标准对纳入数据集进行评价,在调查对象的14位研究人员中,医学信息学院情报学、文献学、图书馆学教研室教师各3人,均具有10年以上的研究经验;图书馆参考咨询部研究人员3人,均具有3年以上的研究经验;情报学专业硕士研究生2人,在科室分布、研究经验、学历分布上均有差异。发放问卷全部回收且有效,对其进行统计分析的结果见表5。

表5 文献集SemRep语义网与MeSH语义网评价结果比较
注:表中t值为独立样本t检验的检验统计量,P<0.05表示差异具有统计学意义
从表5可见,评价人员对SemRep语义网及MeSH语义网在表达单篇论文内容方面的满意程度。从全面性看,评价人员对SemRep语义网和MeSH语义网评分均值均高于8分,且分值差异较小,说明2种网络均能全面覆盖单篇论文的主要研究内容;从准确性看,2种网络的评分均值均不足8分,说明二者所揭示的论文全文的主要概念与MeSH主题词相比还不够准确,单篇论文内容的表达准确性还有待提高;P<0.05说明2种网络在表达单篇论文内容的准确性方面存在显著性差异,且MeSH语义网评分高于SemRep语义网的主要原因为SemRep语义网中冗余、无用概念较多,从而造成准确率的下降;从易用性看,MeSH语义网的评分均值为8.23,高于自然语言语义网,这是因为MeSH语义网中概念节点及语义关系较少,网络清晰,更容易获得评价人员的肯定。整体上看,MeSH语义网在表达单篇论文内容的全面性、准确性及易用性的评分均值均高于SemRep语义网,但2种网络在表达单篇论文内容的准确性方面还有待提高。
3 结论
本文所构建的2种语义网络所提供的语义信息具备一定的文献挖掘潜力,可实现对单篇科学论文内容的揭示与表达。将复杂网络分析方法与语义搭配模式相结合,能够为诸如信息抽取、知识发现、知识图谱及学科研究态势分析等研究提供新的方法和思路。通过比较SemRep语义网及MeSH语义网在表达单篇论文内容的全面性、准确性及易用性方面的异同,根据评价人员对SemRep语义网及MeSH语义网的调查评价结果,发现MeSH语义网相较于SemRep语义网更能深入细致地揭示单篇论文中的主要概念及概念间的语义关系。其主要原因为获得MeSH主题词表的支持,排除了冗余、无用概念的干扰,从而实现单篇论文研究内容的深度表达与揭示,对文献的挖掘更加灵活、强大。
随着语义网络研究的深入,对文献信息的挖掘必然从以概念为对象向以概念结合语义关系为对象的方向发展。利用MeSH语义网表达单篇论文知识的方法可广泛应用于探索施引文献与被引文献之间内容上的异同,探索高质量论文(或高被引论文)与一般论文的差别,探索单篇论文内容的新颖程度,为科研人员进行科研绩效评价提供一种新途径。
4 讨论
本文以语义网络图的形式提出了一种表达单篇论文研究内容的新途径。随着信息技术的发展,不久后我们将能够基于规则和机器学习等方法实现单篇论文全文概念及语义关系的自动化抽取及可视化,即将单篇论文全文输入应用程序,系统自动进行全文概念及关系的抽取,进而实现单篇论文全文内容的可视化,形成单篇论文的语义网络图。用户理解文献内容将不仅仅局限于参考MeSH主题词及文献摘要,还能够结合单篇论文SemRep语义网及MeSH语义网快速浏览和分析文献内容,并清晰直观地了解概念如何在语义网络结构中相互关联。在以后的研究中,我们将能够利用本体构建单篇论文语义网络知识库,实现单篇论文语义网络的规范表达。
本文的局限性主要体现在两方面。一是语义网络复杂性带来的限制。如果单篇论文的篇幅过长,经SemRep处理后所形成的语义述谓项会随之增加,语义网络复杂度也会相应增加,不利于直观清晰地表达单篇论文研究内容,因此此方法还不适用于处理篇幅过长的单篇论文。二是冗余、无用的语义述谓项带来的限制。单篇论文全文经SemRep处理后所形成的语义述谓项存在冗余、无用现象,同一实体概念搭配过多特征词概念,影响单篇论文内容的表达。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
资源信息与工程(2019年2期)2019-05-09 01:29:30
温州医科大学学报(2018年8期)2018-03-03 01:41:09
现代语文(2016年21期)2016-05-25 13:13:44
温州医科大学学报(2016年2期)2016-03-16 08:16:38
大连民族大学学报(2015年2期)2015-02-27 08:28:11
西北工业大学学报(2015年1期)2015-02-22 00:29:19
西北工业大学学报(2015年1期)2015-02-22 00:29:19
沈阳医学院学报(2014年4期)2014-12-27 13:44:34
疑难病杂志(2014年12期)2014-04-16 05:19:35
