
基于修正的已实现阈值幂变差的股市跳跃波动行为研究
2019-06-11 07:29:34宫晓莉
运筹与管理 2019年5期
宫晓莉, 熊 熊,2
(1.天津大学 管理与经济学部,天津 300072; 2.中国社会计算研究中心,天津 300072)
0 引言
受宏观经济因素和市场突发信息的冲击影响,金融资产收益率会产生急剧的上涨或下跌等跳跃现象。这使股价严重偏离连续波动轨道,引起投资者的恐慌情绪,造成市场持续低迷的氛围。金融资产的跳跃波动行为研究是资本市场研究的重要课题之一。研究跳跃、波动行为,分析跳跃、波动产生的内在机理,理清不同类型市场风险,从而准确地对资产价格动态建模,是衍生品定价与风险管理的前提。理论和实践表明,风险资产价格波动具有随机性和跳变性。股市收益率和波动率的异常波动引起的跳跃行为,对金融衍生品定价、资产配置和风险管理至关重要。对波动的计量需要通过市场可观测的样本数据进行估计和推断。已有的连续时间框架下随机波动建模和离散框架下GARCH波动率建模均是在低频数据基础上进行的,损失了大量的日内信息。随着计算机电子高频交易系统的完善,基于高频数据对金融资产波动动态进行测度和建模成为新的趋势,不但充分利用了日内交易数据所包含的信息,而且不需要复杂的模型推导。学者们的研究焦点转移到了探索高频资产价格波动内包含的动态规律。实证研究发现,沪深股市资产价格过程并非连续变化,还存在非连续的跳跃突变行为,同时不能忽视收益率和波动率之间的杠杆效应[1,2]。将资产价格波动和跳跃区分开来进行研究对价格建模有重要意义。而在资产定价和风险管理中是否考虑跳跃的存在和杠杆效应的存在,会对结果造成显著的差异[3,4]。因此,在对金融收益率或波动率建模时,需要考虑跳跃的引入对未来预测的重要影响[5]。
波动率的跳跃在数学上可以表示为时间[0,T]内的随机过程{Zt},在时刻t有ΔZt=Zt+-Zt-≠0,则认为发生了幅度为ΔZt的跳跃。国内外对波动率跳跃特征的估计和研究方法主要有两类,分别是基于离散低频数据的参数方法和基于高频数据的非参数方法。参数方法主要是传统的跳跃-扩散模型和连续时间随机波动模型。这类模型需要估计众多未知参数,并且无封闭形式的似然函数,所使用的低频数据难以反映价格变化的日内信息。基于高频数据的非参数化方法,借助计算机的高效数据处理能力,避免了这些困难。非参数方法一般将波动率分解为跳跃部分和连续部分,进而甄别波动率的跳跃情况。Andersen等[6]等利用日内高频数据给出了已实现波动率(RV)的测量方式,已实现波动率分别由连续变差部分和跳跃变差部分构成,并给出了检验跳跃的Z统计量,为后来的跳跃研究奠定了基础。使用高频数据获取跳跃变差,上述方法已成为经典框架,先得到连续变差的估计值,再从总方差中减去连续部分得到跳跃部分的估计值,再使用跳跃检验统计量判别跳跃的真实性。
Barndorff-Nielsen和Shephard[7,8]指出,当不存在跳跃时,二次幂变差(BV)是连续变差部分的积分波动(IV)的一致估计量,并提出了基于双幂变差的跳跃检验渐进统计量,进而甄别出跳跃成分。之后的一系列研究都是基于已实现双幂变差将连续路径变差和非连续路径变差进行分离,如Bollerslev等[9],Corsi和Reno[10]。Mancini[11]提出了阈值幂变差估计量估计积分方差。相比于非参数化方法,该类方法有效地挖掘了高频数据中包含的各类信息,识别效果更好。金融资产价格中广泛存在杠杆效应,利空消息引起的负冲击强于利好消息引起的正冲击。沈根祥[12]采用核平滑技术和跳消除方法对带跳和杠杆效应的时点波动进行估计,对不存在杠杆效应时的时点波动估计方法进行了改进。Aït-Sahalia和Jacod[13]使用阈值截断方法并利用不同抽样频率的幂变差之比构造A-J统计量,发展了伊藤半鞅框架下的跳跃检验的非参数方法,将识别出的跳跃甄别为大幅的有限活跃跳跃和小幅的无限活跃跳跃,并识别了跳跃方差的贡献。A-J统计量所需的假设条件少,对不同类型的跳跃都有效。刘志东和严冠[14]借鉴该方法对我国上证50指数的成分股分行业进行了跳跃分析。杨文昱等[15]利用A-J统计量研究了沪深300股指期货超高频数据的跳跃活动程度。沪深股市作为新兴资本市场,市场跳跃波动状况不同于发达资本市场,日内高频数据中连续出现跳跃的频率非常高。而已有文献的跳跃识别统计量多是基于国外发达资本市场数据得来的,会低估我国市场波动中的跳跃成分。为此,需要改进符合我国股市波动行情的跳跃甄别统计方法。
为考察金融资产收益率波动中的长记忆性、多标度行为,考虑到实证分析中高阶自回归模型刻画长记忆性的复杂性,Andersen等[6]将跳跃纳入波动建模中,使用带跳的异质性自回归RV(HAR-CJ)模型为波动率建模。Corsi等[16]采用多次幂变差统计方法改进Z检验,提高了跳跃连续发生时检验的有效性,同时提出了使用HAR-RV-TJ模型进行波动率预测。田凤平等[17]考虑收益率与波动率的不对称性,将标准化收益率引入预测模型,使用非对称带跳的AHAR-C-TCJ模型研究沪深300股指期货中跳跃成分对股指期货未来波动率的影响。孙洁[18]在考虑了跳跃和隔夜波动后,使用HAR类模型对股市波动率建模,考虑到误差项的厚尾属性,将误差项设定为GARCH形式。王天一和黄卓[19]直接采用已实现的GARCH模型对高频数据进行建模以分析数据中透露的厚尾分布信息。杨科和陈浪南[20]采用阈值双幂变差(TBPV)对上证综指高频数据的跳跃存在性进行检验,并利用ACD和ARCH模型对波动率建模。唐勇和张伯新[21]结合A-J跳跃识别统计量使用ARFIMA类模型对有限活跃的跳跃动态单独建模,发现跳跃方差呈现尖峰厚尾性,波动呈现集聚性,进一步验证了金融市场波动存在分形和非线性特征。柳会珍等[22]基于跳跃扩散理论研究股市跳跃动态演变规律,验证了含跳的HAR族波动率预测模型比传统的EGARCH模型更具有优势。然而,较少有文献综合全面地考虑收益率、波动和跳跃成分间的复杂关系,当前的波动率预测建模框架有很大的改进空间。
已有的跳跃甄别和已实现波动率预测研究并未全面考虑跳跃的存在,波动的集聚和杠杆效应等问题。本文利用考虑跳跃和金融市场杠杆效应的时点波动估计方法对已实现阈值幂变差进行修正,构造新的跳跃检验统计量对跳跃进行识别,并结合阈值截断方法甄别我国股市跳跃的活动性。为考察跳跃和波动率间的相互作用,建立了考虑杠杆效应和波动率聚集效应的波动率预测模型考察不同模型的预测性能,并对我国沪深股市跳跃波动行为进行实证分析。
1 基于修正的已实现阈值幂变差的股市跳跃甄别方法
1.1 跳跃甄别统计量构建
假设股价Xt是定义在滤子概率空间(Ω,F,(Ft)t>0,X)上的适应于滤子F(Ft)t>0的随机过程。股价Xt服从半鞅框架下的连续时间跳跃扩散模型(1)。公式(1)中包含了三类成分,漂移项,连续路径方差成分和不连续的跳跃方差成分。其中,跳跃项由有限活跃的大幅跳跃成分和无限活跃的小幅跳跃成分构成。模型(1)中的连续变差代表着股市中的系统风险,大幅跳跃变差代表着金融市场的异质性风险,小幅跳跃代表了金融市场中的交易风险。
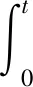
(1)
其中,μ为对数收益率的跳跃测度,v为相应的Lévy测度,bs是连续有界的漂移项,σs是收益率的点波动过程,Ws是标准维纳过程。
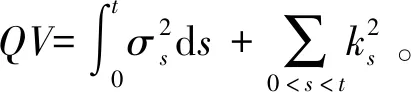
Corsi等[10]提出的已实现阈值多次幂变差(TMPV)形式如下所示:
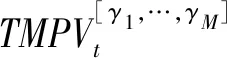
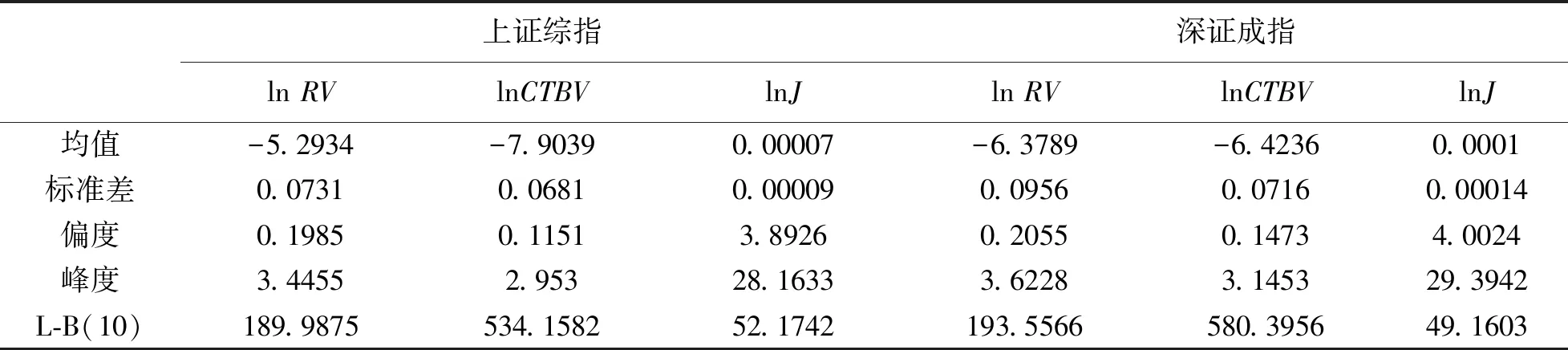
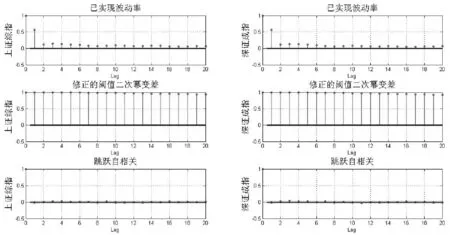
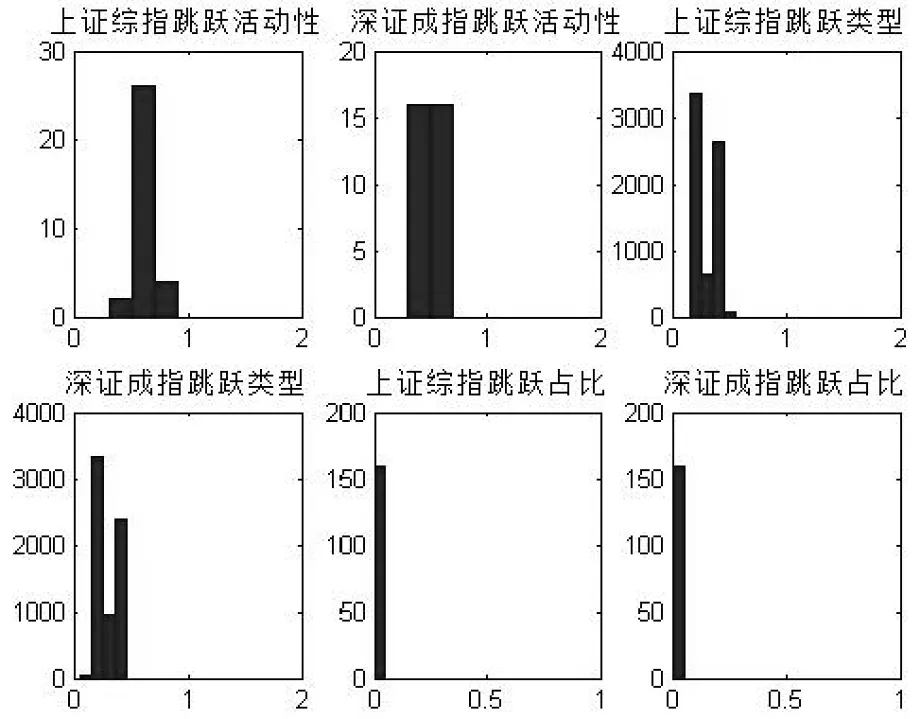
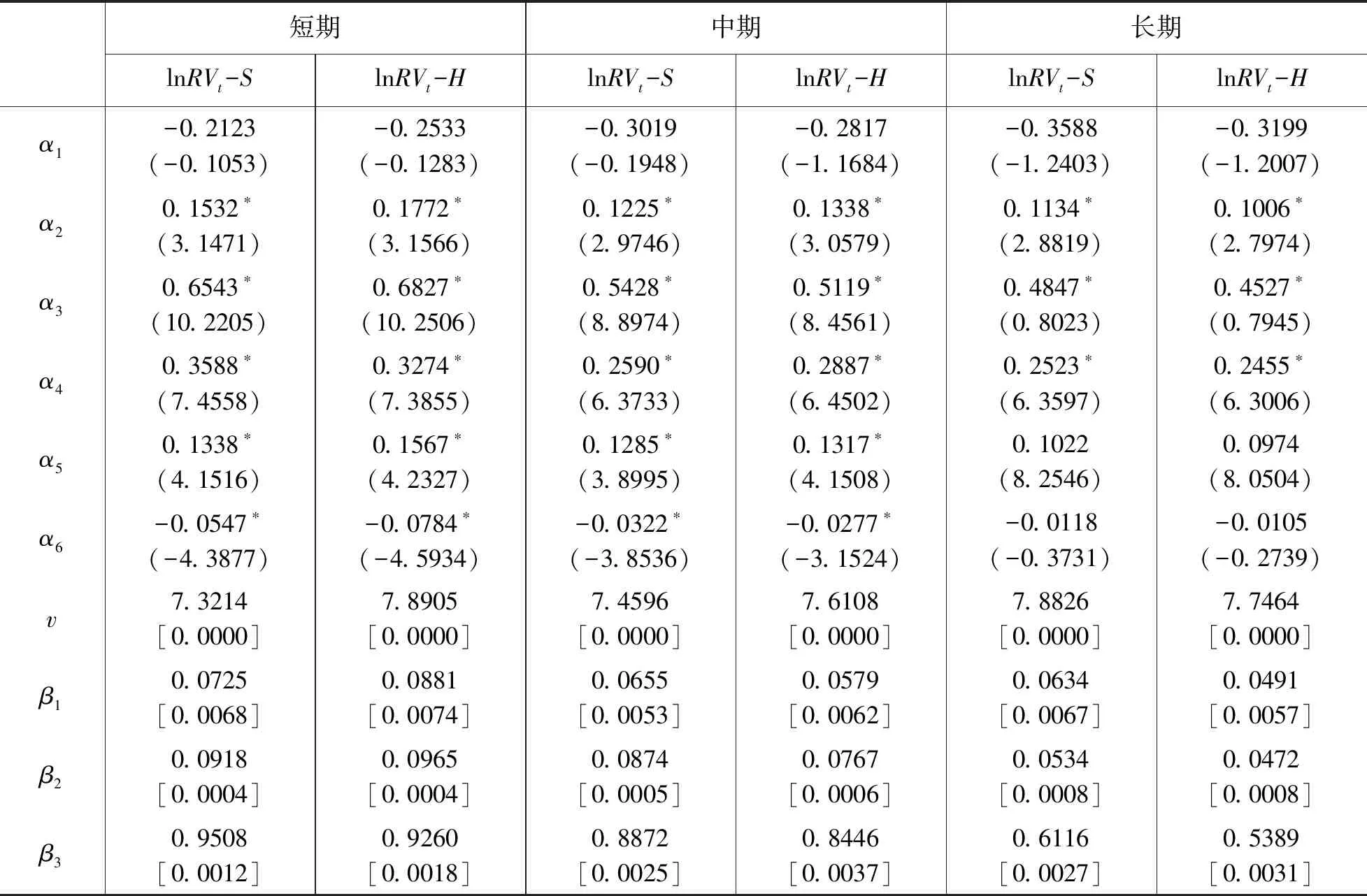
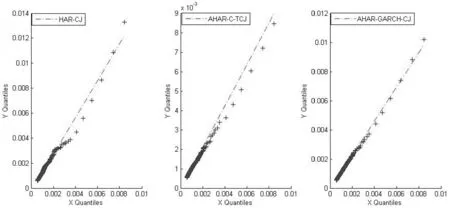
I(|rt,j-k+1|2 (2) 其中,n为t交易日内价格观测值的总数,v是取值为正的随机阈值函数,γ1,…,γM取值为正。 (3) 在TMPV基础上,Corsi等[16]使用C_TZ统计量进行跳跃的识别。本文基于新构建的修正的已实现阈值多次幂变差(MTMPV)估计式,构建起如下的修正的C_TZ统计量(MTZ)来检验资产收益率二次变差中的跳跃成分。相比于国外文献中的跳跃估计量,本文构建的甄别方法防止了部分跳跃成分被包含在波动率连续成分中造成的跳跃低估现象,对跳跃成分进行了符合我国市场实际的偏差修正。 (4) 当抽样间隔无限小时,上述统计量渐进服从标准正态分布。当MTZt的值大于显著水平α的临界值Φα时,资产收益率的跳跃是显著的。基于MTZ统计量,波动率的跳跃序列可由式Jt=I(MTZt>Φα)×(RVt-MTBVt)估计出。其中,I代表示性函数,满足条件时为1,否则为0。 在刻画波动率的长记忆性上,ARFIMA-RV模型和HAR-RV模型都是经典模型,但后者比前者具有更强的可扩展性和清晰的经济学含义,逐渐成为波动率预测的基准模型[27,28]。HAR-RV模型根据不同滞后期的波动率对已实现波动率的影响不同,使用下列形式将已实现方差对其不同周期滞后成分进行回归,RV由其自身滞后项和误差项之和构成。 lnRVt+1=α1+α2lnRVt+α3lnRVti-5+ α4lnRVti-22+εt+1 (5) 其中,RVt,RVTi-5,RVTi-22分别表示日已实现波动率、周已实现波动率和月已实现波动,将其作为解释变量,符合金融研究对日、周和月三种波动水平的统计特点。并且月度滞后期足以刻画波动率的长记忆特性。由于跳跃的广泛存在性,Anderson等[1]的HAR-CJ模型将跳跃变差序列考虑在内,以考察波动率的跳跃成分对未来波动率的影响。将RVt的滞后项替换为连续序列MCt的滞后项,考察了跳跃系列与波动率序列的如下关系。 lnRVt+1=α1+α2lnMCt+α3lnMCti-5+ α4lnMCti-22+α5lnJt+εt+1 (6) 市场的利好与利坏消息对股市波动的冲击具有非对称特点。本文中,为进一步吸收收益率和波动率的杠杆效应,刻画波动率和收益率的不对称行为,引入标准化的收益率。同时考虑波动率误差项的异方差性,将波动率残差项设定为GARCH形式,构建如下新的对数形式的高频已实现波动率模型,即带跳的非对称异质自回归异方差模型(AHAR-GARCH-CJ)。 lnRVt+1=α1+α2lnMCt+α3lnMCti-5+ (7) 大数据金融在实证中的应用已成为研究热点[29]。由于国内外已有大量关于次贷危机前后股市跳跃波动的实证研究,本文基于高频数据的可得性着重研究近年来的股市跳跃波动形态。实证研究选取数据为2014年5月27日至2016年10月21日交易的上证综指和深证成指5分钟高频交易数据。已有研究证明,5分钟高频交易数据受市场微观结构噪音的影响最小[30]。每个交易日选取9∶35~11∶30及13∶05~15∶00区间段的高频交易数据,日内包括48个5分钟高频数据,总计28155个5分钟数据。数据来源于Wind资讯金融数据库。根据已实现波动率的定义计算得到日已实现波动率,使用修正的已实现阈值二次幂变差MTBVt对上证综指和深证成指高频数据进行跳跃甄别,从波动率中分离出跳跃成分后,对跳跃序列的统计特征、跳跃活动性进行研究, 最后采用新构建的AHAR-GARCH-CJ模型进行样本外预测。 表1为股指已实现波动率RVt、修正的已实现阈值二次幂变差MTBVt和跳跃序列Jt的描述性统计量。对数形式的指数标准差分别为0.0731和0.0956,偏离程度较大,股指波动率在这一区间内具有很大的变化。Ljung-Box统计量揭示了各序列自身的相关性,连续变差序列自相关性很强,而跳跃变差序列自相关性很弱,不具有持续性。股指收益率波动的强相关性主要来源于连续成分的强相关性。连续变差的高度自相关性是造成波动率集聚效应的重要原因。无论是上证综指还是深证成指,对数形式的修正的已实现阈值二次幂变差均接近正态分布,这验证了所构造统计量的准确性。跳跃序列的峰度值和偏度值显著过大,具有明显的尖峰厚尾的分布特征。从经济意义上讲,尖峰厚尾分布特征反映了资本市场波动的正相关性,资本市场具有正的反馈效应。已实现波动率和连续变差波动率均较大,说明连续变差部分是日波动率的主要组成部分。深证成指波动率及幂变差的均值和标准差均高于上证综指,说明深市投资风险相对更大,投机性更强。 表1 描述性统计量 注:L-B(10)是滞后10阶的Ljung-Box统计量。 图1展示了RVt、MTBVt和Jt的时间序列图。从图1看出,上证综指和深证成指已实现波动、修正的已实现阈值幂变差和跳跃序列存在显著集聚特性,尤其在2014年12月至2015年1月以及2015年6月至2015年10月期间,并且上证综指的波动率集聚效应强于深证成指。同尖峰厚尾的分布特征类似,波动集聚效应也体现了资本市场的正相关性和正反馈效应。与之前文献做法不同的是,本文的跳跃序列不仅给出了股指的向上跳跃,并且展示了股指的向下跳跃。在与波动率集聚效应相同的时间区间内,股指跳跃序列出现突变,跳变发生频繁剧烈,深证成指的跳跃突变明显于上证综指,股指的较大波动都与跳跃密切相关,变化一致。同时,对比了使用C_TZ统计量与本文的MTZ统计量估计的跳跃序列,发现使用本文所构造的统计量所甄别出的跳跃数目明显多于前者,说明了本文构造的统计量的有效性。限于篇幅,图示在此略去。 图2为波动率分解成分对应序列的自相关图。上证综指和深证成指已实现波动率滞后1期自相关显著,滞后2阶之后自相关性不再显著。而沪深股指修正的阈值二次幂变差序列具有很高的序列相关性,直到滞后20阶序列自相关性仍非常显著。股指跳跃序列自相关性不显著。说明上证综指和深证成指的动态相依性主要由修正的已实现阈值二次幂变差引起,资产收益率二次变差中的连续变差是多期显著相关的,具有长记忆性,而跳跃多是由市场上异质性因素引起,独立性较强,往往与市场上重大的经济或者金融信息等宏观信息发布产生的流动性冲击相关联。 图1 RVt、MTBVt和Jt序列图 图2 RVt、MTBVt和Jt自相关图 表2是使用跳跃活动性检验统计量的跳跃甄别结果。截断水平un代表波动超过半鞅过程的连续成分的标准差倍数,本文中分别设定k=3,4,p=3,4。设定截断水平后,若不存在众多的小幅跳跃,半鞅过程运动过程应类似于连续布朗运动过程。实证结果显示,检验值分布在1周围,表明资产价格增量过程同时具有无限活跃跳跃和有限活跃跳跃,并且以无限活跃跳跃占主导。从圆括号内的相应P值均小于0.05判断,在显著性水平为0.05下5分钟高频股指收益率数据不能拒绝无限跳跃存在的原假设。 表2 跳跃活动性检验 研究资产跳跃的活动性均是对存在跳跃的资产而言的。图3是使用检验方法二与检验方法三得到的上证综指和深证成指跳跃类型及跳跃活动性结果图。从股指活动性强度测度结果看,上证综指β指数介于0.3到0.85之前,呈现无限活跃Lévy跳跃类型,深证综指β指数介于0.3到0.7之间,也同样呈现出无限活跃Lévy跳跃类型。这表明使用具有无限活跃特性的Lévy过程描绘资产价格动态过程,在衍生品定价和风险管理中的预测精确性会更高。上证综指和深证成指的跳跃类型检验值均在(0,0.6)范围内也表明资产价格跳跃过程呈现出无限活跃小幅跳跃,但同时上证综指和深证成指的跳跃类型直方图的分布并未呈现出类似正态分布的特征,说明在大量小幅无限活跃存在的同时还存在着少量大幅有限活跃跳跃。上证综指与深证综指的跳跃类型直方图类似,说明沪深股指变化趋势趋同,只有在存在重大信息冲击导致的增量变化巨大时才呈现出明显差异。从跳跃变差在二次变差中占比看出,上证综指与深证成指的跳跃成分变差在二次变差中均为8%,说明系统性跳跃风险和异质性跳跃风险占据比例较小,连续波动率占据二次变差主体,即资本市场随机波动风险占据主导地位,但跳跃在资产价格动态建模中的作用不可忽视。这些占比大体反映了沪深股市不同来源风险的相对大小。分析我国沪深股市小型跳跃众多的原因,现阶段我国股市投机性重,股票流动性强,由于投资者异质性差异大,交易发生频繁,由此造成市场微观结构变化带来的价格波动频繁发生。 综上所述,在伊藤半鞅框架下,资产价格过程既包含跳跃成分又包含随机波动连续成分,跳跃过程中伴随着大量的无限活跃小幅跳跃和少量的有限活跃大幅跳跃。研究结论能有效提高金融资产价格动态建模的精确性,对于衍生品定价和风险管理,以及投资组合管理具有重要意义。确切地说,在衍生品定价尤其是期权定价中,从物理测度到风险中性测度变换中,价格动态的无限活跃跳跃情况和波动状态及其相对比例在不同测度下是相同的。带有跳跃的模型和不带跳的随机波动模型对不同到期日的期权定价影响不同,其价外期权趋近0的衰减速率分别为线性的和指数的。股市中的跳跃带来的单资产风险以及多种资产之间的时变相关性是投资者制定投资策略,对冲风险的重要影响因素。 图3 跳跃类型及跳跃活动性 为研究跳跃对波动率预测精度的影响,以上证综指和深证成指2016年9月1日之前的数据为估计样本,对2016年9月1日至10月21日之间的波动率进行样本外预测,共计1440个预测样本。表3为AHAR-GARCH-CJ模型样本内参数估计结果。通过估计短期、中期和长期的AHAR-GARCH-CJ模型的参数来分析跳跃和波动率之间的关系。模型参数估计采用两步法估计,先对不带GARCH效应的AHAR-GARCH-CJ模型进行参数估计,所得到的误差性再进行GARCH效应估计。 系数α2、α3和α4分别表示波动率的连续成分对已实现波动率的短期效应、中期效应和长期效应,分别衡量了前一交易日、前一周交易日和前一月的波动率连续成分对当期波动率的影响。从表中看出,上证综指和深证成指的α2、α3和α4的t检验值均显著,说明当日、过去一周和过去一月的连续变差波动率对未来一日收益波动率有明显影响, 波动率存在较强的长记忆性,预测值随着预测周期的变长逐渐减小。上证综指和深证成指的α6值都为负,说明股市波动率与收益率存在非对称效应,负收益率对股市的冲击影响大于正收益率对股市的冲击影响。而跳跃对已实现波动率的参数α5显著,说明根据修正的已实现阈值幂变差估计的跳跃序列对未来波动率的预测影响明显,跳跃能很好地解释波动率趋势形成机制,不能忽视跳跃对已实现波动率的显著作用。弥补了以往文献由于统计量计算偏差而低估跳跃变差对波动率预测的影响的缺陷。从时间序列上看,随着滞后期增加,中期、长期跳跃对波动率的影响逐渐减弱。同时,对数形式的跳跃对波动率的影响参数值分别为短期0.1452,中期0.1301,长期0.0998,这与图3未采用对数形式的估计结果一致。跳跃成分对股市波动率的影响虽然不如连续成分那样作用显著,但对波动率的明显正向作用不可忽视。GARCH误差部分的估计结果p值显著验证了误差项集聚性和厚尾性的存在。 表3 样本内波动率模型估计结果 注:圆括号内为t统计量,方括号内为p值,*表示在5%水平下显著。 图4为上证综指不同模型样本外的向前一步波动率预测走势与真实波动率的QQ图,QQ图直观地反映了不同模型偏离真实波动率的情况。可以看出,本文所使用的高频波动率AHAR-GARCH-CJ模型的分位数紧凑地分布在对角线周围,表明数值和真实波动率较为接近。而HAR-CJ模型以及AHAR-C_TCJ模型的分位数与真实波动率的QQ图离散程度较大,分位数差异较大,与真实波动率有一定程度偏离。AHAR-GARCH-CJ模型充分利用了高频数据和低频收益率残差数据所包含的信息预测股指波动动态特征,因而更好地预测了收益波动风险。 为评价不同模型的预测精度,使用Mincer-Zarnowitz预测回归方程的R2和异方差调整的平方根均方误(HRMSE)指标进行衡量。表4展示了上证综指在不同周期使用损失函数判断不同模型预测精度的数值对比结果,深证成指的对比结果略去。表中HAR-RV模型在各周期的损失函数值最大,且R2值显著低于其他模型。在向前一天的预测中,AHAR-GARCH-CJ模型与AHAR-C_TCJ模型表现近似,而在向前一周和向前一月的预测中,前者HRMSE值小于后者且R2值略大。前三类模型中,HAR-RV的Mincer-ZarnowitzR2值最大,而AHAR-C_TCJ模型的损失函数值最小。在四类对比的模型中,AHAR-GARCH-CJ模型的误差值相对最低,随着预测期增长,误差增加,但其仍表现出相对优势。扰动项服从GARCH分布的模型表现明显好于扰动项服从正态分布的模型表现。显示结果表明,相比于C_TZ统计量,MTZ统计量在预测波动率上解释能力更强,预测性能得到改善。与HAR类以及AHAR类模型相比, AHAR-GARCH-CJ模型能有效地提高波动率预测的精确性。所得到的结论对于衍生品定价,金融风险管理和投资组合配置具有指导意义。 图4 预测模型QQ图 在非参数方法框架下,基于修正的已实现阈值幂变差识别跳跃方差,应用上证综指和深证成指高频数据对其随机波动和跳跃特征进行分析,实证研究发现:股指同时存在跳跃,随机波动和布朗运动成分,连续性波动在股指波动中占据主体,突发性跳跃成分占比较小。其中,跳跃构成成分中无限活跃的小型跳跃居多,有限活跃的大型跳跃较少。跳跃方差序列呈现尖峰厚尾特性,自相关性弱,跳跃多是由市场异质性因素引起。波动率序列存在较强的长记忆性,具有集聚效应,收益率和波动率之间存在杠杆效应。从模型拟合效果看,本文所构建AHAR-GARCH-CJ模型考虑了上述因素,在波动率预测对比中表现出较好的预测性能。同时发现,跳跃对股指波动预测具有显著的解释力,连续波动和跳跃波动对未来波动率预测有重要影响。因此,将跳跃成分作为重要的影响因素对股指收益率和风险进行建模,对股市风险控制具有重要的应用价值。研究金融资产价格跳跃波动行为以及相互间的复杂关系,理清不同市场结构成分,有助于投资者优化投资策略和为风险监管部门提供风险管理基础。
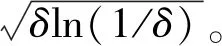
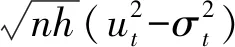
1.2 跳跃活动程度检验
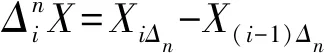
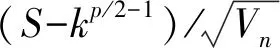
2 扩展的已实现波动率预测模型
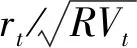
3 实证研究
3.1 跳跃识别

3.2 波动预测效果
4 结论
猜你喜欢
中老年保健(2022年3期)2022-08-24 03:00:12
数学物理学报(2022年1期)2022-03-16 06:15:04
数学物理学报(2020年6期)2021-01-14 01:00:18
投资有道(2018年6期)2018-07-10 18:01:26
沈阳工业大学学报(社会科学版)(2018年1期)2018-03-07 03:50:11
沈阳工业大学学报(社会科学版)(2018年1期)2018-03-07 03:50:11
股市动态分析(2016年11期)2016-10-11 14:10:16
股市动态分析(2016年10期)2016-09-30 14:12:12
股市动态分析(2016年25期)2016-07-23 07:31:08
股市动态分析(2016年25期)2016-07-23 07:31:08
