
基于决策者信任水平和组合赋权的不完全偏好复杂大群体应急决策方法
2019-06-11 07:08蔡晨光徐选华薛行健
运筹与管理 2019年5期
蔡晨光, 徐选华, 王 佩,3, 薛行健
(1.中南林业科技大学 物流与交通学院,湖南 长沙 410004; 2.中南大学 商学院,湖南 长沙 410083; 3.广东外语外贸大学 商学院,广东 广州 510006)
0 引言
近年来,非常规突发事件在国内外频繁发生,例如2004年印度洋海啸、2008年中国南方冰灾、2010年海地地震、2015年天津港爆炸事件等。灾害事件一旦发生,就需要召集相关应急专家根据事件的演化状态在最短的时间内给出合理的应对方案。同常规决策问题相比,非常规突发事件的决策环境更为复杂:首先,非常规突发事件具有偶发性,通常缺少完整的应急预案作为参考,这也使得该类型决策问题大多具有非结构化或半结构化决策的特点。为了保证应急决策的有效性,一般会根据以往相近的案例和抢险经验,结合突发事件类型和所在区域的环境特征制定若干个备选方案,再组织应急专家对备选方案进行评价,确定最优方案[1,2]。由于非常规突发事件的影响范围很大,为了保证应急决策的准确性,需要组织来自不同部门的多位专家共同参与决策。应急决策群体规模通常很大,少则十余人,多则数十人,这也使得应急决策多具有复杂大群体决策的特征(通常我们将群体规模超过12人的决策定义为大群体决策)[3]。大群体决策参与专家数量过多,专家之间偏好差异性过大,增加了专家意见集结与处理、属性和专家权重测算的难度,这也使得传统群决策方法难以适应大群体决策的特点。其次,非常规突发事件具有不确定性,决策过程中专家很难根据已有信息给出精确的评价值,通常会以模糊数的形式来表达自己的偏好。作为一种常见的模糊数表达形式,梯形模糊数凭借其表达简洁、运算简便的优势,已经被广泛地应用于不同类型应急决策活动之中[4,5]。另外,应急决策具有时间压力性,受突发事件的模糊程度、专家所处的决策环境以及专家自身知识储备等方面的影响,很难保证所有专家均能在短时间内给出完整的偏好信息。当专家偏好信息出现残缺时,如何对残缺偏好信息进行处理,也是决策过程中需要考虑的重要问题之一。当前部分学者针对偏好信息不完整的群决策问题已进行一些研究,如偏好信息表示为语言值、互补判断矩阵、二元语义等形式的残缺型群决策问题[6~8]。对残缺值进行填充是偏好信息集结的基础,当前对于残缺值的填充通常以现有偏好信息为依据,且补值过程中很少考虑残缺值对应的决策者意见,该决策者对于被赋予的填充值大多数情况下只能选择被动接受。为了保障残缺值的填充效果,有必要在对残缺值填充时考虑该决策者的个体态度和意见。基于上述分析,本文针对属性权重完全未知且专家偏好信息表示为梯形模糊数的残缺型复杂大群体应急决策问题提出一种新的决策方法。
首先,设计一套基于决策者信任水平的残缺值填充机制对残缺信息进行填充。然后,对各个备选方案的大群体偏好信息进行聚类,形成若干个聚集。将方案信息熵和群体偏好冲突水平相结合确定属性权重,得到各方案的综合群体偏好值。最后利用实际案例对该方法的可行性和有效性进行验证。
1 准备知识
定义1[9]设α=(a,b,c,d)是实数集R上的梯形模糊数,其中0≤a≤b≤c≤d<+∞,则称为梯形模糊数(见图1)。梯形模糊数α的隶属度函数μα(x)如式(1)所示。
(1)
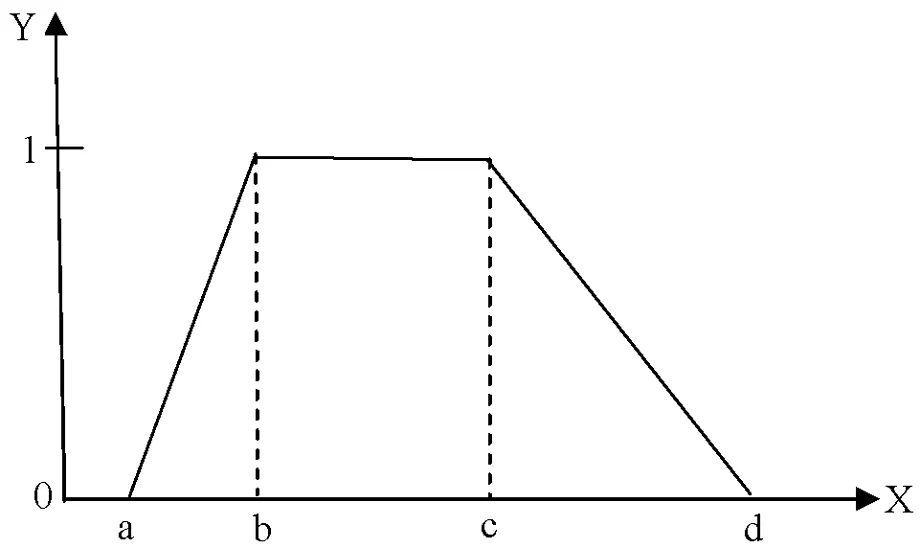
图1 梯形模糊数α
根据梯形模糊数的性质可知,当a=b=c=d时,梯形模糊数α退化成实数。另外,当a=b且c=d时,梯形模糊数α退化成区间数[9]。
定义2[10]设α=(a1,a2,a3,a4)和β=(b1,b2,b3,b4)为两个标准化的梯形模糊数,即0≤a1≤a2≤a3≤a4≤1;0≤b1≤b2≤b3≤b4≤1,α和β之间的距离为
(2)
定理1D(α,β)满足以下性质:
(P1)有界性:0≤D(α,β)≤1;(P2)对称性:D(α,β)=0,ifα=β;(P3)互补性:D(α,β)=D(β,α)。易证性质(P1~P3)成立,在此不再赘述。
定义3[11]设α=(a,b,c,d)是实数集R上的梯形模糊数,则梯形模糊数α的期望值为
(3)

定义4[12]设梯形模糊数α=(a,b,c,d),则α的质心为
(4)
(5)


2 方法原理
2.1 问题描述
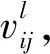

表1 语言变量与梯形模糊数之间的对应关系
2.2 基于决策者信任水平的残缺值填充机制
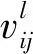
(1)专家属性偏好平均值计算方法

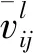
(6)
(2)残缺值取值范围的确定



(7)
(3)考虑决策者信任水平的残缺值填充方法
利用式(6)得到的结果具有群体偏好特征,利用该结果作为参考信息对残缺项进行填充时,还需要考虑残缺项所属专家对于群体偏好的信任水平。专家个体不同,其对于群体偏好的信任水平也有所不同。一般而言,专家对于群体偏好的信任水平通常分为三类:第一类专家对群体偏好持出完全信任的态度,若该类型专家的偏好值出现残缺,可以直接将式(6)得到的群体偏好作为残缺项的填充值;第二类专家对群体意见持完全不信任态度,即便该类型专家的偏好值出现残缺,也完全不愿意依照式(6)得到的群体偏好对残缺值进行填充,此时只能根据残缺值可能的取值范围对其进行赋值;第三类专家对群体意见表现出部分信任态度,当该类型专家的偏好值出现残缺时,式(6)得到的群体偏好只能为残缺值的填充提供部分参考。
(8)
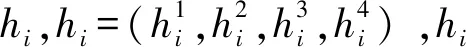
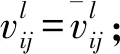
2.3 专家偏好信息的集结
残缺值填充完成后,M个决策者对方案l给出的偏好信息形成矢量集合Ωl,以式(9)作为相聚度公式,设定合理的聚类阈值λl(λl∈[0.5,1])对集合Ωl进行聚类(阈值确定方法及聚类具体步骤详见文[3])。
(9)



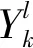
(10)
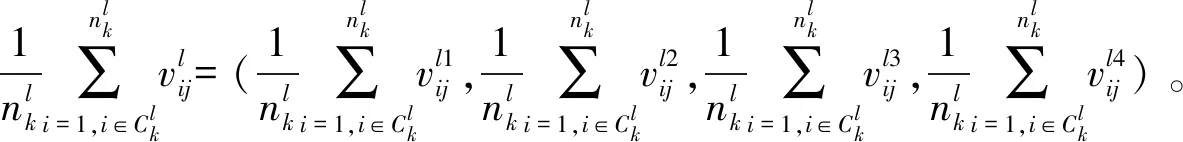
根据聚集中的成员数目对集合Ωl中的聚集进行赋权,如式(11)所示。
(11)
利用聚集权重对聚集偏好进行集结,得到集合Ωl的群体偏好:
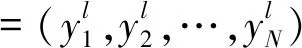
(12)

2.4 属性权重的确定
(1)属性权重范围的确定
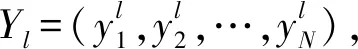
(13)
属性j的信息熵为:
(14)



(2)属性权重的计算
为了对集合Ωl中不同属性的群体偏好冲突进行测度,构建关于集合Ωl的属性群体偏好冲突指标,如定义5所示。
定义5集合Ωl中属性j的群体偏好冲突水平为:
(15)

定义6集合Ωl中所有属性的群体偏好冲突水平为:
(16)
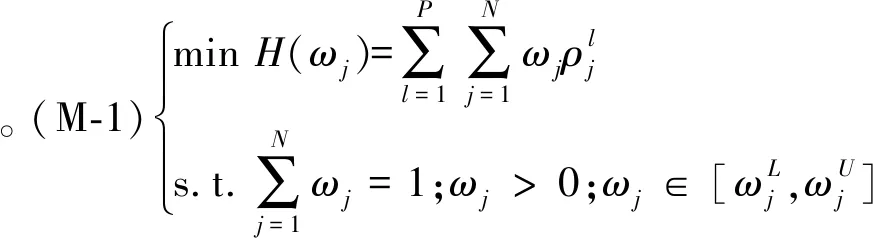
定理4模型(M-1)一定存在最优解。
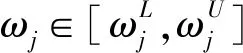
根据模型(M-1)得到属性权重ω=(ω1,ω2,…,ωN)T。
综上所述,本文提出的决策方法具体步骤如下:
步骤1对于缺失的专家偏好信息利用式(6~8)对残缺值进行填充。

步骤3利用式(13~14)确定属性权重的取值范围,再利用模型(M-1)确定属性权重ω。
步骤4利用式(17)对各个方案的群体偏好进行集结,得到各个方案的综合群体偏好B=(b1,b2,…,bP)。
(17)
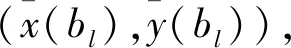
3 案例分析
以洛阳市“11.1”氰化钠污染事件为例,对本文所提出方法的可行性和有效性进行验证。21世纪初,洛阳市一辆装满氰化钠的大货车因下雨路滑在洛宁县境内发生侧翻,11吨剧毒物质氰化钠沿路边排水沟进入附近的洛河之中,由于司机和同车人员在事故发生后并未及时报警,而是选择仓惶逃离现场,使得该河流中的氰化钠浓度在短时间内超标300倍,并以每秒钟3000立方米的速度顺流直下,对河流沿岸人民群众的生命安全造成严重威胁。直至事件发生3个小时之后,当地镇政府才发现这个情况,并迅速向市委市政府进行汇报,市委市政府高度重视此事,立即成立事故紧急处置领导小组,组织当地民兵、干部群众数百人连夜赶赴现场,对污染事故进行处置。此时河流污染情况已经相当严重,被污染的河流长度已经接近20km,当地市政府立即向省政府请示,申请增加更多的抢险设施和物资,同时向当地驻军求助,请求当地驻军参与抢险。驻当地某部的300多名官兵和200多名武警战士以最快的速度赶到现场参与事故处理。
氰化钠是一种成白色粉末状的剧毒危险化学品,人类口服致死量约为0.1g~0.3g。氰化钠泄漏事故会对周边水源造成严重污染,还会引发周边地区整个生态链的连锁污染。事故紧急处置领导小组按照现场抢险的实际需要,将事故处置人员划分成若干个小组,每个小组承担的任务各不相同。例如,污染物检测组要求在污染流域设置10余个监测点,24小时监控河水污染情况;无害化处理组需要不断向河内播撒石灰、漂白粉,对氰化钠进行无害化处理;污染物隔离组则需要采取各种措施对污染河水进行隔离,减缓河水的流速;新闻宣传组一方面需要不断向社会公布事故处置的最新进展,另一方面还通过各种媒体向沿线居民发出紧急通知,禁止人畜饮用河流中的水;物资设备调运组主要负责向灾区调运必要的抢险物资和机械设备。
按照领导小组的要求需要对污染河水进行隔离,以减缓污染河水的扩散速度,防止污染的河水流入市区,造成更大范围的危害。由于当地以前从未发生过如此严重的剧毒危险化学品泄漏事件,因此缺乏可靠的处置案例作为参考,同时该起事故从发生到被发现间隔的时间过长,已有预案中的应对措施已经不能够对当前的污染局面进行有效控制。因此,污染河水隔离方案的制定与选择就成为一种没有完整规则或案例所遵循的半结构化决策问题。为了形成切实有效的河水隔离方案,事故紧急处置领导小组根据已有的应急预案内容,结合现场实际情况,组织水文、地质、环境等方面的专家共同讨论制定出3套备选方案:
方案1(z1) 在事发地下游15km处的公路桥下架设2条由活性炭等吸附物质构成的隔离带对受污染的河水进行拦截和过滤。另外在事发地上游地区将河水进行引流,将河水改道流入下流,并在事发地下游27公里处修筑一条砂土拦截坝,在坝旁挖掘10个直径5~6m、深1m的处理池,将受污染的水引入池中进行无害化处理,同时组织大量人员在隔离水域撒播石灰、漂白粉。
方案2(z2) 利用沙包在事故点下游的宜阳县甘棠村以及洛宁县长水乡长水大桥处建设两道沙包拦截坝对污染河水进行拦截,两道相隔15公里的拦截坝之间形成一个大型污水处理池,组织相关人员利用石灰、漂白粉等对隔离水域的污水进行无害化处理。同时在事故点上游开辟新的河道,对河水进行引流,减轻拦截坝的压力,降低污水处理的工作量。
方案3(z3) 调运大型机械设备在离污染点40公里处构建一道大型砂土堤坝,在堤坝旁修建3个大型污水处理池,对污染河水进行处理。同时在上游利用大型机械抢修出一条人工河道将上游河水改道排入下游,同时组织大量人员在隔离水域撒播石灰、漂白粉。
方案1采用隔离带的形式对河水进行初次过滤,可以降低河水中氰化物的含量,提高河水无害化的处理效果。但是,由于搭建隔离带的桥下水文环境较为复杂,因此隔离带架设难度较大。
方案2利用沙包拦截坝主要是利用人工进行修建,因此修建过程十分灵活便捷,不受场地或交通设施限制。但是沙包拦截坝主要是依靠装满砂土的编织袋构成,因此坝体的密封性不是很好,需要对坝身和坝底进行额外的密封处理。此外,同其他两种方案相比,方案2并未修建处理池,而是直接在拦截坝封闭的水域中进行污水无害化处理,污水的处理效果有待进一步评估。
方案3利用大型工程机械进行筑坝和河水改道工程可以提高工作效率,但是大型工程机械的使用成本较高,此外,由于事故发生地点地处山区,机械调运和作业条件较差,加之连日以来的暴雨,进一步增加了工程机械进场和作业的难度,对方案的实施效果和时效性也会产生很大影响。
根据上述分析可知,3种备选方案既存在自身优势,也存在明显劣势,这使得对3个方案进行排序显得非常困难。为了确定一个最为合理的方案,选取方案的经济性、方案的时效性以及方案的实施效果作为方案属性,组织12位来自不同领域的应急专家依照方案属性对备选方案进行评估,各个专家给出的偏好信息如表2所示。

表2 不同方案的专家偏好信息
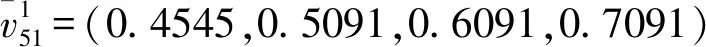
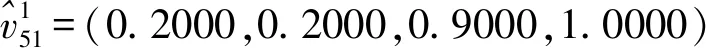
各个残缺值所对应专家给出自己对于群体偏好的信任水平,如表3所示。

表3 专家关于群体偏好的信任水平
基于表3中的专家信任系数,利用式(8)确定填充值:
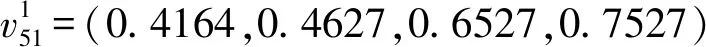
聚类阈值λ1,λ2,λ3分别设置为λ1=0.83,λ2=0.88,λ3=0.81[3],以式(9)为聚类公式,对专家偏好进行聚类,聚类结果如表4所示。

表4 各个方案的专家偏好聚类结果
利用式(13~14)确定属性权重的取值范围ω1∈[0.25,0.26],ω2∈[0.67,0.68],ω3∈[0.06,0.07],利用模型(M-1)确定综合属性权重ω=(0.25,0.68,0.07)T。
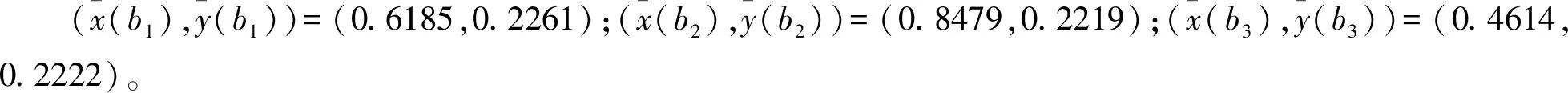
4 方法有效性分析
4.1 大群体决策有效性分析
结合上文中的实例对大群体决策的有效性进行验证。非常规突发事件应急决策多为非结构化或半结构化决策,该类型决策问题通常缺乏必要的资料或数据进行参考,其决策过程、决策模型以及决策方法等也没有固定的规律可以遵循,在缺乏必要参考信息的条件下,决策专家一般依据自己的主观意见给出相应的方案偏好信息。专家的所属部门、知识结构、专业背景、决策特征等方面并不完全相同,使得各个专家的主观偏好意见也存在差异。若仅由一个专家进行决策,很难得到一个可靠的结果。以上文中的案例为例,若仅以专家1中关于3个方案的偏好意见作为决策依据,得到的3个方案的排序结果为:z2>z1>z3;若仅以专家6中关于3个方案的偏好意见作为决策依据,得到的3个方案的排序结果为z2>z1=z3;若以专家12中关于3个方案的偏好意见作为决策依据,得到的3个方案的排序结果为z2=z1=z3。由此可见,根据3个不同专家偏好意见得到的方案排序结果各不相同。为了减小专家个体主观性带来的偏好偏差,保障决策活动的有效性,组织来自不同领域的专家共同参与决策,利用大群体决策的方式确定合理的应急方案。来自不同领域不同部门的专家根据事件的具体情况给出相应的偏好信息,保证了决策结果的可靠性。利用聚类和赋权的方法对大群体偏好信息进行集结,降低了因决策者个体主观性产生的意见偏差,形成具有一致性的群体意见。此外,在时间压力下,部分决策者的偏好信息无法在短时间内全部给出,如专家5、专家9或专家10等,若以这些专家中某一成员的偏好意见作为决策依据,将无法形成完整的决策结果。在大群体决策条件下,对于部分残缺型的专家偏好可以依据其他决策者的偏好信息对残缺的专家偏好信息进行处理和填充,保证了决策活动的顺利进行。综上可知,采用大群体决策方式进行应急决策是切实有效的。
4.2 不同残缺值填充方法的对比分析
4.3 属性赋权的有效性分析
将本文提出的属性赋权法与其他两种赋权方法进行对比,对本文的属性赋权法有效性进行验证。通过定义3计算Yl的期望值,根据Yl的期望值利用熵权法计算属性权重:ω=(0.25,0.68,0.07)T,得到的排序结果为z2>z1>z3,与本文方法得到的排序结果完全一致,且根据群体偏好期望值得到的属性权重处于利用式(13~14)确定属性权重的取值范围之中。若对属性赋予相同的权重,即ω=(0.33,0.33,0.33)T,得到的排序结果为z2>z1>z3。该种赋权方法尽管简便,但是属性权重没有区分度,赋权的意义没有得到实现。本文提出的属性赋权方法一方面基于熵权法确定了属性权重的取值范围,提高了方案群体意见的区分度,另一方面考虑了群体偏好冲突水平,最大限度地保障群体意见的一致性。综上所述,本文提出的赋权方法是合理有效的。
5 结论
本文针对属性权重完全未知且专家偏好信息出现残缺值的复杂大群体应急决策问题,提出了一种新的决策方法。根据专家对于群体意见的信任水平对残缺信息进行填充,使得填充值能够有效反映专家的心理特征。对大群体偏好信息进行聚类,使之划分为若干个偏好大体相近的聚集,缩小了大群体偏好信息的规模,降低了偏好信息集结的难度。此外,在对属性进行赋权时,利用熵权法确定了属性权重的取值范围,再根据群体偏好冲突水平建立模型对属性权重进行求解,保障了属性的赋权效果。未来可以将本文提出的方法进一步扩展,将其应用于具有动态特征的应急决策活动之中。
猜你喜欢
中国西部(2022年2期)2022-05-23
思维与智慧·下半月(2022年5期)2022-05-17
民族文汇(2022年9期)2022-04-13
中学生数理化·八年级物理人教版(2021年12期)2021-12-31
南大法学(2021年6期)2021-04-19
当代陕西(2020年17期)2020-10-28
小学生作文(低年级适用)(2019年12期)2020-01-18
人大建设(2019年5期)2019-10-08
活力(2019年15期)2019-09-25
人大建设(2018年5期)2018-08-16
