
遥感影像建筑物提取的卷积神经元网络与开源数据集方法
2019-06-10 01:50季顺平魏世清
测绘学报 2019年4期
季顺平,魏世清
武汉大学遥感信息工程学院,湖北 武汉 430079
自动化地进行遥感影像建筑物检测和提取在城市规划、人口估计、地形图制作和更新等应用中都具有极为重要的意义,同时也是遥感图像处理与应用领域一个极其困难的问题,其研究跨度超过30年[1]。当前,基于人工智能和机器学习遥感数据处理方法,特别是以深度学习为代表的图像识别、目标检测等技术的发展,为从遥感影像中自动化提取建筑物提供了机遇和前景。然而,由于遥感成像机理、建筑物自身、背景环境的复杂性,从遥感图像中自动提取建筑物迄今仍然停留在理论研究和验证阶段,尚无普适性和实用性的算法及系统出现。
传统上,从航空/航天影像中提取建筑物的主要工作集中在经验地设计一个恰当的特征以表达“什么是建筑物”,并创建相应的特征集用于建筑物的自动识别和提取。常用的指标包括像素[2]、光谱[3-5]、长度、边缘[6-8]、形状[9-10]、纹理[4,11-12]、阴影[1-2,13]、高度[14-16]、语义[17-18]等。而这些指标却会随着季节、光照、大气条件、传感器质量、尺度、建筑物风格和环境发生较明显的变化。因此,这种凭经验设计特征的方法常常只能处理特定的数据,而无法真正做到自动化。
从2015年开始,深度学习中的卷积神经元网络(neural convolutional networks,CNN)被逐渐引入到遥感中,并显示了在图像检索、图像分类、目标检测中的巨大应用潜力[19-20]。CNN的成功之处在于它能够自动学习出一个多层的特征表达,该表达将原始输入映射到二元或多元标签(一个分类问题)或连续的矢量(一个回归问题)。这种自我学习特征的能力超越并逐渐替代了传统的人工经验设计特征的方法;特别地,为本文关注的建筑物自动提取提供了一种更具自动化和稳健性的解决方案。
建筑物提取具有较高的研究复杂度,它不仅仅是一个分类(classification)和语义分割问题(semantic segmentation),它还是一个目标检测(object detection)和实例分割问题(instance segmentation)。2012年,随着计算机计算能力取得长足进展,以多层(大于三层)神经元网络为特征的深度学习技术开始显现出极大的优越性,逐渐超越以“符号主义”为主导的传统视觉处理技术,并逐步成为人工智能和机器学习中领域的一个研究热点。作为视觉处理的主流深度学习框架,CNN被广泛应用于图像分类,并以此为基础逐渐发展了一系列通用的CNN架构,如AlexNet[21]、VGGNet[22]、GoogleNet[23]、ResNet[24]等。在ImageNet[25]、COCO[26]等测试集上,这些架构为一个图像输出一个类别标签,即离散标签的分类。其中,ImageNet由涵盖1000种类别的1000万张自然图像组成,也间接促进了深度学习方法爆发。从2015年开始,特殊的CNN架构得到发展并广泛用于语义分割:为图像中的所有像素都赋予类别标签。这些架构可统称为全卷积神经元网络(fully convolutional network,FCN)[27],包括SegNet[28]、DeconvNet[29]、U-Net[30]等多个变种。当前,最新的建筑物提取的文献都是采用基于FCN的语义分割方法[31-32]。文献[31—32]采用FCN框架,并稍微改进了FCN结构用于建筑物的像素级语义分割;但是这些论文中的试验仅仅考虑了像素上的分类精度。
显然,建筑物提取的研究并非止于语义分割。建筑物提取的目标并非关注某个像素是不是建筑物,而更关注建筑物目标本身,包括建筑物的位置,建筑物的数量。这是一个典型的目标实例分割问题,在本文研究中就是建筑物单体分割。然而,目前基于CNN的建筑物实例分割研究在国内外相关领域关注仍然较少,并亟待填充。在深度学习中,从CNN中发展出一类特殊的网络架构用于目标检测,即通过回归而非标签分类寻找一个最优包容盒(bounding box)。由包容盒的四角坐标,进一步得到待检测物体的位置和数量,其中最流行的是基于区域的模型(region-based model)。这些模型包括R-CNN (region-based CNN)[33],Fast R-CNN[34]、Faster R-CNN模型[35]、YOLO(you only look once)[36]。
结合建筑物的目标检测和语义分割,可实现完整的实例分割。实例分割是指不但在对象级别发现单个建筑物实体(以包容盒的形式),而且能够在包容盒内部通过语义分割准确识别建筑物的前景像素。最新的Mask R-CNN[37]实现了单体目标检测的同时,进行包容盒内目标的语义分割,并且达到了很高的精度。
无论是建筑物语义分割还是尚未开展的建筑物实例分割,基于深度学习的方法强烈依赖于大容量、高精度的样本数据库。如果认为深度学习是智能时代的引擎,数据就是深度学习的燃料,即数据为王。ImageNet、COCO等计算机视觉界的开源数据库极大地刺激了深度学习的发展。然而在遥感领域,像COCO这样的大容量、高质量的数据库尚比较缺乏。这导致两个问题:①个体研究者将在收集试验数据上花费大量精力;②使用不同的非开源数据库,对理论和方法间的定量比较造成障碍,阻碍了深度学习在遥感中的快速进展。例如,最新的两篇文献[31—32]都采用非公开数据库,而且作者都报告了自己所用的数据库的精度较差,因此无法直接比较方法的优劣、无法准确评估先进的深度学习方法能达到的自动化水平。
目前,国际上共有3套开源数据集可用于建筑物提取,分别是Massachusetts数据库[38]、ISPRS的Vaihingen和Potsdam数据库(http:∥www.isprs.org/commissions/comm3/wg4/tests.html)、Inria数据库[39]。ISPRS数据库太小,只覆盖13 km2的地区,建筑物实例太少,无法进行大范围的应用。Massachusetts数据库包含151张1500×1500像素的图像,分辨率为1 m,但这个数据库质量较差,没有被用于最新的文献的试验中。Inria数据库是2017年最新的建筑物数据库,覆盖405 km2,分辨率0.3 m,但目前还没有被广泛应用。从文献[39]可以看出,使用主流的全卷积网络的方法,通过交并比(intersection on union,IoU)进行评估,只能达到0.59的精度,可见数据库质量较差。
针对以上建筑物提取在深度学习时代下的问题和瓶颈,本文提出了相应的解决方法。首先,笔者创建了一套目前范围最大、精度最高、涵盖多种样本形式(栅格、矢量)、多类数据源(航空、卫星)的建筑物数据库(WHU building dataset),并实现开源。希望能够为深度学习时代下的建筑物提取奠定基础,并提供了一个重要的算法性能比较标准。其次,本文提出一种改进的FCN方法,与最新的文献相比,在建筑物语义分割中得到了领先的结果;第三,本文提出了一种改进的Mask R-CNN方法,首次实现了大场景下(18万栋)建筑物的实例分割,经试验验证,其像素语义分割精度略超过基于FCN的方法。
1 方 法
1.1 尺度不变性遥感影像建筑物提取网络:SU-Net
全卷积网络FCN是像素级语义分割的主流框架;U-Net作为FCN的一种经典的变体、获得广泛应用。U-Net的结构如图1(a),包括特征编码和解码两个阶段。在特征编码阶段,原始输入逐层进行卷积和降采样,以获得具有较低空间分辨率的高级语义特征。在解码阶段,通过上卷积操作将底层特征逐层放大2倍,并与编码阶段的同层特征串联,并恢复至原始图像的尺度。在原始尺度下,当前模型的预测结果与真值参考之间的差异用于通过反向传播训练网络参数。U-Net只在最后一层进行图像像素类别分类。尽管U-Net利用了来自编码阶段先前层的一些信息,但其对于多尺度信息的泛化能力是有限的。图2显示了一个含有大型建筑和汽车的场景的分类结果,在图2(b)中,很多汽车被U-Net错误地分类为建筑物,而在第二行中,大型建筑物的右方被错误的分类,这两者都表明单链条的上采样不能完全传递尺度信息。
特征金字塔网络(feature pyramid network,FPN)也是梯形结构,但具有多个预测输出(见图1(b))。FPN在每一个阶段均进行预测,通过对这些输出进行加权得到最终的损失函数。因此各阶段的预测结果都用于反向传播和网络参数的更新。FPN可以定位不同比例的对象,因而在目标检测中具有良好的效果。然而,在像素分割中只关注最后一层(即原始图像分辨率下)的分割精度,其分割能力可能需要进一步强化。
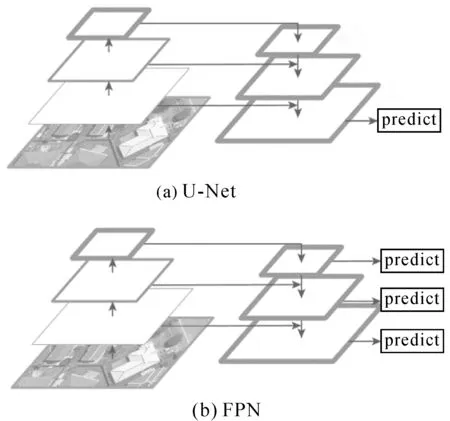
图1 U-Net和FPN的基本结构Fig.1 The basic structure of U-net and FPN
根据以上描述,本文提出SU-Net(scale robust u-net),即基于U-Net和FPN进行设计,专门用于处理遥感图像中不同尺寸的物体或不同分辨率的遥感影像的多尺度问题。在SU-Net中采取了两种策略。一是图3中空心箭头(除了最右边的那个)所指的部分将FPN整合到U-Net的网络主干中。通过预测上采样步骤中每个尺度的分类结果,取代只对原始分辨率层进行输出,因此可以在反向传播和权重更新中利用多尺度信息。

图2 不同网络在两张包含汽车和大型建筑物的512×512图像上的分割结果Fig.2 Segmentation results of different networks on two 512×512 images with cars and large buildings
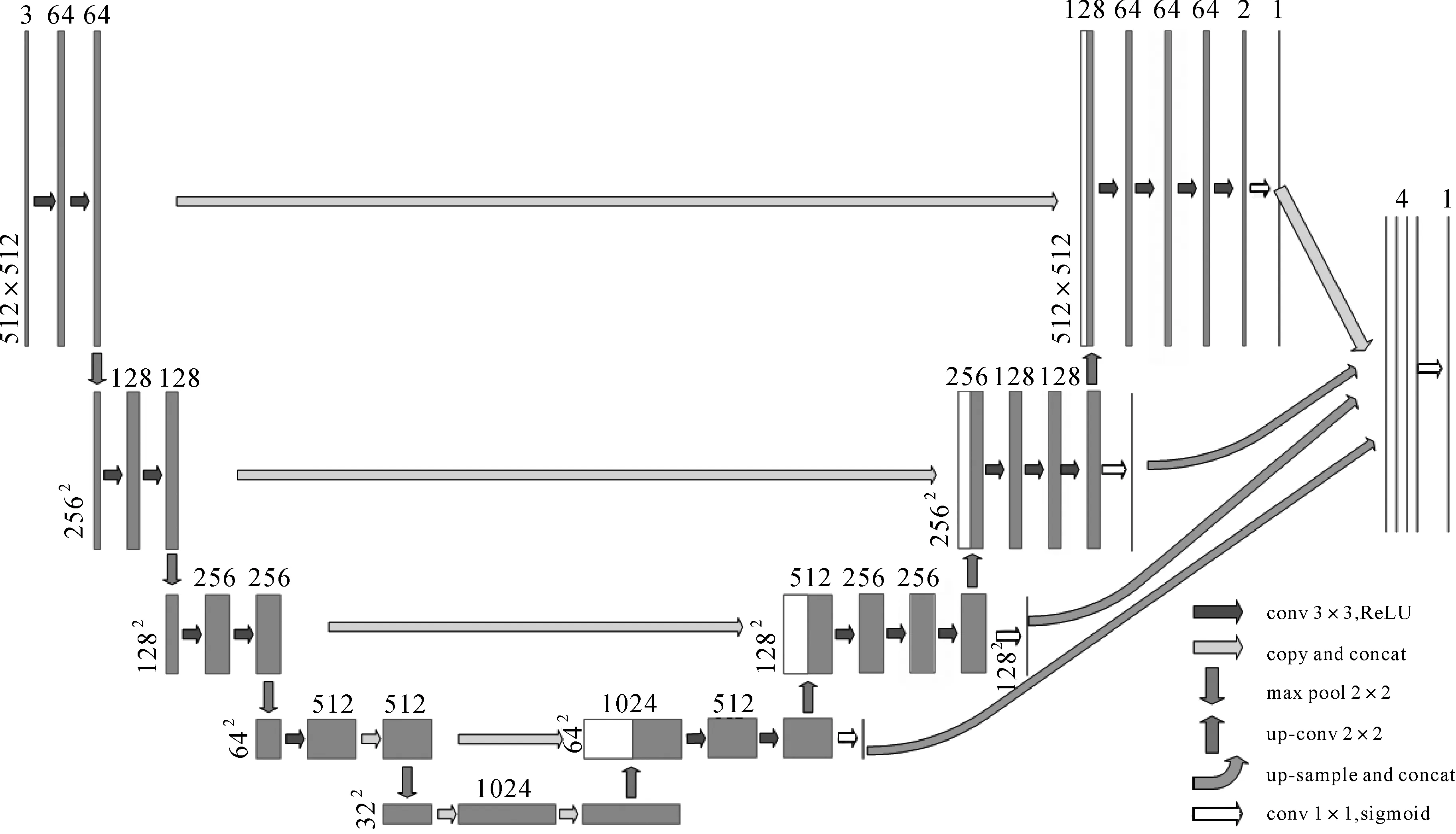
图3 SU-Net的结构。弯曲和空心箭头和相应的块被引入U-Net骨架Fig.3 The structure of SU-net. curved and hollow arrows and blocks are introduced to a U-net backbone
二是将各个尺度上的最终特征图进行串联,形成含有4通道的特征图(最右侧的一个灰色箭头和3个弯曲箭头所指),最后通过1×1的卷积和sigmoid函数得到最终的预测图。通过这种策略,最终的预测图汇聚了多个尺度的信息,各个尺度的信息在反向传播和模型训练中都起到了积极的作用。这种简单有效的跨尺度信息聚合在很大程度上解决了大型建筑物和小型汽车造成的检测困难,如图2(d)所示。
1.2 一种改进的Mask R-CNN遥感影像建筑物识别网络
Mask R-CNN基本沿用了Faster R-CNN的目标识别框架,并在其基础上加入一个前景分割的网络分支。Faster R-CNN是目前R-CNN系列用于目标探测的最流行框架。如图4所示,整个框架分成3个模块。第1个模块是CNN骨干框架,用来从图像中提取特征,常用的框架是ResNet50或ResNet101。取ResNet的靠近最后的卷积层作为特征图,用于后继处理。整个目标识别建立在同一个特征图上,因此做到了高效性。第2个模块是区域建议网络(region proposal network,RPN),该模块用于从特征图中发现可能含有前景目标的区域。该模块采用大小和比例不等的矩形建议框搜寻潜在的目标,一般地,Faster R-CNN输出排在最前面的2000个建议框。第3个部分是兴趣域(region of interest,RoI)池化和最终的输出。该部分将通过RPN得到的建议框,进行一系列卷积操作,最终得到特征向量,并借此识别目标的具体类别,同时对RPN输出的包容盒进行精化。Faster R-CNN共有4个输出,这4个输出通过对损失函数加权的形式,进行反向传播和迭代,得到最优的物体类别及包容盒。
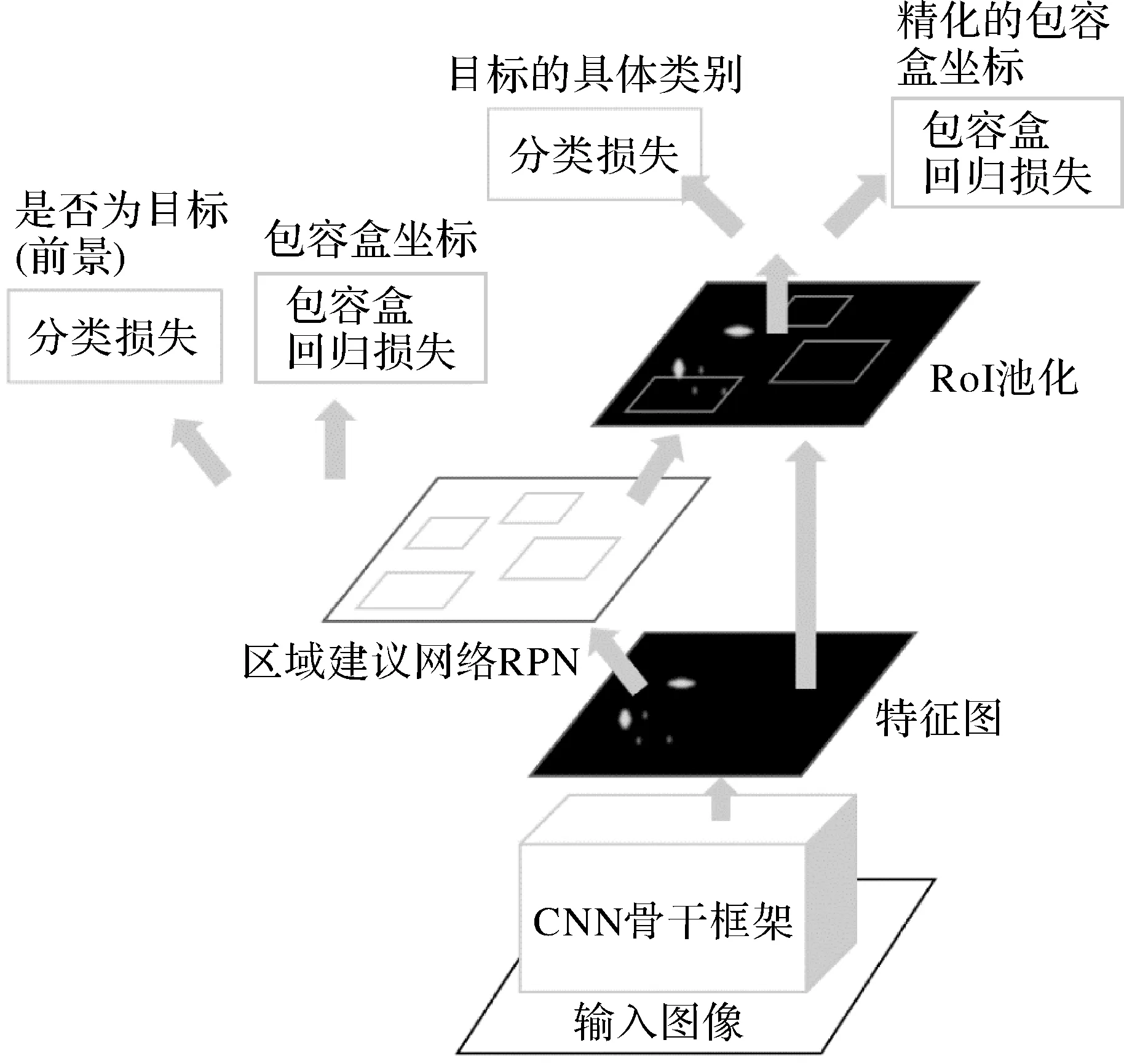
图4 Faster R-CNN 框架和流程Fig.4 The framework and process of Faster R-CNN
实例分割比目标识别更进一步,它不但需要对每个目标进行精确定位(以包容盒的形式),还需要对包容盒内的物体进行前景分割。Mask R-CNN是最新也最著名的实例分割算法。它直接采用Faster R-CNN实现目标识别,并同时利用全卷积网络实现包容盒内前景目标的分割。在图5中,在RoI层之前,Mask R-CNN的结构与图4所示的Faster R-CNN完全相同。RoIAlign指用浮点运算来确定兴趣域的目标边框,对此前的R-CNN结构由于采用取整操作而损造成的精度损失进行了改善。Mask R-CNN在RoI池化层后同样有类别和包容盒输出,并新增加一个用于语义分割的子网络,输出Mask。这样在一个网络结构下,同时就实现了目标的定位、识别和语义分割。
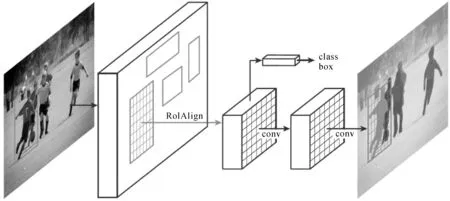
图5 Mask R-CNN的结构[35]Fig.5 The structure of Mask R-CNN[35]
在建筑物提取试验中,对于小型的建筑物,Mask R-CNN的提取结果较好(包括包容盒与目标);而在提取大建筑物时,其包容盒比较精确,但是掩膜Mask的边界存在不太精确之处,本文尝试对其改进。原始版本的mask大小为分别为14×14像素与28×28像素,大建筑物由于缩放比例过高而损失了大量细节信息。在试验中,修改为40×40与80×80像素,同时将包容盒的大小从7×7像素按比例设置成20×20像素。
2 高分辨率遥感影像建筑物样本数据库的建立
笔者团队用近1年时间,手工编辑了一套大场景、高分辨率的遥感建筑物数据库(WHU building dataset)并实现开源(http:∥study.rsgis.whu.edu.cn/pages/download/),该数据库分成航空建筑物数据库和卫星建筑物数据库。航空建筑物数据库影像来自新西兰Christchurch市,涵盖22万栋形式各异的建筑,地面分辨率0.075 m,覆盖450 km2。原始的矢量数据和航空影像都由新西兰土地信息服务(https:∥data.linz.govt.nz/)提供,然而原始数据存在大量的错误,如缺失、错位等,如图6所示,无法直接应用。因此在ArcGIS软件中采用全人工的方式对其进行了前后3次交叉检查和修订,以制作高质量的建筑物矢量图。
图7显示了一块主要建筑物区域,含有18.7万栋不同用途、不同色彩、不同大小的建筑物。为了便于深度学习方法的处理并考虑到当前GPU的容量,本文将原始影像下采样到0.3 m分辨率,并无缝(且无重叠)分割成512×512的瓦片。选取位于中间虚线框中的14.5万栋建筑物用于深度学习训练,两侧实线框的4.2万栋建筑物用于测试。图8是不同风格、用途、尺度和颜色的航空建筑物样本实例图。
卫星数据库包含数据集Ⅰ和数据集Ⅱ,其中数据集Ⅰ包含204张512×512像素的图像,分别采集至不同卫星传感器(ZY-3号、IKONOS、Worldview系列等)、不同分辨率(0.3 m~2.3 m)、包括中国、欧洲、北美、南美和非洲等五大洲的不同城市,如图9所示。这套数据库与航空数据集有明显的区别,可用于深度学习泛化能力的评估:即在航空数据集上表现良好的学习模型是否能较好地用于卫星数据各类目标场景下。
卫星数据集Ⅱ包含6张相邻的、色彩差异明显的卫星遥感影像,地面分辨率0.45 m,覆盖东亚地区860 km2的土地,如图10所示。本文数据集主要用于评估深度学习方法对于不同数据源但建筑物类型相似的样本的泛化能力。建筑物矢量图同样在ArcGIS中全手工画出,包含3.4万栋建筑物。与航空数据集类似,整个区域被分成17 388个512×512像素的瓦片,便于深度学习方法的应用。
表1是WHU数据集与国际开源数据集的比较。可见,该数据库在多个指标上都超越了已有的开源数据库。所提供的矢量样本形式将能为建筑物的单体检测和实例分割提供样本,而其他数据库难以做到。此外,除了ISPRS数据库,WHU数据库也是地面分辨率最高的数据库。但ISPRS数据库面积太小、建筑物类型太少而无法恰当地用于大范围建筑物的提取。下节将证实WHU精度远高于其他2套数据集,见表2。

图7 航空数据集中的绝大部分Fig.7 Most part of aerial dataset

图8 不同风格、用途、尺度和颜色的建筑物样本Fig.8 Examples of the aerial dataset with different architectures, purposes, scales and colors

图9 来自全球的不同传感器不同城市的卫星遥感影像建筑物样本Fig.9 Examples of the satellite dataset with different architectures from cities over the world

图10 由6张卫星影像组成的覆盖860 km2的东亚区域Fig.10 An area of 860 km2 covered by six satellite images in East Asia
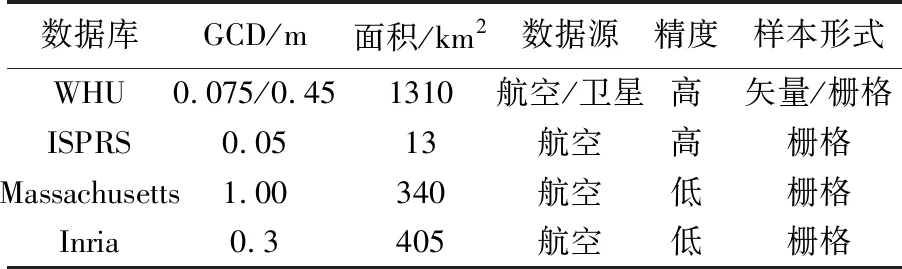
表1 WHU数据库与其他国际开源数据库的总体比较
3 试验结果
3.1 与开源数据集的比较
文中利用3个指标评估检测结果的准确性。第1个是交并比IoU,指算法检测到的建筑物像素与真实的正像素的交集以及它们的并集之间的比值。IoU一般作为目标检测和语义分割中的最常用指标。第2个是准确率(Precision),算法检测到的建筑物像素中真实正像素的百分比。第3个是召回率(Recall),即算法检测到正确建筑物像素占地面真实正像素的百分比。
为保证公平性,在所有数据集中都采用2/3样本进行训练,其余作为测试。网络模型统一采用标准的U-Net。在训练过程中,使用修正线性单元(rectified linear unit,ReLU)作为激活函数。试验在以TensorFlow作为后端的Keras框架下进行,每次输入6张图像,利用Adam算法进行网络优化,学习速率设置为0.000 1,所有参数根据正态分布进行初始化。整个训练过程在单个NVIDIA Titan Xp GPU上大概需要3 h左右的时间。
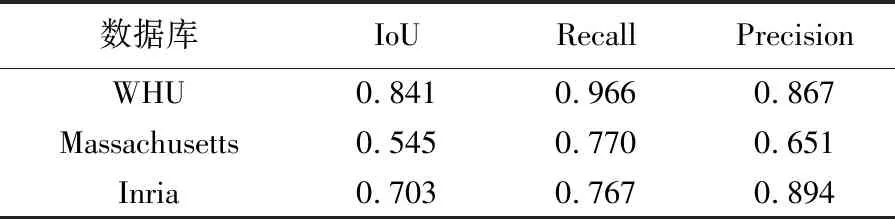
表2 WHU数据库与其他开源数据库的比较
与本文的数据集相比,Massachusetts数据集的质量和分辨率要低得多,且存在许多错误标签,其IoU和准确率/召回率分别比WHU数据集低30%和20%,这对FCN在精确检测建筑物中的应用产生了负面影响。Inria数据集包含来自5个城市的航空影像,但由于每个城市的数据量相对较少,且经过目视检查,发现存在许多房屋的标签遗漏,导致其结果在IoU上比WHU差14%,在召回上差20%。该试验证实本文提出的WHU建筑物数据集应该是目前国际上精度最高的开源数据库。
3.2 基于FCN的主流方法比较
目前最先进的建筑物提取方法几乎都基于FCN结构。表3回顾了U-Net、多尺度U-Net和本文提出的SU-Net在WHU数据集上的表现。SU-Net取得了最优的结果,相比U-Net高出4%,比2018年最新的结果[40]高出3%。由于已经达到极高的识别率(95%的准确率和94%的召回),3%可看作是一个显著的进展。
同时,这些结果也反映出同传统方法相比(往往难以超过50%的准确率),基于深度学习的方法已经将建筑物提取推进到一个新的自动化水平。
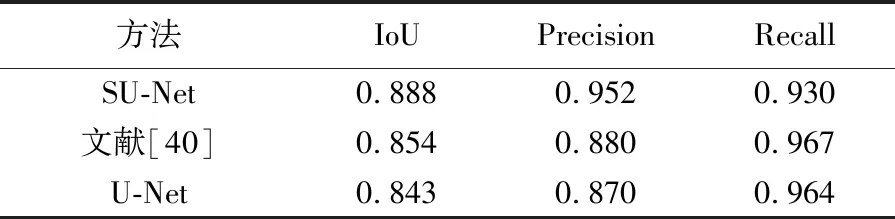
表3 与文献[40]等方法的比较
为了验证本文方法的优越性和稳定性,也在另一套开源数据集Inria上与最新的另外一篇论文的MLP方法[39]进行比较。从表4看出,本文的方法比MLP在IoU上要高出20%。本文方法运行效率很高,整个网络训练只需要3 h左右,而MLP的方法仅仅在微调阶段就需要50 h。此外,试验也表明本文方法在这套数据集上比U-Net和文献[40]的方法分别高出1.9%和0.8%。
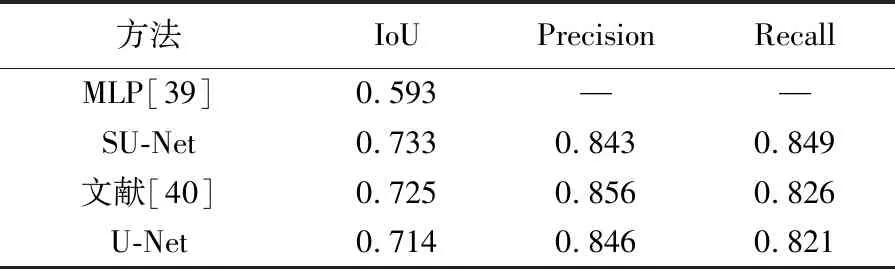
表4 在Inria数据集上各种方法的比较
3.3 基于Mask R-CNN的建筑物实例分割
由于WHU数据库提供了建筑物矢量文件,可以较好地应用于建筑物的单体实例分割。本文基于每个建筑物矢量进一步创建了包容盒,并与像素标签一起用于改进Mask R-CNN模型的训练。
由于Mask R-CNN要比FCN慢很多,本文只采用了4万栋航空图像的建筑物作为训练,其他14万栋建筑物作为测试,即训练区域和测试区域对换,训练模型耗时约20 h。图11示意了两幅图像的分割结果。图中的绝大部分房屋都被精确的包容盒定位,并且包容盒内的建筑物前景也得到了相当好的分类。

图11 建筑物单体实例分割的结果示例Fig.11 Example of the result of segmentation of a single instance of a building
表5显示了改进MASK R-CNN在14万栋建筑图像上的目标检测(包容盒)以及前景分割的定量结果。其中,AP50表示将IoU大于50%的被检测建筑物看作正确统计,所绘制的Precission-Recall曲线下方的面积;召回率83.4%表达了所有单体建筑物中,有83.4%被正确识别。由于FCN等语义分割方法只能统计像素分割的结果,本文在相同的训练集下,将U-Net的结果与改进Mask R-CNN中的前景分割精度作了比较。从表3可见,在相同的训练数据集下,Mask R-CNN的IoU比U-Net高0.5个百分点,这应该是由于更多输入信息(包容盒回归)得到的轻微提升。改进的Mask R-CNN由于加大了包容盒和mask的外框大小,减轻了过高的缩放比例带来的信息损失,因此相对于原始的Mask R-CNN,在包容盒和mask上都得到了0.5个百分点的提升。虽然提升较小,但说明本文方法思路的正确性。
4 结 论
本文报告了遥感影像建筑物提取的数个重要研究进展。第一,与当前国际同类数据集相比,本文建立了一套范围最大、精度最高、涵盖栅格和矢量样本形式、航空/航天数据源的建筑物数据库,并实现开源。该数据库便于研究人员使用、便于方法间的比较、便于新方法的快速发展;同时该数据集提供的矢量形式能够拓展建筑物提取的研究范围,即从当前的像素级语义分割推广至单体建筑物的实例分割乃至多边形提取。第二,本文提出一种基于全卷积网络的建筑物语义分割方法,与最先进的方法相比,达到了领先水平。第三,本文将建筑物提取研究从像素级的语义分割推广至目标实例分割,实现以建筑物为对象的识别和提取,并取得了比语义分割更好的结果。
最后,希望通过本文的开源数据库和相应的方法研究,能够促进建筑物提取的研究进一步发展,最终实现建筑物语义专题估计的自动化、智能化。
猜你喜欢
开放教育研究(2020年2期)2020-03-31
创新作文(1-2年级)(2019年3期)2019-09-03
软件和集成电路(2019年7期)2019-08-30
办公自动化(2016年18期)2016-08-20
办公自动化(2016年18期)2016-08-20
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
外语学刊(2011年1期)2011-01-22
