
一种基于有限数据集的图像快速生成改进方法*
2019-06-10 07:00张家亮何志鹏王媛媛
通信技术 2019年5期
张家亮,何志鹏,王媛媛,曾 兵,沈 宜,贾 宇
(1.成都三零凯天通信实业有限公司,四川 成都 610041;2.电子科技大学 信息与通信工程学院,四川 成都 611731; 3.乌鲁木齐市公安局 网络安全保卫支队,新疆 乌鲁木齐 830000)
0 引 言
生成对抗网络(Generative Adversarial Networks, GAN)[1]自2014年Ian Goodfellow提出以来,受到了学术界的持续关注。生成对抗网络在诸多领域都有广泛的应用,如图像生成、图像去模糊以及文字转换为图像等。虽然在这些领域有着优于传统方法的优势,但是生成对抗网络本身存在的训练不稳定性和模式崩溃问题也不容忽视。针对这两个问题,学术界提出了许多改进方法,其中David Berthelot提出的BEGAN[2]提供了一种新的GAN网络结构,只使用标准的训练方式可以稳定收敛,同时提供了一个超参数来均衡图像的多样性和生成质量以及一种收敛程度的估计,但是该结构需要大量的图像作为训练集才能使生成器较好地学习到真实图像的数据分布,且需要训练多个批次才能使网络达到稳定状态。
为了能够在有限数据集上快速生成图像,本文基于BEGAN和变分自编码器(Variational Auto Encoder,VAE)[3],采取两个生成模型并联的方式,利用变分自编码器提取真实图像的编码信息,将VAE的重建图像视为虚假图像,以提高判别器区分真假图像的难度。特别是在训练前期,可进一步提高模型训练的稳定性,缓解了模式崩溃问题,通过正则化项供给生成器有效的真实数据分布信息加快了学习过程。
1 生成对抗网络
1.1 生成对抗网络模型简介
生成对抗网络主要由两个模块构成——生成器G和判别器D。生成器输入为随机噪声Z,噪声经过生成器G映射到新的数据空间,得到生成数据G(Z);判别器的输入为真实图像与生成的虚假图像,可以简单理解为一个二分类器,用于判别图像的来源。判别器输入为x,代表一张图像,输出D(x)表示x为真实图像的概率。若D(x)=1,则代表x为真实图像;若D(x)=0,则代表x为虚假图像。该网络模型的主要思想是对抗训练思想。训练过程中,生成器更新参数生成与真实图像分布相似的虚假图像,以欺骗判别器D;判别器D增强区分真实图像与虚假图像的能力。如此循环训练,直到判别器无法辨别图像的来源,即D(x)=0.5,网络达到纳什均衡,生成器G和判别器D无法再提高各自生成与判别能力,训练结束。
1.2 标准生成对抗网络模型
标准生成对抗网络的模型如图1所示。
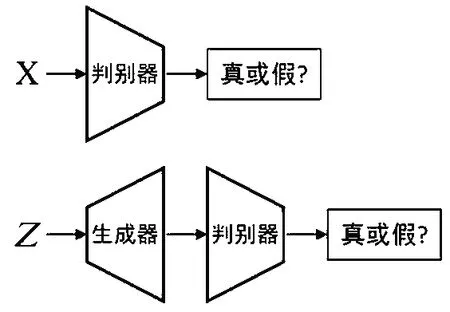
图1 标准生成对抗网络模型
1.3 生成对抗网络的损失函数
原始生成对抗网络的目标函数为:

其中V(D,G)表示生成对抗网络中的目标函数,x~pr表示x服从训练集中的真实图像分布pr;z~pz(z)表示z服从的某一随机噪声分布;E[·]表示求数学期望。
2 变分自编码器
2.1 变分自编码器简介
变分自编码器VAE与生成对抗网络的目标,都是希望构建一个从随机噪声Z到生成数据X的模型。VAE的主要模块分别为编码器和解码器,其中编码器负责将高维空间中的图像转化为一个低维空间的向量Z。给定一张图像Xk,假定p(Z|Xk)是专属于Xk的后验概率分布,而这个概率分布服从正态分布。如果能够得到这个概率,就可以从分布中采样,并且通过解码器将图像从低维空间映射回高维空间,从而达到恢复图像的目的。
2.2 重参数化技巧
需要从p(Z|Xk)中采样Zk,而采样操作是不可导的,采样结果是可导的。于是,从N(0,I)中采样一个ε,令Z=μ+εσ就相当于从N(μ,σ2)中采样一个Z。所以,将从N(μ,σ2)中采样变成从N(0,I)采样,然后通过参数变换得到N(μ,σ2)中采样的结果。这样“采样”操作就不用参与梯度下降,改为采样的结果参与,而采样的结果是可导的,从而使得整个模型能够训练,即VAE中重参数化的技巧。
2.3 变分自编码器的损失函数
变分自编码的损失函数由两个部分组成:原始图像与重建图像之间的重建损失,后验概率分布与标准正态分布之间的正则项。
2.3.1 重建损失
交叉熵度量:

均方误差度量:

其中,x表示原始图像,x^表示重建后的图像。Lrecon越小,表示原始图像与重建图像越接近。
2.3.2 正则项
正则项为采样与标准正态分布之间的相对熵,化简可得:
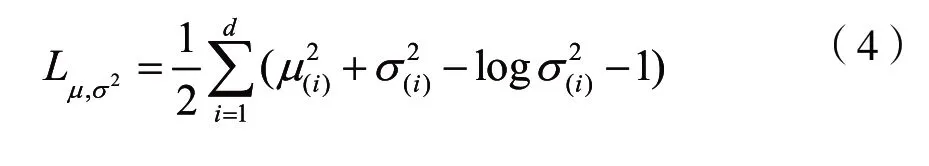
3 模型架构与损失函数
3.1 BEGAN
3.1.1 BEGAN的网络结构
BEGAN没有采用其他GAN估计概率分布的方法,不直接估计生成图像的数据分布和真实图像分布之间的差距,而是改为估计分布的误差之间的差距。为了估计分布的误差,BEGAN与EBGAN[4]类似,也将判别器设计为自编码器结构,输入和输出的图像大小相同。BEGAN的网络模型如图2所示。

图2 BEGAN网络结构
3.1.2 BEGAN的损失函数设计
BEGAN估计分布误差之间的差距,采用范数衡量图像分布的误差,具体函数如下:

其中,L(v)是一个像素误差的损失,表示图像v与经过判别器D之后的输出D(v)之间的相似程度;L(v)越小,则说明v、D(v)越接近。LD表示判别器的损失函数,LG表示生成器的损失函数,x表示真实图像,L(·)表示图像与经过判别器D之后输出的像素误差,z表示随机噪声分布,kt∈[0,1]控制L(G(z))在梯度下降时的比例实现,λk为k的学习率。γ∈[0,1]为比例系数,用于均衡生成图像的生成质量和多样性。γ越小,多样性越差,生成质量越高。mglobal表示训练程度的好坏,越小,训练程度越好。
3.2 改进的BEGAN
3.2.1 改进的BEGAN的网络结构
为了在有限数据集上快速生成图像,将BEGAN 与VAE结合,利用VAE提取真实图像的数据分布,并且将VAE的重建图像也视为虚假图像,增加了判别器辨别真假图像的能力,特别是在训练前期能够进一步稳定模型的训练。通过设计的正则项,生成器可以获取VAE提取的真实图像信息,达到加快图像生成和在有限数据集上生成图像的目的。改进后的BEGAN网络模型如图3所示。

图3 改进的BEGAN网络模型
3.2.2 改进的BEGAN的损失函数设计
通过正则化项获取变分自编码器提取的真实图像信息,若潜空间变量越相似,那么得到的生成图像也应该越相似。

其中,Lreg为设计的正则化项,L1表示L1范数约束,为潜空间变量与生成图像之间的维度比例[5]。

其中,LVAE表示变分自编码器的损失函数,Lrecon表示变分自编码器的重建损失,本文实验中使用L2范数。Lμ,σ2表示重参数化的正则项,kg,kvae∈[0,1]分别控制L(G(z))、L(VAE(x))在梯度下降时的比例实现,λk为k的学习率,γ∈[0,1]为比例系数,用于均衡生成图像的生成质量和多样性,γ越小,多样性越差,生成质量越高,α,β为正则化项的比例系数,mglobal表示训练程度的好坏,越小训练程度越好。
3.2.3 改进的BEGAN的模型训练机制
模型训练的基本思想是对抗训练思想,训练大体流程与BEGAN一致。由于在模型中加入了变分自编码器,所以模型训练的步骤可归纳为以下四个步骤:
(1)训练判别网络,降低判别网络的损失函数,尽可能判别出图像的真假。
(2)训练变分自编码器,使得变分自编码器尽可能生成接近于真实样本的图像,为生成网络的更新提供信息,增加判别网络辨别图像来源的难度。
(3)训练生成网络,通过正则化项获取变分自编码器提取的潜变量信息,尽可能生成真实的图像去迷惑判别网络,达到对抗训练的目的。
(4)经过三个网络的不断循环训练,直至判别网络无法区分其输入图像的来源,即D(x)=0.5,标志着训练达到平衡,各网络无法再通过参数优化提高能力,此时生成网络的生成能力达到最佳,能够生成高质量和高多样性的图像。
4 实验与分析
4.1 具体实验模型与参数
BEGAN基本上解决了GAN训练的不稳定性和模式崩溃问题。本文使用CelebA人脸数据集,将人脸数据统一裁剪为128×128×3大小的图像,对原始BEGAN与改进后的BEGAN进行对比实验。为了验证改进模型在少量数据集上的图像生成效果,分别采用1万张和8万张人脸图像对两个网络模型进行训练。改进的BEGAN网络结构如图3所示,其中具体的判别器网络结构如图4所示;变分自编码器网络结构如图5所示,生成器网络结构如 图6所示。
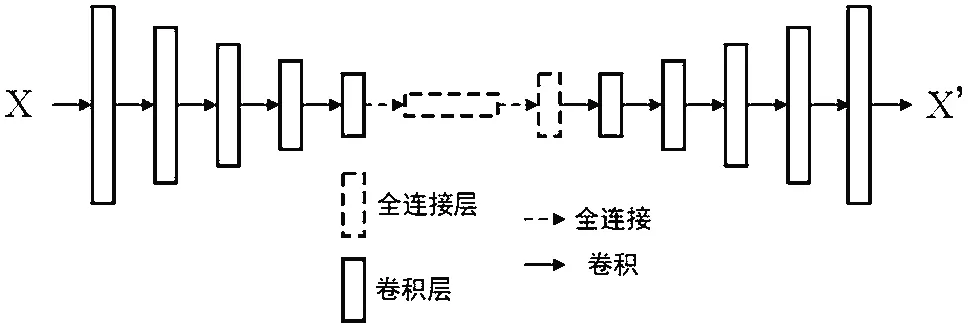
图4 判别器网络结构

图5 变分自编码器网络结构
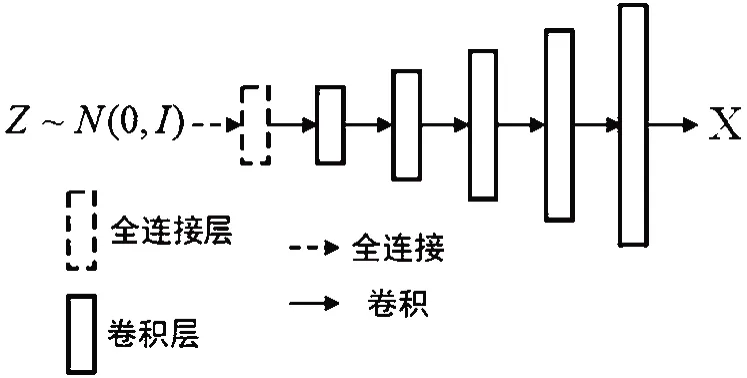
图6 生成器网络结构
相关参数设置为:epoch=50,batch_size=25,lr=0.000 1,m=0.5,m2=0.999,γ=0.7,λk=0.001,fn=128,z=128,α=0.2,β=0.1。其中epoch表示迭代次数;batch_size表示批处理大小;lr表示学习率;m、m2分别表示Adam优化器的两个参数;γ用于在生成图像质量和多样性之间做调节,γ越高,图像的多样性越高;λk表示kg、kvae更新时的步长;fn表示卷积核个数;z表示噪声维度,α、β分别表示正则项的比例系数。
4.2 实验结果
4.2.1 1万数据集
下面将分析训练集为1万张人脸图像时,BEGAN和改进的BEGAN的训练结果。其中,图7为BEGAN训练过程中分别迭代2 500次、5 000次、10 000次、15 000次和20 000次生成的图像。

图7 BEGAN训练中生成图像
图8 为改进后的BEGAN训练过程中分别迭代2 500次、5 000次、10 000次、15 000次和20 000次生成的图像。图9为BEGAN训练完成后由随机噪声生成的5组图像。图10为改进后的BEGAN训练完成后由随机噪声生成的5组图像。

图8 改进后的BEGAN训练中生成图像

图9 BEGAN完成训练后生成的5组图像

图10 改进后的BEGAN完成训练后生成的5组图像
4.2.2 8万数据集
下面是训练集为8万张人脸图像时,BEGAN和改进的BEGAN的训练结果。其中,图11为BEGAN训练过程中分别迭代2 500次、5 000次、10 000次、15 000次和20 000次生成的图像。图12为改进后的BEGAN训练过程中分别迭代2 500次、 5 000次、10 000次、15 000次和20 000次生成的图像。图13为BEGAN训练完成后由随机噪声生成的5组图像。图14为改进后的BEGAN训练完成后由随机噪声生成的5组图像。

图11 BEGAN训练中生成图像

图12 改进后的BEGAN训练中生成图像

图13 BEGAN完成训练后生成的5组图像

图14 改进后的BEGAN完成训练后生成的5组图像
4.3 实验结果分析
在不同量级数据集上的对比实验数据表明,改进后的BEGAN可以更快地学习到图像的特征,特别是基于1万CelebA人脸数据集,生成图像的质量与多样性都远远高于原始的BEGAN,且训练过程中的稳定性较高,即使减少了训练的迭代次数,也能生成高质量与多样性并存的图像。
5 结 语
本文提出了一种使用变分自编码器提取真实图像信息,并将重建图像视为虚假图像来改进BEGAN的方法。经试验对比分析,该改进BEGAN的方法有可能实现基于少量数据集快速生成高质量和高多样性图像的目的。此外,该改进方法依然存在许多可以持续改进的地方,如在网络结构中加入ResNet模块,使用逆卷积代替resize操作对图像进行缩放等,以实现对BEGAN更进一步的 改进。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
怀化学院学报(2021年5期)2021-12-01
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
科学技术创新(2021年5期)2021-03-17
西安邮电大学学报(2020年1期)2020-12-17
——编码器
演艺科技(2020年7期)2020-08-13
计算机系统应用(2019年9期)2019-09-24
上海师范大学学报·自然科学版(2018年3期)2018-05-14
军事运筹与系统工程(2016年4期)2016-07-10
