
基于CNN-LSTM的歌曲音频情感分类*
2019-06-10 07:00陈长风
通信技术 2019年5期
陈长风
(杭州电子科技大学 计算机学院,浙江 杭州 310018)
0 引 言
随着计算机技术的发展,现代人们的音乐体验已经从之前的录音磁带和光盘唱片发展为数字音乐形式。音乐中含有丰富的人类情感信息,并且可以让人直观感受到其中的情感倾向。当海量音乐数据出现时,对其进行情感分析有助于对音乐数据进行有效的组织和检索。人工智能技术的兴起,能够让机器实现主观化的情感分析,许多对情感特征提取和分类方法的研究也在相应展开。
歌曲音频情感分析技术起源于语音情感分析,但由于歌曲音频的复杂性,其特征参数往往表现出维度多、数量大以及难以分析的特点,相较语音情感分析难度更高。大多数学者的研究围绕如何从时域特征和频域特征等诸多音频特征中选取能够表达歌曲中隐含情感信息的特征,并通过传统的机器学习和深度学习建立训练模型对歌曲进行情感分 类[1-5]。本文就特征选取与分类方法两个方向为出发点,研究不同音频特征参数对情感分类的影响,并试图构建新的分类模型,提高歌曲情感分类性能。
1 音频情感特征提取
1.1 音频信号预处理
声音以波的形式存在,模拟的音频信号通过采样量化编码三步操作完成模拟信号到数字信号的转换。数字音频文件读取到计算机后,表现为一行由数据组成的数组。这个数组的维度由歌曲本身的时长和采样频率共同决定。
音频信号的预处理一般包含以下步骤[6]。
预加重:在求音频信号频谱时,往往高频率部分的频谱比低频率部分难求,因此需要加入预加重步骤,目的是提高高频部分,使信号的频谱走势变得平坦,以便进行频谱分析。通常采用数字滤波器实现预加重。
分帧:为了进行短时分析,可以对整段音频信号进行时域内的分段处理,其中每一段称为一帧。一般取10~30 ms,保持短时平稳性。为了使帧与帧之间过渡平滑,可使用交叠分段的方法。
加窗:加窗的目的是解决分帧后起始和终止不连续带来的吉布斯效应。具体操作是将每个短段音频数据与一个窗函数相乘,常见的窗函数有矩形窗、汉明窗和汉宁窗。
1.2 频谱特征提取
从音频信号中可以提取到非常丰富的特征参数,其中包括时域特征和频域特征等。选择合适的特征参数,有助于提高情感分类准确性。在情感分类中,普遍使用的特征参数为梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)[7]。MFCC是基于人耳听觉系统所提出的倒频参数,考虑了人类发出声音与接受声音的过程和特点,其频率的增长与人耳的听觉特性一致[8]。MFCC的提取过程如图1所示。

图1 MFCC提取流程
对预处理后的每一帧音频信号进行快速傅里叶变化,得到每帧信号的频谱,然后通过频率与Mel频率关系:
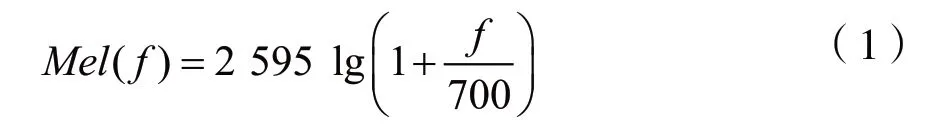
将实际频率尺度转换为Mel频率尺度。再将信号经过M个Mel尺度的三角形滤波器组,并计算每组滤波器对信号幅度滤波后的输出。对所有输出作对数运算,再进一步做离散余弦变换(DTC),即可得到每帧音频信号的M维MFCC。由于标准的MFCC只能够反映音频参数的静态特征,后续可以进行一阶差分和二阶差分系数的提取,然后组合为完整的MFCC特征向量。
除了上述MFCC特征外,音频信号还具有其他一些包含情感信息的特征参数[9],如表1所示。在实验中通过分析不同特征参数对各情感子类的影响,适当选取特征,可以大大提高情感分类性能。

表1 情感特征参数列表
2 音频情感分类方法
2.1 支持向量机
支持向量机(Support Vector Machine,SVM)是一种传统的二元分类算法,核心思想是在高维或无限维空间内构造超平面集合,然后将该平面作为决策边界来划分分类数据。SVM主要对线性可分的情况进行分析,若训练样本是线性不可分的,可以通过非线性映射将低维特征空间特征映射到高维以达到线性可分。SVM的分类效果取决于合适的核函数和惩罚变量,实际中使用RBF核函数往往能达到更好的分类效果。针对情感分类这种多分类问题,可以通过“一对一”和“一对多”两种策略,构造多个二元分类器来达到多分类的效果。
2.2 卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)是一种前馈神经网络,由若干个卷积层、池化层以及全连接层组成。卷积的结构使得CNN能够很好地利用输入数据的二维结构处理图像和语音数据。卷积层的功能是对输入的音频特征参数进行进一步特征提取,其内部包含多个卷积核,然后通过池化层进行特征选择和信息过滤,输入到全连接层解除多维结构展开为向量,并通过激励函数传递到下一层网络。经过最后一个全连接层后,使用归一化指数函数softmax输出分类标签结果。经典的卷积神经网络包括VGGNet[10]和ResNet[11]。
2.3 循环神经网络
循环神经网络(Recurrent Neural Networks,RNN) 是一类处理序列化数据的神经网络。特殊的网络结构解决了序列化信息保存传递的问题,对处理时间序列和语言文本序列问题具有独特优势。在RNN中,一个神经元的输出可以在下一时刻继续作用到自身。但是,随着时间间隔的增大,RNN可能会丧失学习距离较远信息的能力(梯度消失),难以处理长序列数据。
长短期记忆网络(Long Short-Term Memory,LSTM)是一种特殊结构的RNN,能够解决长期依赖问题。LSTM与RNN的区别在于算法中添加了一个用于判断信息是否有用的判决器,这种判决结构通常称为cell。一个cell中放置了输入门、遗忘门以及输出门三种门结构,只有算法判断有用的信息才能留下,否则被遗忘门遗忘。实际应用中,双向LSTM结构和注意力机制的引入,能够给模型带来更好的分类效果[12]。
2.4 组合网络模型
在图像和文本处理领域,已经有不少学者开展了组合网络模型的研究。R Girshick等通过CNN与SVM组合的方式,解决了目标物体检测的问题,相较传统方法性能大大提升[13]。B Shi等提出了CRNN的结构,通过CNN与LSTM网络的组合和CTC实现端到端不定长的图像文本识别[14]。
CNN网络中的卷积层和池化层起到了特征提取和特征选择的作用,可以利用CNN网络的部分结构输出一组特征向量,作为新的特征输入到SVM和LSTM。本文就歌曲音频情感分类研究为前提,以VGG-16作为基础网络,构造了两种组合网络模型,如图2所示。
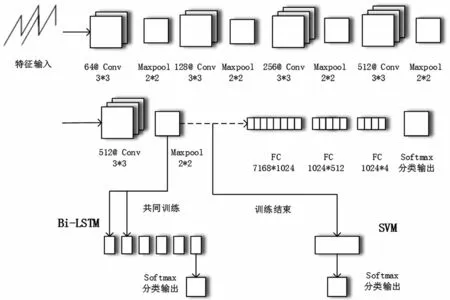
图2 两类组合网络分类模型
3 实验分析
3.1 实验准备
本文用于实验的数据集来自Million Song Dataset(百万歌曲数据集)中的Last.fm标签子集[15],从中抽取4种情感标签歌曲列表,情感标签分别为愤怒(angry)、高兴(happy)、放松(relaxed)和悲伤(sad)。通过python编写脚本工具,从各大音乐网站爬取标签列表下的歌曲音频文件,并进行人工筛选。对歌曲文件进行预处理,去掉多为背景音的前5 s数据,拆分为30 s的歌曲片段,用来统一不定长的音频数据。设定采样频率为8 kHz、单声道,每个30 s音频片段提取到的实际帧数为469帧,并通过随机划分的方式,将歌曲片段样本集划分为80%训练集和20%测试集。数据集组成如表2所示。

表2 数据集组成
3.2 不同音频特征的分类性能比较
本组实验验证不同音频特征对各分类性能的影响,将13维的MFCC特征参数与过零率、频谱质心等其他6种特征参数进行特征拼接,得到19维融合特征。实验中用SVM作为分类器,分别使用单独的MFCC特征和融合特征作为分类器的输入,并通过主成分分析(PCA)进行特征降维[16],采取 5折交叉验证进行参数寻优,分类准确率如表3所示。

表3 不同音频特征的分类准确率比较
实验表明,单一MFCC特征参数能够在一定程度上表征情感信息,但在“高兴”情感上分类表现较差;融合情感特征相比单一MFCC特征,分类准确率在整体上有所提升,且大大弥补了“高兴”分类性能的不足。其中“愤怒”分类性能相比其他三种表现突出,是因为相比其他三种情感标签,“愤怒”情感的歌曲类型一般为金属、朋克等风格,歌曲情感极性突出、节奏较快,特征参数与其他三种类型差别较大,能够获得较好的分类效果。
3.3 不同分类方法的分类性能比较
本组实验验证不同分类方法对各分类性能的影响。实验中分别使用SVM、LSTM以及CNN作为情感分类器,将融合后的特征作为各分类器输入,训练得到分类结果如表4所示。

表4 不同分类方法的分类准确率比较
实验可见,CNN相比SVM,在分类准确率上有6%的提升。由于输入特征维度较低但序列维度较高,使用LSTM进行分类,整体上没有取得较好的分类效果,但在“放松”分类下效果突出。分类结果说明,深度学习的方法可以更好地压缩和提取情感特征参数,相比较浅层学习方法具有更好的鲁棒性。因此,使用深度学习的方式进行歌曲音频情感分类是可行的。
3.4 组合网络模型与单一分类方法的比较
本组实验将2.4节中的两种组合网络分类模型与3.3节中取得较好分类效果的单一CNN分类方法进行比较,输入参数均为融合后的19维情感特征,训练后的分类效果如表5所示。

表5 组合网络模型与单一分类方法准确率比较
可见,相对于单一的CNN分类模型,两种组合网络模型都取得了较好的分类效果,其中CNN+LSTM的平均分类准确率相较CNN提升了5%,且弥补了在“放松”情感上分类效果不佳的问题。CNN+LSTM组合方法在各子分类下性能表现稳定,鲁棒性高,表明了组合网络模型在情感分类下的适用性。
4 结 语
歌曲音频情感分类的效果取决于提取到的音频特征参数和使用的分类方法。在特征参数选取上,本文采用融合的情感特征弥补了MFCC特征在特定子类别下分类效果的不足。针对歌曲情感分类这一主题,本文构建了两种组合网络分类模型,相比较SVM、CNN以及LSTM分类方法,CNN+LSTM组合模型在情感分类准确性上有较大提升。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
空间科学学报(2020年1期)2021-01-14
杭州电子科技大学学报(自然科学版)(2020年6期)2020-12-03
电子制作(2019年13期)2020-01-14
中国交通信息化(2019年12期)2019-08-13
电子制作(2019年11期)2019-07-04
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
中国交通信息化(2017年8期)2017-06-06
