
使用隐式数据中的聚类和关联规则挖掘提高协同 过滤建议的准确性*
2019-06-10 07:00王斯锋朱玉佳祝永志
通信技术 2019年5期
王斯锋,朱玉佳,祝永志
(曲阜师范大学 信息科学与工程学院,山东 日照 276826)
0 引 言
由于信息超载问题的增加,在互联网技术快速发展的时代,推荐系统正变得越来越重要,推荐系统已经成为向用户提供有用的选定信息的重要机制。它可以有效地帮助用户作出决定,例如购买产品、选择观看电影或做任何其他需要作出选择或决定的在线活动等。
推荐系统可以在线的用于某些类型的商业活动,例如电子商务(例如,Amazon 1,图书推荐系统)、在线新闻聚合器(例如,Digg 2)和在线视频共享(例如,YouTube 3)等等。这是因为互联网提供了可能对潜在购买者或消费者有用的大量信息(如在线新闻,书籍,文章,音乐,电影和其他产品)。
推荐系统中最成功的技术之一是协同过滤(Collaborative Filtering,CF),其基于志同道合的用户(称为邻居)对项目/产品的明确评级反馈,许多在线公司和商业系统(例如Netflix.com的电影推荐,Amazon.com中的图书推荐,Last.fm 5中的音乐推荐等)都适用于CF来为其客户提供建议。CF推荐算法,为用户提供了最好的结果和准确的建议,即使它具有简单的算法。
但是,与用户项目矩阵中的大量用户和项目相比,用户对项目的评级比较稀疏,CF会导致了差的推荐(数据稀疏性问题)。在项目缺乏用户评级的情况下,隐式数据可用于分析用户的项目偏好。隐性数据可以根据用户行为的观察提供更多的证据和信息来指示用户的偏好。此外,诸如聚类的数据挖掘技术、分类、奇异值分解(Singular Value Decomposition,SVD)、关联规则挖掘已被应用于推荐系统作为数据稀疏问题的解决方案,在用户和项目基于明确检索(用户评级)或暗示用户偏好,并获得最有效的结果的基础上以提供可能的连接。然而,很少有研究考虑通过关联规则挖掘来开发推荐系统。关联规则挖掘仍然存在一些需要根据新兴推荐系统来解决的问题。此外,大多数基于聚类的CF技术在聚类过程中仅利用历史评级信息,而忽略推荐系统中的其他数据资源,例如用户之间的社交关系交互(标签或用户的收听行为)以及项目之间的相关性。第2节(相关工作提供关于稀疏问题的不同解决方案的更多细节,并分析仍然存在过去的研究中未解决或被忽视的问题。
为了解决数据稀疏问题,文章将项目之间的相关性与用户数据之间的相关性结合到关联规则挖掘和聚类技术。提出了一种通过探索和利用由隐式用户反馈创建的用户简档来改进个性化推荐的CF技术。可以查看聚类技术(分层结构),以便有效地从歌曲的播放记录中分析用户的项目偏好以及作为规则挖掘部分的数据维度削减。更重要的是,文章中提出的技术主要集中在交易中使用关联规则挖掘技术(Apriori算法)与项目重复(每个用户经常播放/收听一组项目),这可以增加CF的改进机会。在基于它们的特征来提出建议时,这种技术涉及项目之间的相似性计算。
研究的主要贡献可以概括如下:
(1)首先,本研究的新颖性是在隐式数据技术中通过应用聚类和关联规则挖掘来提高稀疏数据中协同过滤建议的准确性。这是第一个在关联规则(计数问题)中捕获每个交易多次购买的学术研究,而不仅仅是计算生成总的购买量。为此,实施使用事务中的项目重复分布作为关联规则挖掘的输入的修改的预处理以发现类似的兴趣用户之间的模式。
(2)本项研究的另一个独特之处在于通过关联规则挖掘有效地处理海量数据以模拟用户的行为。为了实现这一能力,聚类技术可以被视为关联规则挖掘部分的数据维数降低。
1 相关工作
CF技术可以分为用户和项目类型。在基于用户的CF中,用户将根据志同道合的用户的兴趣受到建议。在基于项目的CF中,用户将通过考虑对用户/项目矩阵中的两个项目进行评级的用户,基于比较项目之间的相似度来接受建议。CF技术通过明确要求用户对滑动尺度的项目进行评估来构建用户项目评级矩阵。然后,CF使用相似度测量方法根据用户的评分分数来计算用户或项目之间的相似度,以便对矩阵的空单元进行预测。在大多数推荐系统中,通过增加项目数量,每个用户无法在所有可用项目上说明自己的偏好,并且无法对数百万个项目进行评估。因此,用户项目矩阵的大部分单元都是空的。 这种情况下,确定类似的用户或项目(邻里形成)成为一个挑战。这是因为两个用户或项目之间的相似性无法计算,因为没有足够的关于用户评级的信息,因此推荐准确性变得非常低。
为了克服这个缺点,一些研究人员已经开发了数据挖掘算法,用于过滤不可见项目或采用纯评级数据进行预测,如聚类CF模型,维数降低技术,贝叶斯信念网(BN)CF模型,链路分析,模式挖掘方法和潜在语义CF模型。特别地,解决CF中数据稀疏的解决方案之一是奇异值分解(SVD)方法通常用于降低CF技术中用户项目评级矩阵的维度。SVD可以减少用户项目矩阵中的空间,并通过从用户项目矩阵中找到隐藏关系来提高评级密度并找到更多的评级。Zhou等提出了一种基于SVD的增量方法,每次重复计算原始矩阵的奇异值分解,以解决稀疏问题和用户兴趣的动态。
Zahra等(2015)提到[1],聚类技术用于降低稀疏评级矩阵的维数。这种技术是基于一个概念,即在一个小的子区域内,用户往往比整个领域更好地相互联系。由于聚类子矩阵可能比原始大矩阵更密集,预期可以找到更好的相关性,通过利用用户/项目矩阵聚类的最大评级数的用户来改进推荐过程,并找出最相似的质心作为活跃用户的邻居。
除了聚类技术之外,关联规则挖掘技术也被应用于表示用户在各个领域的兴趣以提供推荐模型。这是因为它能够扩展到大数据集并实现高精度。因此,使用关联规则挖掘实施CF研究将是进一步研究的一个有趣的领域。此外,以前的研究论文都没有考虑如何通过采用关联规则挖掘来有效地处理大量数据从而预测用户未来的行为。在本研究中,我们采用聚类技术,有效地处理海量数据,通过采用关联规则挖掘来识别同一组歌曲中用户之间的相似听力历史,并预测用户的未知偏好。
除了传统的强调应用算法来改善CF的邻域形成阶段,利用超越用户/项目矩阵的附加信息源一直是研究人员的重要考虑因素。在用户和项目之间的交互方面,推荐系统依赖不同类型的输入数据来提出建议。使用最方便的交互是高质量的明确反馈,其中包括用户对产品感兴趣的明确输入。例如,Netflix 6收集电影和TiVo用户的星级,通过按向上/向下按钮指示电视节目的喜好。然而,明确的反馈并不总是可用。 因此,推荐者可以通过丰富的隐含反馈来推断用户的偏好,通过观察用户的行为间接反映意见。在隐含反馈的情况下,用户行为隐含的信息被视为偏好指标,用户听,访问,查看或购买了什么。在这项工作中,我们的数据集包含用户的音乐聆听信息和标签活动等隐含信息,以及歌曲的功能,如标题,艺术家,发行,年份,持续时间等,以获得用户对歌曲功能的兴趣。
一般来说,根据Nakatsuji和Fujiwara(2014年)的研究,可以更容易地得到“喜欢”或“不喜欢”形式的辅助数据,克服数字评级中CF的数据稀疏性,如喜好/不喜欢数据在Moviepilot以及Last.fm中的爱/禁止数据以及Flixster中的“想看到”/“不感兴趣”的数据。用户更方便地表达这种偏好,而不是数字评级。以前有研究应用这些辅助数据,“是否评级”(Shinde&Kulkarni,2012)或“是否购买”(Cheng&Wang,2014)或“点击流数据”(Choi et al 2012),以提高推荐准确度。Cheng和Wang(2014)也将模拟采购的隐含数据作为表示品牌忠诚度的用户侧元数据和“购买”用户项目矩阵,将用户品牌矩阵的隐含数据做了更改(Cheng&Wang,2014)[2]。
数据挖掘技术已被用于解决稀疏问题,因为它们能够分析用户购买行为并发现项目和用户之间的隐藏关系。因此,有必要采用数据挖掘技术作为稀疏问题的解决方案。此外,预计将分析过去研究中仍未解决或忽视的问题,以开发新的推荐技术。
要注意的是,基于对CF研究的学术研究论文和问题的回顾,很明显,即使在CF中进行的研究在不同的应用领域取得了很大的发展,音乐,书籍,玩笑和 需要进一步研究的文件推荐系统,特别是新出现的推荐系统应用。因此,为了填补这一空白,音乐,书籍,笑话和文件需要更多的研究。MovieLens数据集已经受到CF的重大研究,因为这个数据集被称为常见用户和使用中最著名的例子的数据集,并且很容易。因此,为了填补这个空白,需要更多的研究人员在其他应用领域而不是电影中使用数据集。此外,使用实用解决方案的研究工作每年都在增加用户对其隐含行为的兴趣。不幸的是,很少有研究工作已经被发布,用于从社交网络活动中吸引用户的兴趣,例如用户的标签和音乐听力信息,以推动推荐。因此,研究人员被驱使开发有效的技术来处理这些隐含的数据。
2 背景理论
本节将简要介绍CF技术的重要概念。接下来,由于所提出的技术的核心是基于关联规则挖掘技术,以基于用户的交互活动(例如(“歌曲”活动))来识别用户之间的类似兴趣模式,将介绍这种技术的简要说明。
2.1 基于CF的推荐系统概述
基本的CF系统可以分为三个步骤:建立用户评级矩阵,开发邻里基础和评级预测(使用邻居预测未分类的项目并生成建议)
CF使用用户评价数据来计算用户项目矩阵的实体之间的相似度,即用户或项目。用户和项目之间的相关性是预测用户对他/她之前没有看到的特定项目的评级的决定性因素之一。因此,通过CF设计推荐系统的中心方面是计算用户或项目之间的相似度,重点是用户或项目对之间的相关性。将这些类似的用户或项目称为最近邻居,CF预测活动用户的通过仅使用这样的社区的评级,而不是整个现有的用户评级,对未评级项目进行评级。因此,在成功选择最近邻居用户时,CF的准确性受到强烈的影响。
CF中最常见的计算相似度是皮尔逊相关系数(PCC)( 式(1))(Gogna&Majumdar,2015)或余弦矢量相似性(CVS)(式(2))(Acilar & Arslan,2009)[3]。

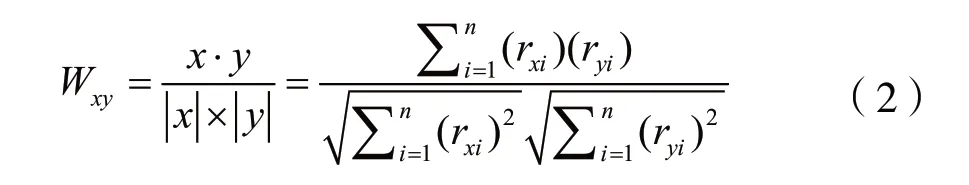
其中,rxi和ryi是项目i上的用户x和y的评级。该记号n表示用户x和y已经评分的所有项目。
当有活跃用户的类似用户被选中时,式(1)和式(2),计算预测活跃用户的偏好未分类的项目。例如,方程(3),predxj是按所有人给出的项目j的评分的加权平均数,计算在活跃用户附近的用户,如下所示:
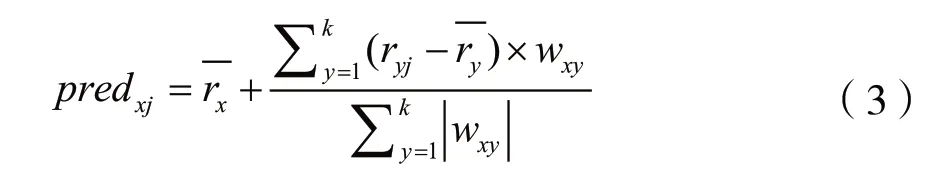
其中,k表示被识别为的用户集合活动用户的邻域和predxj是预测的用户u对物品j的加权数[4]。
虽然这两个相似性度量即Pearson和余弦度量(式(1)和式(2))在识别最近邻居用户方面是成功的,但他们在处理稀疏数据时可能会遇到挑战:
(1)大量的项目远远超出用户对其中一小部分进行评分的能力;(2)用户不喜欢评估查看/购买的项目。当与大量的用户和项目相比用户偏好非常稀疏时,基于皮尔逊和余弦度量的用户或项目之间的相似性,可能仅从少量的普通评级计算,并且可能最终导致不可靠的邻域,降低推荐系统的准 确性。
文章介绍了一种技术,通过克服数据集的稀疏性来提高媒体项目推荐系统中为用户生成的推荐的准确性。所提出的技术的核心基于关联规则挖掘技术,其通过提取关于包括用户已经玩过的标签和歌曲持续时间的歌曲特征的规则,来扩展用户的简档并且从隐式数据中识别用户的偏好。这是因为MSD中的歌曲数据集非常大,以至于无法通过应用有效且准确地处理这些海量数据,关联规则挖掘在正常的台式机上。因此,对具有不同基数的歌曲进行分组的过程取决于预定义最佳数量的聚类。它是基于歌曲特征的。
2.2 关联规则挖掘概述
关联规则挖掘技术已被广泛应用于改进建议并代表用户的兴趣的很多推荐系统,如Tyagi和Bharadwaj (2013)和Lucas,Segrera和Moreno(2012)[5]。这 种技术的目的是发现有趣的关系,根据描述重新记录的数据载入大量数据中,典型的过去用户的导航路径之间的关系。
一般来说,用户的兴趣可以通过关联规则来识别以'A->B'形式进行采矿(A和B是用户的利益或利益)项目),这意味着对'A'感兴趣的用户可能是对'B'感兴趣或换句话说,发生项目A(规则的先行一侧)导致项目B的发生(规则的后续部分)基于数据的用户事务组。例如,在营销分析中,一个关联规则'啤酒,水,尿布"表示购买啤酒和水的顾客都倾向于购买尿布。又如"当顾客购买产品时,X也可能购买产品Y,或者'喜欢产品X的用户也喜欢产品y"可以被发现(Park等,2012)。
关联规则中有两个重要的概念采矿技术,支持和规则的信心措施,用这些措施进行评估。一个人的支持和信心关联规则X->Y由等式(4)和(5)导出,只有具有以下支持和信心值的规则是被选为有用的规则(Kardan&Ebrahimi,2013;Tyagi&Bharadwaj,2013)[6]:

在推荐人中应用关联规则的动机系统,这种技术背后的想法是基于项目或用户之间的数据关联,将活动用户的数据与其他用户的数据或关联数据进行比较,活跃用户对其他项目的数据感兴趣的项目在系统上可用。事实上,关联规则挖掘描述可追踪对象之间关联的概率(用户或项目)在数据库中。通过关联规则生成的规则很容易解释,因此可以很容易地应用于实践。
3 推荐
这个阶段的目标是改进CF中的预测过程并克服与CVS和PCC度量有关的问题,在稀疏情况下只有评级数据用于计算类似用户之间的偏好和预测用户的兴趣(Bobadilla,Ortega,Hernando,&Bernal,2012)。为了解决数据稀疏性问题,我们的技术涉及听用户的历史记录,并且基于将歌曲特征(群集)匹配到用户信息来扩展用户的信息,因为歌曲的属性可以对用户的重要性加权。一旦通过跟踪用户收听习惯获得用户简档,就表示用户播放计数的比率,作为用户对特定类别歌曲感兴趣的提示。然后,根据具有相似偏好(邻居)的用户组的过去交易,使用关联规则挖掘技术提取歌曲类别之间的关联规则。换句话说,我们的技术通过参考用户的类似聆听模式,根据他们听到的音乐的重叠情况,为活动用户预测群集集合。
在预测某个类别的歌曲的活跃用户的未知偏好之后,现在是为活跃用户提供推荐给特定歌曲列表的时间。在这个阶段,我们的技术使用关于歌曲特征的信息来计算歌曲之间的相似度,所述歌曲的特征是艺术家,年份,标题,发行版,歌曲--热度,艺术家--熟悉度,持续时间和标签,以找到与已经存在的项目相似的一组项目在用户配置文件中。
改进技术基于这个逻辑计算项目对之间的相似性,如果两个项目彼此具有紧密特征,则两个项目是相似的。活跃用户收到与他或她喜欢的歌曲类似的歌曲的推荐。以往,计算歌曲之间的相似度的想法是在生成推荐时将用户简档(用户的收听历史)与歌曲特征进行匹配。这个想法背后的逻辑是,用户喜欢接收关于他们在过去基于歌曲特征选择的项目(歌曲)的推荐。
4 结 语
CF根据志趣相投的用户(邻居用户)过去的评级记录向活跃用户推荐项目。由于当用户提供的评级为真时,CF无法准确找到相似的邻居,因此用户的参考预测准确度会较低。因此,导致低质量的建议。在这项研究中,为了克服用户体验矩阵的数据稀疏性,我们提出了一种新颖的基于隐式用户反馈创建的用户配置文件的建议技术,该技术非常适合具有数据稀疏性的CF。这项研究的目标是通过有效地分析用户的项目来提高建议的准确性,以来自用户的收听活动的偏好以及与项目相关联的标签以及在同一类别的歌曲上标识类似的偏好。为了克服数据稀疏性问题,我们采用关联规则挖掘技术来发现用户之间来自隐式信息的相似兴趣模式,而不是明确的信息。近年来,已经证明单个算法通常不能克服使用基本CF的缺点并优化推荐准确性。因此,我们提出的技术通过使用聚类分析技术来减小数据的大小,并且通过使用关联规则挖掘技术来发现用户之间的相似兴趣模式,从而提高了建议的有效性。
作为未来的工作,我们打算在关联规则挖掘过程中利用更多的隐式用户反馈来通过识别相似用户的活动来生成推荐。因此,提供的建议的准确性和质量将是通过使用从关联规则中提取的更多隐式数据来改进。此外,我们计划仔细阅读用户的人口统计数据等其他数据源,以便将它们与隐式数据结合使用,以便根据有关用户及其与项目的交互的有用信息提取更可靠和更准确的规则。所进行的实验涉及一个名为MSD的数据集,其包含关于用户的收听历史的隐含数据并且可以链接到其他同胞数据集(音乐推荐数据集),以提供关于用户的收听历史的更多信息和歌曲。此外,还建议在图像,书籍和电视节目等其他领域继续进行实验评估。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
铁道通信信号(2019年6期)2019-10-08
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
雷达学报(2017年6期)2017-03-26
读者(2017年5期)2017-02-15
股市动态分析(2016年22期)2016-12-27
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
投资与理财(2009年8期)2009-11-16
