
基于SSD的仓储物体检测算法研究
2019-06-09 10:36陈亮杰王飞王梨王林
软件导刊 2019年4期
关键词:卷积神经网络
陈亮杰 王飞 王梨 王林

摘 要:随着信息技术和计算机视觉技术的发展,仓储管理自动化和智能化成为趋势,对仓储物体进行准确检测变得尤为重要。针对仓储环境下的物体检测应用场景,提出一种基于SSD的仓储物体检测算法,实现对仓储环境下的物体智能检测。首先采用VGG16网络进行图像特征提取,然后在仓储物体数据集上进行模型训练,最后通过优化模型参数将训练好的模型应用于仓储物体检测。在创建的仓储物体数据集上训练SSD300和SSD500两种模型,获得的仓储物体检测准确率(mAP)分别为91.83%和94.32%,表明该算法基本实现了仓储物体的准确检测。
关键词:卷积神经网络;仓储环境;物体检测;SSD;VGG16
DOI:10. 11907/rjdk. 182862
中图分类号:TP306文献标识码:A文章编号:1672-7800(2019)004-0028-04
0 引言
物流配送是电子商务的核心环节,仓储物体的自动检测很大程度上能推动仓储物流的自动化、智能化管理。对仓储物体进行准确检测,能够实现数据采集、管理和核对的精确化,动态反映仓储现状,使仓储管理者能及时、准确和全面地了解仓储环境空间布局情况,以有效减少员工的劳动强度,降低成本,提高工作效率。
仓储物体检测本质上属于通用物体检测范畴,物体检测是计算机视觉领域的一个重要研究方向。随着深度学习的深入,在计算机视觉领域采用基于深度学习的算法进行物体检测成为重要方法之一。
Sermanet等[1]提出基于卷积神经网络(Convolutional Neural Network,CNN)的OverFeat算法,该算法主要采用滑窗(Sliding Window)对物体进行定位检测。Girshick等[2]结合AlexNet[3]和选择性搜索(Selective Search,SS)[4]提出R-CNN(Regions with CNN)算法,该算法首先采用SS从可能包含物体的图像中提取区域,然后将这些感兴趣区域(Regions of Interest,RoI)缩放到统一大小,并输入CNN进行特征提取,最后将提取到的特征向量输入SVM分类器进行分类。由于R-CNN中的CNN特征是从每幅图像的每个区域单独提取的,一定程度上存在计算开销昂贵等缺点。因此,He等 [5]将传统的空间金字塔池(Spatial Pyramid Pooling,SPP)[6]引入CNN结构,即在最后一个卷积层(Convolution Layer)顶部添加一个SPP层,通过全连接层(Fully Connected Layer)获得固定长度的特征,提出SPP-Net算法。Girshick等 [7]提出的Fast R-CNN算法主要采用跨区域提议共享卷积计算思路,并在最后一个卷积层和第一个全连接层之间添加一个RoI池层,使每个RoI提取固定长度的特征,以提高物体检测速度和准确性。Ren等 [8]提出的Faster R-CNN算法采用一种高效、准确的区域提议网络(Region Proposal Network,RPN)代替SS生成区域提议,可同时和检测网络共享全图像卷积特征,实现端到端(End-to-End)的物体检测。Dai等[9]提出的R-FCN算法,主要通過去除全连接层和使用一组特定的卷积层作为FCN输出,构建一组位置敏感分数图进行物体检测,以此提高物体检测速度和准确性。Szegedy等[10]提出DetectorNet算法,将物体检测制定为一个目标边界框掩码的回归问题,使用AlexNet和一个回归层取代最终的Softmax分类器层。Redmon等[11]提出YOLO(You Only Look Once)算法,将物体检测作为从图像像素到空间分离边界框和相关类概率的回归问题。由于完全去除了区域提议生成阶段,因此仅使用一小部分候选区域就可直接预测检测。YOLO的检测速度非常快,但检测精度不是很高。为了在不降低过多检测精度的同时保持实时速度,Liu等[12]提出了比YOLO算法更快的SSD(Single Shot MultiBox Detector)算法。SSD算法结合了不同分辨率的多个特征图预测,以处理不同尺度物体,有效集成了YOLO算法的回归思想和Faster R-CNN算法的锚机制,采用多尺度区域特征进行回归实现了快速检测,同时仍保持较高的检测精度。
目前基于深度学习的仓储物体检测算法比较少。刘江玉等 [13]提出基于深度学习的仓储托盘检测算法,主要基于Faster R-CNN算法设计托盘检测模型,训练VGG16网络,并创建仓储托盘检测数据集,实现仓储机器人对仓储环境下的托盘检测。金秋等 [14]提出基于Faster R-CNN优化和改进后的仓储物体检测算法,该算法通过对Faster R-CNN模型进行微调(Fine-Tuning)完成对托盘、货物、人和叉车等物体的检测。本文将通用物体检测算法应用于仓储环境下的物体检测,提出一种基于SSD的仓储物体检测算法。
1 基于SSD的仓储物体检测算法
1.1 SSD网络结构
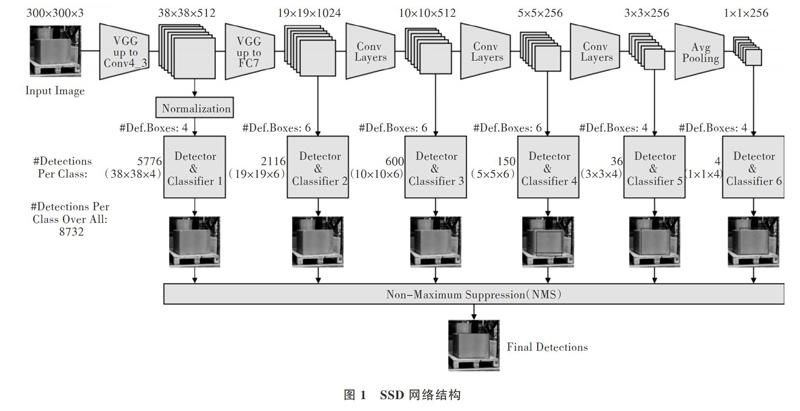
SSD算法是一种基于回归思想的深度卷积神经网络物体检测算法,CNN主要用于为那些框中存在的物体实例生成固定大小的边界框、物体类别的分数,执行非极大值抑制步骤以生成最终检测结果。由于实时性和准确性是仓储物体检测的基本性质,所以选择适用模型至关重要。虽然基于两阶段的算法在物体检测方面取得了令人满意的检测精度,但是检测速度较慢。SSD算法通过去除边界框提议和后面的特征重采样阶段,使检测速度得到了显著提升。同时,SSD算法结合不同分辨率的多个特征图,从而在多个尺度上进行物体检测,在一定程度上保持了较高的检测精度。SSD网络结构如图1所示。
1.2 图像特征提取网络
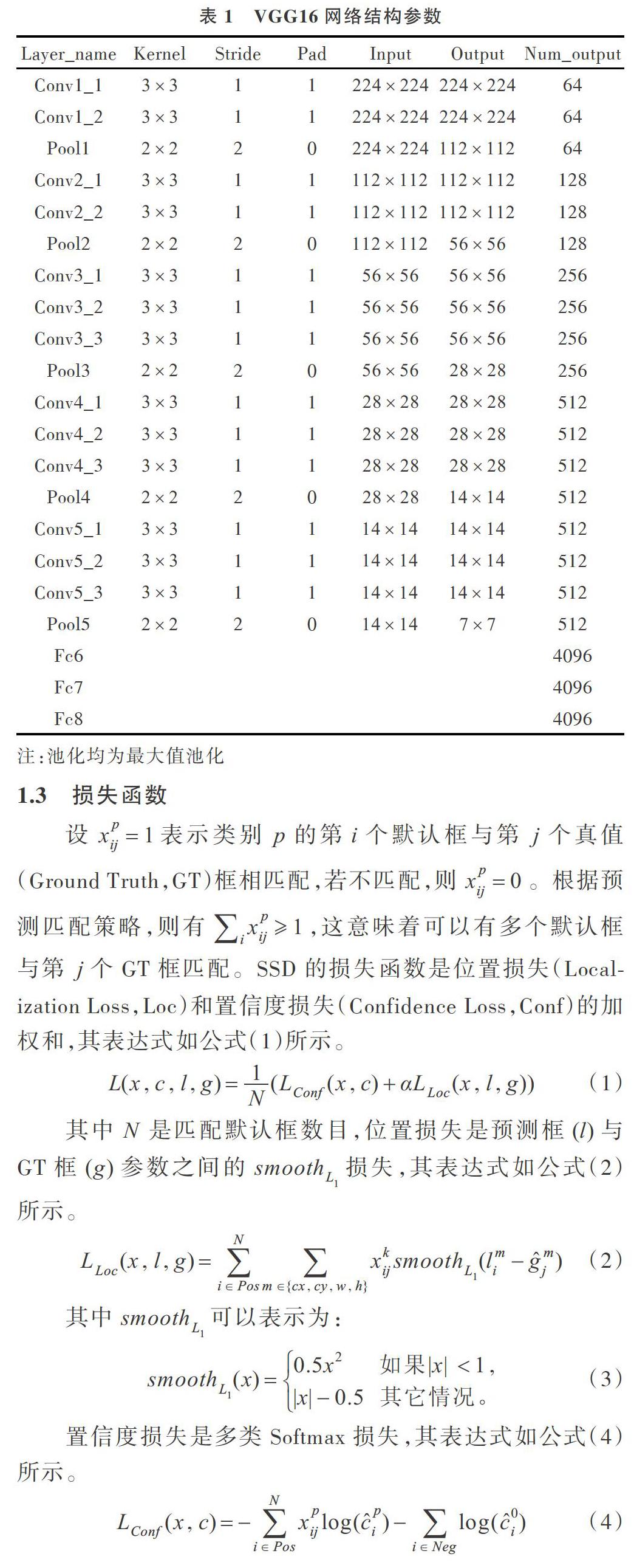
当前,用于图像特征提取的主流网络有AlexNet、GoogLeNet[15]、VGGNet[16]、ResNet[17]、DenseNet[18]等。综合考虑网络结构的复杂性和分类精度,本文选择VGG16网络进行图像特征提取,其网络结构参数如表1所示。
1.3 损失函数
设[xpij=1]表示类别[p]的第[i]个默认框与第[j]个真值(Ground Truth,GT)框相匹配,若不匹配,则[xpij=0]。根据预测匹配策略,则有[ixpij1],这意味着可以有多个默认框与第[j]个GT框匹配。SSD的损失函数是位置损失(Localization Loss,Loc)和置信度损失(Confidence Loss,Conf)的加权和,其表达式如公式(1)所示。
1.4 非极大值抑制
非极大值抑制(Non-Maximum Suppression,NMS)的实质是搜索局部极大值,抑制非极大值元素,其目的是消除多余的框,找到最佳物体检测位置。假设某物体检测到6个候选框,每个候选框分别对应一个类别分数,根据分数从小到大排列分别为(B1,S1),(B2,S2),(B3,S3),(B4,S4),(B5,S5),(B6,S6),S6> S5>S4>S3>S2>S1。NMS的执行步骤为:①根据分数大小,从最大概率矩形框B6开始;②分别计算B1~B5与B6的重叠度IoU是否大于预设阈值,如果大于设定阈值就舍弃分数小于B6的框,同时标记保留的框。例如,假设B2、B4与B6的重叠度超过阈值,就舍弃B2、B4,并标记B6为第一个需要保留的框;③从剩余的矩形框B1、B3、B5中选取类别分数最大的B5,并判断B5与B1、B3的重叠度。如果IoU大于设定的阈值,同样舍弃B1和B3,同时标记B5为保留下来的第二个矩形框;④重复此过程,直到找到全部保留框。
1.5 训练策略
训练过程中需要确定哪些默认框对应于GT检测并相应地训练网络,每个GT框都需要从不同位置、长宽比和尺度的默认框中进行选择。采用MultiBox中的最佳Jaccard重叠将每个GT框匹配到默认框,以使每个GT框都有一个对应的源框。如果Jaccard重叠大于阈值0.5,则将默认框与任意GT框匹配。不同于两两匹配,每个预测匹配可为每个GT框生成多个正的先验匹配。对于每个先验,SSD算法在所有物体类别之间共享边界框调整。
2 实验结果与分析
2.1 实验运行环境
本文实验在Ubuntu16.04操作系统下基于Caffe深度学习框架完成,运行环境基本配置为:GPU型号:NVIDIA TITAN X,CPU型号:Intel i7-7700k,显存16GB,CUDA为CUDA8.0。
2.2 实验数据集
本文实验所需数据均为真实仓储环境下通过摄像机采集获得的仓储物体图像,并采用图像标注工具LabelImg进行标注,创建一个仓储物体数据集,其包含10 450张图像。将仓储物体数据集分为训练集(Train Set)、验证集(Validation Set)和测试集(Test Set),训练集约占64%,验证集约占16%,测试集约占20%。
2.3 实验结果及分析
为验证本文算法的有效性,在创建的仓储物体数据集上进行训练和测试。训练两种不同输入大小的模型,即SSD300和SSD500,测试得到的物体检测准确率mAP(mean Average Precision)如表2所示。
由表2可知,SSD500的mAP为94.32%,SSD300的mAP为91.83%,SSD500的mAP比SSD300的mAP提高了2.49%,基本实现了仓储物体的准确检测。
由于篇幅所限,仅给出部分仓储物体测试图像的检测效果,如图2所示。
从图2可以观察到,在光照条件、物体尺度大小和颜色发生变化时,本文提出的仓储物体检测算法都能较好地检测出仓储环境下的物体。
3 结语
本文将基于卷积神经网络的单阶段SSD算法应用于仓储环境,提出一种基于SSD的仓储物体检测算法。该算法首先采用VGG16网络进行图像特征提取,然后在创建的仓储物体数据集上训练SSD300和SSD500两种模型,分别获得91.83%的mAP和94.32%的mAP,基本實现了仓储物体准确检测。但是本文算法对于较小的仓储物体仍会出现漏检,原因可能是本文使用的预训练模型是在ImageNet上预训练的,导致预训练模型与仓储物体检测模型存在差异,也有可能是由于创建的仓储物体数据集数量不够大。因此,针对物体漏检问题,下一步需要优化或改进算法,创建一个规模大且质量高的仓储物体数据集,以尽量防止漏检问题发生,从而进一步提升仓储物体检测准确率。
参考文献:
[1] SERMANET P,EIGEN D,ZHANG X,et al. Overfeat: integrated recognition, localization and detection using convolutional networks[EB/OL]. http://arxiv.org/abs/1312.6229.
[2] GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]. IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580-587.
[3] KRIZHEVSKY A,SUTSKEVER I,HINTON G E. Imagenet classification with deep convolutional neural networks[C]. Advances in Neural Information Processing Systems, 2012: 1097-1105.
[4] UIJLINGS J R R, SANDE K E A V D, GEVERS T, et al. Selective search for object recognition[J]. International Journal of Computer Vision, 2013, 104(2): 154-171.
[5] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,37(9):1904-1916.
[6] LAZEBNIK S, SCHMID C, PONCE J. Beyond bags of features: spatial pyramid matching for recognizing natural scene categories[C].IEEE Conference on Computer Vision and Pattern Recognition, 2006: 2169-2178.
[7] GIRSHICK R. Fast r-cnn[C]. IEEE International Conference on Computer Vision, 2015: 1440-1448.
[8] REN S,HE K,GIRSHICK R,et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]. Advances in Neural Information Processing Systems, 2015: 91-99.
[9] DAI J, LI Y, HE K, et al. R-FCN: object detection via region-based fully convolutional networks[C]. Advances in Neural Information Processing Systems, 2016: 379-387.
[10] SZEGEDY C, TOSHEV A, ERHAN D. Deep neural networks for object detection[C]. Advances in Neural Information Processing Systems, 2013: 2553-2561.
[11] REDMON J,DIVVALA S,GIRSHICK R,et al. You only look once: unified, real-time object detection[C]. IEEE Conference on Computer Vision and Pattern Recognition, 2015: 779-788.
[12] LIU W,ANGUELOV D,ERHAN D, et al. SSD: single shot multibox detector[C]. European Conference on Computer Vision, 2016: 21-37.
[13] 劉江玉,李天剑. 基于深度学习的仓储托盘检测算法研究[J].北京信息科技大学学报, 2017, 32(2): 78-85.
[14] 金秋,李天剑. 仓储环境下基于深度学习的物体识别方法研究[J]. 北京信息科技大学学报,2018,33(1): 60-65.
[15] SZEGEDY C, LIU N W, JIA N Y, et al. Going deeper with convolutions[C]. Boston:IEEE Conference on Computer Vision and Pattern Recognition, 2015.
[16] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. Computer Science, 2014(1):2205-2211.
[17] HE K,ZHANG X,REN S,et al. Deep residual learning for image recognition[C]. IEEE Conference on Computer Vision and Pattern Recognition,LasVegas:2016.
[18] HUANG G,LIU Z, MAATEN L V D, et al. Densely connected convolutional networks[C].IEEE Conference on Computer Vision and Pattern Recognition, 2017: 2261-2269.
(责任编辑:杜能钢)
猜你喜欢
科技创新与应用(2017年5期)2017-03-16
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
