
基于堆叠自编码器的恶意域名检测
2019-06-04 06:01:12甘肃省公安厅网络安全保卫总队张生顺
网络安全和信息化 2019年5期
■ 甘肃省公安厅网络安全保卫总队 张生顺
编者按: 本文提出了一种基于堆叠自编码器的恶意域名检测模型,通过域名生成算法(DGA)生成C&C域名作为恶意域名集合,最后再将堆叠自编码器和识别分类的功能结合起来进行测试,检测精度达到97.3%。
恶意域名网站给网络用户和企业带来巨大的财产损失和安全威胁,而且由于速变域名和域名生成算法(DGA)技术的不断发展,恶意域名更加难以被检测识别。最初检测方法是利用域名黑名单匹配域名字符串,并使用高匹配来阻止域名,但黑名单需要不断更新,更新速度可能较慢,提高检测精度已经成为现下维护网络安全的主要任务。
目前国内外主要基于统计和机器学习两个方面来对恶意域名进行检测。例如,2007年 Honeynet实 验组提出了速变域名的概念。Passerini等人提取了域名的TTL值等一系列特征值来分析检测恶意域名。Notos系统使用字符串统计特征信息和域名历史记录来确定是否是恶意域名。基于机器学习的方法主要通过对恶意域名大数据的分析提取特征值,得出一套检测规则用于分类。FluxBuster系统第一次将聚类算法应用于速变域名的检测。国内有利用支持向量机和神经网络去检测恶意域名,或通过随机森林算法完成速变域名检测模型的构建。

图1 含两个隐藏层的堆叠自编码器
堆叠自编码器
自编码器是一种无监督学习算法,包括输入层、隐藏层、输出层。自编码器是一种理想状态下输出和输入相同的特殊神经网络算法,输出向量是对输入向量的复现。整个输入层和隐藏层称为编码器,输入向量映射到具有不同隐藏层维度的向量。整个隐藏层和输出层称为解码器,隐藏层的向量映射到输出向量。隐藏层向量可以复现输入向量,称之为特征表示向量。自编码器的主要功能就是生成输入数据的主要特征表示向量。

图2 预训练含三个隐藏层的堆叠自编码器图
图3 特征工程的一般流程
堆叠自编码器是由两个或两个以上的单个自编码器组合而成的,实则就是增加了隐藏层的数量,经过贪婪算法预训练和多层非线性网络,最后从复杂高维的输入数据中学习到不同维度和层次的抽象特征向量。堆叠自编码器中的每一个隐藏层都是输入特征值的另一种表示,并且降低了输入数据的维数,具有提取输入特征值的强大学习能力。如图1所示。
整个堆叠自编码器的训练过程包括两个步骤:第一步是预训练,通过无监督方式去训练单个自编码器,每当上一层训练完时,输出被当做下一层的输入,再继续训练,直到训练完整个隐含层数目,最后输出。假设有三个隐藏层的堆叠自编码器,x表示输入要素向量,hi表示每个隐藏层的表示向量,x",h1’和h2’表示单个自编码器重建的输出向量,w和wT都是权重矩阵。预训练的具体步骤如下,如图2所示。
(1)用无监督训练的方式训练堆叠自编码器的第一隐藏层;
(2)上一个隐藏层训练完成的输出被视为下一个隐藏层的输入,再以无监督方式进行训练;
(3)重复执行步骤(2),直到所有的隐藏层都训练结束。
第二步是微调,是在预训练结束后,再训练整个堆叠自编码器,并且利用误差反向传播调整整个系统的参数,使得权值和偏置值都达到最优。
数据分析
1.数据收集
本文提出了一种基于堆叠自编码器的恶意域名检测模型,使用的恶意域名数据集来源于域名生成算法(DGA)生成的C&C域名。通过使用一个私有的字符串,每隔一定时间生成一系列随机字符串用作域名,再从中随机取出一些作为C&C域名。数据集中的合法域名来自Alexa网站,可认为其中排名靠前的域名为合法域名。判断是否为恶意域名是一个二分类问题,数据集一共25万条数据,其中正例是恶意域名,共使用DGA生成15万条。反例是正常的域名,共收集到近10万条。
2.特征工程
特征工程是机器学习过程中至关重要的一步,想要提高预测模型的精确度,不仅需要选择优化的算法,更要获得好的训练数据,尽可能从原始数据中挖掘更多有用的信息。从给定数据中挑选一组最具有代表性,有统计意义的特征子集,是特征工程的关键任务。特征工程的一般流程如图3所示。
特征工程需要经过循环往复的挑选检验,对选择的特征用分类算法检验并评价结果,假如结果达不到预想效果,应舍弃并重新选择特征。本次实验挑选了根域名,域名各个字符出现的随机性,域名字符长度,连续单字符、双字符、三字符出现的频率的平均排名,域名的连续分散性等17个特征值来描述域名信息。并归一化特征值,获得最终的数据集。

表1 分类指标

表2 分类结果
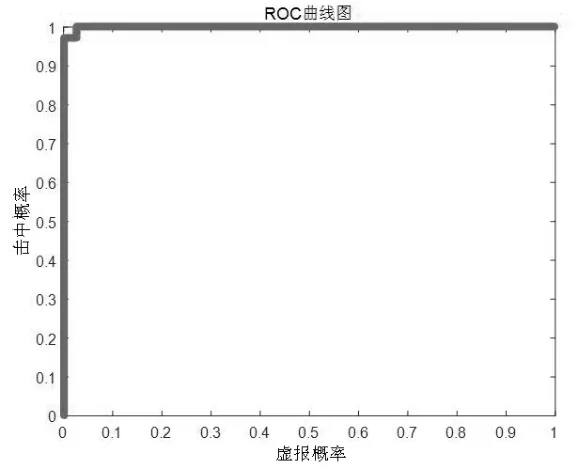
图4 ROC曲线图
实验结果分析
本文中基于堆叠自编码器的恶意域名检测模型是通过MATLAB R2016a平台进行实现,将25万条域名数据集分为20万条域名训练集,剩下的5万条域名作为测试集。
1.评价指标
判断是否为恶意域名是一个二分类问题,通常采用精确率、召回率、误判率和准确率四个指标来衡量。本文中恶意域名是正例,用“1”表示,合法域名是反例,用“0”表示。分类结果如表1所示。
TP表示被检测为恶意域名的恶意域名数量,FP表示被检测为恶意域名的合法域名数量,TN表示被检测为合法域名的合法域名数量,FN表示被检测为合法域名的恶意域名数量,N=TP+FP+FN+TN表示测试集总的域名个数。
(1)精确率 :TP/(TP+FP),表示被检测为恶意域名的恶意域名数占总被检测为恶意域名数的比率。
(2)召回率 :TP/(TP+FN),表示恶意域名被检测为恶意域名的个数占实际总恶意域名个数的比率。
(3)误判率 :FP/(FP+TN),表示被检测为恶意域名的合法域名数与合法域名总数的比率。
(4)准确率:(TP+TN)/N,表示检测到的正确域名数量与测试集域名总数的比率。
在计算实验结果的数据之后,获得如表2所示的4个评价指标的值。
2.ROC与AUC
ROC曲线是横坐标上的假阳性率和纵坐标上的召回率。根据定义,误判率越小,召回率越大,模型的分类效果越好。故ROC曲线越靠近坐标系左上方,模型的分类效果越好。本次实验的ROC曲线如图4所示。
AUC是指ROC曲线以下的面积。AUC值介于0到1之间,当模型的AUC值越大,分类效果更好,模型更合适。实验的AUC值为0.9992,接近于 1,表示本文提出的基于堆叠自编码器的恶意域名检测模型分类效果较好,检测精确度较高。
结语
本文基于堆叠自编码器的恶意域名检测模型,挖掘了域名信息的各项特征,利用堆叠自编码器重构特征值,最后用分类器检测。实验结果表明,该模型能够有效识别出恶意域名,检测精度高达97.3%,有较好的分类效果,提高了恶意域名的检测效率。
猜你喜欢
数学物理学报(2021年5期)2021-11-19 07:01:12
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:40
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
计算机与网络(2018年10期)2018-02-15 09:06:37
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
东北电力大学学报(2015年1期)2015-11-13 05:20:25
中国知识产权(2015年9期)2015-05-30 10:48:04
四川轻化工大学学报(自然科学版)(2014年3期)2014-04-16 03:56:42
电测与仪表(2014年13期)2014-04-04 12:04:18
