
基于DPI和机器学习的加密流量类型识别研究
2019-06-03 12:51陈荣平
数字通信世界 2019年4期
陈荣平
(中国移动通信集团广东有限公司,广州 510000)
伴随互联网技术水平不断提升,网络应用也在不断革新,用户对于网络质量和网络安全性的要求也在变高着。为保护用户隐私,保证数据传递的可靠性,互联网开始引入了HTTPS协议,从而实现了互联网数据的加密。而伴随加密流量的数额巨升,在保证数据传输可靠性的同时,运营商同时也要对加密流量进行识别,从而为用户提供差异化服务。
1 网络流量识别方法
当前主要有三种网络流量识别方法:
1.1 通过端口号进行流量识别
其主要依照TCP/UDP 协议端口号展开应用流量识别。IANA所分配的通用端口号是0-1023,比如说,能够利用80端口识别WEB应用,利用23端口识别 Telnet,利用21端口识别FTP等,很多应用程序都于早期设置过特定端口,所以通过端口号来进行流量识别的方式很容易想到[1]。通过端口号来进行流量识别的方式比较简单,且具备可操作性,对于传统-网络的流量识别非常精准。然而伴随互联网技术的普及和发展,很多新兴业务已经开始不再采用标准化端口,都选择绕过防火墙,采取动态端口的方式,这就导致通过端口号来进行流量识别的方式不再适用,无论是识别精准度,还是识别难度,都受到非常大的影响。
1.2 通过特征字段进行流量识别
通过特征字段进行流量石碑,其技术就是Deep Packet Inspection,简称DPI技术。DPI技术会通过特征字段来进行业务的匹配,并分解网络数据包,从而就可以分析数据包特征码,进而就可以确定应用程序类型。所以,DPI技术对于应用程序端口的依赖程度较低,能够有效是被P2P等护理网应用类型[2]。然而DPI技术的识别取决于应用协议特征字段,因此没有办法对数据包荷载未知情况进行识别,伴随数据加密技术和应用的不断发展,这种检测方式已经没有办法有效满足实际应用需求。
1.3 通过机器学习进行流量识别
机器学习系统模型如下图所示:
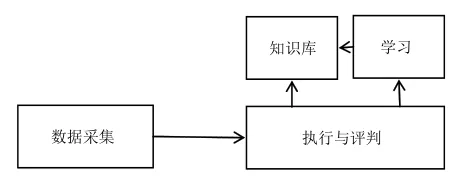
图1 机器学习系统模型
如图1所示,机器学习系统模型是闭环系统,能够互相促进和更新。首先,系统在外部环境中采集到相关信息,然后对数据信息进行有效处理,知识库模板中会有固定的规律知识模型,按照知识库规则方法来进行实际问题的解决,并验证评判实际应用效果,与此同时,还会把收集到的价值信息传至学习模块来进行规则方法的补充更新。通过机器学习进行流量识别的方式会先提取流量统计特征,然后利用机器学习算法把统计特征训练成为流量识别模型,然后进行未知流量类型的有效识别[3]。不管是通过端口号进行流量识别,还是通过特征字段进行流量识别,从本质上来说都为解析识别方式,必须要按照相应设置规则来进行流量识别,都缺乏足够的智能性。然而与之相比,通过机器学习来进行流量识别的方式并不再局限于流量局部解析特征,其是利用流量宏观特征来进行识别,利用数据挖掘分类技术进行流量类型划分,智能性较高。但其也存在局限性,无法对具体应用进行识别。
2 基于DPI和机器学习的加密流量类型识别方法
基于DPI和机器学习的加密流量类型识别方法有效地结合了DPI识别技术和机器学习识别技术的优势,具体流量如下图所示:
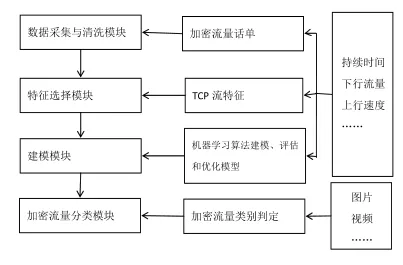
图2 加密流量类型识别流程
数据采集与清洗模块:利用DPI技术对SSL/TLS协议中的HOST进行提取,然后重新填至用户话单内,从而就会形成一个加密话单数据。
特征选择模块:按照从话单中得到的原始数据及相应计算口径产生TCP数据集,之后就可以向下输出[4]。
建模建块:通过随机森林算法来对当前获取到的大数据展开建模,依据上选取查准率、查全率及F值,对模型进行评估,之后展开参数调优。
加密流量分类模块:对流量种类不明确的加密流量流特征进行计算,通过模型来对计算结果进行判定,从而就可以获取到是否为加密流量。
3 结束语
在本文的研究出指出了一种结合DPI技术优势和机器学习优势的新型加密流量识别方式,利用DPI技术来对网络流量进行识别,能够获取到很多已知特征的数据。这一点可以有效地降低机器学习计算量,且可以对具体应用进行识别,之后利用机器学习对未知特征加密流量进行有效识别,这可以在很大程度上弥补DPI技术没有办法对未知加密流量进行识别,从而就可以大大提升识别率。
猜你喜欢
环球时报(2022-07-13)2022-07-13
湖南理工学院学报(自然科学版)(2022年1期)2022-03-16
环球时报(2022-03-14)2022-03-14
西安航空学院学报(2021年1期)2021-07-24
科学家(2021年24期)2021-04-25
电子制作(2019年13期)2020-01-14
太原科技大学学报(2019年3期)2019-08-05
电影(2018年8期)2018-09-21
课堂内外(小学版)(2017年5期)2017-06-07
航天器工程(2014年5期)2014-03-11
