
一种面向微博的突发事件触发词识别方法研究
2019-05-27 07:08:42孙小川尹浩然芦天亮
中国人民公安大学学报(自然科学版) 2019年4期
孙小川,吴 警,尹浩然,芦天亮
(中国人民公安大学信息技术与网络安全学院, 北京 102600)
0 引言
近年来,伴随着互联网技术的发展,自然语言处理领域中的事件抽取技术在很多方面有了新的进展,并得到了广泛应用,如搜索引擎、文本分类和舆情分析等[1]。互联网中公开文本语料库和大规模真实书面文本语料库的广泛使用,使得事件抽取技术越来越依赖于统计机器学习的方法,进一步促进了事件抽取技术发展。
事件是由事件触发词标识,关联了参与者、时间和环境等要素组成[2],而事件抽取是从非结构化信息中抽取出用户关注的事件,并且以一定的形式呈现给用户。事件抽取主要包含两个步骤[3]:一是对事件的识别,二是对识别出的事件进行分析,进而抽取事件要素。而事件识别中,触发词识别是事件抽取的核心任务之一,也是判定事件类型的基础[4]。因此,事件触发词的识别既能表征事件识别,也能奠定事件抽取基础。网络文本中存在海量、篇幅较短且原创性较高的数据文本,但文本数据规范性程度较低,存在大量文本片段指向同一事件主题或社会现象。当前事件抽取主要通过触发词示别、文本聚类和关键词抽取等方法进行事件检测,存在抽取精度不足,事件冗余和事件粒度较粗等问题,无法精细化描述事件信息。为此,文中提出一种融合模型进行事件触发词识别方法,旨在从低规范化的网络文本中准确抽取突发事件信息,提升触发词识别准确率,进而提高事件检测精度。
1 相关研究
近年来,触发词识别研究已经取得许多成果,研究大致分成如下两大类:基于模式匹配的方法和基于机器学习的方法。
1.1 基于模式匹配的方法
模式匹配方法是通过寻求一定的模式匹配规则,在文本数据串中寻求一个模式串的匹配结果,是数据检索的核心[5]。李培峰等[6]采用基于核心论元和辅助论元的规则构建方法进行了触发词的识别实验,F值为70.4%;孟环建等[7]采用基于依存句法的规则匹配方法进行了事件识别实验,F值为67.1%。基于模式匹配的方法触发词识别中人工工作量大、效率和识别率偏低。当前,触发词研究集中于采用机器学习的方式。
1.2 基于机器学习的方法
基于机器学习的方法通常将词向量做为输入特征进行模型训练,并进行触发词的识别,模型训练中又有单一模型和融合模型识别。基于单一模型的方法中,王红斌等[8]采用神经网络作为分类器,将词向量作为神经网络的输入对事件句的语义进行分类,并在CEC语料库进行实验,取得较好结果;何馨宇等[9]采用了双向长短时记忆神经网络,将词向量以及所有单词对应的预训练词向量和微调后词向量的差值求和取平均得到的句子向量做为特征输入,进行触发词识别,并在MLEE语料库中进行了触发词的识别实验,F值分别为73.62%和77.13%;Yubo Chen等[10]使用动态多池卷积神经网络对句子中的每个单词进行分类从而识别触发词,并在ACE语料库中进行了实验,F值为69.1%。基于单一模型的方法中,虽然事件触发词识别模型训练快捷,识别率较传统有所提高,但是建立准确的模型需要进行大量实验和学习,学习周期长,实验效果并不是很理想。
基于融合模型的方法一般将多种识别方法相结合,构建一个融合多种方法的新模型。苏晓丹等[11]采用了一种将规则与二值分类相结合的混合模型方法,并在人民日报的年全语料中随机抽取500篇文本进行实验,F值为68%;陈亚东等[12]将高置信度词典的特征分别加入到最大熵和条件随机场模型当中,融合两个模型进行触发词的识别,并在KBP2015英文语料库中进行实验,实验结果相比于ME最大熵模型的F值59.03%,融合模型进行触发词识别F值为65.46%,F值提高了6.43%。基于融合模型的方法中,触发词识别模型训练高效,同时避免了大量人工工作,兼顾了识别准确率,也是本文采用的触发词识别方法。
2 基于扩展触发词表的触发词识别
本节实现基于扩展触发词表的触发词识别,其主要包括以下两个步骤[13]:
(1)语料库中去除停用词后采用统计学习计算出高频词,以此构建出原始触发词表,进而采用同义词林[14]扩展技术在语料库中进行扩展,得到扩展触发词表;
(2)在扩展触发词表基础上创建候选触发词集,通过计算候选触发词权重比,选取权重比较大的候选触发词作为事件触发词。
2.1 构建原始触发词表
文中沿用对中文事件和事件要素标注较全面的CEC语料库[15]构建原始触发词表。通过统计学习对CEC语料库进行统计研究,并整理出语料中出现频率较高5类事件及各类事件的触发词,原始触发词统计结果如表1所示。

表1 原始触发词统计表
2.2 扩展原始触发词表
文中结合人工检查并采用哈尔滨工业大学同义词林[16]对原始触发词表进行扩展,扩展规则如下:
(1)从原始触发词表中提取事件类型主题词,对其进行同义词林扩展,得到其相对应的词汇集;
(2)为避免原始触发词过度扩展,筛选词语编码的前三级词语,筛选后的词语表达意义相似,符合原始触发词扩展;
(3)最后进行人工筛选,选择事件触发词,得到扩展后的事件触发词表。
经过扩展后的触发词表如表2所示:
2.3 基于扩展触发词表的触发词识别
首先,对文本数据进行数据预处理,文中使用结巴分词[17]工具,包括分词、词性标注和分句等步骤;其次,从预处理后的按照文献[18]的研究结果从文本中筛选出触发词词性,缩小候选触发词集范围;最后,计算并选取触发词权重比较高的词作为事件触发词。
词语是表达文本处理的最基本单元,因此,文中基于word2vec技术[19]生成词向量,采用词频- 逆文档频次算法来计算词权重,计算公式如下[20]:

其中wi为候选触发词,ni为候选触发词wi在语料库中触发的事件总数,mi为训练语料中该类事件总数,Ni为全部训练语料中句子总数,Mi为含有触发词wi为的句子总数,scorei代表触发词的权重。
上述公式中,TF为词频,它反映触发词对整个事件的贡献程度;IDF为逆文本频率指数,它过滤掉常见的词语。将权重较大的候选触发词作为突发事件触发词。该方式基于词向量模型,仅考虑数据统计特征信息,收敛速度快,但是选取特征单一,人工工作量较大,触发词识别率偏低。
3 基于P- Multi模型的触发词识别
鉴于词向量模型中触发词识别率偏低,文中借鉴融合模型的方式提出基于P- Multi模型的触发词识别,并在特征选取中考虑文本语义信息[21],对微博突发事件进行触发词识别。本节在扩展触发词表的基础上,构建事件触发词模式匹配规则,分析文本中潜在语义,进而完成对微博突发事件中触发词的识别,基于P- Multi模型的触发词识别总体流程图如图1所示:

图1 基于P- Multi模型触发词识别流程图
基于P- Multi模型的触发词识别,其主要包括以下3个步骤:
(1)对数据进行预处理,分析语料库中数据统计特征信息,并进行依存句法分析[22],凝练出词对间依存关系,建立模式匹配规则;
(2)对预处理后的文本数据逐一进行模式规则匹配和语义信息提取,模式匹配基础上结合潜在语义分析,得到候选触发词集;
(3)重复以上步骤,并对得到的候选触发词集与基于扩展触发词表识别出的触发词集进行相似度比较,筛选出权重较大的候选触发词作为事件触发词。
3.1 模式匹配的构建
句子的构成单元是词,文中利用哈尔滨工业大学的语言云平台[23]对语料库进行依存句法分析后发现触发词是满足一定的句法关系,且这些句法关系有规律可循,并非杂乱无章[24]。因此,本文根据依存句法分析结果,总结出以下6种主要依存关系,如表3所示。
根据上面分析,利用词对间依存关系,本文制定了如下抽取规则:
(1)规则1:当句中存在ATT关系类型,候选触发词可能处于谓语位置,那么识别〈ATT的核心词〉;
(2)规则2:当句中存在CMP关系类型,候选触发词可能处于动补结构中,那么识别〈CMP的核心词〉;
(3)规则3:当句中存在SBV关系类型,候选触发词可能处于主语、谓语位置,那么识别〈SBV的修饰词,SBV的核心词〉;
(4)规则4:当句中存在VOB关系类型,候选触发词可能为SBV的核心词和VOB的核心词,那么识别〈VOB的核心词〉;
(5)规则5:当句中存在FOB关系类型,候选触发词可能为FOB的核心词和ADV的核心词,那么识别〈FOB的核心词〉;
(6)规则6:当句中存在ADV关系类型,候选触发词可能处于状中结构中,那么识别〈ADV的核心词〉。
根据主要依存关系,对语料库进行训练,按照抽取规则初步筛选出候选触发词词对,下一步筛选出候选触发词集。
3.2 潜在语义分析识别候选触发词集
LSA(Latent Semantic Analysis,潜在语义分析)算法[25]是为了解决传统向量空间模型对文本的语义信息利用能力匮乏的问题,由美国贝尔通讯实验室S.T.Dumais首次提出,全面和完整的阐述了潜在语义分析在提取文本语义上的实现方法,主要步骤包括以下4个步骤:
(1)对文本进行向量化;
(2)将所有的词向量拼接起来构成词- 文本矩阵,并进行SVD(奇异值分解)操作;
(3)根据SVD结果将词- 文本矩阵降维到一个低维度的语义空间中,以此近似表达SVD结果,通常情况下会考虑降维过程中数据保留方差百分比,用语义维度权重K表示;
(4)每个词和文本都可以表示为低维度空间中的一个点,通过计算KL相似度[26],选取相似度低于语义维度权重K的词加入候选触发词集。
文中在尽可能减少信息损失的情况下对特征数据进行降维,因此文中采用PCA[27](Principal Component Analysis,主成分分析)方法对犯罪数据进行降维,该算法会考虑降维过程中数据保留方差百分比,其计算公式为:
其中,k为数据保留方差百分比,λj为协方差矩阵的第j个特征值。
降维过程中数据保留方差百分比越大,语义信息保存越完整,文中当K=0.5时,基于潜在语义分析识别候选触发词集如表4所示。

表4 潜在语义分析识别候选触发词集表
3.3 候选触发词相似度分析
在结合模式匹配和潜在语义分析基础上得到基于多值(P- Multi)确定的候选触发词集,为进一步提升触发词识别准确率,将该候选触发词集与基于扩展触发词表识别出的触发词进行相似度分析,文中基于哈尔滨工业大学同义词词林扩展版计算词语相似度[28],选取相似度较高的候选触发词作为触发词。
4 实验及性能比较
本文实验阶段所采用文本数据主要来源于微博和CEC语料库,其中模型训练阶段实验数据选用中文突发事件语料库进行训练,突发事件语料库的分类体系包括3个层次,标注的中文突发事件语料库主要包括地震、交通事故、恐怖袭击、食物中毒和火灾5个类别,总共332篇;微博数据通过爬虫爬取,剔除无效数据,保留了14 257条微博文本数据作为测试集。
模型评价标准采用通用的评价指标:准确率(precision)、召回率(recall)以及两者结合计算得到的F值(F1-measure)对事件触发词识别性能进行评价。具体定义如下[29]:
Correct:如果模型识别为触发词与人工标注为触发词相同;
Incorrect:如果模型识别为触发词与人工标注为触发词不同;
Missing:如果人工标注为触发词,但模型未识别;
Spurious:如果模型识别为触发词,但人工未标注;
通过使用以下参数评价模型性能:
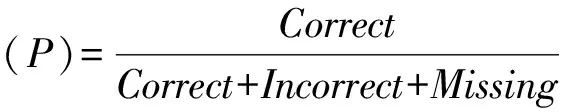
文中对语料库进行数据预处理并统计分析,多次训练语料库,使模型趋于稳定,而后针对人工标注的微博数据进行测试,通过实验结果衡量和评估模型性能。
4.1 语义维度权重对实验结果影响
实验中在触发词识别中涉及到的语义维度权重,需要设置阈值提取文本语义信息,参数设置对实验结果具有一定影响,模型中语义维度权重因子对实验结果影响如图2,图3所示。

图2 语义维度权重—准确率关系图

图3 语义维度权重—召回率关系图
从图中分析可知,当设置语义维度权重较大时,触发词识别准确率呈现上升趋势;相反,触发词识别召回率却呈现下降趋势。由此可见,触发词识别中考虑文中语义信息多时,对触发词精准识别具有明显提升。
4.2 相似度权重对实验结果影响
但是在事件触发词识别中,仅仅考虑识别准确率是不够的,还应考虑召回率,模型训练中涉及到的触发词相似度权重因子对实验结果同样具有一定影响,相似度权重因子对实验结果影响如图4、图5所示。

图4 相似度权重—准确率影响图

图5 相似度权重—召回率影响图
进一步分析可知,当相似度权重较大时,触发词识别准确率呈现下降趋势,触发词识别召回率呈现上升趋势。当相似度权重接近于1时,基于融合模型方法与基于模式匹配方法结果接近。
4.3 模型评价
文中进行多次实验,进一步衡量模型优劣,实验结果取多次实验结果平均值,实验结果如表5所示。

表5 模型衡量指标表
文中通过突发事件触发词识别率之和来描述事件检测的准确性,通过表5可以看出,基于P- Multi模型在触发词检测阶段P值之和为2.83,基于扩展触发词表在触发词检测阶段P值之和为2.59,P值提高了0.24;同理,R值提高了0.35,F值提高了0.28。为进一步衡量模型的有效性,文中将触发词识别结果进行均值化处理并与其他触发词识别方法的实验结果进行对比,对比结果如表6所示。
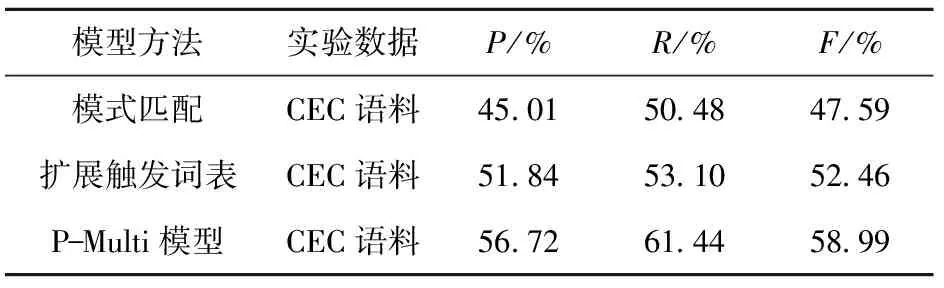
表6 实验结果对比表
通过表6中分析可知,定义模式规则,采用模式匹配方法对事件触发词进行识别中将文本数据规范化,在文本数据中查找所有符合规则定义的字符串,虽然方法简单易行,但是识别准确率偏低,P值为45.01%;为此,对模式匹配方式中抽取出的触发词进行触发词扩展,充实原始触发词列表,以期提升触发词识别准确率,此方法较与模式匹配方式有所改进,局限在识别思路同样基于规则匹配,触发词识别准确率对比模式匹配方法实验结果略有提升,P值为51.84%。以上两种方式仅关注于触发词本身特征,在识别准确率上均较低;文中结合机器学习和模式匹配方法形成融合模型,融入语义特征识别触发词并进行多分类,触发词识别准确率较前两种方法有所提高,P值为56.72%,实验结果表明,基于P- Multi模型的触发词识别较传统扩展触发词表的识别方法准确率、召回率和F值均有所提高,通过实验证明了文中触发词识别方法的有效性。
本文的工作在语料库处理和机器学习模型训练方面做了初步改进,语料库处理不仅要注重触发词本身还需要融合其他特征对触发词进行学习、训练,并对测试集中触发词进行抽取识别,实验结果基本令人满意。但是实验方法仍然有待改善,一方面,语料库选取着重针对突发事件,选取面并不广泛;另一方面,触发词识别和权重计算过程中涉及的权重因子对实验结果也具有一定影响,特别是融合模型中容易造成级联误差,影响模型性能。下一步研究工作是选取合适方法对微博数据进行噪声过滤,保证高质量数据。同时,尝试采用多种机器学习模型进行对比实验,减少实验误差,进一步改善触发词识别模型。
5 结语
微博作为用户关系信息分享平台,逐渐成为突发事件传播的主要载体,对于曾经发生过突发事件的舆情爆发,应该予以重视[30]。文中通过对语料库进行数据统计分析,并采用融合模型训练的方法对微博文本数据进行了触发词识别,以此来及时发现微博中的突发事件,为舆情指导提供相应理论支撑,实验结果还有待提升。在下一步的工作中会对触发词的精准识别和事件要素抽取等问题进行更加深入研究,以期找到一种能融合触发词识别和事件要素抽取的快速寻优方法来改善模型。
猜你喜欢
英语世界(2021年13期)2021-01-12 05:47:51
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
电子制作(2019年13期)2020-01-14 03:15:32
移动信息(2018年1期)2018-12-28 18:22:52
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:38
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
国家图书馆学刊(2016年2期)2016-10-09 06:19:31
山东工业技术(2015年21期)2015-07-27 08:18:10
语言与翻译(2015年4期)2015-07-18 11:07:45
图书馆建设(2012年3期)2012-10-23 05:16:30
