
基于改进空洞卷积神经网络的丘陵山区田间道路场景识别
2019-05-21 07:17李云伍徐俊杰刘得雄
农业工程学报 2019年7期
李云伍,徐俊杰,刘得雄,于 尧
(1. 西南大学工程技术学院,重庆 400716;2. 丘陵山区农业装备重庆市重点实验室,重庆 400716;3. 贵州省山地农业机械研究所,贵阳 550002)
0 引 言
丘陵山区占中国国土面积的 70%左右,是中国粮油糖作物及薯类、果桑茶麻、蔬菜、青饲料等特色经济作物的重要生产基地[1]。农村劳动力的缺乏以及生产率提升的迫切需求,使得丘陵山区亟需各种自动化程度高、安全性好的智能农业机械。机器视觉系统是智能农机搭载的主要环境感知装备之一,其主要任务是完成对可行驶区域、障碍物或作物的检测。丘陵山区田间道路场景复杂,道路宽度不一、曲率变化大、形态复杂,路内路边杂草泥土等障碍物散布,给智能农机的自主导航与避障带来较大的困难。因此,针对丘陵山区田间道路的复杂场景识别研究变得尤为重要。
根据识别的内容和范围,基于图像处理的道路场景识别可分为低层次的道路识别和高层次的道路场景理解[2]。道路识别一般采用图像分割法将道路区域和非道路区域区分开。道路场景理解则是在像素级对场景中检测到的各类对象进行语义分割,能够更精确地识别出道路区域及周围的环境对象,为自主导航和避障提供支持。在道路场景识别方法中,深度学习具有精准性高、鲁棒性强等优点,成为道路场景识别的重要发展方向[3]。
近年来在道路场景理解研究中,Oliveira等[4]使用卷积神经网络(convolutional neural networks,CNN)算法学习场景中的高阶特征进行单目道路场景分割,通过应用在一个普通图像数据集上的训练算法对其他测试图像进行分类,生成训练标签;然后使用基于颜色层融合的新纹理描述子来获取道路区域的最大一致性;最后将离线和在线信息结合起来对城市道路区域进行检测。Coombes等[5]提出基于HSV(hue saturation value)色彩空间的语义分割算法,使用CNN来分割解释场景,通过训练基于颜色的贝叶斯网络分类器对每个分割的聚类进行语义分类,利用亮度特征识别飞机场滑行道上的表面线,然后与 CNN分割相融合,给出改进的分类结果。Wang等[6]提出一种利用相对位置先验信息和语义分割相联合的方法来估计城市道路布局和分割城市场景。Cordts等[7]和Zhang等[8]利用多传感器信息融合技术提高城市交通道路场景理解的准确性。Chen等[9]提出了一种基于视差建议的检测方法,在立体视差的基础上快速提取检测对象的候选帧,保证了候选帧在不同扰动下的鲁棒性。
上述文献的场景理解方法基本上是为解决特定结构化场景下的智能导航问题而提出,具有特定的功能,仅适用于特定的环境。由于基于卷积神经网络的深度学习能够自动学习图像的层级特征,在物体识别和像素标注上表现出优秀性能,因此成为图像语义分割的重要方法之一。轩永仓[10]将大田场景对象分为 7类,采用基于全卷积神经网络 VGG-16结构的 FCN-32s、FCN-16s和FCN-8s 3种模型进行语义分割,测试结果表明 FCN-8s的总体效果最好,在大田应用场景下的统计像素准确率可达90.87%。该模型应用场景为平原大田环境,图像较为简单,训练集分辨率为 256×256像素,对分割的细节要求不高。张利刚[11]将VGG-16中的18层卷积层和池化层均改为空洞卷积层和空洞池化层,构建了全空洞卷积神经网络,使用该网络在MIT Scene Parsing Dataset下训练测试,统计像素准确率达到 72.81%,比 FCN-8s高1.49%。该方法未保留池化层,网络采用了大量膨胀信息,对一些大物体有较好分割效果,但对小物体的分割不够准确,边缘也较模糊。
本文针对丘陵山区田间道路无车道线、边界模糊、环境复杂多变等特点,利用全卷积神经网络 VGG-16结构,融合空洞卷积构造预测精度更高的前端模块,并利用不同膨胀系数空洞卷积层的级联进行多尺度上下文聚合,构建了基于改进空洞卷积神经网络的田间道路场景识别模型,对复杂非结构化田间道路图像进行语义分割,以获取道路的可行区域和障碍物等信息,为后续丘陵山区智能农机的自主导航奠定基础。
1 丘陵山区田间道路场景对象分类
道路一般分为结构化道路和非结构化道路[12]。目前针对结构化道路的图像识别技术相对成熟。非结构化道路一般指无车道线和无明显边界的非主干道或乡村道路。对非结构化道路的准确识别是当前道路环境感知的主要研究内容之一[13]。
随着丘陵山区农田整治与农田基础设施建设的推进,田间、居民点、仓库之间普遍建立起0.8~1.2 m宽的田间便道[14](如图1所示)。

图1 丘陵山区田间道路场景图像语义分割实例Fig.1 Example of semantic segmentation of field road scene in hilly areas
这些道路属于典型的非结构化道路,主要特点包括:1)道路形状变化多样,蜿蜒曲折,坡度大;2)路况复杂,道路两旁多为不同类型的作物和杂草,道路边缘多被杂草和作物枝叶覆盖,路面上的阴影千差万别;3)路面状况受季节和天气的影响较大,不同季节和天气情况下道路的颜色和纹理特征差异较大。这些复杂的场景特征为田间道路及道路上障碍物的识别带来较大困难。因此,要实现智能农机在田间道路上基于机器视觉的自主导航,需通过多重处理区分出田间道路、周围环境,以及道路上的物体。
本文根据田间道路环境特征以及自主导航的需要,将田间道路图像中的对象分为11种类别,分别是“背景、道路、行人、植被、天空、建筑、牲畜、障碍、池塘、土壤和杆”,其定义见表1。对“道路、土壤、植被、建筑、池塘”分类的目的在于实现后续自主导航的局部路径规划;对“行人、牲畜、障碍”分类是便于后续自主行驶中的自动避障;对“杆”分类是便于后期对路牌和标志牌的识别。

表1 丘陵山区田间道路场景对象分类Table 1 Classification of field road scene objects in hilly areas
2 图像样本数据集建立
2.1 数据集获取
本文田间道路场景图像语义分割的主要目的是实现智能农机在田间道路上的自主导航与避障,因此以前期研制的自主行驶田间道路搬运车[1]为图像采集平台,以获取真实的行驶过程中的道路图像。如图 2所示,该搬运车整车尺寸1 130 mm×530 mm×822 mm(长×宽×高),轮距450 mm,轴距760 mm。图像采集模块为RER-720P高清摄像头,最高分辨率为1280×720像素。摄像头离地高度800 mm,光轴中心与地面夹角15°。搬运车以2 m/s的速度行驶,摄像头采集道路场景真实视频数据后存储于笔记本电脑中,再剪辑选取帧图像。
为提高构建的场景理解模型算法的鲁棒性,使其适应多种环境特征,依据田间实际情况和自然光照,在多种复杂条件下进行图像采集。采集过程中道路上存在大量阴影遮挡的情况。

图2 田间道路搬运车采集图像Fig.2 Image acquisition by field road carrier
图像采集地点为重庆市北碚区内的丘陵山区田间道路。将采集后的视频图像进行分析,提取多个场景和环境条件的1 000张帧图像作为数据集进行后续处理。为降低对计算机显存的需求,将采集到的图像像素全部缩放为512×512像素。
2.2 数据集预处理
为了获得精确的语义分割数据集,并有效地提升数据质量、增加数据特征多样性,对采集的田间道路图像集进行预处理,包括数据标注、数据增强及均值处理 3个步骤。
卷积神经网络需要进行有监督的训练。采集的帧图像本身没有标签和语义,必须进行人工分割和标注,然后图片才能用于训练[10]。使用Adobe Photoshop CC 2018工具对数据集进行手动分割。在缩放后的图片中,对 11种对象类别进行手动标注,每种类别标注的 RGB(red-green-blue)3通道值如表2所示。
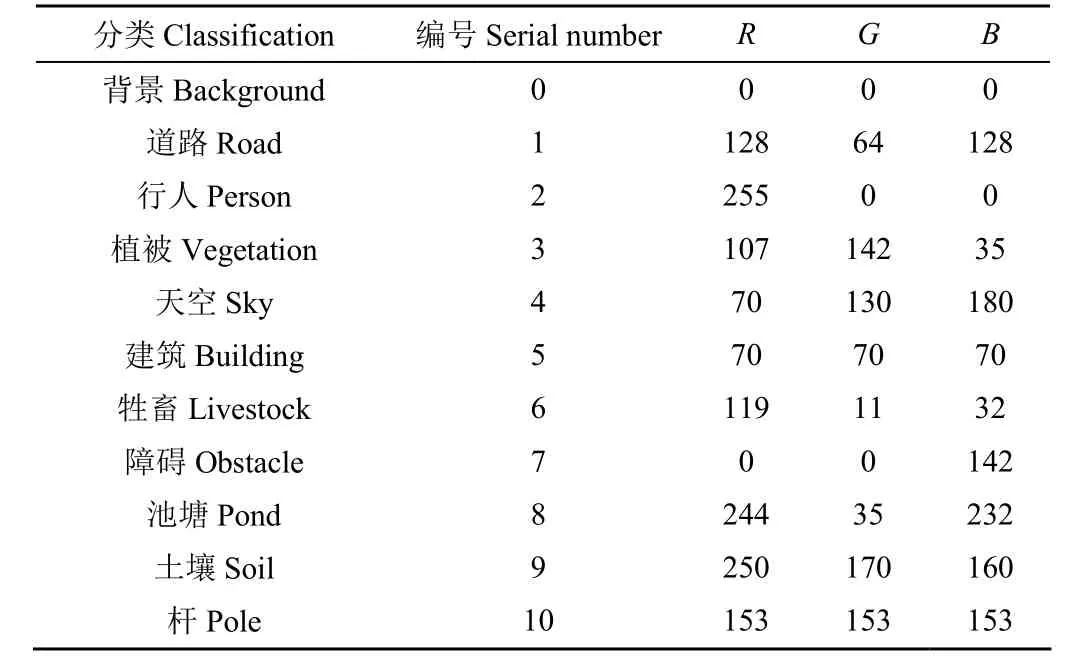
表2 丘陵山区田间道路场景对象的标注颜色Table 2 Marked color of field road scene objects in hilly areas
数据增强参考文献[10]提供的方法,对缩放后的图片集以及人工语义分割后的图片进行水平和垂直翻转,然后将图片沿水平方向移动48个像素位置。采用这3种方式,每种方式可扩充 2倍的数据量,由此将训练集数据扩充为原始数据集的8倍。
数据集均值处理,具体步骤是先计算数据集所有图像在同一个位置上像素点对应的RGB三通道均值,再将所有图像对应位置的RGB通道值减去相应的均值。采取此处理,能够让输入样本的各通道数据中心化,减少噪声值的干扰,加快模型的收敛。
经过上述 3种方式处理之后,按照“训练集∶测试集=4∶1”的比例[15],将图像样本数据集分成训练集和测试集,选取训练集图像1 600张、测试集图像400张进行模型训练和对比试验。
3 田间道路场景理解模型构建
Long等[16]提出的全卷积神经网络(fully convolutional networks,FCN)模型,使得卷积神经网络无需全连接层即可进行密集的像素预测,可生成任意大小的图像分割图,且运算速度比图像块分类法要快。FCN可以基于若干种结构(AlextNet、VGG-Net、GoogLeNet、SIFT-Flow、VGG-16等),其中VGG-16被广泛认为是效果最好的一种结构[16]。可是,FCN是在传统CNN上进行的改编,CNN最初是设计成用于图像分类的人工神经网络,而语义分割属于像素预测(dense prediction)问题,在结构上不同于图像分类问题。在相同计算条件下,空洞卷积(dilated convolutional networks,DCN)能提供更大的感受野,经常用在实时图像分割中。基于此,本文融合全卷积及空洞卷积的优点,构建了基于空洞卷积神经网络的田间道路场景图像语义分割模型。
3.1 空洞卷积
空洞卷积(convolution with holes),是一种特征图上数据采样的方式,可以在不损失分辨率或覆盖率的情况下增大感受野。感受野为网络每一层输出的特征图上的像素点在原始图像上映射的区域大小,感受野21ir+的计算式如下

式中ri表示第i层的感受野边长,l表示空洞卷积的膨胀系数。
空洞卷积与普通卷积的卷积核大小一样[17-18],在神经网络中即参数量不变,但它具有更大的感受野。二维空间上的空洞卷积可定义如下[19]
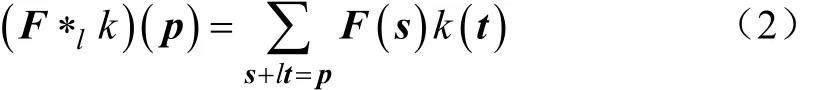
式中*l为空洞卷积,p是其定义域;F是输入图像,s是其定义域;k是核函数,t是其定义域。与普通的卷积相比,空洞卷积的条件从s + t = p变成了s+lt=p,即每次卷积核仅与图像F中l倍数位置的元素运算。当l=1时,*即为普通的离散卷积操作。
全卷积神经网络通过池化层下采样降低图像尺寸的同时增大感受野,然后使用上采样将图像变回原大小,此过程中导致了图像信息丢失,而空洞卷积在一定程度上可以避免此问题。图 3展示了空洞卷积与感受野之间的关系,其感受野呈指数级增长。
在图3中,卷积核均为3×3。图3a采用l=1的空洞卷积(即普通卷积)对原图操作得到第1层特征图,第1层中各元素代表的信息是原图 3×3元素的信息,即感受野为3×3。图3b采用l=2的空洞卷积对第1层操作得到第2层特征图,由于膨胀系数为2,实际上卷积核分布为图中圆点位置,第 2层中各元素相对于原图的感受野为7×7。图 3c采用l=4的空洞卷积对第 2层操作得到第 3层特征图,同理第3层中各元素的感受野为15×15。

图3 空洞卷积带来的感受野增长Fig.3 Expansion of receptive field due to dilated convolution
对比于传统卷积的3层3×3卷积核联立只能获得7×7的感受野,空洞卷积实际参与卷积的因子数量没有变,卷积的计算量没有变,但是卷积核的尺寸变大,使得特征图中一个特征值对应原来更大的区域,也就是可以获得更大的感受范围。
3.2 基于空洞卷积的上下文聚合及前端模块
近年来卷积神经网络研究中,Long等[16]分析过滤波器的扩张但是并未进行应用。Chen等[20]用空洞来简化Long等提出的全卷积神经网络结构。而Yu等[21]2016年提出采用空洞卷积的上下文模块(context module),系统地使用空洞卷积来进行多尺度上下文聚合,旨在通过聚合上下文信息来提高像素预测体系结构的性能。该模块的输入和输出都是C个通道特征图(C可以表示图像中的对象分类数),输入输出的形式相同,因此可以将该模块插入到现有的像素预测网络中,但它不具备完整的预测网络功能,需要一个前端网络为其提供特征图作为输入,即前端模块(front-end module)。
1)上下文模块
Yu等[21]提出的上下文模块共8层。前7层都采用具有不同膨胀系数的3×3卷积核进行空洞卷积;膨胀系数l在各层中呈指数增大,以使用小感知区域的卷积核先获取局部特征,再用大感知区域的卷积核把特征分到更多区域中。各卷积操作后,接着是逐元素截断操作max(·,0),以裁剪空洞卷积造成的扩大边缘。最后一层执行 1×1×C的卷积并产生模块的输出。上下文模块根据卷积的通道不同又分为Basic和Large 2种网络形式。
卷积神经网络通常用随机分布样本进行初始化[22]。然而,试验表明标准的随机初始化方案并不能提高上下文模型的预测精度,使用明确语义的替代初始化形式更加有效[21]。
Basic网络采用的初始化方案为

式中a是输入特征图的索引,b是输出特征图的索引。该初始化方案设置所有滤波器直接将每层的输入传递给下一层[25],试验表明其反向传播能可靠地获取网络的上下文信息,提高处理后的特征图的精度。
Large网络与Basic网络的区别在于在较深的层中使用更多的特征图。Large网络也需要更改初始化方案来解决不同层特征图数量差异的问题,其方法是:设ci和ci+1为2个连续层的特征图数量,将C同时除以ci和ci+1,具体可表示为

式中ε~N(0, σ2)且 σ<<C/ci+1。
2)前端模块
前端模块又称前端预测模块(front-end prediction module),其作用是产生一定分辨率的特征图提供给上下文模块。前端模块源自Long等[16]和Chen等[20]的研究,Long等保留了传统分类网络中的最后两个 pooling和striding层,Chen等使用扩张代替striding层并保留pooling层,而 Yu等[21]发现通过移除 VGG-16网络最后两个pooling层来简化网络可以提高预测精度。本文采用 Yu等修改之后的前端模块。
3.3 基于空洞卷积的语义分割模型的构建
根据前述空洞卷积网络的特征,本文利用全卷积神经网络 VGG-16结构,融合空洞卷积构造预测精度更高的前端模块,利用不同膨胀系数空洞卷积层的级联进行多尺度上下文聚合,由此构建的田间道路场景图像语义分割模型如图4所示。图中final层之前的部分即为前端模块,之后的部分为上下文模块。前端模块将一幅彩色图像作为输入,生成C=11个特征图作为输出。上下文模块则对前端模块输出的特征图作进一步预测。
为简化计算和提高预测精度,前端模块在 VGG-16的基础上改进,具体构建方法为:将VGG-16中的pooling4和pooling5层移除,且将Conv5中的3个卷积层改为膨胀系数为2的空洞卷积,fc6层的卷积改为膨胀系数为4的空洞卷积,以保持感受野不变。另外,VGG-16中间特征图的padding操作,其功用是配合pooling层进行下采样,适用于传统的分类网络,但操作中可能会引入噪声,这在像素预测中既不必要也不合理,因此,删除了padding操作。
构建的上下文模块则为不同膨胀系数空洞卷积层的级联,各层的具体结构参数如表3所示,包括final输出层在内共8层,前6层是膨胀系数分别为1、1、2、4、8和16的空洞卷积。由于原图经过前端模块前面层下采样后分辨率变成 64×64像素,因此在上下文模块设计中停止了第六层之后感受野的指数扩张,第7、8层的感受野为67×67。为便于对比,根据输出特征图通道数量不同设计了Basic和Large 2种网络形式。
以上修改使得能够利用传统 VGG-16网络进行参数的初始化,并可产生更高分辨率的输出。由此构建的空洞卷积神经网络即为田间道路场景图像语义分割模型。
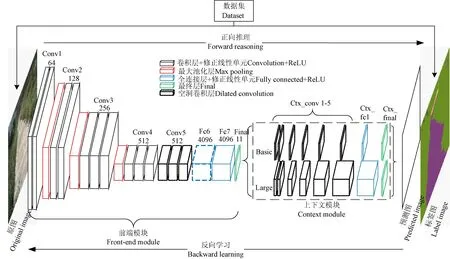
图4 基于空洞卷积神经网络的田间道路场景图像语义分割模型Fig.4 Dilated convolutional networks (DCN) architecture for semantic segmentation of field road images

表3 上下文模块网络结构参数Table 3 Architecture parameters of context module network
3.4 模型的搭建与训练
依托深度学习框架快速特征嵌入的卷积结构(convolutional architecture for fast feature embedding,CAFFE)[27]搭建基于空洞卷积的田间道路场景图像语义分割模型。CAFFE中使用 deploy.prototxt进行空洞卷积算法的定义,solver.prototxt对训练参数进行设置,solve.py进行网络的训练,infer.py调用模型生成语义分割的结果。本文试验硬件环境为英特尔 Core i7-6700HQ@2.60GHz四核八线程处理器,16 GB内存,显存为6GB的Nvidia GeForce GTX 1060显卡。
随着层数的不断加深,DCN识别模型的精度也在不断提高,但也带来了模型易陷入局部最小值的问题[28]。因此,在实际的深度网络模型训练中,一些学者普遍采用上一个较好的收敛模型的参数来初始化新模型的初始参数,SSD(Single Shot Multibox Detector)[29]、DeepID[30]等现有的卷积神经网络模型都采取了预训练的策略。
本文参考轩永仓[10]和Bengio等[28]的思路,采用预训练初始化参数的同时,对模型采用了两阶段训练(two-stage training)[31]的方法。具体步骤是:
1)使用ImageNet上训练好的VGG-16模型参数初始化需要训练的DCNN网络。
2)人工选取一些特征明显、包含对象类别少的简单图像 500张先单独对模型进行训练。经过多次试验,确定权值参数的学习率为 10-4,mini-batch size为 14,momentum为0.9,weight decay为0.000 5,采用随机梯度下降法进行训练,等到模型收敛之后,将模型参数保存。由于图像简单,模型收敛速度快。
3)在全部训练集上对上一步保存的模型进行再次训练,利用上一步中所得到的参数来初始化模型,减小学习率为10-5,通过训练更新所有的网络权值和参数。
4 田间道路图像语义分割试验
4.1 试验设计
为验证构建的基于空洞卷积神经网络的丘陵山区田间道路图像语义分割模型的效果,对实际道路场景的语义分割进行了测试。
1)模型改进效果测试
首先测试前端模块,只采用本文构建的前端模块(下文简称为Front-end)进行训练和测试,验证对于VGG-16的修改是否有效。
然后测试上下文模块与前端模块的组合,分别将构建的Basic和Large 2种结构的上下文模块插入前端模块(下文分别简称为Front-end + Basic和Front-end + Large),设置学习率为10-5,迭代次数4 000,对上下文模块进行初始化。由于上下文网络的感受野为67×67,因此使用宽度为33的缓冲区来填充输入特征图。
网络模型都采用两阶段训练方法进行训练。在各网络模型的测试过程中,图像的读取操作通过调用 Python第三方库函数实现。
2)不同模型对比试验
测试文献[10]中效果最好FCN-8s模型,用以对比本文构建的语义分割模型的预测精度。采用CAFFE提供的基于VGG-16的FCN-8s模型进行训练,训练策略与参数设置和前端模块相同。
3)阴影道路对比测试
针对田间道路上阴影突出的问题,测试 Front-end +Large网络模型对阴影道路的语义分割效果。在测试集中选取了100张道路被阴影明显覆盖的图片、100张路面无阴影的图片,分别应用Front-end + Large进行语义分割测试,对比2种情况下的语义分割效果。
4)导航线提取精度测试
田间道路图像语义分割的主要应用之一就是提取道路上的导航线。采用文献[1]和文献[14]中对二值化道路图像提取导航线的方法对本文语义分割后的图像提取导航线,具体方法是:1)采用Front-end + Large模型对田间道路图像进行语义分割;2)语义分割识别出道路区域后,对道路区域分块求解形心点;3)对这些形心点采用最小二乘法进行拟合得到道路的虚拟中线,此虚拟中线即为智能农机在田间道路上自主行驶的局部路径导航线。为验证本文构建的语义分割模型对田间道路识别的实际效果,测试了此虚拟中线与田间道路实际中线的偏差。偏差求取方法是:将获取的虚拟中线通过相机标定将其像素坐标转换为实际平面坐标,沿纵向方向等距离取点计算其横向坐标值与实测的道路中线上对应点横向坐标值的相对偏差。选取与文献[1]和文献[14]所选道路类似的普通水泥路、小障碍物遮挡道路以及杂草、水渍等覆盖道路等3种田间道路进行测试。
4.2 语义分割评判指标
将网络模型分割的结果与人工标注图像(采用Adobe Photoshop CC 2018)进行比较以分析各网络模型语义分割的精度。把人工标注结果视为真实图像分割结果,以此为标准,通过统计各网络模型语义分割像素误差来评判模型分割效果。使用目前普遍采用的评价标准进行评判[32]。
假设njm表示属于j类语义而被识别为m类的像素点个数;N表示语义类别总数,本文N=11,评判指标定义如下:
1)类别像素准确率wj:属于j类语义且被正确分割为j类的第j类像素准确率为

2)统计像素准确率PA(pixel accuracy):标记正确的像素占总像素的比例,计算式为

3)类别平均准确率MPA(mean pixel accuracy):计算每个类被正确分类像素数的比例,然后求取所有类的平均值,计算式为

4)平均区域重合度 MIoU(mean intersection over union):预测像素正确的交集除以预测像素与原来像素的并集。具体计算过程为在每个类上计算区域重合度,然后求取所有类的平均值,计算式为

以上度量标准中,像素准确率反映了在图像中具体类别被正确分割的概率,而MIoU由于简洁、代表性强而成为最常用的度量标准。
4.3 试验结果与分析
4.3.1 模型改进效果测试
网络模型进行训练时,每迭代500次保存一次模型,分别选取损失函数值最低、MIoU最高时的模型进行测试。表4为4种网络模型对测试集丘陵山区田间道路场景中每类对象的分割结果。

表4 改进网络模型语义分割效果Table 4 Effect of semantic segmentation by improve networks model
从表4中可知,在具体类别的识别方面,4种网络模型对“背景”及“道路”的识别像素准确率都最高,而对“杆”的识别像素准确率都最低,对“行人”的识别像素准确率也较低。这是因为,“背景”和“道路”之间的特征差异比较明显;而远处的“行人”和“杆”相对其他对象来说通常较小,图像经预处理后分辨率较低,低分辨率下小的对象容易失去形状和颜色特征信息。
比较4种网络模型,除对“土壤”外,Front-end+Large对其他类别的识别像素准确率都最高;Front-end对于“土壤”的识别像素准确率最高;FCN-8s对所有类别的识别像素准确率都是最低。总体效果最好的Front-end + Large对“背景”及“道路”的识别像素准确率最高,分别达到93%和91.3%;而对“杆”的识别像素准确率最低,只有79.0%。
从表4还可知,4种网络模型相比较,在统计像素准确率 PA、类别平均准确率 MPA以及平均区域重合度MIoU评价指标上,Front-end+Large都是最高,分别达到88.5%、86.0%和 74.2%。测试结果表明,本文构建的Front-end + Large模型对丘陵山区田间道路对象类别具有良好的适应性和较高的识别准确率。
图5所示为4种网络模型对田间道路图像语义分割的效果。

图5 不同网络模型产生的语义分割结果Fig.5 Semantic segmentation results produced by different network models
总体上看,FCN-8s的语义分割效果最差,Front-end +Large效果最好。这主要有两方面的原因:1)FCN-8s的上采样结构为第3层8倍放大,在FCN中进行放大还原时,较浅的卷积层感受野比较小,学习感知细节部分的能力较强,但是在丘陵山区田间道路复杂场景下,“植被”、“土壤”和“建筑”等的像素区域总是交叉覆盖,对象之间的特征差异并不明显,其感知细节的能力没有发挥作用;2)构建的前端模块相对于FCN-8s具有很大的提升,插入 Large 上下文模块后,增大了感受野,聚合了上下文信息,对于田间道路复杂场景具有更好的区块化分割效果。另一方面,在某些场景下,相比Front-end和 Front-end+Basic,Front-end+Large会丢失一些细节上的信息,如图5第3行场景中的“土壤”对象,大范围地被识别为“植被”。其主要原因在于Large结构上下文模块在更深层(靠后的)中采用了更多的特征图,虽然进一步增加了感受野,但是细节(边缘)会更加粗糙,也容易丢失一些交叉覆盖区域(如“植被”和“土壤”)的细节信息。此外,田间“土壤”形状、大小、颜色等特征变化多样也是其易被识别错误的重要原因。
综上所述,本文基于 VGG-16构建的前端模块有效地提高了田间道路图像语义分割的精度,而与上下文模块的结合进一步增加了识别准确率,但是过大的感受野不利于小物体的分割。Front-end + Large总体上的语义分割比Front-end + Basic更为准确和完整。所以,本文选取表现最好的Front-end + Large网络结构作为田间道路场景图像语义分割模型。
4.3.2 不同模型对比试验分析
表5为文献[10] FCN-8s对大田环境、文献[11]全空洞卷积神经网络对MIT Scene Parsing Dataset测试集、FCN-8s以及本文构建的Front-end+large对丘陵田间道路场景的测试效果对比。
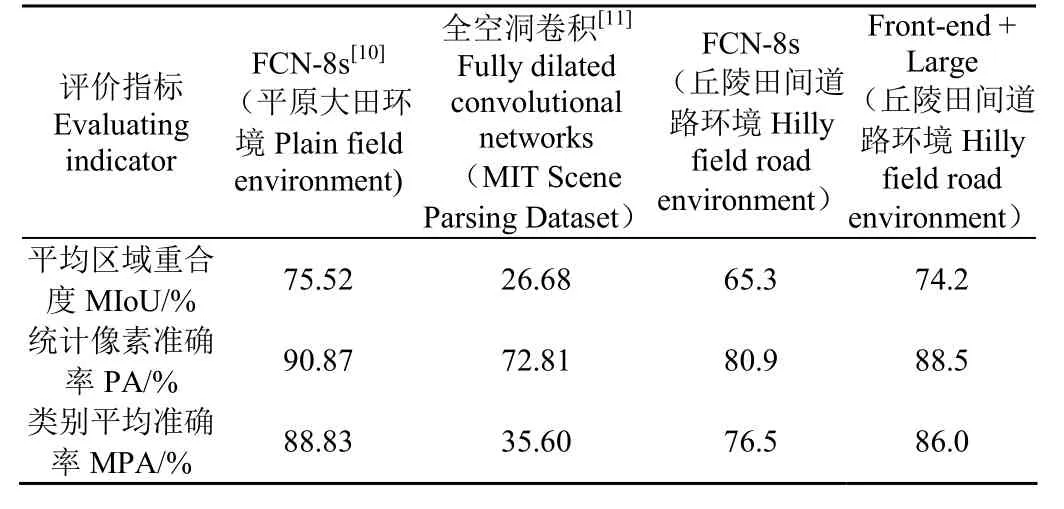
表5 不同场景下各种网络模型测试效果对比Table 5 Comparison of test results of various network models under different scenes
文献[10]采用传统全卷积网络的 FCN-32s、FCN-16s和FCN-8s这3种不同的网络结构,针对大田平原场景进行训练和对比测试,结果显示效果最好的FCN-8s的PA、MPA以及MIoU分别为90.87%、88.83%和75.52%。文献[11]基于传统FCN进行改进,将FCN-VGG16结构中原有的卷积层和池化层全部改为空洞卷积层和空洞池化层,针对MIT Scene Parsing Dataset进行训练,测试结果显示 PA、MPA以及 MIoU分别为 72.81%、35.60%和26.68%。
本文将文献[10]中效果最好的FCN-8s针对丘陵山区田间道路场景的数据集进行了训练和测试,结果FCN-8s在本文测试的4种网络中的PA、MPA以及MIoU都是最低,分别为 80.9%、76.5%和 65.3%。表 5可以看出,Front-end+Large测试结果既优于FCN-8s,也优于文献[11]提出的全空洞卷积网络的测试结果,表明本文构建的Front-end+Large模型对丘陵山区田间道路对象类别具有更好的识别效果。
4.3.3 不同阴影覆盖下的试验结果
Front-end + Large网络模型对有阴影道路测试集以及无阴影道路测试集的语义分割结果如表 6所示,分割效果如图6所示。
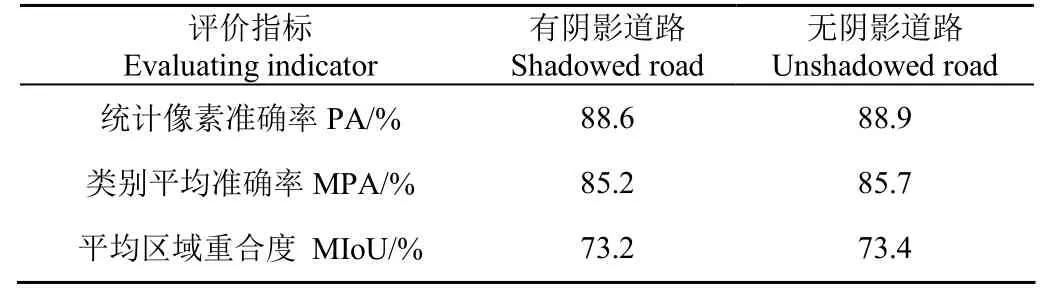
表6 有阴影和无阴影道路的测试结果Table 6 Test results of shadowed and unshadowed roads

图6 Front-end+Large网络模型对有阴影和无阴影道路图像的分割效果Fig.6 Front-end + Large network's image segmentation results for shadowed and unshadowed roads
卷积神经网络对几何变换、形变、光照具有一定程度的不变性,这是被许多学者所认同的。由表 6中可以看出,基于Front-end + Large构建的田间道路复杂场景图像语义分割模型,其 MIoU在无阴影道路测试集上为73.4%,在有阴影道路测试集上为 73.2%,仅减少了 0.2个百分点;而且两种测试集的PA和MPA也仅分别相差0.3和0.5个百分点。丘陵山区田间道路上由于树木、作物等遮挡产生阴影的现象普遍存在,而本文构建的语义分割模型对田间道路的识别准确率基本上不受阴影的影响,说明该模型对阴影干扰有良好的适应性。
4.3.4 导航线提取测试结果
表 7为普通水泥路、小障碍物遮挡道路以及杂草、水渍覆盖道路 3种田间道路提取的导航线与道路实际中线的偏差(5个采样点)。测试表明,3种道路提取的导航线与实际道路中线的最大偏差分别为2.16%、3.39%和3.61%,均低于文献[1]和文献[14]所得到的5%最大偏差。上述文献采用图像颜色特征进行阈值分割和处理识别出田间道路区域,然后提取道路区域的导航线。测试结果说明本文构建的语义分割模型对田间道路的识别准确率更高,能满足智能农机在田间道路上自主导航对田间道路的识别精度要求。

表7 导航线提取相对偏差Table 7 Relative errors of navigation centerlines extraction
5 结 论
针对丘陵山区田间道路图像特征,将道路场景对象分为11类,构建了基于改进空洞卷积神经网络的丘陵山区田间道路场景图像语义分割模型。
1)构建的空洞卷积神经网络语义分割模型,包括前端模块和上下文模块。前端模块为 VGG-16融合空洞卷积的改进结构,上下文模块为不同膨胀系数空洞卷积层的级联。该模型能够利用传统 VGG-16网络进行参数的初始化,可产生更高分辨率的输出。
2)对 FCN-8s、Front-end、Front-end +Basic、Front-end+Large 4种网络模型进行了对比测试。在统计像素准确率、类别平均准确率以及平均区域重合度评价指标上,Front-end+Large最高,FCN-8s最低,可采用Front-end+Large网络模型作为田间道路场景的语义分割模型。
3)验证了构建的Front-end + Large网络对不同阴影道路图像的适应性,其 MIoU在无阴影道路训练集上为73.4%,在有阴影道路训练集上为 73.2%,仅减少了 0.2个百分点,而且对两种训练集的PA和MPA仅分别相差0.3和0.5个百分点。该模型对于丘陵山区田间道路场景的阴影干扰有良好的适应性。
本文构建的语义分割模型实现了对田间道路及道路上障碍物的较准确的识别,能满足智能农机在田间道路自主导航的场景对象识别精度要求。下一步将通过增大训练样本量、减小分类数、后处理优化等方法进一步提高模型识别的精度,为更好地获取田间道路场景对象的深度信息奠定基础。
猜你喜欢
今日农业(2022年14期)2022-09-15
北京航空航天大学学报(2022年8期)2022-08-31
今日农业(2021年8期)2021-11-28
今日农业(2021年11期)2021-11-27
今日农业(2021年2期)2021-03-19
金桥(2020年9期)2020-10-27
学生天地(2020年18期)2020-08-25
故事作文·高年级(2017年2期)2017-03-01
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
