
一种云平台下的大数据聚类系统研究
2019-05-20 06:06:24严志
长沙民政职业技术学院学报 2019年1期
严 志
(长沙民政职业技术学院软件学院,湖南长沙410004)
1. 引言
随着云计算技术的不断发展,大数据内含的价值逐渐被人们正视。淘宝大数据系统[1]会统计用户页面级的点击量来分析热门产品,将最受欢迎的产品推荐给用户,并且能够根据用户年龄、历史消费记录向用户推荐其他产品。农夫山泉公司利用大数据系统分析矿泉水的销售[2],这些数据分析体现在如何在终端摆放产品、产品购买者的年龄、消费者消费停留时间、购买数量等,系统甚至还将物流数据也纳入评价范围,通过数据精准分析使产品利润达到最大。Wal-Mart应用大数据分析系统Polaris研究用户的消费行为,该系统利用 Deep learning、Semantic data、Machine learning等方式对用户输入关键词进行文本分析,深度挖掘用户所需商品并支持个性化推荐。社交巨头Facebook公司利用用户在平台上留下的历史数据进行大数据计算,能够判断出用户的财务状况、教育水平,使得用户个人数据能够被一览无余。
目前工业界各大厂商如Amazon、IBM、Google、Microsoft、Sun、阿里巴巴等公司都推出自己的大数据系统,越来越多的学者推出了大数据在行业领域内的应用。孟超、金龙、孙知信[3]运用无线传感网络技术,设计构建了一个传感网结点实时定位跟踪的大数据传输模型;荆旭全、蔡德楠等开发精准施肥大数据系统及相应的信息服务应用平台,集施肥决策、农技推广、施肥数据可视化于一体[4];徐超、吴波提出了以最小化系列跨域作业平均完成时间为优化目标的在线随机调度算法处理跨域大数据带来的作业完成时延[5];行艳妮、钱育蓉等分析了内存计算框架Spark和K-means聚类算法,分析了K-means算法聚类不稳定性的因素,提出优化K-means算法方法[6];王静宇等提出了基于数据敏感性Hadoop大数据访问控制模型,模型利用数据内容、使用模式和数据敏感性来强化访问控制策略,在评估数据敏感性上用户干预最小[7]。赵帅对大数据知识服务模式进行分析,以图书馆用户信息作为研究调查对象,并对平台中关键技术进行探索[8]。杨正理、史文等利用海量招生异构数据,采用并行化随机森林预测高校招生策略模型,缩短了模型的预测时间、提高了模型的预测精度[9]。
本文以某招聘网站数据作为数据源,通过爬取网页关键数据,然后将数据保存到云平台,接着对数据进行清洗、聚类,最后使用可视化工具将分析结果呈现出来。通过大数据系统分析,可以得到某个地区的薪资水平、岗位分布、学历要求、工作行业性质等数据,为企业精准人才需求、技能要求提供了可靠的服务。
2. 数据聚类算法
大数据体量巨大,数据价值密度低,聚类分析是将数据样本划分为若干个不相交的子集,每一个子集称为一个簇。一般是用来对数据按照特征属性进行分组,经常被应用在客户分群、欺诈检测、图像分析等领域。
K-means是最典型的聚类算法,其主要思想是:给定K值和K个初始类簇中心点,计算数据节点到所有类簇中心点的欧式距离,把每个数据节点加入到类簇中心点距离最小的类簇中,直到所有数据节点分配完毕,再次计算类簇中所有数据节点到各类簇中心的距离,取距离的均值重新计算该类簇的中心点,然后所有数据节点再次进行聚类迭代分配并更新类簇中心点的,直至类簇中心点的变化很小,或者达到指定的迭代次数。
给定数据样本 D,包含了 n 个对象 D={X1,X2,X3,...,Xn},其中每个对象包含m个维度属性,算法目标是将n个对象依据对象间的相似性聚集到指定的k个类簇中,每个对象仅且属于一个其到类簇中心距离最小的类簇。
k 个类簇定义为 ={C1,C2,C3,...,CK},1≤k≤n,通过计算对象X到C中的每个聚类中心的欧式距离,公式如下:
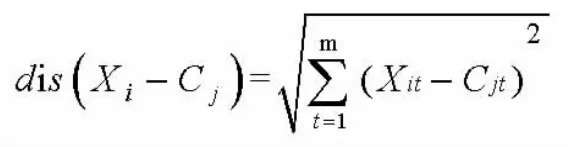
上式中是样本数据对象,1≤i≤n,Cj表示第j个聚类中心,1≤j≤k,Xit表示 Xi对象的第 t个属性,1≤t≤m,Cjt表示第j个聚类中心的第t个属性,依次比较每一个对象到每一个聚类中心的距离,将对象分配到离聚类中心最近的类簇中,得到 k 个类簇{S1,S2,S3,...,Sk}。
K-means算法用类簇中心定义了类簇的原型,类簇中心就是类簇内所有数据对象在各个维度的均值,其计算公式如下:
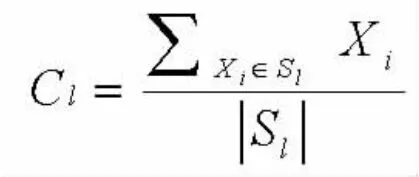
上式中,Cl表示第L个聚类的中心,1≤L≤k,|Sl|表示第L个类簇中对象的个数,Xi表示第l个类簇中的第i个对象,1≤i≤|Sl|
该算法的实现如下[10]:
输入:样本集 D={X1,X2,X3,...,Xn},k 个聚类簇数
过程:
1:从样本集D中随机选择k个样本作为初始向量值{u1,u2,u3,…,uk}
2:repeat
3:令 Ci= φ(1≤i≤n)
4:for j=1,2,3,…,mdo
5:计算样本xj与各均值向量ui(1≤i≤k)的距离,dji=|xj-ui|2;
6:根据距离最近的均值向量确定xj的簇标记:
7:将样本xj划入相应的簇:
8:end for
9:for i=1,2,…,k do
11:if u'i!=uithen
12:将当前向量值ui更新为u'i;
13:else
14:保持当前均值不变
15:end if
16:end for
17:until当前均值向量均未更新
输出:簇划分 C={C1,C2,C3,...,Ck}
3. 系统架构设计
招聘大数据分析系统的主要原理是:利用开源框架解析数据源,将爬取得到的文本数据经过分词算法处理后上传到HDFS,经过MapReaduce处理后存储到云数据库Hbase,然后访问云数据库计算获取元数据,对不规则的数据进行清洗,将清洗后的数据存放到Hbase列簇,清洗列簇数据并对数据进行聚类分析,将聚类结果通过可视化的形式直观展示给用户。系统以Hadoop作为云平台,采用第三方招聘网站作为数据源,得到了如图1的系统的核心架构。

图1 系统架构图
系统自下而上分为数据解析层、数据存储层和数据应用层,每一层的实现细节如下。
数据解析层:数据解析层主要功能是爬取第三方网站的web数据,运用中文分词,xpath解析获取数据源。爬虫核心采用第三方爬虫框架WebMagic,系统架构如图2所示。Downloader通过http请求从互联网上下载页面,交给页面处理对象PageProcesor处理。页面处理对象采用jsoup工具解析页面,通过xpath表达式抽取页面关键信息,如果发现新的链接加入到采集地址队列Scheduler。Scheduler调度管理待抓取的URL,对URL集合来进行去重,Pipeline负责处理抽取结果,将数据持久化到文件、数据库。
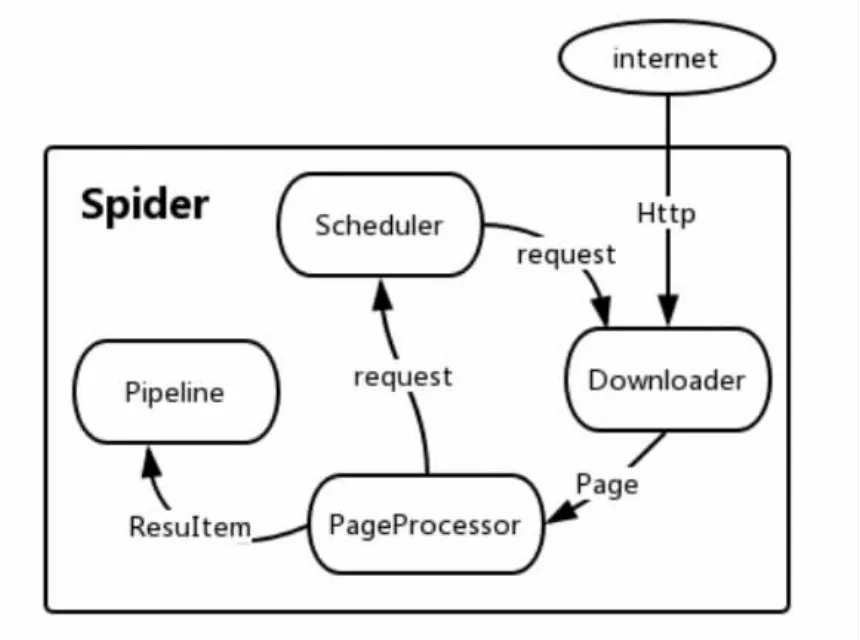
图2 WebMagic架构
数据存储层:WebMagic网络爬虫程序获得数据源之后,将数据保存到云数据库HBase,爬取过程中需要进行中文分词处理,本文使用的中文分词工具是基于Lucence内核的庖丁解牛工具,该工具可实现自定义词典,将特殊词语构建词典保存到项目路径即可。将所得到的数据存入到HDFS文件中,然后对HDFS中的文件进行MapReducer大数据处理,清晰无规则数据,将结构化数据存储到HBase中。为了对数据进行归类整理,找出统计规律再次对清洗的数据进行聚类分析,将聚类分析的结果存储到MongoDB。以岗位聚类分析为例,通过搜集发布的工作岗位,按照地区显示岗位数量,可以推导出工作热点。
数据应用层:通过云平台存储的大量数据,可以按照用户的要求抽取数据,然后在数据应用曾定义显示数据的接口,将数据与接口对应起来即可。典型的应用如按照岗位发布的地区统计工作数目,按照岗位的学历要求统计工作数目,按照工作发布的招聘企业类型统计工作分布。
4. 云存储设计
4.1 源数据存储
通过网络爬取数据文档模型是一个N元组,其定义为:
<PAGEID, JOBNAME,LOCATION,RELEASEDATE,SALARY,EXPERIENCE,EDUCATION,AMOUNT,COMPANY_SCALE,CATEGORY,COMPANY_INDUSTRY,COMPANY_NAME,COMPANY_NATURE,ISTAGED,DISCRIPTION>,
其含义分别是html页面编号,岗位名称,招聘地点,发布日期,薪资水平,工作经验,教育水平,公司规模,招聘人数,岗位类别,所处行业,公司名称,公司性质,是否标记,任职要求,其爬取原型数据如下图3所示。
通过Web端远程访问云数据库HBase的数据,Hbase数据表效果如图4所示。

图4 Hbase表数据
4.2 数据清洗存储设计
原始页面的数据如图3所示,是一个不规则文档,需要对数据进行清洗。以公司行业性质为例,在配置文件中,详细定义了各种性质的类型,如国企、民营企业、事业单位、外企、私企等等,由于有些就业发布信息没有说明,所以爬取的时候无法获得数据,对于这些数据需要进行处理。在招聘需求时,许多公司都发布了职位的任职需求,爬取数据会将换行数据或者是空数据存放,这些数据是不规则数据,需要进行清理。在获得职位的类别时,需要对工作任职要求或者工作名进行中文分词,然后匹配工作类型词库,分析该工作所属类别。
数据清洗关键步骤如下:
(1)通过手动配置开启数据清洗服务;
(2)从云数据库Hbase的列族读取爬取原始数据;
(3)根据配置文件的规则对原始字段进行清洗判断或者分词处理;
(4)将处理后的数据缓存到集合中,批量提交到云数据库的清洗列族;
(5)数据清洗后,按岗位类别保存数据,关闭清洗服务;
以下是截取以云计算分类的配置文件,当岗位名称或者任职描述中包含以下词语时,可以将该条记录分类到云计算的类别当中。

4.3 数据聚类存储设计
数据清洗完毕之后,所有的数据保存到HBase中,聚类服务根据用户需求,按岗位类别进行数据聚类计算,然后显示给用户。其工作流程如图5所示。

图5 数据聚类流程
本文以爬取的492条计算机类招聘数据作为研究对象,按照 develop、operation、framework 三类进行抽取,详细聚类过程如下:
1.从服务配置中启动服务,输入待聚类的岗位集合;
2.根据指定的岗位集合从清洗数据库中解析数据源,并对所有的数据岗位进行分类,形成岗位集合数据;
3.遍历岗位集合数据,对每一个岗位的任职要求进行分词计算,获得每一个岗位的描述;
4.以岗位分类和岗位描述分析进行向量距离计算,并将结果作为数据聚类的依据;
5.将向量结果计算并以MongoDB文档对象存储,最后将MongoDB对象文档提交到MongoDB数据库中
6.通过web前端的计算,将文档对象转换成json对象数据,显示到html文档中。
服务配置的关键代码如下所述:

5. 实验与结论
本系统的开发是在南京55所云计算系统框架下展开的,通过数据采集整理分析可以发掘出用户想要的数据。图6是以开发、运维和架构三个类簇模型进行的聚类效果展示,每个类簇包含若干数据记录。以开发类簇为例,该类簇总的记录条数是27条,占所有类簇中记录数据的84.38%,在开发类簇中,主要分为云计算开发工程师和云应用开发工程师,通过该数据可以得出,云计算开发工程师在就业市场比较受欢迎。
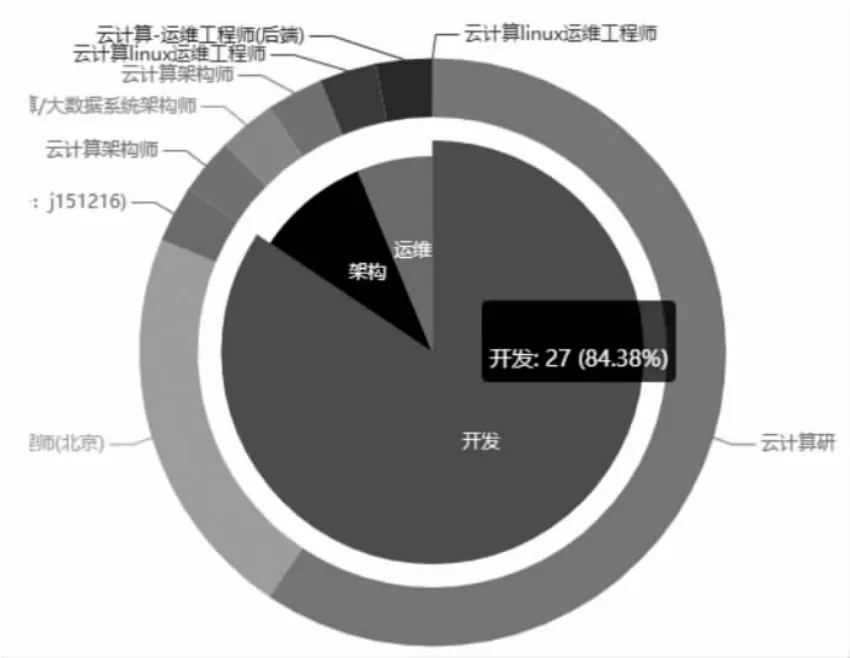
图6 岗位聚类效果
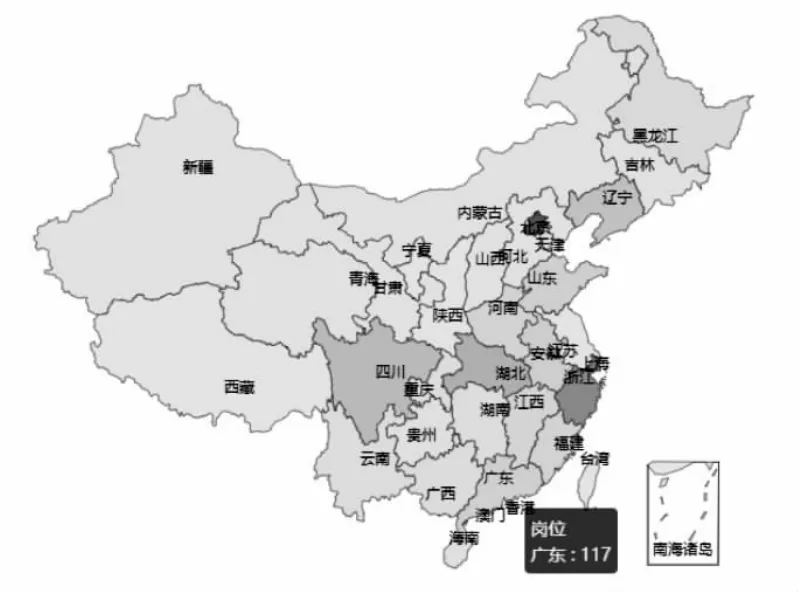
图7 地区分布效果图
在所有采集的数据中,按照岗位发布的地区进行统计,形成了如图7的效果图,通过不同的地区颜色标记岗位的发布数量,可以得出全国岗位发布密集的地区是浙江、上海、北京、广东、湖北、四川等省市,其中广东发布的工作岗位需求量最大。
根据用户的需求,还可以抽取其他数据进行分析,如分析工作的薪水、招聘公司的行业性质、岗位学历的要求等等。
本文详细描述了聚类算法的思想及算法实现,解剖了Hadoop环境下招聘大数据系统架构,论述了源数据的大爬取,数据整理保存到Hbase,然后对Hbase数据进行清洗和聚类,将聚类的结果保存到MongoDB,,最后通过echarts显示出来,为今后类似大数据系统的开发提供参照。
本文的聚类算法是基于Spark框架下自带的聚类方法,对于聚类的k值的选取及算法的性能测试并没有做深入的研究,聚类算法的演变有基于原型聚类、密度聚类及层次聚类等,在算法改进需要做进一步的研究。
猜你喜欢
睿士(2023年2期)2023-03-02 02:01:09
乡村地理(2018年2期)2018-09-19 06:44:06
意林(2018年3期)2018-03-02 15:17:24
电子测试(2017年15期)2017-12-18 07:19:27
中华儿女(2016年14期)2016-12-20 18:22:28
厦门理工学院学报(2016年1期)2016-12-01 04:50:48
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:48
智能系统学报(2015年4期)2015-12-27 09:38:39
现代企业(2015年4期)2015-02-28 18:48:18
电子设计工程(2015年6期)2015-02-27 12:04:53
