
基于隐结构分析建立中医证候分型规则的三种方法*
2019-05-18 02:05:58许玉龙吴秀艳李延龙王天芳张连文薛晓琳
世界科学技术-中医药现代化 2019年1期
许玉龙,吴秀艳,李延龙,王天芳**,张连文,薛晓琳
(1.河南中医药大学信息技术学院 郑州 450046;2.香港科技大学计算机科学与工程学系 香港;3.北京中医药大学 北京 100070)
中医辨证过程实质上是在无金标准情况下对患者进行分类的问题[1,2],在研究中医证候时,常用的方法有数据回归分析、聚类分析、主成分分析、因子分析等[3],但这些技术在中医证候分类研究时存在不足。回归分析基于专家对过往病例的判断建立辨证规则,缺乏客观性;聚类分析主要用于对症状变量聚类,而辨证是把患者分类;主成分分析和因子分析是数据降维方法,不对患者进行分类,其工作原理也与中医思维不符;因子分析研究都把症状视为实数值变量,并假设它们是由一组相互独立的实数值隐变量(代表证候)通过线性关系确定的。
隐类分析是一种患者聚类方法,它把症状视为离散变量(一般是二值),其基本思想是:某患者是否属于一个证候类型取决于一组症状的出现情况,这与中医思维吻合。隐类分析在西医研究中已得到广泛运用,截止2011年,隐类分析关于在西医研究中应用的文章有180 余篇,且增长速度较快。比如,学者Li et al[4]利用隐类分析研究了汉族妇女重型抑郁症亚型问题,该问题与中医辨证分型类似,都是要在无金标准的情况下对患者进行分类。关于隐类分析的原理,Li Y 说:“一般而言,临床诊断的经验,是由临床专家通过观察大量患者,总结关键症状和体征出现的规律(同质性)而逐渐形成的。隐类分析能以相对严谨地统计学方式,模拟上述过程[4]”。隐类分析的输入是一组症状以及这些症状在患者身上出现情况的数据,其结果是在概率意义下把患者聚为若干个类。但是,隐类分析有一个严重的弱点,它依赖局部独立假设,即在每个类中,观测的症状值是相互独立的[5]。换句话说,模型假设症状的出现与否直接由其所属类别决定,而不受其它因素影响。但在实际中这个假设往往不成立,从而导致估计的偏差[5]。
隐树分析法,又称隐结构分析法[6,7],是对隐类分析法的改进,它放宽了隐类模型的局部独立假设,使得模型能够更好地与数据拟合,也更贴近中医理论。近年来的相关研究表明[8-13],利用隐结构分析能较合理地模拟中医辨证论治的过程,弥补常规方法存在的不足,适合于研究中医证候问题。

表1 中医证候以及其相应的症状
图1 打开模型学习功能
隐结构法有单步隐树分析和双步隐树分析两个版本。顾名思义,双步隐树分析有两个步骤:第一步是对所有症状数据进行隐树分析,全面揭示数据的各个侧面,得到总体模型;第二步审视第一步的结果,依据医学知识,选择与某证候相关的隐变量和症状,并建立一个针对该证候的隐树模型,对患者进行聚类分析。隐类分析在对患者进行聚类时使用的是症状显变量,而隐树分析使用的变量部分是隐变量,从而局部假设得到放宽。单步隐树分析的出发点与隐类分析一致,即与某证候相关的一组症状以及关于这些症状的病例数据。它通过分析这些数据,而不是包含所有症状的数据,一步建立针对该证候的隐树模型,对患者进行聚类分析。
为介绍和验证隐类分析、单步隐树分析、双步隐树分析这三种方法在分析数据时的差异,以及其建立模型质量的优劣,本文针对801 例肝硬化患者的中医症状数据,分别用上述三种方法进行分析,并对比得到的模型及其BIC分值,来揭示三种方法各自的特点,以便在研究和应用时做出适当的选择。
1 三种方法介绍
隐类分析、单步隐树分析和双步隐树分析的基本功能是[13,15]:依据用户提供的症状数据,可将患者分别聚成两个或多个类别,这些结果可用来确定证候的分布情况和特点。下面以801例肝炎肝硬化患者的症状数据为例,对上述三种方法做简单介绍。
1.1 数据情况
本文使用的801 例数据源自2011 年11 月至2012年9月在解放军302医院、湖北省中医院、首都医科大学附属北京地坛医院、首都医科大学附属北京佑安医院、北京中医药大学东方医院、中国中医科学院西苑医院、首都医科大学附属北京中医医院及广西中医药大学第一附属医院的门诊或住院部采集的真实病例数据。数据包含97个症状,每条记录对应在某患者身上出现的相关症状信息,症状出现时值为1,不出现时值为0。数据是无标签的,即无辨证结论。
参考团队中医专家组的经验和行业委员会发布的证候标准,依据待分析的症状信息,分别选出气虚证、气滞证、热证、湿证、水停证、血瘀证、阳虚证、阴虚证,共8个证候所涉及的症状(表1)。
使用孔明灯隐结构分析软件[15]对数据进行分析,其包含了隐类分析、单步隐树分析、双步隐树分析三种方法。
1.2 隐类分析法
以气虚证为例介绍隐类分析法。操作流程是首先在孔明灯软件中,点击“分析”—“隐树模型学习”(图1);读入气虚证涉及9个症状的数据文件,使用隐类分析算法LCM处理(图2);接着点击确定,运行后得到气虚证的患者聚类模型(图3)。注意,隐类模型是一种特殊的隐树模型,所以在孔明灯软件中归于“隐树分析之下”。
隐类分析得到的模型只包含一个患者聚类变量(隐变量“气虚”),它直接与症状变量相连,表示它假设症状的出现与否直接由患者所属类别完全决定,而不受其它因素影响。聚类模型把患者分成了3 类,称为隐类S0、S1、S2(表2)。隐类S0、S1、S2的患者数占总数比率分别为0.36、0.51、0.13。在隐类S0 中,症状“神疲”、“乏力”、“便溏”、“懒言”出现的概率分别为0.16、0.44、0.13、0.07,这些症状出现的概率较小,可认为隐类S0为非气虚人群。在隐类S1中,上述症状出现的概率分别为0.86、1、0.06、0.54,它们出现的概率都较大,认为是属于气虚人群。在隐类S2中,上述症状出现的概率分别为0.89、0.96、0.97、0.61,所有症状出现的概率都较大,也认为是属于气虚人群。在S2 类中,“便溏”出现的概率远大于类S1,根据中医知识,脾虚会造成“便溏”的出现,所以可认为S2类为脾气虚人群。
1.3 单步隐树分析法
使用单步隐树分析时,用户提供的输入数据与隐类分析完全相同。以气虚证为例,在孔明灯软件中,点击“分析”中的“隐树模型学习”,该步骤与图1 相同。读入气虚证涉及9 个症状的数据文件,使用单步隐树分析算法(UC-LTM)分析处理(图4),然后点击确定,运行得到气虚证患者聚类模型(图5)。
单步隐树分析使用UC-LTM(unidimensional cluster with latent tree model)算法[14]处理数据(图5),模型包含有隐变量“Y1”和患者聚类变量“气虚”。然后,利用模型对数据进行聚类分析,结果把患者聚成了S0和S1两个隐类,各类中症状出现的概率(表2)。与图3隐类分析得到的模型不同,图5 的模型认为气虚不直接影响所有症状,它通过一个隐变量“Y1”间接影响“便溏”、“泄泻”等5 个症状。这样,局部独立假设得到了放宽。从表3 可知,隐类S0 占人群总数的36%,在隐类S0 中,症状“神疲”、“乏力”、“面色晦暗”、“懒言”出现概率分别为0.15、0.44、0.55、0.07;隐类S1 占人群总数的64%,在隐类S1中,上述症状出现概率分别为0.86、0.99、0.72、0.56。明显地,隐类S1中所有症状出现概率全部大于隐类S0,即可以推断隐类S1 为气虚证人群,S0为非气虚证人群。
1.4 双步隐树分析法
双步隐树分析[12,13,16]有两大步骤,所以称为双步隐树分析法。第一步,对数据中所有症状(而不是只针对某证候的症状,这与隐类分析和单步隐树分析不同)进行分析,得到整体模型。第二步依据医学专业知识,参照第一步的结果,选取与某证候有关的症状,利用它们和整体模型构造最终的患者聚类模型,然后对患者进行聚类。
图2 读入数据,选择隐类分析LCM算法
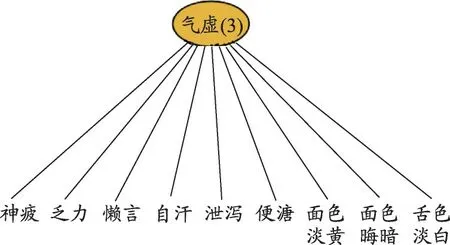
图3 隐类分析得到的气虚证聚类模型
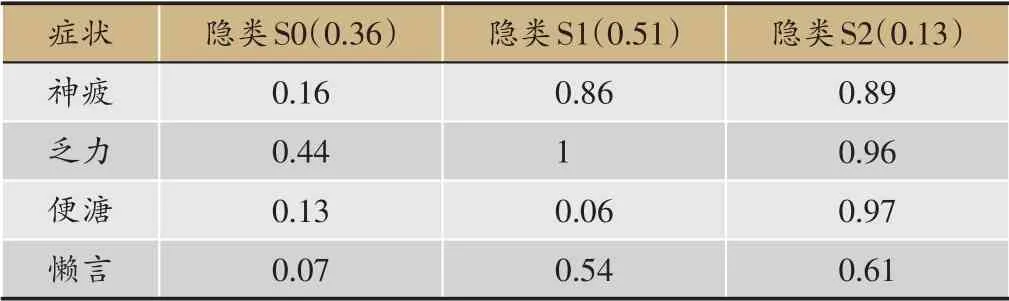
表2 图3对应的隐类及其概率分布
图4 读入数据,选择单步隐树分析UC-LTM算法

图5 单步隐树分析得到的气虚证聚类模型
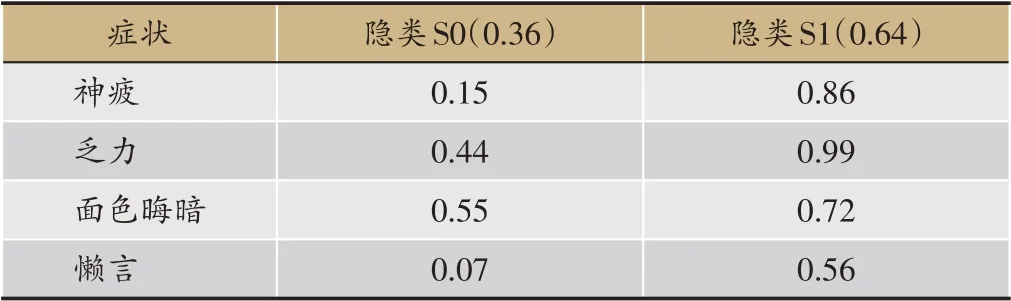
表3 图5对应的隐类及其概率分布
图6 读入数据,选择双步隐树分析LTM-EAST算法
以气虚证举例,在孔明灯软件中点击“分析”中的“隐树模型学习”,该步骤与图1相同。然后,读入所有的症状数据(注意不只是气虚的数据),选择EAST 或BI算法学习(图6),点击确定,运行后得到总体模型如图7所示。依据表1中气虚证涉及的症状,在总体模型中选取这些症状进行综合聚类,得到最终的患者聚类模型如图8所示,它包括隐变量Y1、Y2、Y3和患者聚类变量“气虚”(证候隐变量)。注意,在图8中神疲、乏力通过一个隐变量与证候间接相连,这是因为在第一步分析中,它们被放在同一个隐变量(Y26)下,表示它们来自数据的同一个侧面。另一方面,自汗在第一步分析中与其它几个症状一起被放在隐变量Y20 下,这些症状中只有自汗一个症状与气虚有关,所以在综合聚类模型中,它直接与证候隐变量相连。
与单步隐树分析得到的模型相比,图8 模型的中间层隐变量更多,它把“神疲”、“乏力”归纳为一个隐变量Y1;把“便溏”、“泄泻”归纳为一个隐变量Y2;把“面色晦暗”、“面色淡黄”归纳为一个隐变量Y3,这些症状都分别反映相同或相近的侧面。双步隐树分析利用图8 模型对数据进行聚类分析,把患者聚类变量分成了S0和S1两个隐类,每个类的特性(表3)。
从表4可以看出,隐类S0占患者群的39%,在隐类S0 中,症状神疲、乏力、泄泻、懒言出现概率分别为0.24、0.51、0.06、0.04。隐类S1 占患者群的61%,在隐类S1中,上述症状出现的概率分别为0.85、0.98、0.18、0.6,他们在此类中出现的概率明显高于隐类S0,即可推断隐类S1为气虚证人群,S0为非气虚人群。与表2相比,表3中增加了泄泻症状,且在隐类S1中该症状的出现概率明显高于S0类。
2 三种方法的比较
2.1 关于其它证候的患者聚类模型
除了气虚证,我们还对肝硬化患者群的其它证候分布情况进行了研究,相应模型(图4),其中证候隐变量旁边的数字为隐类个数。为节省空间,只展示气虚证、热证、湿证用三种方法得到的患者聚类模型。
隐类分析相比,两种隐树分析得到的患者聚类模型一般包含多个隐变量,从而放宽了局部独立假设,另外,其得到的隐类个数也相对较少,便于对患者的分类(表5)。
2.2 模型评分的比较
在对数据进行聚类分析时,不同方法得到的模型不同,如何判断模型的优劣?我们使用BIC(Bayes Information Criterion)评分[17]。BIC 评分是统计学中常用的模型评价准则,它要求模型与数据尽量拟合,但不能过于复杂。实际上在聚类算法中,类的个数也是由BIC评分来确定。

图7 双步隐树分析得到总体模型

图8 双步隐树分析综合聚类后得到的聚类模型

表4 图8对应的隐类及其概率分布
表6 给出了所有证候聚类模型的BIC 分,采用负分法计量,其分值越大越好。可以看出,使用隐类分析得到模型的分值普遍较小,即模型质量较差。单步隐树分析得到模型的BIC得分接近或略好于双步隐树分析,具体而言,在气虚证、湿证中,单步隐树分析得到模型的分值较好;在气滞和热证中,双步隐树法得到模型的分值较好;在其它证候中,单步隐树分析得到模型的分值稍微较好。总之,仅从表6模型的BIC分数来看,在三种方法中,单步隐树分析和双步隐树分析得到的模型得分均优于隐类分析的模型,双步隐树分析得到模型的BIC分值接近或稍微差于单步隐树分析。

表5 隐类分析、单步隐树分析和双步隐树分析得到聚类模型
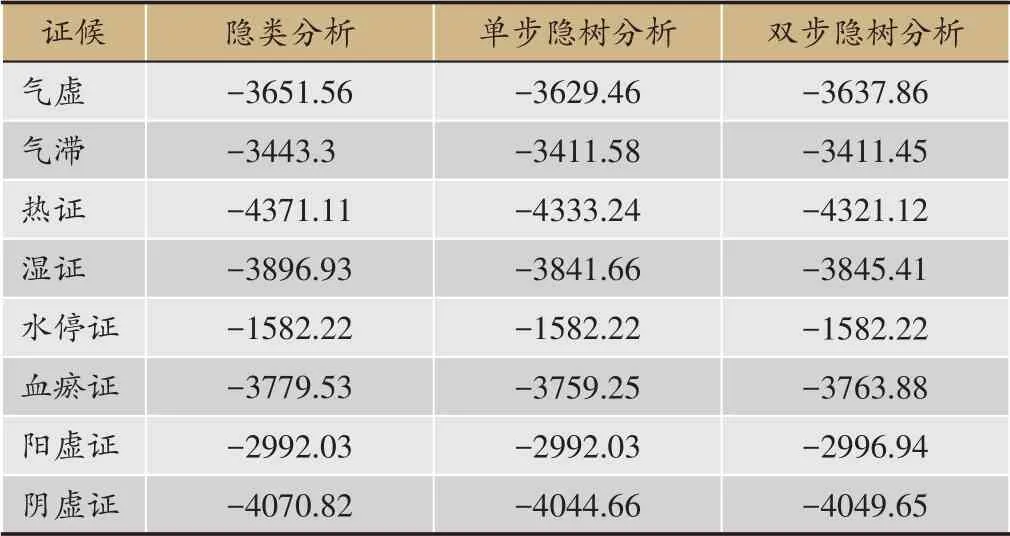
表6 三种方法得到聚类模型的BIC分数对比
2.3 模型结构的比较
首先以气虚证为例,对表4 中的聚类模型图4a、4b、4c进行对比分析。单步隐树分析的聚类模型(4b)把“舌色淡白”、“面色淡黄”、“泄泻”、“便溏”、“自汗”五个症状归为一个隐变量Y1,他们都反映了患者的状态,而其他所有症状与证候隐变量直接相连。双步隐树分析的聚类模型(4c)把“神疲”、“乏力”归为一个隐变量Y1,他们从整体角度反映了患者的精神状态;把“便溏”、“泄泻”归为一个隐变量Y2,他们从二便角度反映了脾阳虚情况;把“面色晦暗”、“面色淡黄”归为一个隐变量Y3,他们都从面色角度反映了患者的病情特征。从上述对比可知,双步隐树分析得到的聚类模型较为复杂,它增加了隐变量个数,每个隐变量更明细反映了某种相似的侧面。由于模型复杂,在计算BIC 分数时惩罚项较多,所以模型得分略差,但整体而言,双步隐树分析的聚类模型更为合理。
考虑热证的聚类模型,发现单步隐树分析的模型表4e 和双步隐树分析的聚类模型4f 中存在相同的隐变量,即他们把“口渴”、“口咽干燥”和“老舌”、“燥_糙苔”分别归纳到相同的隐变量下,这两个隐变量均从口感和舌像角度反映了热证的情况,从而验证了两种分析方法在考虑相似侧面的一致性。两个聚类模型区别为:双步隐树分析将“尿色深黄”、“便秘”归为一个隐变量,将“发热”、“数脉”归为一个隐变量,较单步隐树分析更清晰地揭示了在二便和整体上的表现,分类更为细致,更符合肝炎肝硬化的临床表现,所以双步隐树分析的模型结构和BIC评分都优于另外两种方法。
对湿证的模型结构比较,从模型的BIC评分来看,单步隐树分析得到的模型优于双步隐树分析;但对模型表4h 和4i 比较发现,在4i 中,双步隐树分析模型把“纳呆”、“厌油腻”归为一个隐变量,较单步隐树分析把“纳呆”、“厌油腻”和“黄疸”归为一个隐变量更为合理。因为黄疸是反映患者的整体情况,而纳呆和厌油腻反映了患者的脾胃功能。另外,双步隐树分析把“齿痕舌”、“胖舌”归为一个隐变量,更为精确地从舌质角度反映了湿证的情况。
综上所述,从得到患者聚类模型及中医诠释考虑,双步隐树分析得到模型的结构更合理,较符合实际临床,优于或不差于另外两种方法;从得到模型的BIC得分和方法使用步骤来看,单步隐树分析得到模型的得分较好、操作步骤较为简单,优于另外两种方法。隐类分析方法则较适合于在满足局部独立假设的情况下,进行简单的数据分析。
3 总结
辨证论治是中医的精髓,但目前尚无证候诊断的相关金标准,在临床诊病过程中,证候的确定较严重地受医生主观性影响。隐类和隐结构分析已被证明是研究此类问题的适宜方法,本文介绍了三种基于无标签症状数据建立证候分型的隐类及隐结构方法,并在801 例肝炎肝硬化患者症状数据上进行测试,对三种方法的特点和效果进行比较分析,明确它们各自的优势和不足,以便在临床研究中供用户选择使用。这些方法的使用可以促进辨证分型的客观化,提高临床诊疗的一致性。
猜你喜欢
世界科学技术-中医药现代化(2022年9期)2023-01-17 07:31:10
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
河北理科教学研究(2020年2期)2020-09-11 06:15:48
电子测试(2017年15期)2017-12-18 07:19:27
智能系统学报(2015年4期)2015-12-27 09:38:39
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
云南中医学院学报(2015年2期)2015-07-31 18:11:59
电子设计工程(2015年6期)2015-02-27 12:04:53
新高考·高二数学(2014年7期)2014-09-18 00:42:02
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
