
基于改进Apriori的WiFi入侵检测模型研究
2019-05-16 07:17:00刘明峰郭顺森
沈阳航空航天大学学报 2019年2期
刘明峰,侯 路,郭顺森,韩 然
(国网山东省电力公司青岛供电公司,山东 青岛 266002)
随着Wi-Fi技术的普及,基于IEEE802.11协议的短距离传输无线网络成为主流,但其自身安全机制存在较大的安全隐患[1],任何未知用户都可通过无线接入点访问局域网,而防火墙策略无法满足高安全性的要求。因此,入侵检测系统(IDS)成为防火墙的合理补充,实时的IDS能最大程度检测出网络异常行为[2-4]。因此,提出一种实时的Wi-Fi网络入侵检测机制成为亟待解决的问题[5]。
目前,国内外学者提出了多种基于数据挖掘的入侵检测系统,如:文献[6]提出一种基于关联规则挖掘Apriori算法的无线网络入侵检测系统ADAM;文献[7]将聚类划分思想融入Apriori中以提高挖掘的效率;为降低检测算法的误报率,文献[8]提出一种基于稀疏自编码的非监督式入侵检测方法。虽然上述方法取得了良好的检测效果,但检测过程都是离线的,无法将网络危害风险降至最低。另一方面,基于Apriori算法的检测方法只计算了某个数据包的频繁模式,而许多入侵行为的数据流不存在频繁模式,若将整个攻击流嵌入到单个数据包中,此种方法就很难发现网络异常。文献[10]通过分析数据包包头结构生成特征数据,训练分类器检测网络流量,但该方法没有考虑数据包载荷问题,因此该系统无法检测出提权攻击或越权访问攻击,同时训练分类器也增加了检测过程的时间开销。
1 基于关联规则挖掘的入侵检测方法
1.1 关联规则挖掘原理
文献[11]首次提出了关联规则挖掘,定义L={i1,i2,…,in}为项目集合,称为项集。数据库(事务集)D为全体事务的集合,每个事务T是一组集合,有T⊆L,对应的标识为TID。定义事务X⊆L(其中,X为L某些项目的集合,且有X⊆L)。关联规则定义形如:X→Y,其中X⊆L,Y⊆L且X∩Y=φ。若D中c%的事务既包含X又含Y,则规则X→Y在数据库D中的置信度为c。若D中s%的事务包含X∪Y,则规则X→Y在数据库D中的支持度为s。表1罗列了TID为1,2,3,4和5的五个事务,关联规则{A}→{C}{A}→{C}的置信度为75%,支持度为60%。
1.2 Apriori算法
Apriori算法在入侵检测中表现出了良好的性能[12]。算法的基本思想是使用较短的k项频繁集集合Lk,推导出长度为k+1项的频繁集Lk+1(从k=1开始),直到找不到更频繁的项集。使用以下两个步骤从频繁k-1项集的集合Lk-1中找到频繁k项集的集合Lk,首先,将Lk中的频繁项集两两结合,生成候选k项集集合Ck,其次,修剪Ck中不满足Apriori属性的项集,筛选掉低于预设支持度的候选频繁k项集。要从候选集Ck获得Lk,必须扫描数据库以获得Ck中所有项集的支持度。Apriori算法实现流程如图1所示。

表1 数据库记录示例

图1 Apriori算法流程
2 基于关联规则挖掘的入侵检测方法
2.1 相关定义
为了方便理解所提方法,将网络数据包看做数据库D中的记录,有如下相关定义和命题。
定义1 若记录Ri具有的最大频繁n项集,即包含n个不同项目,则记录最大级别为n。
定义2 最大级别为n的记录具有一组频繁和非频繁项集:由其所有的1项集至n项集组成。
定义3 频繁k项集:支持度大于或等于给定最小支持度的k项集。
定义4 非频繁k项集:支持度小于给定的最小支持度的k项集,且其所有1至k-1级子集是频繁项集。
定义5 最大级别为n的记录的频繁项集集合FR:由其所有1项集到n项集的集合组成,其中所有项集的支持度均大于或等于给定最小支持度。
定义6 最大级别为n的记录的非频繁项集集合IFR:由其所有1项集到n项集的集合组成,其中所有项集的支持度均小于给定最小支持度。并且其所有1至k-1级子集是频繁项集。
定义7k项集异常得分:如果项集是频繁项集,则k项集的异常得分为-k;如果项集是非频繁项集,则k项集的异常得分为+k。
定义8 记录的异常得分:最大级别为n的记录的异常得分是其所有级别从1到n的频繁和非频繁项集异常得分的总和。
命题记录属性(正常/异常):正常记录中的频繁项集多于非频繁项集,记录异常得分为负值;异常记录的非频繁项集多于频繁项集,记录异常得分为0或正值。
2.2 系统架构相关定义
本文提出的Wi-Fi入侵检测系统包括三个模块:输入模块、数据预处理模块和异常检测模块、结构如图2所示。为提高检测的响应时间,输入模块使用Network Chemistry无线传感器[13]实时捕获无线数据包。预处理器模块使用CommView软件从传感器的firebird数据库中捕获数据并保存为.csv文件。通过该软件,提取必要的特征并将其存储为文本文件,还可将记录存储到数据库中,进行后续离线分析或跟踪。本文所提方法是在线的,可不依赖训练数据,对数据进行预处理后,便可将其发送给异常检测模块。
2.3 基于非频繁模式的关联规则挖掘算法
基于非频繁模式关联规则挖掘算法(IF-Apriori)可计算出每个级别对应的频繁模式和非频繁模式,并统计记录的异常分值。本文对传统Apriori的连接过程进行改进。Li为频繁i项集,若要连接Li中的项集M和P,需要满足:M在Li中的排列在P之前;M和P中的前i-1项集相同;M和P均是可连接的,即M和P中的最后一项在Z列表中,其中Z列表为Li中所有项集中前i-1个项目的集合,该连接方法避免了与那些不太可能生成频繁模式的项集的连接,减少了对非频繁项集的剪枝操作。IF-Apriori算法伪代码如算法1所示,其使用的智能连接方法如算法2所示。

图2 基于IF-Apriori算法的智能连接
算法1 非频繁模式计算
Input:候选集C1,最小支持度λ
Output:频繁项集集合L,每条记录的异常得分
其它变量:非频繁项集S
Begin
k=1
步骤1 根据最小支持度λ,从Ck中计算频繁项集集合Lk和非频繁项集集合Sk
步骤2 While(Lk≠0) do
begin
k=k+1
根据算法2,从Lk-1计算候选集Ck
ForCk中每一个项集 do
计算所有可能的子集,并进行剪枝
IfCk=φ,转到步骤3
根据最小支持度λ,从Ck中计算频繁项集集合Lk和非频繁项集集合Sk
调用异常分数计算函数,使用Lk和Sk更新记录的异常得分
步骤3 计算所有的频繁模式,L=L1∪L2…∪Lk
算法2 智能连接算法(从Lk-1中生成候选集Ck)
Input:k-1项集集合L
Output:候选k项集集合Ck
Begin
Ck=φ
Z=Lk-1中所有项集中前k-2个项目的集合
ForM,P∈Lk-1do
Begin
M与P连接生成M∪P
if 满足如下条件:
(a)M在Lk-1中排列在P前
(b)M和P的前k-2项集相同
(c)M和P均为可连接,二者最后一项目在Z中
then
Ck=Ck∪M∪P
end
End
2.4 异常分数计算
通过计算每个连接数据包的异常得分,所提方法避免了频繁模式生成关联规则的步骤。异常得分计算是对记录的每个n项集的非频繁模式赋予+n的异常分数,对频繁模式赋予-n异常分数。计算过程基于以下前提:异常是偶然事件,若异常嵌入到频繁或正常的数据包(记录)中。则记录的得分为该记录从1到n项集频繁和非频繁模式的所有异常得分数总和,其中n是记录中频繁模式的最后非空级别。若记录的总得分为零或正,则该记录异常;总得分为负则该记录正常。若网络记录产生类似表2中第一列和第二列的数据库事务表,其中候选项集为{A,B,C,D,E,F}。在数据预处理阶段,A到F可以表示为以下属性:连接时间、源和目的MAC、数据包大小、接入点MAC(BSSID)、帧类型/子类型、传输速率、接入点名称、源类型(站点或接入点)等。
3 基于关联规则挖掘的入侵检测方法
3.1 实验数据
本文采用Network Chemistry传感器捕获Wi-Fi网络内的实时数据。在5分钟内,捕获了约20500个数据包,含手工生成的攻击包约600个,包括被动攻击(用于WEP破解和端口扫描的数据包)、主动攻击(SYN Flood和UDP Flood攻击数据包)和中间人攻击(建立虚假接入点的数据包)。以上具体实现过程可参考文献[14]和[15]。表3总结了实验中攻击数据的攻击签名。
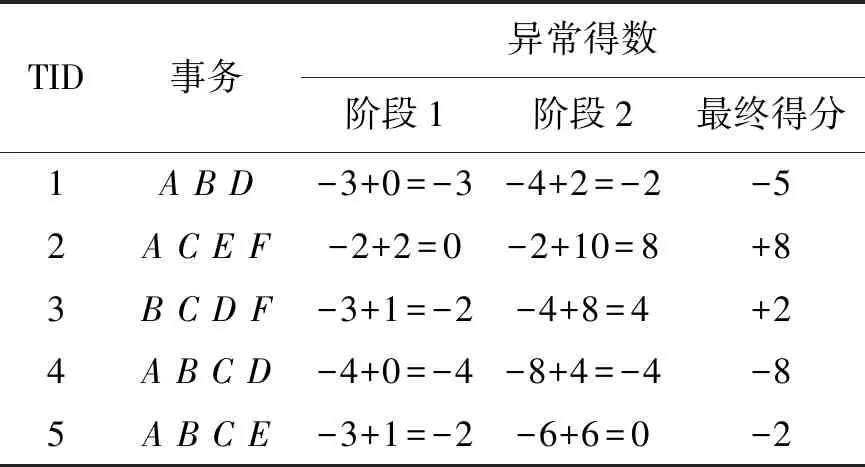
表2 数据库记录异常得分

表3 攻击签名
3.2 异常得分计算
对表2中的前两列进行计算并统计异常分数并最小支持度为60%。根据算法2,C1={A:4,B:4,C:4,D:3,E:2,F:2},L1={A,B,C,D}中每项异常得分为-1,S1={E,F}中每项异常得分+1。对于TID为1的事务,ABD的异常得分为:-1(A)-1(B)-1(D)=-3;TID为2的事务,ACEF的异常得分为:-1(A)-1(C)+1(E)+1(F)=0;以此类推,TID为3,4,5的事务异常得分为-2,-4,-2。接下来计算C2,此时列表Z为空。因此,C2={AB:3,AC:3,AD:2,BC:3,BD:3,CD:2}。L2={AB,AC,BC,BD},其中每个项集异常得分-2,而S2={AD,CD},每个项集异常得分+2。事务异常得分更新为:Tid1(ABD)=-3(来自上一步骤的分数)-2(AB)+2(AD)-2(BD)=-5。Tid2(ACEF)=0(来自上一步骤的得分)-2(AC)+2(AE)+2(AF)+2(CE)+2(CF)+2(EF)=+8。其余异常得分更新如表2中第4列所示。第三次迭代创建C3列表,首先从L2中创建Z列表,将每个L2中的项加入Z中得到Z={A,B}。连接L2的项集,若项集的最后一项不在Z中则终止连接。根据以上规则,由于AC、AD、BC、BD和CD的最后一个元素不在Z列表中。可将L2={AB,AC,AD,BC,BD,CD}中的项减少至{AB},通过改进的关联规则算法连接{AB},得到C3={AB}=φ。由于C3和L2均为φ,不计算此次迭代的异常得分,算法结束。所有异常得分为负的记录可认为是正常数据,而异常得分为0或正的记录则会产生告警。示例中各记录的最终异常得分如表2中第5列所示。
3.3 结果分析
与Apriori进行比较,以验证所提方法在检测率和运行时间方面的优势。与两种IDS(ADAM和Snort Wireless)进行比较,以验证所提方法在检测率和误报率方面的优势。如图3所示,所提方法IF-Apriori与传统的Apriori相比,算法执行时间降低了约35%。这是因为所提算法无需生成与置信度值相关的关联规则,同时所提的智能连接方法降低了连接过程消耗的时间。实验表明,在测试数据集相同的情况下,IF-Apriori与Apriori可生成相同的完整频繁模式和非频繁模式。

图3 不同算法运行时间
本文提出的方法与基于Snort的IDS(Snortwireless)[17]和基于Apriori的IDS(ADAM)[6]进行了对比实验,研究三种IDS的检测和误报情况。实验结果如表4和图4所示。

表4 检测情况
针对主动攻击、被动攻击以及中间人攻击这三种特定的攻击类别,本文提出的IDS与另外两种IDS相比,能识别出更多的攻击包且误报率更低。根据图5不难看出,针对不同类型的攻击本文提出的IDS具有较高的检测率,这也说明其具有较强的泛化能力。
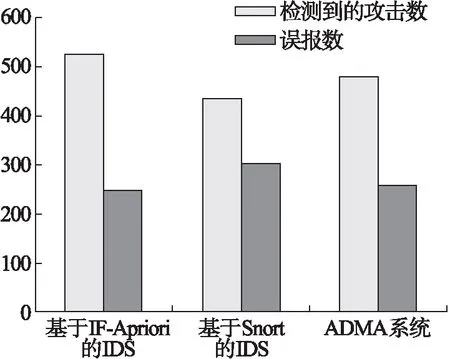
图4 三种IDS检测情况和误报情况对比
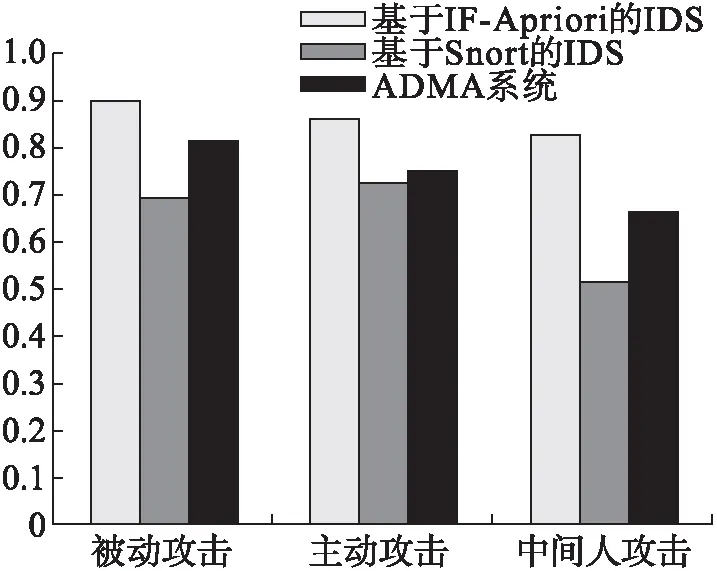
图5 三种IDS对不同攻击的检测率对比
无线干扰攻击在现实生活中很少出现,所提方法还不具备检测该攻击的能力。此外,若将最小支持度阈值设置过低,会产生大量的频繁项集和较少的非频繁项集,这会增加发现攻击的难度。经过多次实验,针对提出的IF-Apriori算法,最小支持度应设置为60%或更高。为了检验支持度对入侵检测效果的影响,统计了IF-Apriori算法与Apriori算法在不同支持度检测率,如图6所示。

图6 不同支持度下的检测率
通过与其他方法进行比较以验证IF-Apriori分类器的有效性。实验中,结果取10次十折交叉验证对应的平均值以确保实验合理性。此外,本节所展示的时间是平均分类时间。通过与支持向量机(Support Vector Machine,SVM)算法[16]和随机森林(Random Forest,RF)算法[17]进行了比较,实验结果如表5所示。此外,集成了Real AdaBoost算法的SVM和RF分类器[18]的AUC值能得到一定程度的提高,在集成Real AdaBoost算法后,IF-Apriori分类器的AUC未得到改善。
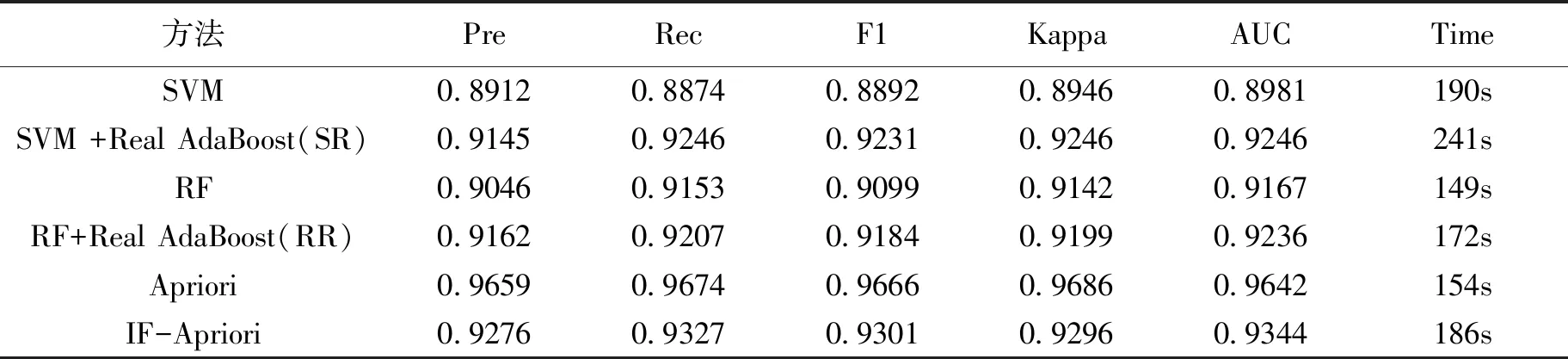
表5 分类器性能对比
4 结论
本文提出一种wifi无线网络入侵检测系统,使用基于非频繁模式的关联规则匹配算法来检测非频繁的模式,为每个数据包分配一个异常分数,通过判断异常分数的正负判断数据包是否异常。使用专用的Network Chemistry硬件传感器来捕获实时流量,改善入侵响应时间。与现有的无线IDS不同,它不依赖训练数据集,实现了实时入侵检测。实验结果表明,本文方法具有更高的检测率和更低的误报率,同时大大降低了系统运行时间。此外,本文还引入了一种智能联合方法,改进了Apriori中连接和剪枝过程。但所提IDS还不具备检测无线干扰攻击的功能,这将是下一步研究的工作。
猜你喜欢
当代陕西(2019年15期)2019-09-02 01:52:00
网络安全和信息化(2018年4期)2018-11-09 12:01:54
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
中国新通信(2014年11期)2014-09-11 19:27:52
卷宗(2014年5期)2014-07-15 07:47:08
计算机工程(2014年6期)2014-02-28 01:26:12
深圳信息职业技术学院学报(2013年3期)2013-08-22 11:42:30
电子设计工程(2011年24期)2011-06-09 10:15:02
当代修辞学(2011年2期)2011-01-23 06:39:12
