
一种保持轨迹数据高可用性的隐式位置访问隐私保护技术
2019-05-16 07:07:24刘向宇刘竹丰夏秀峰李佳佳宗传玉
沈阳航空航天大学学报 2019年2期
刘向宇,刘竹丰,夏秀峰,李佳佳,宗传玉,朱 睿
(沈阳航空航天大学,计算机学院,沈阳 110136)
随着社交网络的蓬勃发展,带有签到服务的社交应用层出不穷,用户可以在这些应用发布自己访问过的位置。由于签到服务的广泛使用,用户的轨迹数据不断地被大量收集。当应用将轨迹数据进行公开发布时,对用户的隐私威胁也就随即产生。
虽然用户可能在某些敏感位置进行位置访问时避免签到,但用户却难以注意到隐式位置访问隐私的泄露。如图1(a)所示为用户u的轨迹集合T,从t1到t5分别是u产生的五条轨迹。而轨迹t1以及各个位置在地图上的方位展示在了图1(b)中,各个位置的语义信息展示在了图1(c)中。注意在本文中T都认为是一个特定用户的轨迹集合,且为了方便表示,每条轨迹都将用位置序列来表示,序列的每个元素即是用户的签到位置。但一条T中的轨迹可能和它对应的实际访问轨迹有所不同,例如,给定轨迹t3∈T,其对应的实际访问轨迹是A→D→G→B→C,而位置B的访问是在轨迹t3中没有出现的,这样的存在过实际访问却不存在于轨迹信息中的位置访问,称为隐式位置访问。假设位置B对于用户u来说是敏感的,所以用户拒绝了在轨迹t3中进行位置B的签到。在本文中,一个位置被考虑为在某个特定的时间段对用户是敏感的。
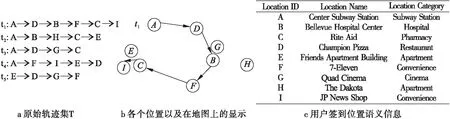
图1 用户u的历史轨迹数据
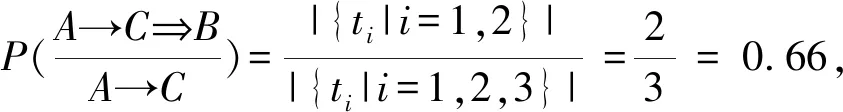
为了避免隐私泄露的发生,本文将采用位置替换技术来匿名化特定轨迹从而使泄露概率下降而起到隐私保护的作用。但是使用位置替换技术还存在两个待解决的问题:(1)位置替换后轨迹不符合用户的行为模式。如果在位置替换后轨迹中出现了新的行为模式,那么攻击者便很容易辨识出替换位置。如图2所示,如果地点B被替换为H,那么就将会出现两种新的行为模式且他们的频度都是1,这样就很容易被攻击者识别出替换位置。(2)位置替换后导致轨迹特征丢失。如图3所示,虚线即为轨迹t1的轨迹特征,如果地点B被替换为H,轨迹特征将会被剧烈改变。但是如果将地点B替换为G,这两个问题都将被有效地解决。
1 相关工作
伴随着社交应用的使用,用户数据不断产生,通过推演技术能推测出用户的重要个人情报,也就产生了数据中隐含的隐私被泄露风险。而位置隐私保护则是隐私保护领域中一个重点研究方向,目前国内外已经提出了多种位置隐私保护技术。

图2 位置替换后行为模式的变化

图3 位置替换后轨迹特征的变化
第一种使用泛化与失真技术[2-5],通过泛化技术将位置转换为一个区域同样可以达到保护目的。Zheng等[4]人提出一种新的隐形区域技术,由用户位置生成隐藏区域并选择其中的子区域来代替发出请求,能够有效防止攻击者通过边信息进行攻击。通过考虑一种半可信服务器框架将移动用户的信息分为三个部分,再使用基于组合优化的隐匿区域算法将用户的位置进行隐藏[5]。
第二种使用概率预测技术[6-7]。M等[6]人提出一种个性化隐私保护系统,针对用户自定义的敏感上下文信息进行有针对性的过滤,这样整个系统便可以抑制攻击者所能增益到的信息,即使攻击者了解整个系统且拥有上下文的时间相关性。而针对智能手机中的上下文感知应用激增的情况,通过考虑和调整假设攻击者的攻击策略可以通过学习算法来获得一种有效防御体系[7]。
第三种使用差分隐私技术[8-12]。Me等[9]人根据差分隐私的基本概念提出一种地理不可辨识性的新概念,通过对用户位置添加双变量的拉普拉斯函数的噪音值将其应用到LBS服务中,最终能取得良好的隐私保障。基于这种地理不可辨识性,MA等人将差分隐私应用到最近邻查询中,通过分类机制将个体分为群组,并将质心查询结果返回给用户[10]。差分隐私技术同样可以应用在位置推荐上,且基于空间索引的技术可以得到优质的推荐结果[11]。
第四种使用加密技术[13-16]。Chen等[13]人构建了一种个性化的排名查询协议,不同用户使用不同密钥加密位置信息。该协议可以以不同粒度进行查询,同时在查询服务中模糊化查询结果。Maede等[14]人考虑了组内成员寻找位置要求聚合距离最小的场景,设计了一种组内位置隐私协议,通过匿名veto网络和同态加密技术来保护所有人的位置隐私。
综上所述,当前位置隐私保护技术还存在以下不足:在执行保护处理时没有考虑到轨迹信息含有的用户行为模式,处理后的新轨迹则很有可能不符合用户行为模式,而产生这个问题的根本原因则是因为当前没有考虑到各个位置类别的转移;对于发布的轨迹数据无法保证轨迹数据可用性,而通过保持轨迹特征则能有效保证数据可用性。
2 预备知识和问题定义
在本文中,每个位置li都有其对应的位置名称和位置类别c(li),而用户轨迹集合中曾出现的所有位置类别将组成位置类别集C,其中第i个类别被表示为C[i]。推演技术将使用到轨迹数据中的移动规则用rule表示。假设front,back和λ都是用户曾经过的位置,那么front→back则代表着用户曾在一条轨迹中先后经过front和back两个位置。相似地,front→back⟹λ代表着用户曾在一条轨迹中的先后经过front和back的途中还经过了λ这个位置。已知移动规则rule和轨迹集T,那么T关于rule的支持轨迹集被表示为ST,rule,它是T的子集,且其中的每条轨迹都满足移动规则rule,它所包括的所有轨迹总数为|ST,rule|。
定义1 (隐式位置访问):已知用户的某条轨迹t和t对应的实际访问轨迹tTURE,假设t中满足移动规则front→back,而tTURE却还能满足移动规则front→back⟹λ,那么此时就称轨迹t有移动规则front→back下的隐式位置访问λ[1]。
定义2 (泄露概率):已知对用户敏感的位置λ和关于该用户的轨迹集T,那么关于隐式位置访问λ的泄露概率被表示为[1]:
(1)
公式的分子部分是关于移动规则front→back⟹λ的支持轨迹集ST,front→back⟹λ,称为推测轨迹集。公式的分母部分是关于移动规则front→back的支持轨迹集ST,front→back,称为条件轨迹集。此公式作为隐式位置隐私推演的基准公式。推测轨迹集和条件轨迹集的集合大小,分别称为推测轨迹的支持度和条件轨迹的支持度。该公式的求值称为隐式位置访问λ关于移动规则front→back的置信度。
定义3 (类别转移概率):已知关于用户u的位置类别集C,和两个用户访问过的位置li和lj,它们的位置类别分别是c(li)和c(lj),那么类别从c(li)转移到c(lj)的类别转移概率计算为:
(2)
其中|c(li)→c(lj)|代表着从位置类别c(li)转移到c(lj)的转移频度,是指在用户的轨迹集合中,发生过的从属类别是c(li)的位置转移到从属类型是c(lj)的位置的转移总次数,注意li和lj在轨迹中一定具有时间先后顺序和连续性。同理|c(li)→C|代表着从位置类别c(li)转移到所有类别的转移频度。
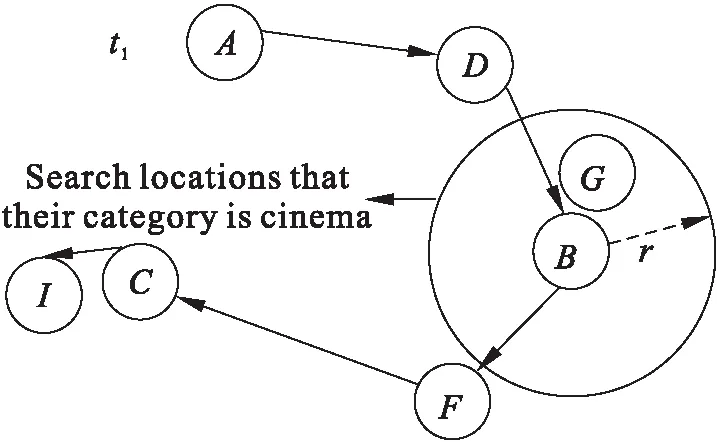
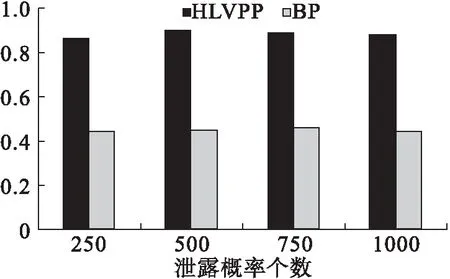
定义4 (特征序列与轨迹特征点):已知轨迹t=l1→…→ln,那么其对应的特征序列为tchar=[lc1,lc2,lc3,…,lcpar-1,lcpar],其中c1=1,cpar=n且c1 每条轨迹都有其对应的轨迹特征,代表了其主要的运动特征,如图4所示,图中的实线代表轨迹本身,而虚线则代表其对应的轨迹特征。轨迹特征点是原轨迹中某些特定的能够代表轨迹运动特征的点,连接轨迹特征点便形成了轨迹特征,在图例中,lc1、lc2、lc3和lc4便是原轨迹的特征点,在图中用空心点来表示。通过算法3中的最小描述长度优化原则来获得轨迹的特征序列。 图4 轨迹及其对应轨迹特征 定义5 (轨迹特征保持):已知一条轨迹t,一个在t中的位置L的序号为i以及t对应轨迹特征tchar,那么在替换位置L为L′后,称此时有轨迹特征保持当且仅当新的轨迹特征tchar′等于: (3) 问题1 (隐式位置访问隐私安全问题):已知特定用户的轨迹数据集T、用户自定义设置的敏感位置集SenLoc和泄露概率最大。允许阈值δ,通过位置替换和位置抑制两种方法对轨迹数据集的特定轨迹进行匿名,使所有泄露概率降低到δ以下,同时使得匿名轨迹符合用户行为模式和保持轨迹特征。 提出一种隐式位置访问隐私保护算法(Hidden Location Visit Privacy Protection,HLVPP),具体过程如算法1所示。算法1基本思想是针对每条泄露概率的推测轨迹和条件轨迹的构成,对特定轨迹执行位置替换或位置抑制来匿名化轨迹,最终使泄露概率减小到用户允许阈值;替换位置时通过考虑用户行为模式,使位置替换后位置类别转移概率最大。同时关注原轨迹的轨迹特征是否改变,为提高算法的执行效率和合理性,通过局部轨迹拓展规则来检测轨迹特征的保持。 算法1隐式位置访问隐私保护算法(Hidden Location Visit Privacy Protection) 输入:特定用户的轨迹数据集T,用户设置的敏感位置集SenLoc,阈值δ. 输出:匿名化后的轨迹数据集T. 1.Get the Leakage Probability Set PSet; 3.For tinST,front→back⟹λdo 4.Decrease_Speculation(t,λ,r); 5.frontAround = front.around(r); 6.backAround = back.around(r); 7.For t inST,front→backAround⟹λor frontAround→back⟹λdo 8.Add_Condition(t,front,back,frontAround,backAround); 9.For tinST,front→back⟹λdo 10.t.Suppression(λ); 11.ReturnT; 算法1首先根据输入参数执行推演攻击,并返回泄露概率集PSet(1行)。整个算法的外层循环中,可以分成三个子模块——通过位置替换来减小推测轨迹集(3-4行)、通过位置替换来增加条件轨迹(5-8行)、通过位置抑制来减小推测轨迹集(9-10行),它们的优先度依次降低。一旦概率数值降低到用户允许阈值δ之下,则退出子模块所在循环,并继续外层循环以处理下一条泄露概率。r代表着执行位置替换时原始位置与替换位置之间允许的最大欧式距离,通过实验证明当r选取300米时能使寻找替换目标时获得最大的收益。 在第一个子模块中,推测轨迹集中的每条轨迹会被循环遍历,每当成功执行一次位置替换,推测轨迹集大小将减1。Decrease_Speculation函数的步骤如下:(i)算法2被执行以获得关于替换位置λ的优先位置类别,其中包含各个位置类别以及对应的类别转移概率;(ii)根据优先位置类别依次搜索属于特定类别且距离λ小于r的位置集。最后一次搜索则无类别限制,且位置集中将去掉敏感位置;(iii)依次将(ii)步骤中返回结果作为替换位置分别执行位置替换,并执行算法3;(iv)如果(iii)步骤返回结果为真,那么执行当前的位置替换并终止函数,否则(ii)、(iii)和(iv)将重复执行。如图5所示,将位置B视为被替换位置,第一次搜索过程中将会搜索到所属类别为cinema的位置G作为返回,然后再检测若替换位置为G时是否能使轨迹特征保持。 图5 对t_1执行Decrease_Speculation函数 在第二个子模块中,front.around(r)将返回距离front小于r的位置集,并将其称为frontAround,back.around(r)与backAround同理。ST,front→backAround⟹λ or frontAround→back⟹λ代表的是类条件轨迹集,其中每条轨迹并不是条件轨迹,并且其中不会包括敏感位置λ,但通过替换其中一个位置为front或者back后就可以成为一个条件轨迹。执行位置替换后条件轨迹集大小加1。 Add_Condition函数的步骤如下(这里只介绍此函数处理ST,front→backAround⟹λ轨迹集中的轨迹时的步骤,因为对另一种轨迹集ST,frontAround→back⟹λ的轨迹的处理步骤是完全类似的):(i)根据backAround位置集的每个位置loc,分别替换为back后执行算法3;(ii)如果步骤(i)返回结果为真,且当前还没有某个位置将可能会替换为back的记录,则将c(back)在算法2返回的优先位置类别集中的类别转移概率和当前位置loc记录作record;(iii)如果步骤(i)返回结果为真,且已有记录record,则在c(back)的类别转移概率更高的情况更新record,否则不更新;(iv)在遍历位置集的过程中,(ii)(iii)将会被重复执行,遍历完成后如果record存在,那么记录的位置loc将会被替换为back。如图6所示,在分别将E和I替换为C后,将执行算法3判断二者是否都能使轨迹特征保持。 图6 对t_4执行Add_Condition函数 在第三个子模块中,Suppression函数将会对一条推测轨迹中的敏感位置执行位置抑制操作,执行后,推测轨迹将会退化为一个条件轨迹。此时,推测轨迹集大小减1,条件轨迹集大小不变。如图7所示,t2作为一条推测轨迹,其中的敏感位置B将会被删除,所以t2将不再是一条推测轨迹。 图7 对t2执行Suppression函数 HLVPP算法中将使用到子算法——位置类别优先级算法,具体过程如算法2所示。算法2基本思想是通过建立概率转移矩阵返回替换位置的可能类别及其对应的类别转移概率,返回结果作为替换位置选择策略。 算法2位置类别优先级算法 输入:轨迹数据集T,位置类别集C,被替换位置L. 输出:数组Category-Priority. 1.MN×N,CountNare created; 2.For eachtinTDo 3.Ift.length>= 2 4. Fori←1 tot.length -1 Do 5.Countc(t[i]).index++; 6.Mc(t[i]).index,c(t[i+1]).index++; 7.Get_Probability(); 8.Fori←1 toNDo 9.prob=MprevIndex,i×Mi,nextIndex; 10.Category-Priority.add(Category[i] ,prob); 11.Category-Priority.DeleteZero_Sort(); 12.Return Category-Priority; 算法2中N为C的大小,概率转移矩阵MN×N和转移计数器CountN被初始化(1行),每个元素都为0。遍历轨迹集中的每条轨迹,根据轨迹中的每次转移对矩阵和计数器进行加1操作(2-6行)。Get_Probability函数将概率转移矩阵元素Mi,j除以Counti得到的数值赋值给Mi,j(7行),这样矩阵的每个元素就代表着C[i]到C[j]的类别转移概率。prevIndex代表L之前经过prev位置的类别在C中的索引,nextIndex代表L之后经过next位置的类别在C中的索引。prob将计算出替换位置可能类别的联乘类别转移概率。DeleteZero_Sort函数将删除数组中概率为零的位置类别,然后从大到小进行排序(11行)。如图8所示,将t1中的B当作被替换位置,那么优先搜索类别为cinema的替换位置,以图1轨迹数据执行本算法,得到各个类别转移概率:从restaurant转移到cinema的概率为0.33,从cinema转移到convenience的概率为0.5,再根据以上数据得到从restaurant转移到cinema再到convenience的联乘概率为0.33。 图8 t1中B的替换位置的类别优先级 HLVPP算法中也将使用到子算法——检测轨迹特征保持算法,具体过程如算法3所示。算法3基本思想是通过最小描述长度(minimum description length,简称MDL)优化的概念获得位置替换前后的轨迹特征序列,从而检测轨迹特征是否能够保持。MDL由两组件构成[17]:L(H)和L(D|H),其中H代表某种假设,而D代表数据。而MDL优先则是指得到一个最好的假设H来解释D,使得L(H)和L(D|H)的总数据量最小。文献[18]中使用了MDL规则得到轨迹的特征序列,其中L(H)对应轨迹的一种特定轨迹特征的长度,L(D|H)则代表轨迹与轨迹特征之间的总差异量。 算法3检测轨迹特征保持算法 输入:特定轨迹t,被替换位置L,替换位置L′. 输出:布尔值true或者false. 1.i=t.index(L); 2.range,ChaSe,indexPairs=Part_Traj_Char(t,i); 3.t[i]=L′; 4.indexPairs.Delete_About(i); 5.NewChaSe,MDLCost =Get_ChaSe(t,range,indexPairs); 6.ReturnCheck_Preservation (ChaSe,NewChaSe); 算法3首先获得了L在轨迹t中的索引i(1行)。Part_Traj_Char函数将通过局部轨迹拓展原则来计算替换位置周围局部轨迹的特征序列,返回的range为局部轨迹索引范围,ChaSe为对应特征序列,indexPairs的每个元素存储一个索引对形如(j,k)以及从t[j]到t[k]的部分轨迹的MDL消耗(2行)。执行位置替换后(3行),将indexPairs中索引范围包括了i的索引对进行剔除(4行),在第5行执行Get_ChaSe函数,将计算range范围内的t的局部轨迹在最小描述长度优化规则下求得的轨迹特征序列。Check_Preservation函数将检测位置替换后能否保持轨迹特征,如果符合则返回true,否则返回false。图9展示了局部轨迹拓展方法,以当前隐式位置访问为中心往轨迹的两端进行延伸,每次拓展后进行计算,当对应的MDL消耗除以拓展次数的数值大于上一次拓展,或者已经到达轨迹两端时,拓展停止。 本文对提出的隐式位置访问隐私保护算法的有效性进行评估。在实验过程中,选取两个真实数据集Brightkite和Gowalla进行实验和分析。 Brightkite和Gowalla是来自斯坦福大学公开的两个轨迹数据集,其中包括了用户的签到位置信息。在实验前,对两个数据集都进行了预处理,剔除掉美国加州地区以外的信息,表1为实验数据集的统计信息。 图9 在轨迹t1上的局部轨迹拓展 表1 实验数据集统计信息 实验软硬件环境如下: (1)硬件环境:Intel Core i5 3.20GHz,4GB DRAM内存. (2) 操作系统平台:Microsoft Windows 10. (3) 编程环境:Python 3.6,Spyder 3.2.6. 为了进行对比,本文将文献[19]中的位置替换算法进行了实现,记作BP。在实验中为每个用户分配随机的敏感位置集,并将用户允许的最大泄露概率设为0.5,通过推演泄露概率算法获所有可能的泄露概率,然后再从中挑选1000个泄露概率。根据每个用户关联的所有泄露概率,分别执行本文算法后将使所有泄露概率数值均小于阈值,即用户的隐式位置访问隐私得到了保护。 本文采用以下三个标准衡量保护结果。 (3) 运行时间:算法处理运行的总时间。 优先类别概率结果如图10所示,在两个数据集上,HLVPP算法的优先类别概率都要远高于BP算法,这是由于BP算法中简单地挑选替换位置的规则而替换位置根本没有考虑到用户行为模式,HLVPP算法则优先搜索属于优先类别的位置候选集。其中HLVPP算法的优先类别概率基本稳定在90%,而BP算法则在31%左右上下浮动。从两个数据集上的比较来看,Gowalla数据集要略高于Brightkite数据集,这是因为在Gowalla数据集中的位置分布密度要略高于Brightkite数据集。 图10 优先类别概率 特征保持概率结果如图11所示,在两个数据集上,HLVPP算法的特征保持概率都要远高于BP算法。这是由于BP算法只是从离原始位置一定范围内随机选择替换位置,这样会使得替换位置大概率不满足轨迹特征的保持条件,而HLVPP算法每个替换位置都经过了特征保持的检验。其中HLVPP算法的特征保持概率基本稳定在91%,而BP算法也是在46%左右稳定。 图11 特征保持概率 运行时间结果如图12所示,HLVPP算法在两个数据集的表现都比较稳定,平均运行时间为198ms;而BP算法由于需要执行的计算较少,所以平均运行时间为23ms。 图12 运行时间 本文针对隐式位置访问隐私保护问题进行研究,提出了一种隐式位置访问隐私保护算法(HLVPP算法),通过位置替换与位置抑制技术针对性地对特定轨迹进行匿名化处理。通过位置类别优先级算法和检测轨迹特征保持算法使得匿名轨迹能够符合用户行为模式且保持轨迹特征。基于真实轨迹数据集进行实验,结果表明HLVPP算法能够有效保护隐式位置访问隐私免受推演攻击,同时保持轨迹数据高可用性。
3 隐式位置访问隐私保护



4 实验
4.1 实验设置


4.2 实验结果分析



5 结论
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05 06:49:10
中学生数理化·中考版(2021年6期)2021-11-22 07:52:30
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
新世纪智能(数学备考)(2021年4期)2021-08-06 09:04:50
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
现代装饰(2018年5期)2018-05-26 09:09:39
中国三峡(2017年2期)2017-06-09 08:15:29
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
