
社会科学视野中的“大数据”研究现状分析
2019-05-15 09:47:44刘玮马续补秦春秀陈颖
西安电子科技大学学报(社会科学版) 2019年1期
刘玮,马续补,秦春秀,陈颖
(西安电子科技大学经济与管理学院,陕西 西安 710071)
伴随着云计算、社交网络、移动商务、物联网等新兴信息技术的快速渗透,数据量急剧增长,大数据已经成为新一代信息技术的核心与竞争前沿[1]。大数据技术和大数据分析已经被成功应用于许多领域,如健康医疗、商业分析、互联网金融、社交媒体用户行为分析、舆情分析、电子商务以及制造业等[2]。大数据研究已经成为学术界和产业界最热门的主题之一。大数据应用是大数据 5个基础研究方向之一,是科研项目关注最多的方向,包括各学科、各领域的基于数据的新方法、新范式、新理论等,用于支撑基于大数据的科学研究方法、社会发展方式、经济建设模式和国防安全手段[3]。社会科学的各个领域是大数据研究重要的应用场景,也是大数据解释阶段的主要依据,大数据是社会科学研究面临的机遇和挑战。
White、Luo、Gu等学者采用文献计量方法分析了医疗领域大数据研究的规律[4-6],国内学者采用文献计量方法分析了计算机领域、经济管理领域的大数据研究现状[7-8],对大数据工具、大数据应用、大数据可视化等具体问题进行文献计量分析[9-11]。现有研究多关注某个特定研究主题或具体学科中大数据研究规律,本文尝试对包含诸多具体学科的广义的社会科学领域大数据研究现状进行分析,以辨别大数据研究在整个社会科学中的发展规律和知识基础。
一、数据来源和研究方法
(一)数据来源
科学文献是科学活动的主要产出形式,也是科学计量和文献计量研究的重要数据来源。学术期刊是发表研究成果、进行学术交流、获得学术地位的重要媒介[12]。考虑我国社会科学研究现状,学者更擅长母语写作[13-14],因此本文采用多个文献数据库作为国内和国际社会科学大数据研究现状分析的数据来源。通过对期刊论文的文献计量分析,发现研究特点和规律。英文文献数据来自WOS(Web of Science)的社会科学引文索引(Social Sciences Citation Index,SSCI);中文文献数据来自中文社会科学引文索引(Chinese Social Sciences Citation Index,CSSCI)和中国知网(CNKI)。
选择“big data”和“大数据”作为检索词,数据库检索时间是2019年1月20日。在SSCI中检索主题=“big data”,得到4320篇文献,为数据集1;在CSSCI中检索标题=“大数据”或关键词=“大数据”,得到3132篇文献,为数据集2;在CNKI中检索标题=“大数据”或关键词=“大数据”,且来源类别为CSSCI,得到5010篇文献,为数据集3,作为分析时的马充数据。表1列出了数据集1和2的具体数值。
(二)研究方法和工具
波普尔的“三个世界”学说和科学计量之父普赖斯的科学学理论,解释了科学计量和文献计量能够帮助人们通过对特定领域文献(集合)进行计量,绘制、生成和解读知识图谱,从而改变人类打开世界的方式[15]。文献计量和科学计量方法已经被广泛应用于科学学和科研管理等研究领域。本文通过对社会科学大数据研究的文献计量分析,梳理了大数据研究现状和发展规律;通过对引文来源聚类,分析了社会科学大数据研究的知识基础;通过分析不同数据源,对比了国内外研究的异同。主要采用引文分析和共被引分析方法,使用了VOSviewer和HisCite软件工具。
引文分析法是文献计量和科学计量领域广泛使用的方法[16]。引文分析法的基本假设是科学研究的积累性、连马性和继承性,具体表现为文献之间的引用和被引用关系。文献的引用和被引用,使得大量文献分群聚类,构成文献聚类、学科聚类分析的理论基础。
HisCite是科学引文索引(Science Citation Index,SCI)创始人加菲尔德开发的文献计量可视化软件,能够用图示的方式展示文献之间的引用关系,绘制出某研究领域的发展历史,找到该领域的重要文献以及最新的重要文献[17]。
VOSviewer是Van Eck N J和Waltman L开发的绘制文献图谱的软件工具,通过相似度计算、VOS绘图技术和转换、旋转和映射,该工具能清晰展示文献计量中的共现关系,是一款能用于较大规模数据集合的文献计量可视化分析工具[18]。
二、结果分析与讨论
(一)文献增长分析
通过文献数量的增长变化规律来判断和预测科学知识的增长状况,继而探索科学发展规律是科学史和科学学研究中常用的方法[16]。普赖斯指数模型和逻辑模型是两个重要的文献增长模型。分析1990-2015年之间WOS数据库中“大数据应用”相关文献的数量分布[10],可认为该领域文献在2012-2015年之间符合普赖斯指数增长规律。

表1:社会科学大数据研究文献数量分布
对表1的数据进行文献增长分析,取累积量为纵轴,时间为横轴,实线为实际观测值,虚线为拟合后的指数曲线。数据集1和2的指数模型拟合效果最好,R2>0.9,数据集1的指数拟合见图1。文献数量变化符合指数增长模型和逻辑模型的前期增长阶段。
图1中,2017年文献累积量的实际值略低于预测值,2018年的文献累积量明显低于预测值,是否意味着2017年之后文献增长速度降低呢?我们对比了2018年2月以同样检索条件获得的数据集,指数拟合曲线见图2。对比两个图的变化,我们认为观测值低于预测值主要因为文献数据库更新时滞,是否出现文献增长加速度变缓即出现逻辑模型的拐点,还需要更长时间的观察。这个现象在CSSCI的检索结果中同样出现。因此,大数据研究仍处于加速增长期,大数据还在继马向社会科学研究的各个领域渗透。

图1:大数据相关文献的增长曲线(2019.1)
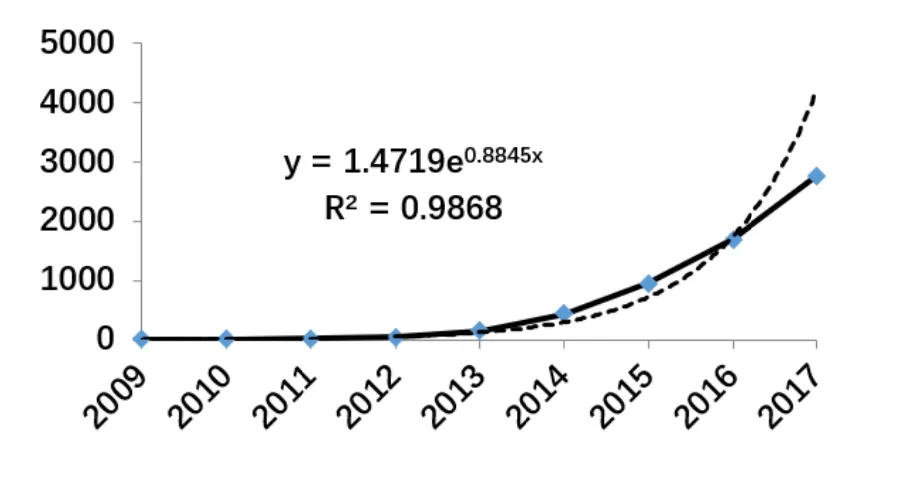
图2:大数据相关文献的增长曲线(2018.2)
(二)学科分布分析
SSCI和CSSCI均包括社会科学中的诸多具体学科,大数据对各个具体学科的渗透程度不同。表2列出数据集1中发文最多的7个类别,考虑源刊数量,文献在类别1中的集中度最高。类别3和5属于SCIE,原因是部分期刊属于双检索,如MISQUARTERLY。在SSCI和SCIE中,一个期刊可以属于多个类别,如MIS QUARTERLY同时属于表2中的类别1/2/3,因此,表2中各类别的文献量之间存在重复统计。尽管如此,依然可认为SSCI中大数据研究文献产出主要集中在7个类别,其中属于SSCI的类别有5个,INFORMATION SCIENCE & LIBRARY SCIENCE领域产生的大数据研究文献最多。

表2:SSCI文献的学科类别分布(数据集1)

表3:CSSCI中文献的学科类别分布(数据集2)
表3列出了数据集2中发文最多的5个学科。同样考虑源刊数量,文献在类别1中的集中度最高,即中文CSSCI数据库中,来自图书馆、情报与文献学的大数据研究文献最多。
(三)机构及其影响力分析
为了识别国内和国际在社会科学大数据研究中的主要发文机构及其影响力,我们对各研究机构的发文量和被引量进行统计。对数据集1的发文机构进行统计,即截止2019年1月发文数量最多的10个机构及其发文量,见图 3。UNIVERSITY OF CALIFORNIA SYSTEM 发文量最多,UNIVERSITY OF LONDON紧随其后,中科院和武汉大学分别居第4和第9位。
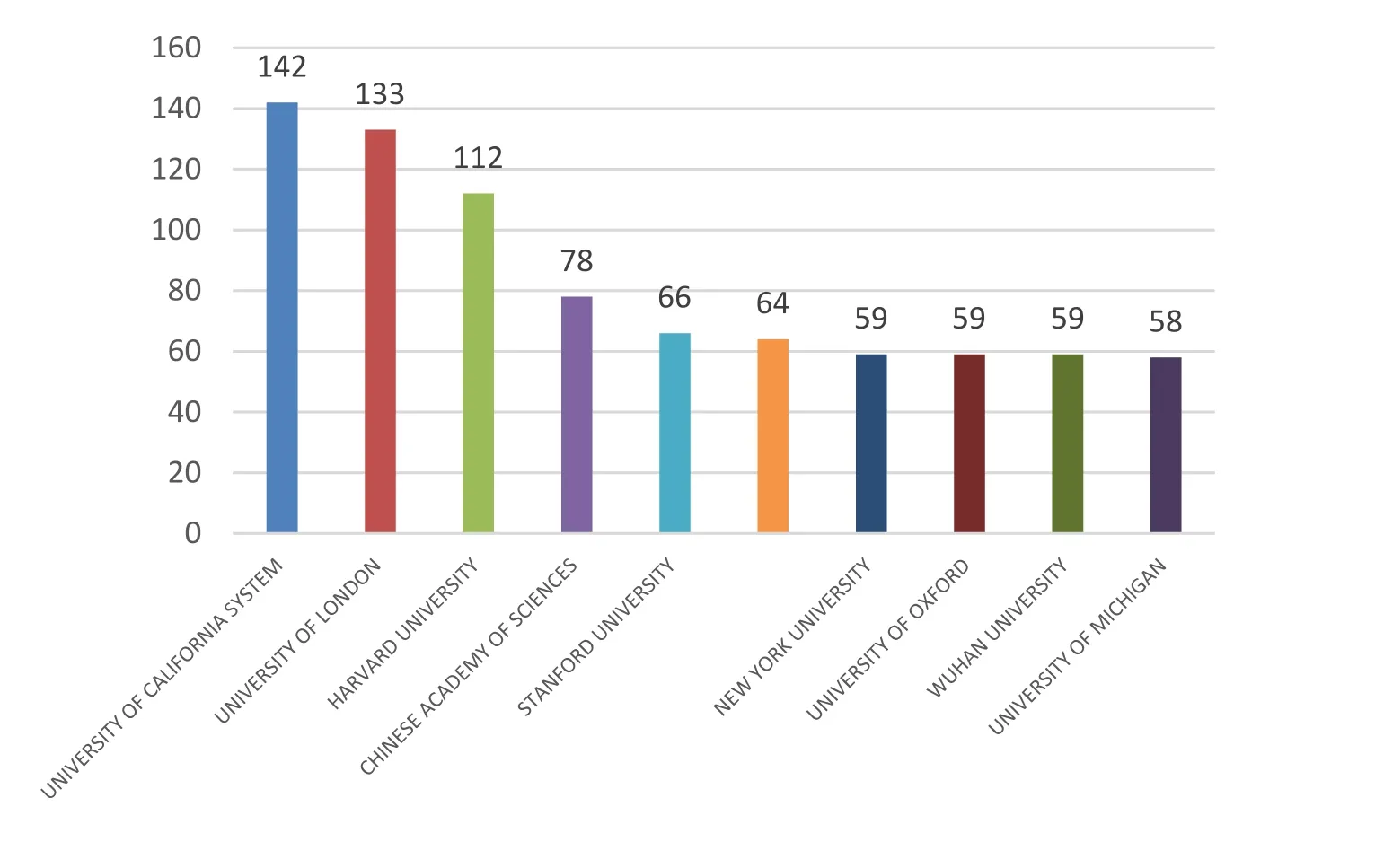
图3: SSCI中发文量最多的10个研究机构
引用通常被作为衡量科学研究成果影响力的重要指标之一。HisCite采用LCS(local Citation Score)和GCS(Global Citation Score)两个引用指标测量一篇文献在当前数据库和所有WOS数据库中的被引数量,可认为是该文献在本领域和整个学术界的影响力[17]。数据集1导入HisCite,统计数据集1中研究机构的论文数量和被引情况。由于文献被引用存在时滞,且文献发表后不一定被引用,表4的论文数量不大于图3的数量。表4列出被引文献数量不少于36篇的机构。LCS引用最高的是MIT、哈佛大学和宾夕法尼亚大学。MIT的篇均被引达到12.4,以0.9%的文献数量获得了6.5%的LCS引用。GCS引用最高的是哈佛大学和MIT,篇均被引约36。中科院由2018年同期的第7位升至第3位,但篇均LCS被引不到0.5。武汉大学由第16位升至第6位,篇均LCS被引约0.75。清华大学由第19名升至第12位,篇均被引不到0.4。
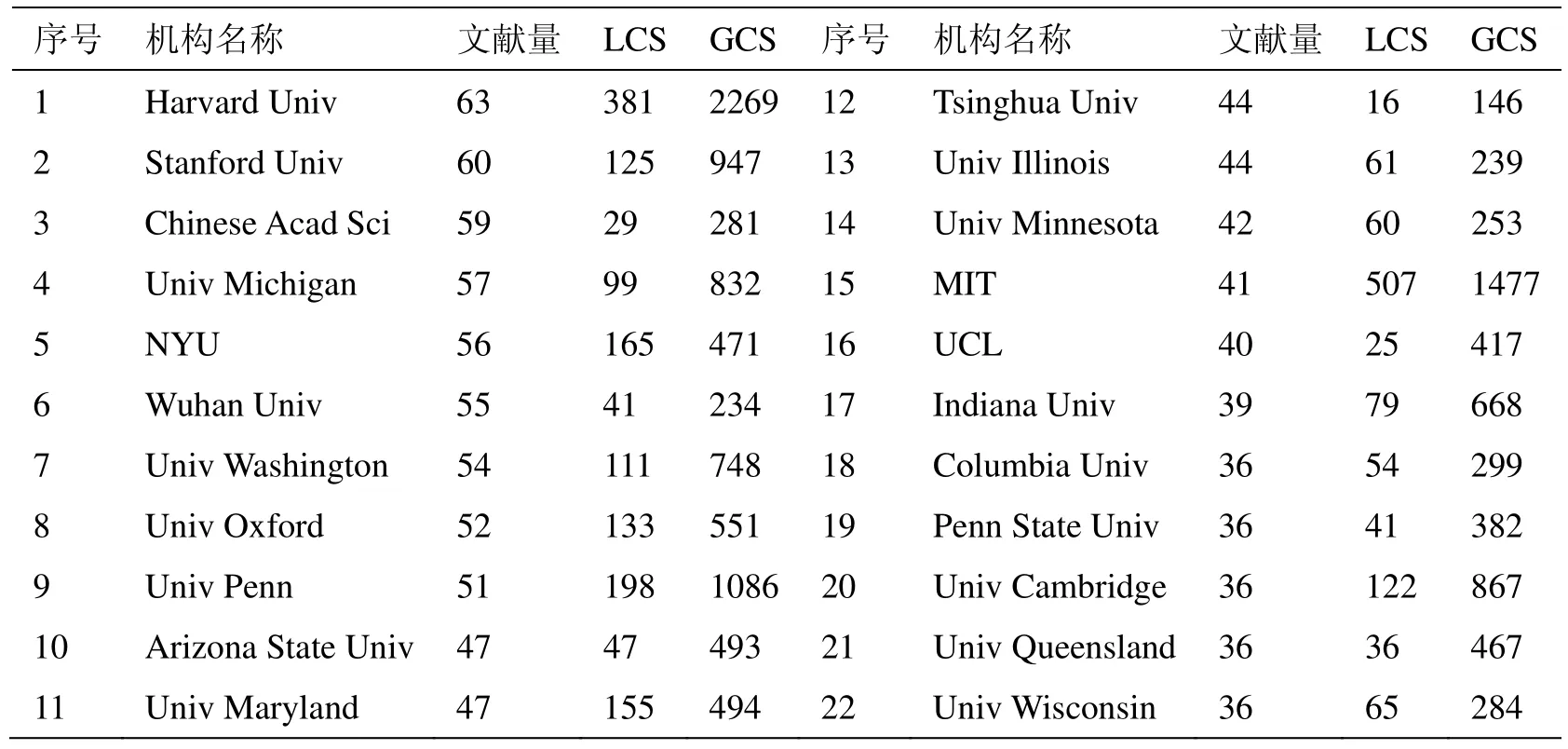
表4:主要发文机构和被引情况(SSCI)
检索CNKI数据库得到数据集3,统计其发文最多的8个机构及其文献被引用数量,如表5所示。中国人民大学在社会科学领域的研究成果产出不仅数量多,而且影响力显著高于其他高校。
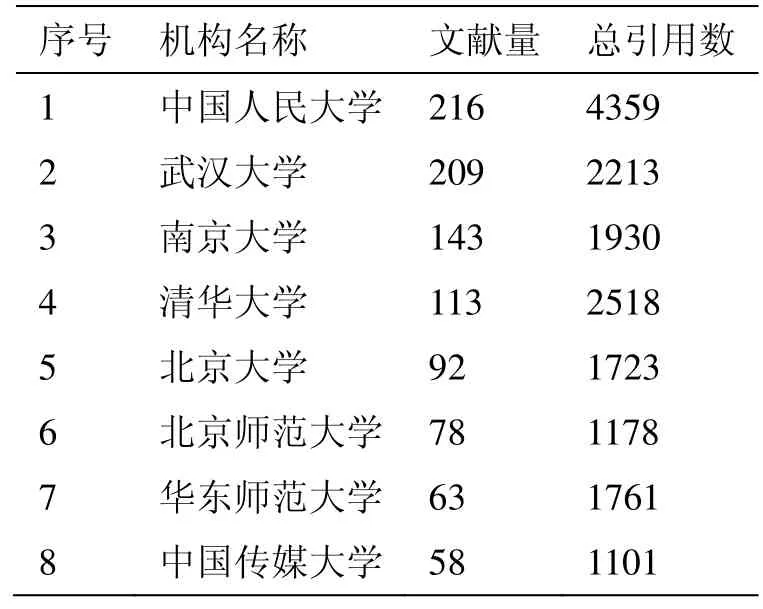
表5:主要发文机构及引用情况(CSSCI)
(四)知识基础分析
Kuhn认为,科学范式是某个学科领域中公认的重要的概念[19]。文献引用关系和共被引网络能反映知识继承、传递和发展脉络,能刻画出学科结构、特征和演化过程。陈超美认为,知识基础(INTELLECTUAL BASE)是研究前沿所指向的引证文献[20]。知识基础由前期研究内容和某个领域的结构组成,知识基础对于更好的理解研究前沿很重要[21]。本文采用陈超美对于研究前沿和知识基础的定义,通过引文关系和共被引聚类分析社科领域大数据研究的知识基础,并通过研究前沿和知识基础的关系分析社会科学领域大数据研究的特点和规律。如图4所示,研究前沿即通过检索获得的数据集,而知识基础是研究前沿指向的引证文献的共被引聚类。本文在分析中主要以社会科学中的具体学科为分析对象,将数据集1和2分别导入VOSviewer,对知识基础的来源期刊(引文来源)聚类。

图4:研究前沿和研究基础的关系
1.基于SSCI的知识基础分析
对数据集1进行分析,选择被引次数大于120次的230种引文来源,根据共被引强度进行聚类,聚成6类,如图5所示。分别是红色区域(区域1,68个节点),绿色区域(区域4和5,共43个节点),蓝色区域(区域2,37个节点),黄色区域(区域6,35个节点),紫色区域(区域3,31个节点),青色区域(16个节点,比较分散)。区域1包括了表2中属于类别1/2/3/4的期刊;区域4包括了多学科科学期刊;区域5是医学类期刊;区域2以计算机类期刊为主,包括了表2中类别2/5的期刊;区域3以交通、地理、环境类期刊为主,包括表2中类别6的期刊;区域6以新闻、传播类报刊为主,表2中类别7的期刊出现在黄色区域。
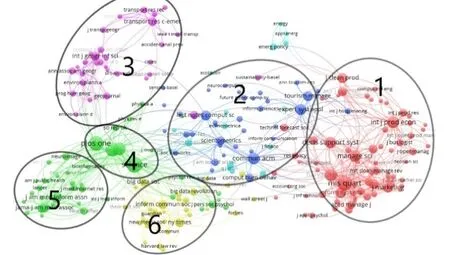
图5:基于SSCI的知识基础聚类
图5中,较大节点表示该引文来源被引次数较高,节点之间的连线和距离表示两个引文来源之间的共被引强度。分析高被引文献来源和聚类结果,可以发现以下特征:(1)在社会科学大数据研究中,有六大知识基础。第一,INFORMATION SCIENCE & LIBRARY SCIENCE、MANAGEMENT、COMPUTER SCIENCE & INFORMATION SYSTEMS和BUSINESS,这些学科期刊被引次数多,共被引强度高,共同构成了社会科学大数据研究在信息科学图书馆学、管理学、信息系统和商业领域的重要知识基础。第二,计算机通信相关的期刊中介性强,通常与其他学科的文献一起被引用,构成了社会科学大数据研究的技术基础。第三,交通、环境类期刊构成了地理类大数据研究的重要知识基础;第四,science、plos one、nature和 p natl acad sci usa属于高被引期刊 TOP5(第 5个是 MIS QUARTERLY),是 SCIE中的multidisciplinary sciences期刊,共同构成了社会科学大数据研究的核心知识基础;第五,医学类期刊仅与第四部分联系紧密,构成了医学大数据研究的重要知识基础;第六,新闻、传播类期刊及其他文献源,构成了媒体大数据研究的重要知识基础。
被引最多的27种文献来源中,有2种不属于SSCI和SCIE收录期刊,双检索4种,只被SCIE检索13种,只被SSCI检索8种。即通过SSCI检索到的大数据研究文献,代表了社会科学领域当前的研究前沿,其对应的知识基础既来自SSCI的具体研究领域,又广泛的吸收了SCIE的研究成果,特别是计算机通信类和多学科科学类的文献源。
社会科学大数据研究文献更倾向于引用什么?首先,作者倾向于引用本研究领域的论文,表2中的类别1/2/3/4/6/7与图中知识基础聚类有较强的相关性。其中类别1/2/4合计发文占比29.1%,而8种高被引SSCI来源期刊中,属于这三个类别的期刊分别有5种。其次,作者引用非本领域论文,倾向于计算机通信类和多学科科学类文献。
2.基于CSSCI的知识基础分析
对数据集2进行分析,选择被引次数大于20次的57种引文来源,按照共被引强度进行聚类,聚成4类,如图6所示。分别是红色区域(区域1,21个节点),绿色区域(区域2和5,共20个节点),蓝色区域(区域3,9个节点),黄色区域(区域4,7个节点)。
区域1的文献来源除了1种旅游学刊和2种英文期刊,其余18种均属于表3中的类别1,即图书馆、情报和文献学;区域2和5包括计算机通信类期刊、管理学期刊和较多的英文文献源;区域3全部属于表3中类别3,即新闻与传播学期刊;区域4全部属于表3中类别2,即教育学期刊。
图6中,分析高被引文献来源和聚类结果,可以发现:(1)图书馆、情报和文献学期刊是中文社会科学大数据研究的主要知识基础;(2)管理学和计算机通信类期刊具有较高的中介性,构成了中文社会科学大数据研究的重要知识基础;(3)新闻和传播学期刊是大数据研究在媒体行业应用的重要知识基础;(4)教育学期刊是大数据研究在教育行业应用的重要知识基础;(5)Harvard business review、science等英文文献源已经成为中文社会科学大数据研究的知识基础。
被引最多的20种期刊中图书馆、情报和文献学有9种;教育学有1种;新闻和传播学有2种;计算机通信类有3种;多学科期刊1种;其余是英文文献源。即通过CSSCI检索到的大数据研究文献,代表了中文社会科学领域当前的研究前沿,其对应的知识基础既来自社会科学的具体研究领域,又吸收了自然科学的研究成果。
中文社会科学大数据研究文献更倾向于引用什么?首先,作者倾向于引用本研究领域的论文,表3中的类别1/2/3与图6中知识基础聚类有较强的相关性。类别1/2/3合计发文占比51.6%,而20种高被引期刊中,属于这三类的期刊有 12种。其次,图书馆、情报和文献学更倾向于同时引用本学科、计算机通信、多学科、管理学以及英文文献源,其知识基础更广泛。

三、研究结论
(一)大数据是社会科学的研究热点
国内外相关研究成果产出数量表明,社会科学研究对大数据的关注经历了 2012-2014年的爆发期,目前依然处于加速增长期;从高被引论文的引用历史分析,当前的研究更多体现出科学的积累性和继承性,即受范式制约的常规科学阶段。
(二)大数据对社会科学的具体学科渗透程度有差异
CSSCI和SSCI的收录范围广泛,包含较多的具体学科,如法学、管理学、教育学、环境科学、经济学、历史学、新闻与传播学、哲学、心理学、社会学等等。具体学科对大数据问题的关注度有明显差异,SSCI中 INFORMATION SCIENCE & LIBRARY SCIENCE,MANAGEMENT,BUSINESS,ENVIRONMENTAL STUDIES和COMMUNICATION的研究成果最多;CSSCI中图书馆学、情报与文献学,新闻学与传播学,教育学,经济学和法学的研究成果最多。国内和国际社会科学大数据研究在具体学科分布上有共同点,也存在显著差异。图书馆学、情报和文献学与 INFORMATION SCIENCE &LIBRARY SCIENCE是社会科学大数据研究的最重要的力量。
(三)国内、国际社会科学大数据研究的知识基础共性与差异并存
从被引用文献及其来源角度分析,SSCI中大数据研究的知识基础既包含文献高产出的具体类别(即表2中的类1/2/4/6/7既是高文献产出类别,也是高被引文献和知识基础类别);也有来自计算机通信相关的具体学科,特别是IS领域;SCIENCE等多学科科学期刊成为特别突出的公共的知识基础。CSSCI中大数据研究的知识基础包含文献高产出的具体类别(即表3中的类1/2/3既是高文献产出类别,也是高被引文献和知识基础类别);也有来自计算机通信相关的具体学科;中科院院刊、SCIENCE等多学科科学期刊,管理科学学报等管理学期刊成为公共的知识基础。
国内大数据研究的文献产出更加集中在图书馆、情报和文献学,教育学和新闻与传媒学等具体学科(文献产出合计超过50%),高被引文献和知识基础也集中在这三个学科(高被引文献源占12/20)。大数据对于社会科学研究的渗透不够广泛,其知识基础也较局限在这三个领域。国内社会科学大数据研究对于社会科学中其他学科、自然科学领域研究成果的吸收程度不够(数据集1中的TOP27文献源中,来自SCIE的期刊多于来自SSCI的期刊)。
(四)我国社会科学研究成果产出量有显著增长,但国际影响力有待提升
数据集1的资助基金主要来自国家自然科学基金NSFC、美国国家自然科学基金NSF、中央高校基本科研业务费、英国ESRC、美国NIH基金等。数据集2的资助基金主要来自国家社会科学基金和国家自然科学基金,前者是后者的两倍。国家级别的研究基金依然是文献产出最主要资助来源,我国自然科学研究基金、高校基本科研业务费的持马投入在WOS平台已经有显著的成果产出,中科院、武汉大学和清华大学的论文数量已经明显增加,但是被引次数较少,国际影响力不足。中文发表的研究成果主要来自国家社科基金的支持,在国内,中国人民大学的成果数量和影响力最强。
社会科学大数据研究在未来仍是热点,具体学科的大数据应用研究既受到本领域研究的影响,也受到信息技术发展的影响。大数据必然更广更深的影响我国社会科学研究的各个学科。
[1] 王海涛,毛睿,明仲.大数据系统计算技术展望[J].大数据,2018(2):97-104.
[2] KIM G H,TRIMI S, CHUNG J H.Big data applications in the government sector:a comparative analysis among leading countries[J].Commun ACM,2014(3):78-85.
[3] 朱扬勇,熊贇.大数据的若干基础研究方向[J].大数据,2017(2):104-114.
[4] WHITE S.A review of big data in healthcare: challenges and opportunities[J].Open Access Bioinformatics,2014(6):13-18.
[5] LUO J,MIN W,GOPUKUMAR D,et al.Big Data Application in Biomedical Research and Health Care:A Literature Review[J].Biomedical Informatics Insights,2016(8):1-10.
[6] GU D,LI J, LI X,et al.Visualizing the knowledge structure and evolution of big data research in healthcare informatics[J].International Journal of Medical Informatics,2017,98:22-32.
[7] 况俞竹,洪玫,曾嘉彦.基于文献计量的大数据研究现状分析[J].数据挖掘,2016(3):125-137.
[8] 王岑岚,尤建新.大数据文献评述:基于软件Citespace的可视化研究[J].科技管理研究,2017,37(21):180-189.
[9] 赵丹,王晰巍,李嘉兴,等.国内外大数据工具学术论文比较研究——基于文献计量方法[J].情报科学,2016(6):133-137.
[10] 张姣姣,刘云,程旖婕.基于文献计量学定律的大数据应用领域发展规律研究[J].知识管理论坛,2016(5):384-392.
[11] 陈军,谢卫红,陈扬森,等.国内外大数据可视化学术论文比较研究——基于文献计量与 SNA 方法[J].科技管理研究,2017,37(8):44-53.
[12] NO H J,AN Y,PARK Y.A structured approach to explore knowledge flows through technology-based business methods by integrating patent citation analysis and text mining[J].Technological Forecasting & Social Change,2015,97:181-192.
[13] 侯海燕,郭芳琪,孙太安,等.基于 VOSviewer的山东省生物技术领域国内及国际研究现状分析[J].科学与管理,2018,209(2):29-37.
[14] ZHOU P,THIJS B,GLANZEL W,et al. Is China also becoming a giant in social sciences[J].Scientometrics,2009,79(3):593-621.
[15] 陈悦,陈超美,刘则渊,等. CiteSpace知识图谱的方法论功能[J].科学学研究,2015,33(2):242-253.
[16] 邱均平.信息计量学[M].武汉:武汉大学出版社,2007:64.
[17] APRILIYANTI I D,ALON I.Bibliometric analysis of absorptive capacity[J].International Business Review,2017,26(5):896-907.
[18] VAN ECK N J,WALTMAN L.Vosviewer:A Computer Program for Bibliometric BACKHAUS K,KAI L,KOCH M.The Mapping[J].Scientometrics,2010,84(2):523-538.
[19] structure and evolution of business-to-business marketing:A citation and co-citation analysis[J].Industrial Marketing Management,2011,40(6):940-951.
[20] CHEN C.CiteSpace II: Detecting and visualizing emerging trends and transient patterns in scientific literature[J].J Am Soc Inf Sci Technol,2005(3):359-377.
[21] HOCHULL CHOE,DUK HEE LEE,HEE DAE KIM IL WON SEO.Structural properties and inter-organizational knowledge flows of patent citation network:The case of organic solar cells[J].Renewable and Sustainable Energy Reviews,2016,55:361-370.
猜你喜欢
云南社会科学(2022年1期)2022-03-16 06:29:30
河北农业大学学报(社会科学版)(2021年6期)2021-12-29 09:18:36
计测技术(2020年6期)2020-06-09 03:27:32
特别健康(2018年4期)2018-07-03 00:38:26
消费导刊(2017年24期)2018-01-31 01:28:33
数学理论与应用(2016年1期)2016-02-28 09:26:17
新校长(2016年8期)2016-01-10 06:43:59
现代企业(2015年2期)2015-02-28 18:45:02
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
