
神经网络在退化图像复原领域的进展综述
2019-05-14 07:59刘龙飞赖舜男
图学学报 2019年2期
刘龙飞,李 胜,赖舜男
神经网络在退化图像复原领域的进展综述
刘龙飞,李 胜,赖舜男
(北京大学信息科学技术学院,北京 100871)
退化图像复原是图像计算领域中的一个重要的难题。近年来以深度学习为代表的人工智能(AI)技术取得了快速的发展,越来越多的基于神经网络解决退化图像复原的研究工作出现。首先介绍了神经网络进行退化图像还原的主要技术并对图像复原的问题进行分类;然后利用神经网络解决退化图像复原问题中细分的多个主要问题,并对每个问题的当前研究现状与多种基于深度学习网络的解决方法的优势与局限性进行归纳分析,并给出与传统方法的对比。最后介绍了基于对抗神经网络的极限退化图像复原的新方法,并对未来前景进行展望。
退化图像复原;神经网络;对抗网络;人工智能
近年来,以神经网络(neural networks)[1]为代表的深度学习方法为包括退化图像复原在内的计算机图像与视觉各个领域带来了快速的发展。其可以通过网络训练的方式找到退化图像与原图像之间的映射关系,从而进行退化图像的复原。由于良好的复原效果和对不同场景灵活的适应能力已经吸引了越来越多的学者从事相关的研究。在多个退化图像复原的相关细分问题中,基于神经网络方法的复原效果超越了传统方法。神经网络的快速发展为退化图像复原的发展做出了巨大的贡献。
1 退化图像复原问题
图像在形成、记录、处理和传输过程中,由于成像系统、记录设备、传输介质和处理方法的不完善,导致图像质量的下降,造成了图像退化。退化图像分很多种,本文重点介绍神经网络对6种退化图像的复原问题[2-6],图1为不同退化图像的复原效果图[7-10]。

退化图像 复原图像 (a) 图像局部 缺失修复(b) 插值图 像复原(c) 高斯噪声 图像复原(d) 运动模糊 图像复原(e) 黑白图 像着色(f) 低分辨率 图像复原


图2 图像退化/复原过程的模型[12]
2 基于神经网络的退化图像复原技术
HINTON等[13]于2006年提出深度学习的概念。2011年卷积神经网络(convolutionalneuralnetwork,CNN)被应用在图像识别领域,取得的成绩令人瞩目。2015年LECUN等[14]在Nature上刊发了一篇深度学习(deep learning)的综述,标志着深度神经网络不仅在工业界获得了成功,也被学术界所接受。而在图像领域,最出名的无疑是CNN。通常CNN在卷积层之后会接上若干个全连接层,将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以AlexNet[1]为代表的经典CNN结构适用于图像的分类和回归任务,并期望得到整个输入图像的一个数值描述(概率),当AlexNet网络训练ImageNet数据集时输出一个1 000维的向量,其向量表示输入图像属于每一类的概率(经softmax归一化)。在此基础之上,提出了全卷积网络(full convolution network,FCN)[15],自编码器(autoencoder)[16-17]和生成对抗网络(generative adversarial nets,GANs)[18],其是神经网络能够进行退化图像复原的基础。FCN实现了通过神经网络进行图像生成的愿望。自编码器最早是用来进行数据降维,但之后人们发现使用自编码结构的FCN能够对图像的生成的稳定性起到很大的帮助。2014年GOODFELLOW等[18]提出GANs,进一步提高了图像的生成质量。其也是使用神经网络进行退化图像复原的主要技术。
2.1 全卷积网络
FCN[15]对图像进行像素级别的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全连接层加softmax输出)不同,FCN可以接受任意尺寸的输入图像。首先,将输入图像逐层卷积;然后,对最后一个卷积层的特征采用反卷积层进行上采样,使其恢复到输入图像相同的尺寸;最后,使用损失函数计算生成图像的loss值进行反向传播,结构如图3所示。需对每个像素均产生了一个预测,同时保留原始输入图像中的空间信息;在上采样的特征图上进行逐像素分类并计算其softmax分类的损失,相当于每一个像素对应一个训练样本。该网络如UNet[19-20]能实现从一张图片生成另一张图片的功能,即FCN技术是使用神经网络进行以图生成图的基础技术。

图3 全卷积网络模型[6]
2.2 自编码器
自编码器,也称自动编码器[16-17](auto-encoder,AE),其是一种人工神经网络。在无监督学习中用于有效编码。自编码器的目的是通过对一组数据学习得出一种表示(也称表征,编码),通常用于降维。



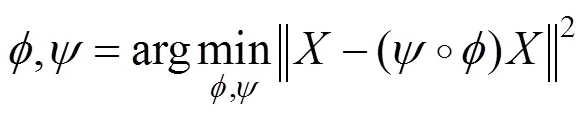
自编码的概念广泛地用于数据的生成模型。如Auto-Encoding Variational Bayes[21]和Generating Faces with Torch[22],其基本原理是输入和输出使用不同的图像。这样自编码器可以根据输入图像生成新的图像。在退化图像复原领域,很多网络如Context Encoders[23],UNet[19]借鉴了自编码器的设计思想并取得了不错的效果。

图4 自编码器网络模型结构
2.3 生成对抗网络
GANs与2014年由GOODFELLOW等[18]在深度卷积网络的基础上提出,且在深度学习领域产生了巨大的轰动。
GANs与普通的CNN相比一个突出的优点是在判别网络与生成网络的博弈下,使生成的图像更加逼真。GANs的核心思想是从训练样本中学习所对应的概率分布,以期根据概率分布函数获取更多的“生成”样本实现数据的扩张[24]。GANs由生成网络和判别网络组成,且网络相互交替学习。“对抗”是该网络的核心,结合了博弈论的零和博弈思想。训练判别网络让其更好地区分真实样本与生成网络生成图像的差别,而训练生成网络,是让生成网络更好地生成图像来“欺骗”判别网络。2个网络通过不断的相互博弈,最终达到让GANs能够生成更加逼真图像的目的。
有时除使用随机噪声图像生成类似真实图像分布的逼真图像外,还需通过得到原图像与退化图像之间的映射关系来生成某些退化图像的原图像,也就是常说的以图生图。此时仅给GANs提供大量完整图像的训练集进行训练显然是不够的,还需要将缺损的图像和对应的完整图像一起提供给网络,让网络学习到其间的一一对应关系。条件生成对抗网络(conditional generative adversarial nets,cGANs)[25]的出现解决了上述问题。
cGANs是在GANs提出不久后由MIRZA和OSINDERO[25]在GANs的基础上进行了改进、设计并提出。条件生成对抗网络(如图5所示为条件生成对抗网络的目标函数)的生成网络和判别网络都基于下述条件信息,即

其中,为生成网络;为判别网络;为损失函数的缩放系数。PATHAK等[23]证明,在cGANs的损失函数中加入传统1或2范数,会进一步提升网络有效性。
在条件生成对抗网络提出不久后,人们便意识到其将会给退化图像复原领域带来巨大的影响,对图像合成和编辑也有广泛的用途[26]。ISOLA等[9]利用条件生成对抗网络技术开发了pix2pix①项目,用于实现一类图像到另一类图像的生成任务,为图像领域的应用带来了新的启发(如图5所示),输入图像经过生成网络得到新生成的图像(),然后分别将()与结合作为负样本,将真实图像与结合作为正样本训练判别网络,让其学习鉴别该图像是否为真实图像。只有网络学习找到缺损图像与完整图像之间的对应关系后,生成网络生成的对应完整图像,才能使与()融合在一起的图像被判别网络认可。该方法为退化图像复原的很多领域打下了基础。
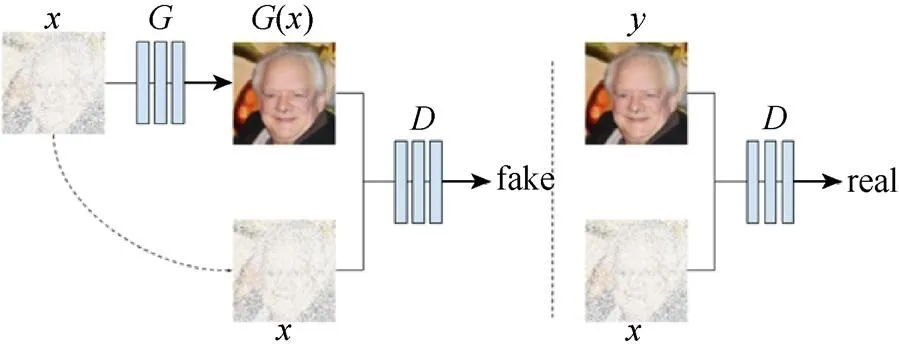
图5 条件生成对抗网络pix2pix的网络模型结构[9]
2.4 自监督学习
自监督学习(self-supervised learning)是一种自主监督学习的方法,能够消除人们对标注数据的依赖。自监督学习方法非常自然的使用了训练数据以及上下文之间的关系或是嵌入元素作为监督信号进行网络训练。其可以是输入数据即为训练目标的类Auto-Encoder[16-17]网络结构,也可以是训练目标即为输入的数据的类循环神经网络结构,甚至可以是输入与输出数据通过某种固定策略相互转换,然后网络目标是学习这种转换规则的逆运算的网络结构等。自监督学习也是目前解决非监督学习难题的有效手段之一。很多神经网络处理退化图像还原问题,如文献[8, 20]等借鉴了自监督学习的思路。神经网络的学习目标往往是清晰的图像,而输入图像往往是退化图像。通常情况采用传统的策略或手段将清晰图像转变为退化图像,而网络的学习目标就是逆向该处理过程,学习如何将退化图像转换为清晰图像。
3 退化图像问题分类及解决方法
3.1 图像局部缺失修复
图像局部缺失修复问题[23,27](image inpainting),是指一张图像中一整片区域或几片区域缺失,而缺失的区域可以是固定的色彩,也可能是随机的色彩,缺失区域的形状也可能是固定形状或随机形状。这些有局部缺失的图像作为神经网络的输入,而原图像作为网络的目标图像,从而进行神经网络的训练。需说明的是,此类问题因为缺失的区域通常很大,所以往往不能通过传统方法[2,28-30]解决。在计算机图形学领域,填充缺失区域一般使用基于场景计算的方法[31],但该方法通常用于修复图像中某个物体缺失的一部分。而使用神经网络技术可以根据整个图像缺失的内容进行复原。评价处理此类问题的难点为:①缺失区域的大小及所占原图的比例;②缺失区域的个数;③缺失的区域形状是否固定;④缺失的区域呈现固定已知的单一颜色还是未知的多种色彩。
表1为近年主要处理图像修补问题文献成果[20,23],文献[23]方法通过在原有2 loss函数的基础上增加Adversarial loss,可以有效地提高图像的修补效果。文献[20]提出了多尺度训练的思路,能够将更大尺寸的图像进行复原并能提高复原的效果。由于该问题的解决是在原图中遮盖或替换较大部分的区域,所以生成的图像不一定需要与原图像内容一致。因此判断图像复原的好坏就不能单一通过客观评价指标(如PSNR值)来衡量,更多的是需要主观评价来衡量。

表1 主流图像修补网络对退化图像处理结果
Context Encoder[23]是最早提出通过合理的参数化算法解决图像缺失问题的算法(图6)。其将缺失图像作为网络的输入图像,经过特征编码和特征解码的过程,生成缺失部分图像。利用生成图像和真实缺失图像计算损失函数,进行网络的反向传播训练。

图6 Context Encoder的网络结构
综上,神经网络已经成为解决图像局部缺失问题的最重要手段,而且已经取得了令人兴奋的效果。尤其是GANs的出现,使复原效果得到了质的飞跃。从某些角度讲,图像局部缺失问题已经成为了GANs的“代名词”。然而,还需面对当图像缺失面积过大,区域过多或是缺失后又有一定其他图片混淆,且神经网络依旧无法复原出令人满意的效果的情况。
3.2 像素插值与图像去噪
像素插值复原问题[7,32](pixel interpolation),是指原始图像被其他颜色以像素为单位有规律或无规律的插入。神经网络处理像素差值复原的过程为:先将原图像的随机像素位置替换为固定或随机颜色,然后将生成的图像作为神经网络的输入图像,原图像为神经网络的目标图像。该问题的关键是被插入像素占原图像的比例(通常比例较大)大小,被插入像素的位置是否遵循一定的规律,以及被插入像素的颜色是固定的单一颜色还是未知的多种颜色等。此类问题在CT图片复原等方面有着重要的实用意义,但针对该问题的研究并不很多,只是作为图像重建方法的附带功能,更多的研究集中在图像的去噪问题上。
图像去噪[33-43](image denoising)是指减少图像中噪声像素的过程,也可以被看作是图像插值复原问题的一种特例,由于在现实中十分常见,而被单独提出来,作为一类研究。噪声概率密度函数(probability density function,PDF)包括:高斯噪声、瑞利噪声、伽马噪声、指数噪声、均匀噪声和椒盐噪声等。通常处理比较多的是加性高斯白噪声(additive white Gaussian noise,AWGN)和椒盐(脉冲)噪声(salt and pepper noise),AWGN是将符合零均值分布的高斯噪声添加到原图像上,噪声级别根据高斯分布的方差决定,的取值通常在75以内。而椒盐噪声,又称为双极脉冲噪声或散粒噪声、尖峰噪声;噪声脉冲可以为正也可以为负。与图像信号的强度相比,脉冲污染通常较大,所以在一幅图像中脉冲噪声通常被数字化为最大值(纯黑或纯白)。由于这一结果,负脉冲以一个黑点(胡椒点)出现,而正脉冲则以白点(盐粒点)出现在图像中。噪声级别是根据插入椒盐噪声的像素占图像整体的百分比决定的,通常情况下噪声所占比例不会超过75%。
表2对比了几个比较流行的使用神经网络在不同数据集上进行去噪PSNR值。由表2可以看出,在神经网络提出之前就有很多学者从事图像去噪的相关工作。而近些年使用神经网络进行图像去噪的工作,不断地取得突破。JAIN和SEUNG[43]建议使用CNN进行图像去噪,并证明CNN可以达到甚至超越MRF模型且具有更好的复原能力。此外,文献[39]成功将多层感知机应用于图像降噪中;文献[42]还将稀疏自编码器引到图像去噪问题中,并取得了与K-SVD相近的效果。文献[40]使用基于非线性反应扩散(TNRD)模型,用前馈神经网络对使用稀疏编码的传统迭代方法进行扩展,然后通过使用固定步数的梯度下降来加速模型推理的性能。然而,TNRD模型也存在局限性,其采用的先例是基于分析模型,而该模型在捕获图像结构的全部特征方面有限,因此限制了TNRD的作用。然而,与BM3D相比,TNRD具有较高的性能优势。而且TNRD与MLP相结合可达到与BM3D相近的处理效果。

表2 主流图像去噪网络对退化图像处理结果
(注:表中数据为高斯方差为50的噪声图复原结果与原图计算的PSNR值)
综上所述,神经网络之所以在图像去噪领域有着不错的效果得益于机器学习的模式,对图像去噪有较好的泛化能力。神经网络不但能处理固定噪声的图像,经过相应的训练也可以对不同程度的噪声产生不错的复原效果。然而,神经网络处理去噪问题时会遇到被去噪图像的噪声与训练图像的噪声分布相差较大,就根本无法复原其结果的情况。而且,当出现复原效果不理想的时候,神经网络的可解释性也比较差。
3.3 图像去模糊
图像去模糊[8,32,44-45](image deblurring) 是指经过某种模糊处理的图像通过神经网络进行清晰图像复原的过程。常见的模糊种类包括高斯模糊、运动模糊、中值模糊等,也可能是多种模糊混合生成的一种复合模糊。神经网络处理图像去模糊的过程为:先将原图像进行模糊处理,得到的图像为神经网络的输入图像,原图像为神经网络的目标图像。非均匀图像模糊计算为

其中,I为模糊的图像;()为由运动场决定的模糊核;I为原图像;为卷积操作;为加性噪声。
文献[44]是早期的工作,主要集中在假设模糊核()是已知的非盲去模糊。其主要依赖于执行反卷积操作获得和模糊核()的估计值。由于要为每个像素找到一个合适的模糊核是一个无法解决的问题,之前大多数算法是基于启发式,图像统计和假设的方法获得图像模糊的来源,即假设模糊来源于相机,那么整幅图像的模糊是一致的,然后再执行反卷积操作去模糊。
之后出现了一些基于CNN的方法进行去模糊操作。SUN等[45]最早利用CNN的方法预测模糊核进行图像去模糊操作,图像的非均匀模糊是由物体或相机的运动造成的,其为原图像带来了具有方向性的运动向量,这些非零的运动向量沿着运动轨迹构成了模糊核,其在清晰图像上的卷积操作产生了模糊的图像。图7(a)为输入的模糊图片,图7(b)中的线段表示利用神经网络预测出的非均匀运动模糊核,图7(c)为复原后的效果。文献[45]并未做全局性的运动参数假设,而是将图像分成很多局部的区域进行分别估计(模糊核),从而实现图像去模糊操作。而最近,NAH[46]使用多尺寸CNN进行端到端的去模糊,也取得了一定的效果。表3对比了几个比较流行的网络[8,45-48]进行图像去模糊的实验效果。由于模糊的情况种类较多,而且程度也有很大区别,神经网络在图像去模糊问题上与传统算法相比还有一定的距离。

(a) 输入图像(b) CNN估计的 运动模糊场(c) 去模糊 后结果
图7 文献[45]去模糊的处理流程
表3 主流图像去模糊网络对退化图像处理结果

方法名称神经网络损失函数复原效果PSNR(dB) Unnatural L0 SR[47]×–较好27.47 Non-uniform Deblurring[48]×–较好27.03 LCNN[45]√L2较差25.22 DMsCNN[46]√L2+adversarial loss较差26.48 DeblurGAN[8]√L1+adversarial loss一般26.10
目前基于神经网络的图像去模糊仍未能达到传统方法所取得效果,主要问题在于模糊的种类和范围难以估计。在真实环境中,模糊的种类可能是高斯模糊、运动模糊、中值模糊等,而且模糊所占图片的范围也可能不固定,模糊的程度差别很大,此类问题都对使用神经网络处理图像去模糊问题产生了限制。
3.4 图像着色
图像着色[49-50](image colorization)是指将局部或整体颜色缺失的退化图像通过着色进行图像复原处理。使用神经网络处理图像着色问题的步骤为:先将原图片处理为灰度图像,并做为神经网络的输入图像。原图像为神经网络的目标图像。解决该问题早期使用的是半自动化的方法,如基于图像示例的方法[51-55],从单幅图或多幅图中统图像的颜色信息[56-57],然后使用类似色彩迁移[58]或图像类别[59]的技术输出到灰度图像中。当引用图像与被处理图像十分相似时,此类方法有很好的处理效果。然而找到相似图像的工作十分的耗时,尤其是对于那些复杂的对象或场景。
最近,全自动的图像着色方法被纷纷提出[9,60-63],通常使用基于全卷积的深度神经网络技术来完成。而对于图像着色问题的另一种思路是给出一定的位置的提示信息,进行图像着色。图8展示了文献[64]使用的半自动着色方案,将黑白图像与彩色离散的色块相结合的方式输入网络,进行图像色彩预测。一方面能够让网络更加有针对性的进行颜色预测,另一方面也为图像着色提供了更多的选择,能够将指定位置着色成给定的颜色。表4对比了几个主流图像着色网络[5,62-64]的处理效果。由表4可以看出在图像着色问题上神经网络较传统方法有着较明显的优势,因为基于神经网络的图像着色技术擅长于从图像中提取丰富的语义信息,然后将其关联到高层次的感官和场景信息中。尤其是在给出一定额外的提示输入后,神经网络可以很好的充分利用提示信息进行图像颜色推断并将最合理的颜色赋予指定的区域。

(a) 灰度图像(b) 用户输入的 稀疏色块(c) 输出图像
表4 主流图像着色网络对退化图像处理结果

方法名称神经网络额外输入复原效果PSNR (dB) 像素预测×–较差22.82 CIC[5]√自动局部颜色缺失22.04 LRAC[63]√自动局部颜色缺失24.93 AICSC[62]√自动局部颜色缺失23.69 RTUGIC[64]√局部颜色提示较好24.43
目前基于神经网络的图像着色问题已经取得一定的进展。然而,使用神经网络进行图像着色依旧存在很多的问题,如对于图像中物体的细节部分或是图像中有一定遮挡物体来说,神经网络的着色通常不是很准确。这主要是因为神经网络的着色过程是基于机器学习的思路,对于物体细节部分或是受到遮挡物体的颜色信息容易受到光线、角度等因素影响。但是,在神经网络技术发展的推动下正逐步被克服。例如对于图像颜色信息不明确的问题,学术界的处理思路已经从基于端到端的全自动着色进展到基于一定条件的半自动着色上来。而且,从现阶段的复原效果上看,半自动噪声已经逐步替代了全自动着色成为了图像着色领域的主力。相信在不久的将来,利用神经网络进行图像着色一定会有更大的发展市场,也会让更多的资源倾向到利用神经网络处理图像着色问题中来。
3.5 图像超分辨率
图像超分辨率[50,65-73](image super resolution)是利用量化后的关系将LR图像通过恢复生动纹理和颗粒细节等以变成HR (high resolution)的过程。通常使用神经网络进行超分辨率的方法为:先将原清晰图像压缩尺寸得到LR图像,然后将LR图像通过线性插值方式得到新的HR图像。由于新的HR图像是经过LR处理后得到的,所以内容比较模糊,此图像即为神经网络的输入图像,原清晰图像为神经网络训练的目标图像。从图像转换的角度看,通常说的超分辨率问题指的是单幅图像的超分辨率(single image super-resolution,SISR)问题,其可分为4类[67]:预测模型(prediction models)、基于边缘方法(edge based methods)、基于图像统计方法(image statistical methods)、基于补丁(patch based)或基于样例(example-based)的方法。评价此类问题处理的难度主要看图像放大的倍数。放大倍数通常为2,3,4倍。表5比较了主流图像超分辨率网络[67,69-73]的处理效果。可以看到神经网络处理超分辨率问题相较于传统算法有着比较明显的优势。当图像放大4倍时,基本能达到30 dB以上的峰值信噪比(peak signal noise ratio,PSNR)。双线性插值是在神经网络之前经典的处理超分辨率问题的算法。
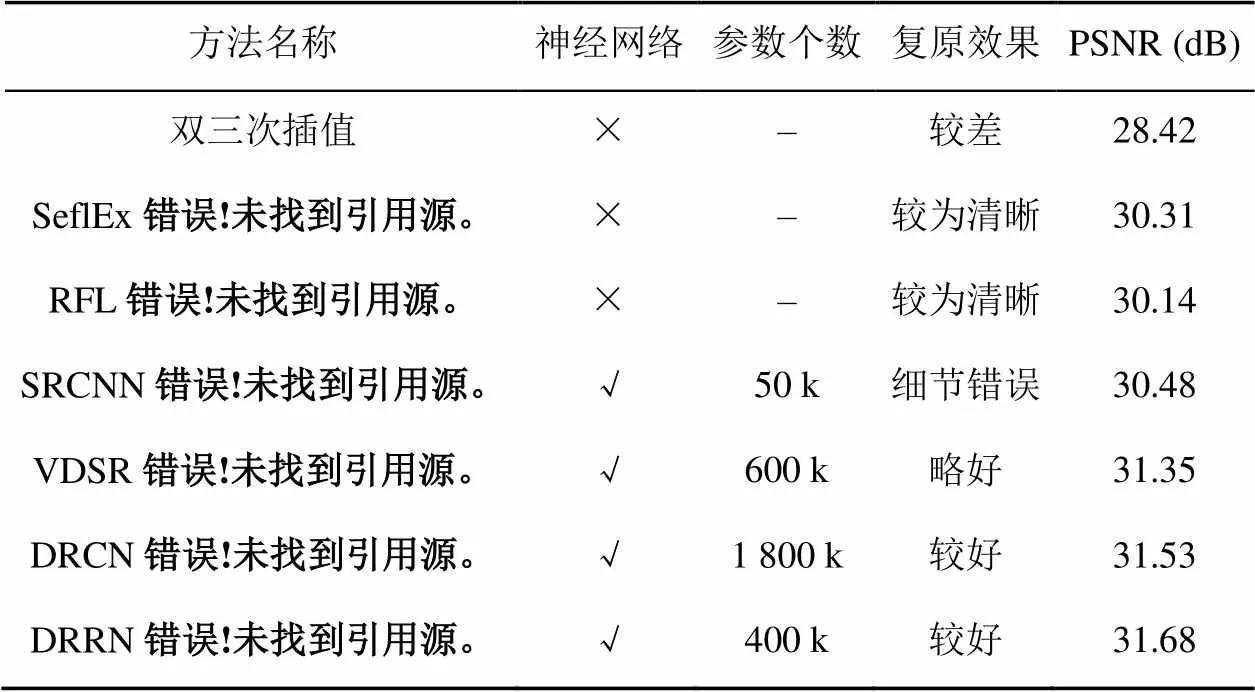
表5 主流图像超分辨率网络对退化图像处理结果
(注:表中数据为放大4倍的复原图与原图计算的PSNR值)
SRCNN[69](图9)是使用CNN处理超分辨率的鼻祖方法,其通过FCN的方式预测LR与HR之间的非线性映射关系。具体方法为:先将LR图像使用双三次差值放大至目标尺寸(如放大2倍、3倍、4倍),并称放大至目标尺寸后的图像为LR图像(Low-resolution image),即图中的输入(input)。将LR图像输入3层CNN,第1层卷积:卷积核尺寸9×9,卷积核数目为64,输出64张特征图;第2层卷积:卷积核尺寸1×1,卷积核数目32,输出32张特征图;第3层卷积:卷积核尺寸5×5,卷积核数目1,输出1张特征图即为最终重建HR图像。该方法处理LR图片的效果明显优于非神经网络方法。之后随着神经网络技术的发展,人们逐渐意识到更深的网络层数能够提高网络预测HR的效果。于是VDSR[72]提出使用20层的卷积层来提高网络的复原能力;之后DRCN[67]引入了非常深的递归链结构层。此时,不断加深的网络层次所带来的庞大的参数数量又给神经网络处理超分问题带来了新的困惑。DRRN[73]提出了具有多路径结构的递归块(该模块能够在增加卷积深度而不添加参数的情况下提升准确率),再次缓解了该问题。而且随着网络的发展,参数也在尽可能的缩减。

图9 SRCNN网络架构图(左侧的低分辨率图像经过特征提取层、非线性映射层与重建层,最终生成右侧的高分辨率图像)
目前基于神经网络的图像超分辨率已经取得令人满意的效果,尤其是在GANs大行其道的今天,神经网络技术已经成为了解决图像超分辨率问题首选技术。然而,对于使用神经网络技术解决超分辨率问题仍存在一定的问题。其中就包括超分辨率后图像的尺寸问题,现阶段使用神经网络进行超分辨率时很难生成高质量的清晰图片(如分辨率在1 K或2 K)。因为,生成HR图像需要更高清晰度的训练集和更大的计算量。神经网络是基于训练的机器学习方法,训练的耗时是主要问题。
4 基于对抗神经网络的极限退化图像复原
图像的复原可能要面临非常极端低质的原始数据。在极端条件下,由于大量的原始信息丢失、有效信息稀少同时还存在大量的干扰信息,因此如何在恶劣的条件下进行有效的图像复原是一个非常困难的问题。针对上述极端条件,提出X (Etreme Cases)-GANs,一种基于条件生成对抗网络的方法来解决极限退化图像复原问题[7]。图10为网络架构图,网络由生成器Generator和损失函数组成。生成器包括下采样、基于残差网络的残差块Residual blocks和上采样3部分。损失函数包括关联点损失函数Corresponding point loss、基于VGG网络的感知损失函数VGG perceptual loss和基于多尺度判别器的对抗感知损失函数Adversarial perceptual loss、GANs本身的对抗损失函数Adversarial loss 4部分组成。本文聚焦于仅包含极少的有用信息的图像复原工作,不同于文献[3]是将25%以上离散点的64×64或128×128图像进行复原,挑战具有更高难度的只包含20%以内有用信息的256×256退化图像复原。面对将尽少量的随机离散点进行复原的问题,基于文献[6, 74]的工作,本文尝试了如使用非参数概率密度函数估计方法等。X-GANs可以解决更少的已知离散点的图像复原并可以得到更好和更稳定的效果。本文所设计的神经网络在解决此类问题时有着自身独特的优势,通过对大量数据样本进行学习,学会了“联想”出离散点与对应图像映射关系。X-GANs对极少量离散点(20%以内离散点)的图像复原也取得了不错的效果。

图10 网络架构图(左侧生成器由残差块组成,右侧包括对抗损失函数,对抗感知损失函数组成的多尺度判别器以及VGG感知损失函数和下面的关联点损失函数)
为了进一步压缩已知离散点数量,本文将离散点分布在特定的区域其有益于图像复原,采用sobel[75]或canny算子将图像边缘提取出来,目的是将离散点分布在梯度变化较大的区域。实验表明,在相同百分比有效离散点的时候,使用sobel[75]算子指定离散点分布的图像能够更好的进行图像复原。被复原图像的细节和边缘更加清晰。考虑到人们对图像某些区域的复原效果更为重视,也就是人们视觉重点关注的区域。本文最终将被复原的图像定义为离散点根据概率重点覆盖梯度变化较大的区域进行掩码处理之后的图像。而对于那些梯度没什么变化的区域,则覆盖较少的离散点。该策略可用于图像的高倍率压缩方法中。
为了从另一个方面挑战网络训练的能力。本文尝试解决具有更高复杂性的随机彩色噪声这个新问题。因为网络需要在大量彩色点中剥离开干扰信息找到能够构成某个人物的图像的有效点信息并进行复原。针对该问题,同样采用了仅包含20%以内的有用信息的图像进行复原并取得了良好的结果。
最后,本文在图像修补问题上也进行了探讨,网络对256×256图像,缺失块在128×128大小也取得不错的效果。并且为提升问题难度,本文定义了将缺失白色块替换为随机的错乱色块的图像缺失问题,提高了网络恢复图像难度。网络除了要面对区分复原数据的区域,还要进行复原这两个任务。图11在上述2个问题上都取得了令人满意的效果。

图11 X-GANs网络对不同退化图像的复原结果((a) 随机场景彩色噪声;(b) 随机场景像素插值;(c) 使用Sobel算子处理后的像素插值复原问题;(d) 图像修补;(e) 图像修补(空白);(f) 人物场景彩色噪声图像)
5 结论与展望
综上可知,相比于非神经网络的算法,使用基于神经网络技术解决退化图像复原问题的优势十分明显。首先,开发者不必针对每种复原问题设计完全独立的算法并进行分析,而只需要设计一种网络模型,就能解决很多种退化图像复原的问题。其次,网络的训练只需要进行简单的数据标注和映射等工作,网络能够根据所给的数据自动学习到退化图像与完整图像的映射关系并自动进行图像的复原工作。最后,GANs根据学习到的东西产生了一定的“联想”能力,能够在数据量极少的情况下对未知区域给出相对合理的数据预测。
但是神经网络处理上述问题也有一定的局限性。如泛化能力不足,是因为其是基于机器学习的,所以多数情况下只对学过的问题类型敏感,并依赖于训练的数据质量和数量。而且在很多时候网络对大尺寸图像和高清图像处理效果不是很理想,神经网络存在不稳定性,很容易陷入到一个鞍点或局部极值点上。除此之外,神经网络的可解释性比较差[24],当出现生成效果不理想时很难通过调整网络来进行修复。而这些问题都是未来研究工作需要解决的关键。
神经网络技术为解决退化图像复原问题带来了新的思路,同时也带来了新的挑战。本文除了介绍的6类问题之外,还有图像去雾(haze removal)、去雨水(raindrop removal)等问题也受到学者们的关注。对于图像去雾问题,比较经典的解决方案还是传统算法为主[76-78],如文献[76]使用暗通道先验去雾算法对图像去雾问题产生了巨大的影响。对于去雨水问题,神经网络已经是主流的解决方法[79-81],如文献[79]解决思路与上文介绍的主流算法一致,通过全卷积或GANs等方式进行雨水图像还原。
随着越来越多的学者投身其中,问题也在不断地被克服。比如pix2pixHD方法[82]对解决条件生成对抗网络如何生成高清图像问题取得了不错的效果。再比如使用非监督方式训练条件生成对抗网络方面也做出贡献[83]。相信不久的将来在越来越多学者的努力下,神经网络在退化图像复原领域会有更好的发展。
[1] KRIZHEVSKY A, ILYA S, HINTON G E. Imagenet classification with deep convolutional neural networks [C]//The 25th International Conference on Neural Information Processing Systems. New York: ACM Press, 2012: 1097-1105.
[2] BERTALMIO M, SAPIRO G, CASELLES V, et al. Image inpainting [C]//The 27th Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM Press, 2000: 417-424.
[3] GAO R, GRAUMAN K. On-demand learning for deep image restoration [EB/OL]. [2016-12-05]. https://arxiv. org/abs/1612.01380.
[4] BUADES A, COLL B, MOREL J M. A non-local algorithm for image denoising [C]//2005 IEEE Conference on Computer Vision and Pattern Recognition. York: IEEE Press, 2005: 60-65.
[5] ZHANG R, ISOLA P, EFROS A A. Colorful image colorization [C]//The 17th European Conference on Computer Vision. Heidelberg: Springer, 2016: 649-666.
[6] YANG J, WRIGHT J, HUANG T S, et al. Image super-resolution via sparse representation [EB/OL]. [2010-05-18]. https://ieeexplore. ieee.org/abstract/ document/ 5466111.
[7] LIU L, LI S, CHEN Y, et al. X-GANs: Image reconstruction made easy for extreme cases [EB/OL]. [2018-08-06]. https://arxiv.org/abs/1808.04432.
[8] KUPYN O, BUDZAN V, MYKHAILYCH M, et al. DeblurGAN: Blind motion deblurring using conditional adversarial networks [EB/OL]. [2017-11-19]. https://arxiv. org/abs/1711.07064.
[9] ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [EB/OL]. [2016-11-21]. https://arxiv.org/abs/1611.07004.
[10] SØNDERBY C K, CABALLERO J, THEIS L, et al. Amortised map inference for image super-resolution [EB/OL]. [2016-10-14]. https://arxiv.org/abs/1610.04490.
[11] 张红英, 彭启琮. 数字图像修复技术综述[J]. 中国图象图形学报, 2007(1): 1-10.
[12] 冈萨雷斯, 伍兹. 数字图像处理[M]. 3版. 阮秋琦, 阮宇智等译. 北京: 电子工业出版社, 2011: 1-633.
[13] HINTON G E, OSINDERO S, TEH Y W. A fast learning algorithm for deep belief nets [EB/OL]. [2006-07-18]. https://www.mitpressjournals.org/doi/abs/ 10.1162/neco.2006.18.7.1527.
[14] LECUN Y, BENGIO Y, HINTON G. Deep learning [EB/OL].[2015-05-28]. https://www.nature. com/articles/ nature14539.
[15] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2015: 3431-3440.
[16] LIOU C Y, HUANG J C, YANG W C. Modeling word perception using the Elman network [EB/OL]. [2008-10-01]. https://www.sciencedirect. com/science/ article/pii/S0925231208002865.
[17] LIOU C Y, CHENG W C, LIOU J W, et al. Autoencoder for words [EB/OL]. [2014-09-02]. https://www.sciencedirect.com/science/article/pii/S0925231214003658.
[18] GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]//NIPS’14 Proceedings of the 27th International Conference on Neural Information Processing Systems. New York: IEEE Press, 2014: 2672-2680.
[19] RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional networks for biomedical image segmentation [C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Heidelberg: Springer, 2015: 234-241.
[20] YANG C, LU X, LIN Z, et al. High-resolution image inpainting using multi-scale neural patch synthesis [C]// The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 3.
[21] KINGMA D P, WELLING M. Auto-encoding variational bayes [EB/OL]. [2013-12-26]. https://arxiv. org/abs/1312.6114.
[22] Generating Faces with Torch [EB/OL]. [2015-11-13]. http://torch.ch/blog/2015/11/13/gan.html.
[23] PATHAK D, KRAHENBUHL P, DONAHUE J, et al. Context encoders: Feature learning by inpainting [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 2536-2544.
[24] 焦李成. 深度学习、优化与识别[M]. 北京: 清华大学出版社, 2017: 1-137.
[25] MIRZA M, OSINDERO S. Conditional generative adversarial nets [EB/OL]. [2014-11-06]. https://arxiv. org/abs/1411.1784.
[26] WU X, XU K, HALL P. A survey of image synthesis and editing with generative adversarial networks [EB/OL]. [2017-12-14]. https://ieeexplore.ieee.org/abstract/ document/8195348.
[27] YEH R A, CHEN C, LIM T Y, et al. Semantic image inpainting with deep generative models [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 5485-5489.
[28] OSHER S, BURGER M, GOLDFARB D, et al. An iterative regularization method for total variation-based image restoration [EB/OL]. [2005-04-06]. https:// epubs.siam.org/doi/abs/10.1137/040605412.
[29] BARNES C, SHECHTMAN E, FINKELSTEIN A, et al. PatchMatch: A randomized correspondence algorithm for structural image editing [J]. ACM Transactions on Graphics (ToG), 2009, 28(3): 24.
[30] EFROS A A, LEUNG T K. Texture synthesis by non-parametric sampling [EB/OL]. [1999-08-10]. https://www.computer.org/csdl/proceedings/iccv/1999/0164/02/01641033.pdf.
[31] HAYS J, EFROS A A. Scene completion using millions of photographs [J]. Communications of the ACM, 2008, 51(10): 87-94.
[32] LIU S, PAN J, YANG M H. Learning recursive filters for low-level vision via a hybrid neural network [C]// The 17th European Conference on Computer Vision. Heidelberg: Springer, 2016: 560-576.
[33] LIU C, FREEMAN W T, SZELISKI R, et al. Noise estimation from a single image [C]//2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2006: 901-908.
[34] LIU X, TANAKA M, OKUTOMI M. Single-image noise level estimation for blind denoising [EB/OL]. [2013-08-10]. http://www.ok.sc.e. titech.ac.jp/res/NLE/ TIP2013-noise-level-estimation06607209.pdf.
[35] CHEN G, ZHU F, ANN HENG P. An efficient statistical method for image noise level estimation [C]// Proceedings of the IEEE International Conference on Computer Vision.New York: IEEE Press, 2015: 477-485.
[36] DABOV K, FOI A, KATKOVNIK V, et al. Image denoising by sparse 3-D transform-domain collaborative filtering [EB/OL]. [2007-07-16]. https://ieeexplore.ieee. org/abstract/document/4271520.
[37] GU S, ZHANG L, ZUO W, et al. Weighted nuclear norm minimization with application to image denoising [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: Press, 2014: 2862-2869.
[38] ZORAN D, WEISS Y. From learning models of natural image patches to whole image restoration [C]// 2011 IEEE International Conference on Computer Vision (ICCV). New York: IEEE Press, 2011: 479-486.
[39] BURGER H C, SCHULER C J, HARMELING S. Image denoising: Can plain neural networks compete with BM3D? [C]//2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2012: 2392-2399.
[40] CHEN Y, POCK T. Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration [EB/OL]. [2016-08-01]. https:// ieeexplore.ieee.org/abstract/document/7527621.
[41] ZHANG K, ZUO W, CHEN Y, et al. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising [EB/OL]. [2017-02-01]. https://ieeexplore. ieee.org/abstract/document/7839189.
[42] XIE J, XU L, CHEN E. Image denoising and inpainting with deep neural networks [C]//NIPS’12 Proceedings of the 25th International Conference on Neural Information Processing Systems. New York: IEEE Press, 2012: 341-349.
[43] JAIN V, SEUNG S. Natural image denoising with convolutional networks [EB/OL]. [2012-08-10]. http://papers.nips.cc/paper/4686-image-denoising-and-inpainting-with-deep-neural-networks.
[44] SZELISKI R. Computer vision: Algorithms and applications [EB/OL]. [2010-08-10] http://citeseerx.ist. psu.edu/viewdoc/download?doi=10.1.1.414.9846&rep=rep1&type=pdf.
[45] SUN J, CAO W, XU Z, et al. Learning a convolutional neural network for non-uniform motion blur removal [C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 769-777.
[46] NAH S, KIM T H, LEE K M. Deep multi-scale convolutional neural network for dynamic scene deblurring [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 3.
[47] XU L, ZHENG S, JIA J. Unnatural l0 sparse representation for natural image deblurring [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2013: 1107-1114.
[48] WHYTE O, SIVIC J, ZISSERMAN A, et al. Non-uniform deblurring for shaken images [EB/OL]. [2011-10-27]. https://link.springer. com/article/10.1007/ s11263-011-0502-7.
[49] LEVIN A, LISCHINSKI D, WEISS Y. Colorization using optimization [J]. ACM Transactions on Graphics (TOG), 2004, 23(1): 689-694.
[50] XU L, YAN Q, JIA J. A sparse control model for image and video editing [C]//ACM Transactions on Graphics (TOG), 2013, 32(6): 1-10.
[51] CHIA A Y S, ZHUO S, GUPTA R K, et al. Semantic colorization with internet images [J]. ACM Transactions on Graphics (TOG), 2011, 30(6): 156.
[52] GUPTA R K, CHIA A Y S, RAJAN D, et al. Image colorization using similar images [C]//Proceedings of the 20th ACM International Conference on Multimedia. New York: ACM Press, 2012: 369-378.
[53] IRONI R, COHEN-OR D, LISCHINSKI D. Colorization by Example [EB/OL]. [2005-08-11]. http:// citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.76.424&rep=rep1&type=pdf.
[54] LIU X, WAN L, QU Y, et al. Intrinsic colorization [J]. ACM Transactions on Graphics (TOG), 2008, 27(5): 152.
[55] WELSH T, ASHIKHMIN M, MUELLER K. Transferring color to greyscale images [J]. ACM Transactions on Graphics (TOG), 2002, 21(3): 277-280.
[56] LIU Y, COHEN M, UYTTENDAELE M, et al. Autostyle: Automatic style transfer from image collections to users’ images [EB/OL]. [2014-07-15]. https://onlinelibrary.wiley.com/doi/abs/10.1111/cgf.12409.
[57] MORIMOTO Y, TAGUCHI Y, NAEMURA T. Automatic colorization of grayscale images using multiple images on the web [C]//ACM SIGGRAPH Computer Graphics 2009. New York: ACM Press, 2009: 59.
[58] REINHARD E, ADHIKHMIN M, GOOCH B, et al. Color transfer between images [EB/OL]. [2001-09-11]. https://ieeexplore.ieee.org/abstract/document/946629.
[59] HERTZMANN A, JACOBS C E, OLIVER N, et al. Image analogies [C]//Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM Press, 2001: 327-340.
[60] CHENG Z, YANG Q, SHENG B. Deep colorization [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 415-423.
[61] Deshpande A, Rock J, Forsyth D. Learning large-scale automatic image colorization [C]//Procee Dings of the IEEE International Conference on Computer Vision. New York: IEEE Press, 2015: 567-575.
[62] IIZUKA S, SIMO-SERRA E, ISHIKAWA H. Let there be color!: Joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification [J]. ACM Transactions on Graphics (TOG), 2016, 35(4): 1-11.
[63] LARSSON G, MAIRE M, SHAKHNAROVICH G. Learning representations for automatic colorization [C]// The 16th European Conference on Computer Vision. Heidelberg: Springer, 2016: 577-593.
[64] ZHANG R, ZHU J Y, ISOLA P, et al. Real-time user-guided image colorization with learned deep priors [EB/OL]. [2017-05-08]. https://arxiv.org/abs/1705.02999.
[65] DONG C, LOY C C, HE K, et al. Learning a deep convolutional network for image super-resolution [C]// The 14th European Conference on Computer Vision. Heidelberg: Springer, 2014: 184-199.
[66] DONG C, LOY C C, TANG X. Accelerating the super-resolution convolutional neural network [C]// The 16th European Conference on Computer Vision. Heidelberg: Springer, 2016: 391-407.
[67] KIM J, KWON LEE J, MU LEE K. Deeply-recursive convolutional network for image super-resolution [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 1637-1645.
[68] YANG C Y, MA C, YANG M H. Single-image super-resolution: A benchmark [C]// The 14th European Conference on Computer Vision. New York: IEEE Press, 2014: 372-386.
[69] DONG C, LOY C C, HE K, et al. Image super-resolution using deep convolutional networks [EB/OL]. [2015-06-01]. https://ieeexplore.ieee.org/ abstract/document/7115171.
[70] HUANG J B, SINGH A, AHUJA N. Single image super-resolution from transformed self-exemplars [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 5197-5206.
[71] SCHULTER S, LEISTNER C, BISCHOF H. Fast and accurate image upscaling with super-resolution forests [C]//Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 3791-3799.
[72] KIM J, KWON LEE J, MU LEE K. Accurate image super-resolution using very deep convolutional networks [C]//Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 1646-1654.
[73] TAI Y, YANG J, LIU X. Image super-resolution via deep recursive residual network [C]//Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 5.
[74] YEH R A, CHEN C, LIM T Y, et al. Semantic Image Inpainting with Deep Generative Models [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 4.
[75] IRWIN S. History and definition of the sobel operator [EB/OL]. [2014-07-11]. https://www. researchgate.net/publication/239398674_An_Isotropic_3_3_Image_Gradient_Operator.
[76] HE K, SUN J, TANG X. Single image haze removal using dark channel prior [EB/OL]. [2010-09-09]. https://ieeexplore.ieee.org/abstract/document/5567108.
[77] ZHU Q, MAI J, SHAO L. A fast single image haze removal algorithm using color attenuation prior [EB/OL]. [2015-11-11]. https://ieeexplore.ieee.org/iel7/83/4358840/ 07128396.pdf.
[78] CAI B, XU X, JIA K, et al. Dehazenet: An end-to-end system for single image haze removal [EB/OL]. [2016-08-10]. https://ieeexplore. ieee.org/abstract/ document/7539399.
[79] FU X, HUANG J, ZENG D, et al. Removing rain from single images via a deep detail network [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 1715-1723.
[80] YANG W, TAN R T, FENG J, et al. Deep joint rain detection and removal from a single image [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 1357-1366.
[81] QIAN R, TAN R T, YANG W, et al. Attentive generative adversarial network for raindrop removal from a single image [C]//Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 2482-2491.
[82] WANG T C, LIU M Y, ZHU J Y, et al. High-resolution image synthesis and semantic manipulation with conditional gans [EB/OL]. [2017-11-30]. https://arxiv. org/abs/1711.11585.
[83] DONG H, NEEKHARA P, WU C, et al. Unsupervised image-to-image translation with generative adversarial networks [EB/OL]. [2017-06-10]. https://arxiv.org/abs/ 1701.02676.
① “pix2pix”https://phillipi.github.io/pix2pix
Advance of Neural Network in Degraded Image Restoration
LIU Long-fei, LI Sheng, LAI Shun-nan
(School of Information Science and Technology, Peking University, Beijing 100871, China)
Restoration of degraded image is an important and challenging issue in the field of image computing. In recent years, artificial intelligence (AI), especially deep learning, has achieved rapid progress. More and more methods based on neural networks have been proposed to solve this problem. This paper first introduces the main techniques based on neural networks to restore the degraded images and makes a classification of the problems. Then we focused on the key neural networks to resolve the problems of each category. By reviewing the development of various network-based methods in the field of deep learning, we analyzed the advantages and limitations between these methods. Furthermore, a comparison between these methods and the traditional ones was also made. Finally, we put forward a new solution on restoration of extremely degraded image using GANs, sketching out the future work on the restoration of degraded image.
degraded image restoration; neural network; generative adversarial networks; artificial intelligence
TP 391
10.11996/JG.j.2095-302X.2019020213
A
2095-302X(2019)02-0213-12
2018-08-21;
2018-10-29
国家自然科学基金项目(61472010,61631001,61632003)
刘龙飞(1988-),男,辽宁沈阳人,算法工程师,硕士研究生。主要研究方向为人工智能、计算机视觉等。E-mail:liulongfei@pku.edu.cn
李 胜(1974-),男,广东高州人,副教授,博士,硕士生导师。主要研究方向为计算机图形学、虚拟现实技术。E-mail:lisheng@pku.edu.cn
猜你喜欢
农业工程学报(2022年14期)2022-10-19
疯狂英语·新悦读(2022年8期)2022-09-20
今日农业(2021年9期)2021-11-26
陶瓷学报(2020年6期)2021-01-26
今日农业(2020年16期)2020-12-14
紫禁城(2020年8期)2020-09-09
电影(2018年10期)2018-10-26
数码世界(2017年12期)2017-12-28
计算机应用(2016年12期)2017-01-13
航天返回与遥感(2014年4期)2014-07-31
