
基于CEEMD-GRNN组合模型的月径流预测方法
2019-05-13 08:55
人民长江 2019年4期
(太原理工大学 水利科学与工程学院,山西 太原 030024)
1 研究背景
准确预测径流变化,对更好地利用分配有限的水资源具有重要意义。然而气候、地理环境、社会发展及人类活动等不确定因素的影响,导致径流预测仍然存在精确度低等诸多问题[1]。长期以来,国内外水文工作者一直致力于探索研究各种径流预测方法,以期进一步提高预测精度。传统方法是根据河川径流的变化具有连续性、周期性和随机性等特点开展研究,主要有成因分析法、数理统计法和时间序列法[2]。随着计算机技术的发展和新的数学方法的不断涌现,为径流预测拓展了新的途径,主要包括模糊数学、支持向量机、人工神经网络、混沌理论等[3],其中人工神经网络是一种模拟动物神经网络,进行信息处理的算法数学模型,具有自学习、容错性等特点[4]。而广义回归神经网络(GRNN)对于非线性映射能力很强,适用于非线性问题,相比于其他神经网络模型效率、精度均较高[5],在一定程度上使径流预测效果进一步改善。
在径流序列模拟预测过程中,掌握径流内部变化规律及减小噪声因素的影响,对于预测模型选择及使用具有重要意义。目前常用于径流序列分析的方法有主成分分析法[6]、奇异谱分析法[7]、小波分解方法[8]、经验模态分解法(EMD)[9-10]、互补集合经验模态分解法(CEEMD)[11]等。其中,主成分分析无法衡量变量间的非线性依赖程度;奇异谱分析按经验选取嵌入维度长度,具有一定的主观性;小波分解方法基函数是人为确定的,缺乏对数据的自适应性;EMD方法具有较强自适应性,却易出现模态混叠问题。而CEEMD方法不仅能够解决主观性及模态混叠问题,且能够有效处理径流序列中存在的数据噪声。
由于各种分析方法仅能揭露径流序列的变化特征及有效处理随机因素,不能对径流序列进行预测;单一预测模型中的函数辨识选择受径流序列中噪声等大量随机因素的影响,难以对整个水文过程进行有效的拟合。组合预测模型成为近年来广受关注的研究方向之一。目前组合模型在实践中更多的是利用不同分析方法与各种预测模型进行组合,以分析方法为基础来提高模型的预测精度。
因此,本文提出CEEMD-GRNN组合模型,以汾河上游4个水文站月径流数据为例进行预测,探究组合模型不同的建模方式对预测精度的影响,并将其与单一GRNN模型进行对比,为径流预测提供一种新的有效方法。
2 研究方法
2.1 互补集合经验模态分解法(CEEMD)
CEEMD方法对月径流序列分解后,得到多个具有一定物理意义的固有模态函数(IMF)和趋势项(Res)。该方法可依据各层分解的频谱提取有效信号,将随机噪声消除。其主要分解步骤如下[12-13]。
(1) 设x(t)为原序列,则IMF1公式为
(1)
(2) 求一阶残差r1(t):
r1(t)=x(t)-IMF1
(2)
(3)IMF2的计算公式为
(3)
(4) 求k阶残差:
rk(t)=rk-1(t)-IMFk
(4)
(5) 计算原序列的IMFk+1,公式如下:
(5)
(6) 重复(4),(5)步,直至残差不能再分解,求得最终残差R(t):
(6)
其中K为IMF的总数,则原序列x(t)的表达式为
(7)
式中,Ek(·)为定义好的算子;ωi(t)为单位方差的零均值高斯白噪声;εk为系数允许在每个阶段选择信噪比;x(t)为径流序列。
2.2 广义回归神经网络(GRNN)
GRNN是一种径向基网络,由输入层、模式层、求和层和输出层构成,结构简单完备,对数据样本的数量要求不高,具有较高的泛化能力和全局收敛性等特性;隐含层节点中的作用函数采用高斯函数,从而具备局部迫近能力,因而学习速度更快;网络训练中,人为参数较少,只有一个阈值,因此可以最大程度避免人为因素造成的误差,使预测准确性更高[14-15]。
2.3 加权平均集成法
加权平均集成法的基本思想是计算IMFs及Res经GRNN预测所得结果的权重,求取加权平均值,以此作为最终预测结果[16]。
加权平均集成法计算公式为
(8)

(9)
式中,ei为第i个分量预测误差的绝对值。
2.4 CEEMD-GRNN组合模型
CEEMD方法可有效解决径流序列中的噪声因素,但对噪声的去除是逐步进行的,因此,CEEMD分解出的高频分量中仍含有部分噪声。为探究包含部分噪声的高频分量是否影响组合模型预测精度,并验证加权平均集成法相比于直接相加法能够有效减小预测误差,本文提出3种不同建模方式构成的组合模型。组合模型1采用加权平均集成法建模,即将CEEMD分解出的各个IMF分量及Res通过GRNN神经网络预测,使用加权平均集成法将各预测结果相加;组合模型2采用高频分量去除法及加权平均集成法建模,即将CEEMD分解出的高频项去除后,剩余IMF分量及Res通过GRNN预测后,使用加权平均法将各预测结果相加;组合模型3采用高频分量去除法建模,即将CEEMD分解出的高频项去除后,剩余IMF分量及Res通过GRNN预测后直接相加。通过组合模型1与组合模型2预测结果对比可探究高频分量是否影响模型预测精度;通过组合模型2与组合模型3预测结果对比来验证加权平均集成法是否能够减小预测误差。3种组合模型具体建模过程如图1所示。
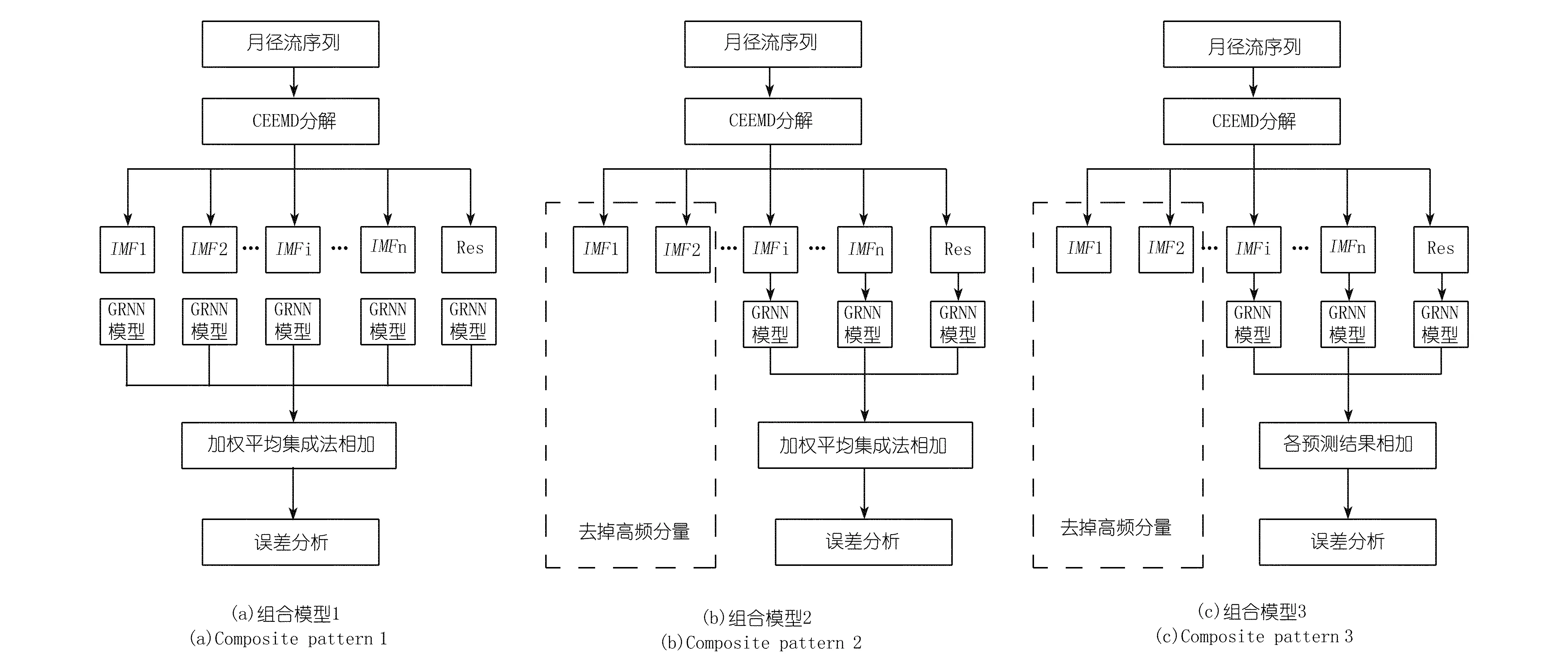
图1 CEEMD-GRNN组合模型预测流程Fig.1 Flow chart of the three proposed CEEMD-GRNN model
3 实例分析
汾河是黄河第二大支流,流经山西省6市的29县(区),是全省生产生活重要的水源。近年来,汾河上游为生态环境建设和农业发展兴建了大批水利工程,在人类活动及气候变化的影响下,径流的变化十分显著。因此能够准确预测汾河上游的径流变化对于当地可持续健康发展具有重要意义。
上静游站位于汾河支流岚河上,其月径流序列波动较为缓和;汾河水库站、寨上站及兰村站位于汾河干流上,其月径流序列波动较为剧烈。因此本文选用汾河上游这4个水文站1958~2000年月径流数据进行预测验证。
3.1 月径流资料CEEMD分解
CEEMD可将复杂的月径流序列分解成包含不同尺度信息且噪声逐渐减少直至消除的IMF及Res。汾河上游4个水文站CEEMD分解结果如图2所示,由图2可知:4个水文站的月径流序列经过CEEMD分解得到的子序列,均呈现从IMF1到趋势项,频率降低,波长变长,振幅变小。各站IMF1~IMF3具有较高的频率,较短的波长,较大的振幅,其中IMF1,IMF2的变化极不规律,这是由于这些分量受原序列极值的影响较大,仍含有部分高频噪声。上静游站、汾河水库站、寨上站IMF4~IMF7,兰村站IMF4~IMF6,逐渐表现出一定的变化规律及周期,表明噪声因素已被逐步消除。各站Res分别表现了该站1958~2000年的月径流序列变化趋势,其中,上静游站和汾河水库站呈现下降趋势,寨上站呈现先下降再上升的趋势,兰村站呈现先下降后小幅上升继而再下降的趋势。由Res可知,各站原月径流序列均为非线性序列,因此本文选取适用于非线性的GRNN模型预测。
综上所述,CEEMD可有效去除高频噪声这一随机因素的影响,进而展现出原径流序列中不同尺度的信息,对后续预测模型的选择及模型能够提取月径流序列中的有效信息从而为提高预测精度奠定基础。
3.2 预测结果分析
本文以上静游站、汾河水库站、寨上站及兰村站1958~1998年共492个月径流数据作为模拟期样本,1999~2000年24个月径流数据作为验证期样本。模型在模拟期通过不断地滚动预测来调整内部结构,寻求最优参数;在验证期检验此模型的预测效果。组合模型1与组合模型2使用加权平均集成法将各分量预测结果重组时,各分量权重见表1。
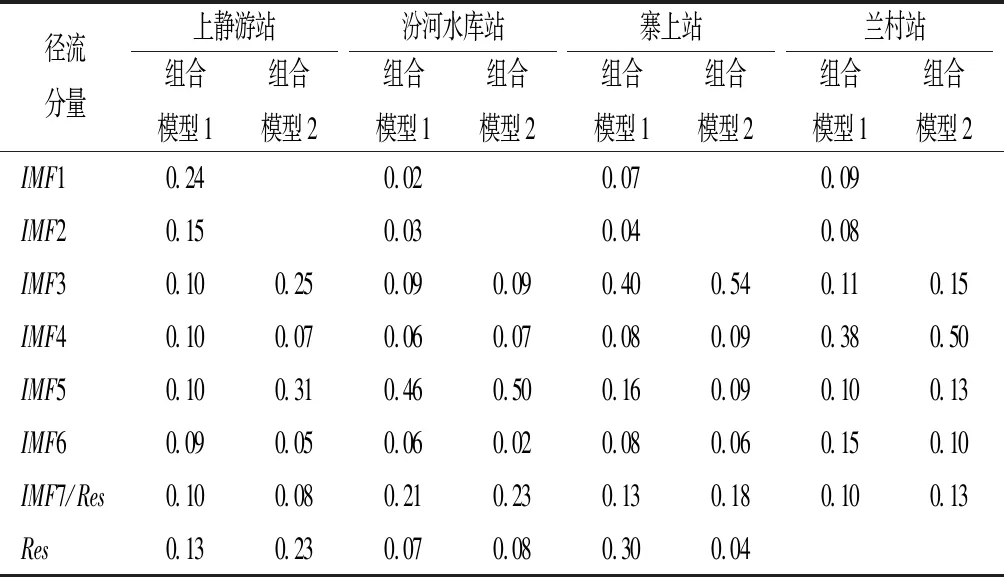
表1 组合模型1与组合模型2分量权重Tab.1 Weight of combined model one and combined model two
加权平均集成法中,权重表示各分量对于最终预测结果的相对重要程度,即权重越大,对提高预测精度的作用越大。由表1可知,上静游站组合模型1中IMF1、IMF2预测值所占权重比其余各分量大,因此高频分量对于预测精度的贡献较大;汾河水库站、寨上站、兰村站组合模型1中IMF1、IMF2预测值所占权重比其余分量小,说明高频分量对于预测精度的贡献较小。而不同频率分量预测精度也不相同,根据表2中组合模型1的各分量预测值平均相对误差可看出,对于上静游站,IMF1、IMF2的平均相对误差分别为13%、18%,均比其他分量小,高频分量预测精度较高;对于汾河水库站、寨上站及兰村站,IMF1、IMF2的平均相对误差为48%~68%,均大于其他分量,高频分量预测精度较低。为了进一步探究高频分量预测值对总体预测精度的影响,本文提出的组合模型2及组合模型3将高频分量去除。

图2 月径流序列的CEEMD结果(径流量单位:万m3)Fig.2 CEEMD results of monthly runoff sequences
4个水文站验证期不同模型预测值与实测值对比结果如图3所示。
由图3结果做初步判断可得:各模型预测结果的总体变化趋势与实测月径流序列基本一致;单一GRNN模型预测值相比于其他3种组合模型与实测月径流序列值相差最大。
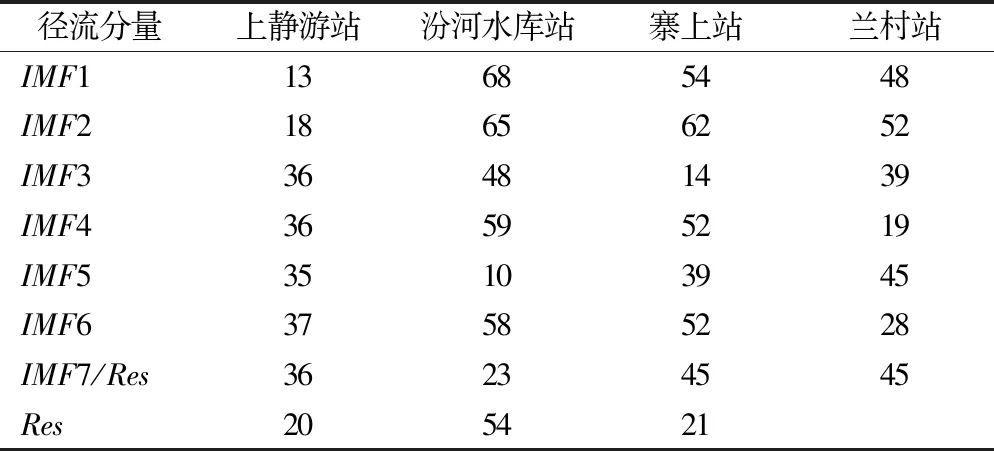
表2 组合模型1各分量平均相对误差Tab.2 Average relative error of components in combined model one %
单一GRNN模型预测结果中,上静游站1999年7月、2000年8月,汾河水库站1999年8月、2000年7月和9月,寨上站1999年5月和6月及2000年6月和7月,兰村站1999年6月、2000年8月预测结果明显大于原径流数据,相对误差达到了66%以上。由于汾河流域在每年6~10月随着降雨量增大,月径流量也随之增加,使月径流序列产生较大程度的波动,高频噪声随机因素增多,导致GRNN模型对于6~10月的径流预测结果误差增大,各站中,相比于其他月份57%以上的平均相对误差,6~10月的平均相对误差增大到89%以上,因此影响了单一GRNN模型的整体预测精度。而其他3种通过CEEMD与GRNN不同建模方式构成的组合模型,预测值曲线均与实测值曲线有更高的拟合度,各站6~10月的径流预测结果平均相对误差降低至39%~64%,进一步说明了CEEMD可有效去除高频噪声随机因素的影响,为降低预测误差奠定基础。
不同建模方式构成的组合模型,预测值与实测值拟合效果也不相同。
对于上静游站,拟合效果为组合模型1>组合模型2>组合模型3。通过前文可知,组合模型1中CEEMD分解出的高频分量预测值所占权重比其余分量大,且平均相对误差较小,说明该站径流高频分量的存在可提高预测精度。这是由于上静游站位于汾河支流岚河上,月径流序列波动程度较缓和,极差也较小约为317万m3,因此CEEMD分解出的高频分量中仍存在的部分噪声因素对预测精度影响较小,能够较好地预测波峰值,使结果更加贴近原径流序列,平均相对误差不超过19%;若去除高频分量,则会减少部分波峰值信息,使组合模型2、组合模型3的预测结果大部分小于月径流实测值,两种组合模型的最大相对误差分别达到36%、45%。
对于汾河水库站、寨上站、兰村站,拟合效果为组合模型2>组合模型3>组合模型1。前文提到组合模型1中CEEMD分解出的高频分量预测值所占权重比其余分量小,平均相对误差也较大,高频分量的存在,在一定程度上影响预测精度。这是由于这3个站位于汾河干流,月径流序列波动程度较为剧烈,极差较大,分别约为2 300万、2 268万、2 631万m3,极差至少为上静游站的7倍,因此CEEMD分解出的高频分量中仍存在的部分噪声因素对后续预测过程产生较大影响。各站使用组合模型1预测的结果最大相对误差达到53%~66%;使用组合模型2、组合模型3预测的结果相对误差均减小。
4个水文站中,组合模型2的拟合效果均优于组合模型3的拟合效果,各站组合模型二预测结果的平均相对误差较组合模型三减小4%~28%。由此可验证加权平均集成法可对各分量预测结果扬长避短,进而构成更准确的预测结果。
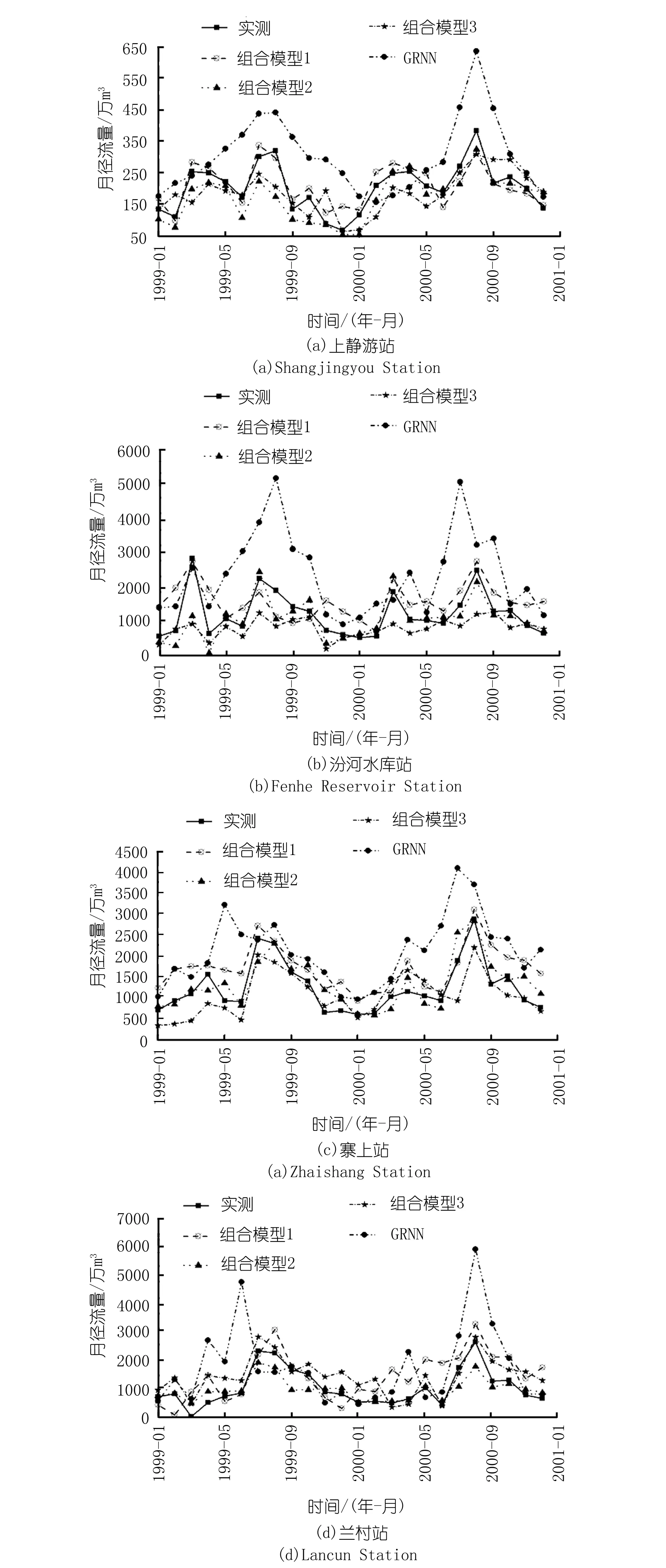
图3 4个水文站各模型预测结果对比Fig.3 Forecast results of each model at four hydrological stations
为了更准确地描述这些模型预测效果的好坏且避免偶然性,本文采用平均绝对误差(MAE)、平均绝对百分比误差(MAPE)、均方根误差(RMSE)及确定性系数(NS)4个指标评价模型的预测精度。
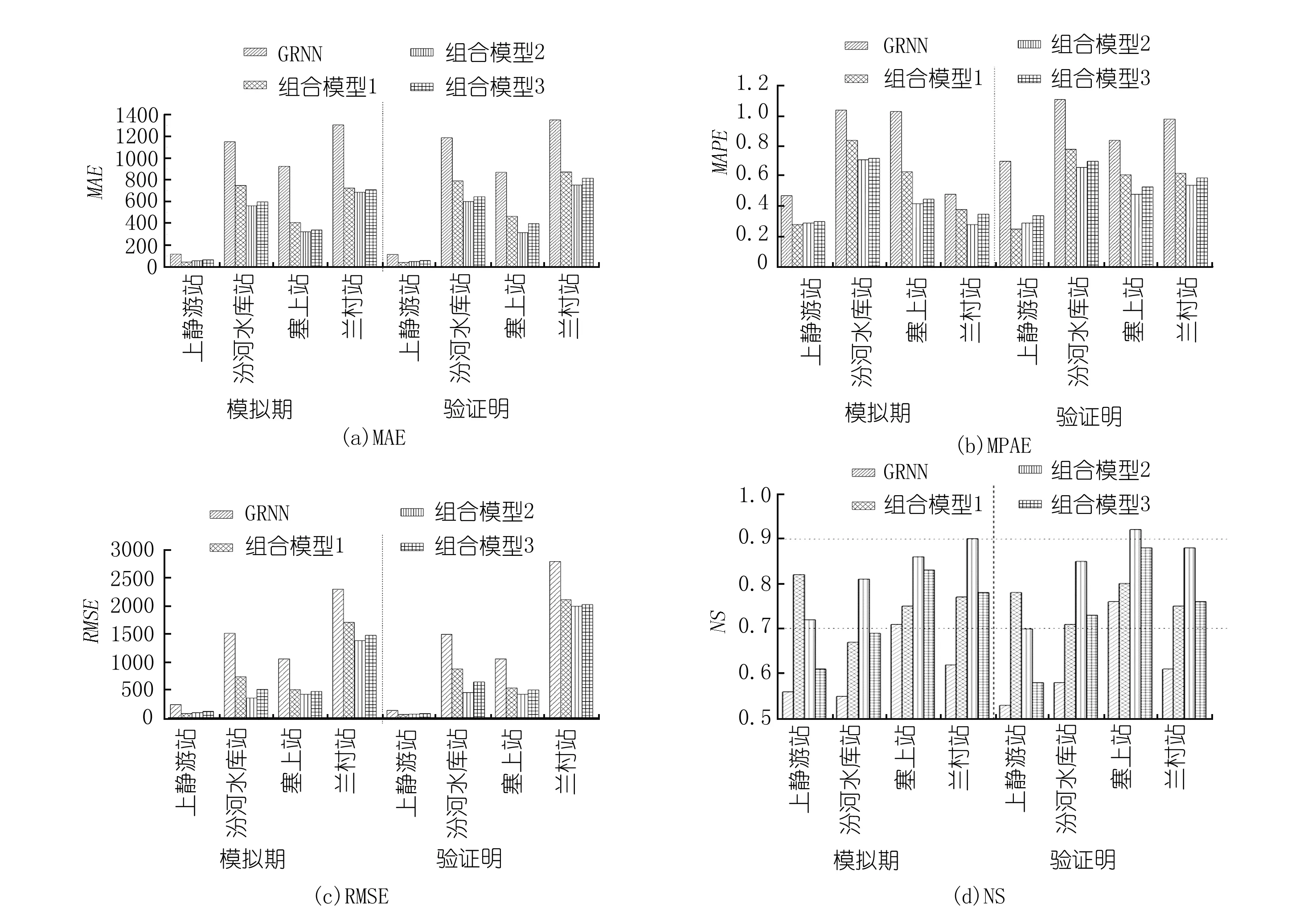
图4 4个水文站各模型预测误差及NS对比Fig.4 Prediction error and NS of each model at four hydrological stations
(10)
(11)
(12)
(13)
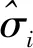
根据《水文情报预报规范》(SL250-2000)规定:当NS≥0.9时,预测精度为甲级;0.7≤NS<0.9时,为乙级;当0.5≤NS<0.7时,为丙级;当NS<0.5时,预报结果不可信。
汾河上游4个水文站预测误差及确定性系数结果如图4所示,由图4可知:
(1) 各模型在模拟期与验证期的NS值均大于0.5,即预测结果均具有可信度,NS越大,则表示预测结果精度越高。各站组合模型的NS值始终大于单一GRNN模型。但在不同水文站,组合模型的预测精度也不相同。对于上静游站组合模型1的NS最大,模拟期为0.82、验证期为0.78,精度为乙级;组合模型2次之,模拟期为0.72、验证期为0.70,精度为乙级;组合模型3的NS值最小,模拟期为0.61、验证期为0.58,精度为丙级。对于汾河水库站、寨上站及兰村站,组合模型2的NS最大,模拟期为0.81~0.90、验证期为0.85~0.92,精度达到乙级以上,其中兰村站模拟期及寨上站验证期精度可达到甲级;组合模型3次之,模拟期为0.69~0.83、验证期为0.73~0.88,除汾河水库站模拟期精度为丙级外,其余精度为乙级;组合模型1的NS值最小,模拟期为0.67~0.77、验证期为0.71~0.80,除汾河水库站模拟期精度为丙级外,其余精度为乙级。
(2) 在模拟期,上静游站误差结果为组合模型1<组合模型2<组合模型3 汾河水库站、寨上站及兰村站误差结果为组合模型2<组合模型3<组合模型1 (3) 在验证期,结果与模拟期相似,上静游站误差结果为组合模型1<组合模型2<组合模型3 汾河水库站、寨上站及兰村站误差结果为组合模型2<组合模型3<组合模型1 综上,各模型预测结果均具有可信度,模拟期、验证期中各组合模型与单一GRNN模型相比,预测误差较小,精度较高,再次验证CEEMD可有效减小月径流序列中高频噪声的影响,为提高预测精度奠定基础。对于上静游站组合模型1的预测误差较组合模型2与组合模型3小,且精度更高,对于汾河水库站、寨上站、兰村站组合模型2的预测误差较组合模型1与组合模型3小,且精度更高,进一步证明将月径流序列通过CEEMD分解后,对于极差较小的月径流序列,保留高频分量可以得到较好的预测效果,对于极差较大的月径流序列,去除高频分量后进行预测能够减小误差。组合模型2的预测误差总是小于组合模型3的预测误差,因此进一步验证加权平均集成法能够有效提高预测精度。 本文针对月径流序列所含的噪声因素及其非线性特征,提出CEEMD-GRNN组合模型,并探究不同建模方式下的组合模型预测效果,通过与单一GRNN模型相比,以汾河上游4个水文站月径流序列为例进行预测分析,得出如下结论。 (1) 各模型的NS值均大于0.5,预测结果具有可信度。3种不同建模方式下的组合模型预测精度均优于单一GRNN模型,CEEMD方法可有效去随机噪声的影响,组合模型更适用于径流预测。 (2) 不同的径流序列适用不同的建模方式。对于极差较小的径流序列,CEEMD分解出的高频分量对预测精度影响较小,且有助于对极值点的预测,因此加权平均集成法构成的组合模型适用于此类径流序列的预测;对于极差较大的径流序列,CEEMD分解出的高频分量对预测精度影响较大,若去除高频分量后进行预测,则误差会减小,因此高频分量去除及加权平均集成法构成的组合模型更适用于此类径流序列的预测。 (3) 加权平均集成法可对各分量的预测结果扬长避短,有效提高总体预测精度。4 结 论
猜你喜欢
星星·散文诗(2022年16期)2022-12-21水利水电快报(2022年8期)2022-11-23水力发电(2022年8期)2022-10-12星星·诗歌原创(2022年6期)2022-07-03黑龙江大学自然科学学报(2022年1期)2022-03-29读者·校园版(2020年19期)2020-09-16品牌研究(2020年32期)2020-08-09当代陕西(2019年19期)2019-11-23智族GQ(2019年9期)2019-10-28新作文·小学低年级版(2019年3期)2019-04-20
